Mixing Vector Model for Copolymer Inference via Mixed Integer Linear Programming
Pith reviewed 2026-06-29 00:09 UTC · model grok-4.3
The pith
The mixing vector model represents copolymers as convex combinations of monomer features, enabling MILP-based inverse design with high predictive accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the mixing vector model a copolymer feature vector is represented as a convex combination of MILP-tractable monomer descriptors weighted by the mixing ratio of the constituent monomers. Prediction functions built from this representation using neural networks, reduced quadratic regression, and random forests achieve test R squared exceeding 0.7 for nine of ten datasets and 0.9 for six. The multi-monomer inverse-design MILP instances remain tractable even for three-monomer settings, and an external consistency check confirms that re-computed property values align with the learned predictions.
What carries the argument
The mixing vector model, which encodes a copolymer as a convex combination of its monomer feature vectors weighted by mixing ratios, allowing direct use of MILP solvers for design without sequence information.
Load-bearing premise
Representing a copolymer solely as a convex combination of its constituent monomer descriptors without any sequence-class information suffices to capture the relevant structure-property relationships.
What would settle it
Finding that the property values recomputed from the inferred copolymer structures deviate substantially and systematically from the values predicted by the learned model on the same structures.
Figures
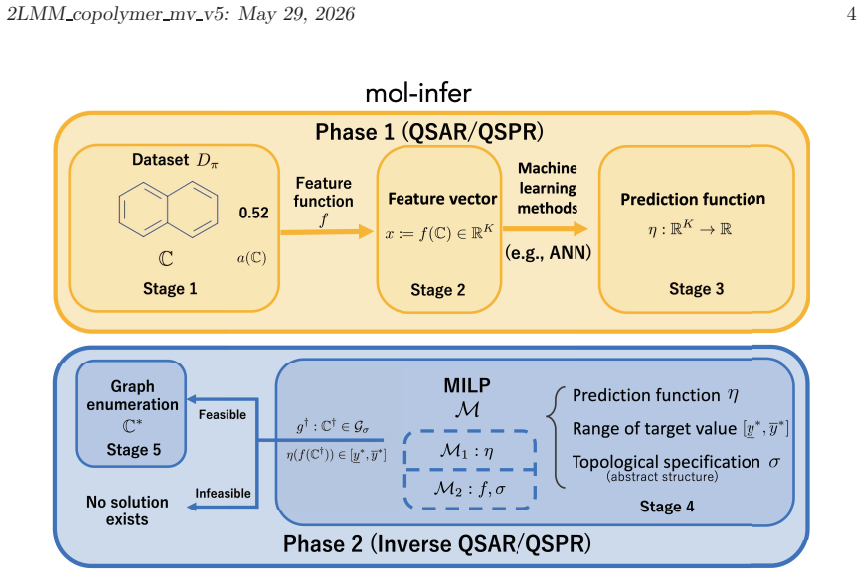

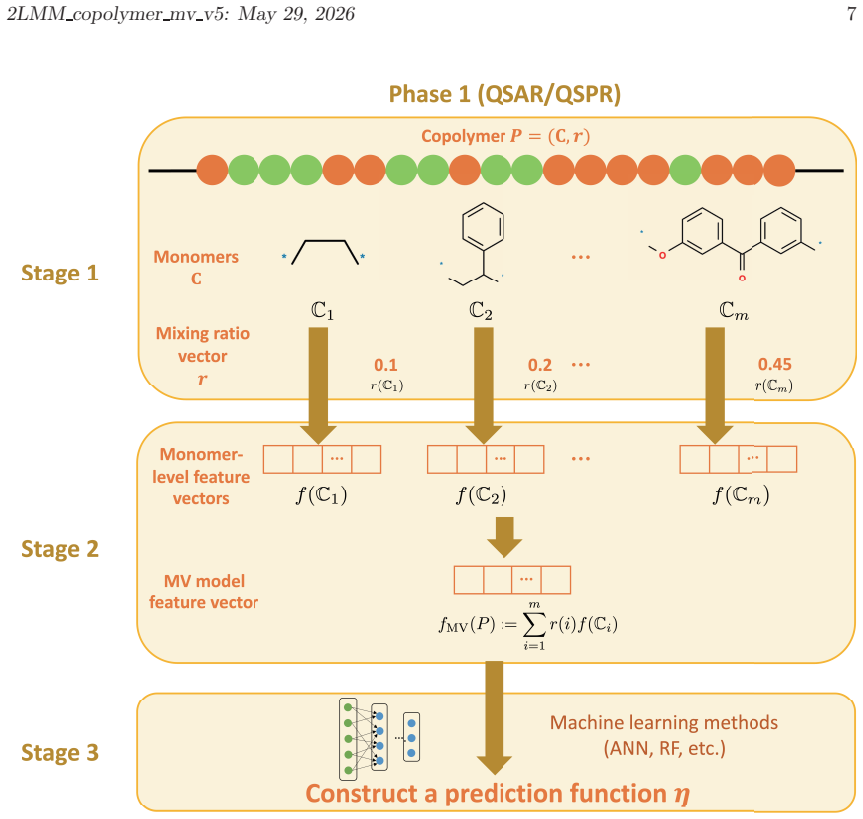
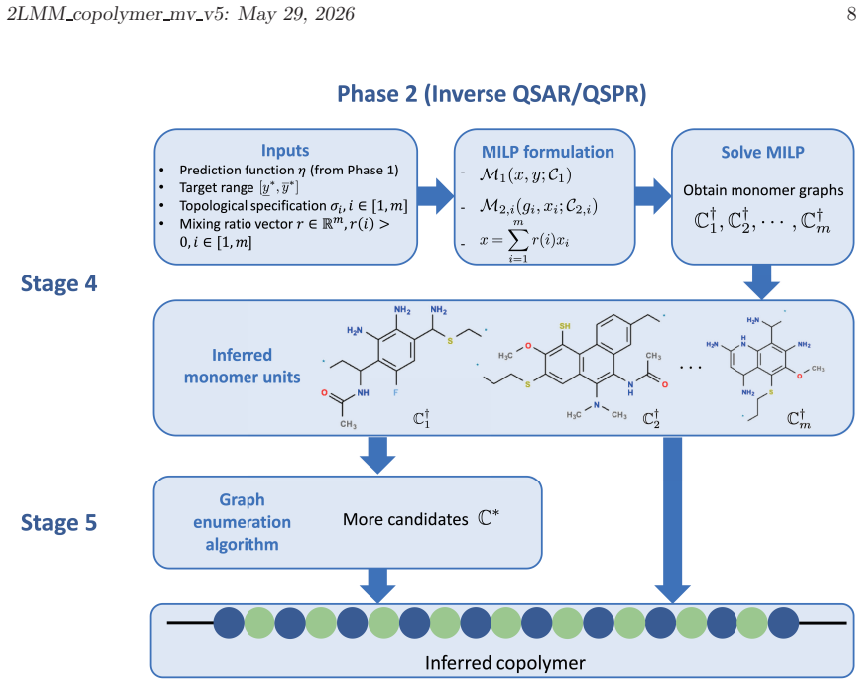
read the original abstract
A novel two-phase molecule inference framework, mol-infer, has recently been developed to infer chemical graphs with prescribed abstract structures and desired property values through mixed integer linear programming (MILP) under the two-layered model, with guaranteed optimality and exactness relative to the given learned prediction function and structural constraints. In this study, we extend this framework to copolymers by introducing a simple feature representation, called the mixing vector (MV) model. In the proposed model, a copolymer feature vector is represented as a convex combination of MILP-tractable monomer descriptors weighted by the mixing ratio of the constituent monomers. This representation does not require explicit sequence-class information and is therefore naturally compatible with MILP-based inverse design. Under this model, we construct prediction functions for several copolymer property datasets using artificial neural networks, reduced quadratic multiple linear regression, and random forests. The proposed representation achieves practically useful predictive performance across multiple physicochemical property datasets; in particular, the best test R^2 score exceeds 0.7 for nine of the ten datasets and exceeds 0.9 for six datasets. We also formulate a multi-monomer inverse-design problem under the MV representation with a prescribed mixing ratio and show that the resulting MILP instances remain tractable, even for three-monomer settings. Finally, we perform an external consistency check by re-evaluating the inferred candidates and comparing the re-computed property values with those predicted by the learned model. Overall, the proposed framework gives a tractable first step toward model-level exact inverse design of copolymers under the two-layered model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the mixing vector (MV) model for copolymer feature representation as a convex combination of monomer descriptors by mixing ratio. This enables MILP-based inverse design in the two-layered mol-infer framework without needing sequence-class information. Prediction functions built with artificial neural networks, reduced quadratic multiple linear regression, and random forests yield test R² exceeding 0.7 for nine of ten datasets and 0.9 for six. The multi-monomer inverse-design MILPs are tractable for up to three monomers, and an external consistency check is conducted by re-evaluating inferred candidates.
Significance. If the reported results hold, the work offers a tractable approach to model-level exact inverse design for copolymers, extending prior MILP frameworks. The high predictive performance on multiple datasets, demonstration of MILP tractability even in three-monomer cases, and the external consistency check are notable strengths that support practical utility. This could facilitate inverse design in polymer chemistry where composition dominates the properties of interest.
major comments (2)
- [Results section (predictive performance)] Details on data splits, feature construction for the monomer descriptors, hyperparameter choices for the ANN, RQMLR, and RF models, and any post-hoc data exclusions are not provided. These are essential to substantiate the test R² claims and assess potential issues like overfitting or selection bias.
- [MV model definition] The sufficiency of the composition-only MV representation for the physicochemical properties is assumed without explicit validation against sequence-aware alternatives or discussion of whether the ten datasets exhibit sequence-dependent behaviors. This assumption underpins both the predictive scores and the inverse-design applicability.
minor comments (3)
- [Abstract] The abstract could specify the total number of datasets and the range of properties considered for better context.
- [Methods] Clarify the exact formulation of the reduced quadratic multiple linear regression and how it differs from standard quadratic regression.
- [Inverse design section] Provide more details on the MILP formulation size (e.g., number of variables/constraints) for the three-monomer cases to support the tractability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive recommendation for minor revision. The feedback highlights important areas for improving clarity and reproducibility. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Results section (predictive performance)] Details on data splits, feature construction for the monomer descriptors, hyperparameter choices for the ANN, RQMLR, and RF models, and any post-hoc data exclusions are not provided. These are essential to substantiate the test R² claims and assess potential issues like overfitting or selection bias.
Authors: We agree that these methodological details are essential for reproducibility and to allow assessment of the reported performance. In the revised manuscript, we will expand the Results and/or Methods sections to include: (i) the data splitting strategy (including ratios and whether random or stratified), (ii) the specific monomer descriptors employed and their construction process, (iii) the hyperparameter selection procedure and final values for the ANN, RQMLR, and RF models, and (iv) explicit confirmation that no post-hoc data exclusions were applied beyond standard preprocessing. These additions will directly address concerns regarding potential overfitting or selection bias. revision: yes
-
Referee: [MV model definition] The sufficiency of the composition-only MV representation for the physicochemical properties is assumed without explicit validation against sequence-aware alternatives or discussion of whether the ten datasets exhibit sequence-dependent behaviors. This assumption underpins both the predictive scores and the inverse-design applicability.
Authors: The MV model is deliberately formulated as a composition-only representation to ensure compatibility with MILP-based inverse design without requiring sequence-class information, which is frequently unavailable for copolymers. The ten datasets used are standard copolymer property collections where composition is the dominant variable, and the achieved predictive performance supports applicability in this regime. We will add a clarifying paragraph in the manuscript discussing the scope of the MV model, explicitly noting its suitability when composition dominates properties and that sequence-dependent cases would require alternative representations. However, a direct empirical comparison to sequence-aware models is not feasible here, as the datasets lack sequence annotations; such validation would constitute a separate study. revision: partial
Circularity Check
No circularity: MV representation and MILP extension are independent of fitted outputs
full rationale
The paper introduces the MV model as a new convex-combination representation explicitly chosen for MILP compatibility, trains standard ML regressors on external datasets, and states that inverse-design optimality holds only relative to the learned functions. No equation reduces a claimed result to its own fitted parameters by construction, no uniqueness theorem is imported from self-citation, and the mol-infer reference is used only as the base framework being extended rather than as load-bearing justification for the new claims. Performance numbers are reported on held-out test data, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Copolymer properties can be modeled as a convex combination of monomer descriptors weighted by mixing ratio without sequence information
invented entities (1)
-
Mixing vector (MV) model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Akutsu and H
T. Akutsu and H. Nagamochi. A mixed integer linear programming fo rmulation to artificial neural networks. In Proceedings of the 2nd International Conference on Informa tion Science and Systems , pages 215–220, 2019
2019
-
[2]
´Asgeirsson, C
V. ´Asgeirsson, C. A. Bauer, and S. Grimme. Quantum chemical calculat ion of electron ioniza- tion mass spectra for general organic and inorganic molecules. Chemical Science, 8:4879–4895, 2017
2017
-
[3]
N. A. Azam, R. Chiewvanichakorn, F. Zhang, A. Shurbevski, H. N agamochi, and T. Akutsu. A novel method for the inverse QSAR/QSPR based on artificial neura l networks and mixed inte- ger linear programming with guaranteed admissibility. In Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies - BIOINFORMAT...
2020
-
[4]
N. A. Azam, J. Zhu, K. Haraguchi, L. Zhao, H. Nagamochi, and T. Akutsu. Molecular design based on artificial neural networks, integer programming and grid neighbor search. In 2021 IEEE International Conference on Bioinformatics and Biome dicine (BIBM) , pages 360–363. IEEE, 2021
2021
-
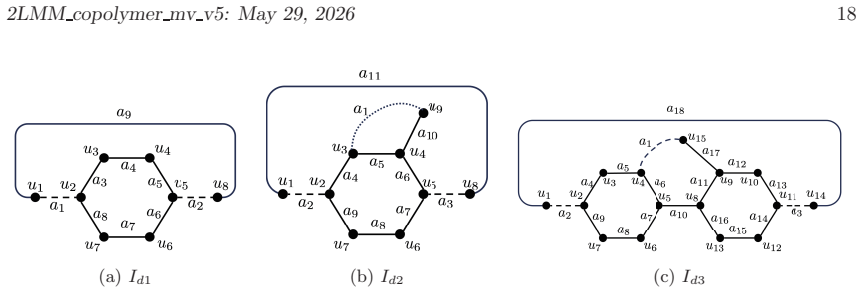
[5]
N. A. Azam, J. Zhu, Y. Sun, Y. Shi, A. Shurbevski, L. Zhao, H. Na gamochi, and T. Akutsu. A novel method for inference of acyclic chemical compounds with bou nded branch-height based on artificial neural networks and integer programming. Algorithms for Molecular Biology , 16:1–39, 2021
2021
-
[6]
Y. Bai, L. Wilbraham, B. J. Slater, M. A. Zwijnenburg, R. S. Sprick , and A. I. Cooper. Accelerated discovery of organic polymer photocatalysts for hyd rogen evolution from water through the integration of experiment and theory. Journal of the American Chemical Society , 141(22):9063–9071, 06 2019
2019
-
[7]
W. Bort, D. Mazitov, D. Horvath, F. Bonachera, A. Lin, G. Marc ou, I. Baskin, T. Madzhidov, and A. Varnek. Inverse QSAR: Reversing descriptor-driven pred iction pipeline using attention- based conditional variational autoencoder. Journal of Chemical Information and Modeling , 62(22):5471–5484, 11 2022
2022
-
[8]
Brierley-Croft, P
S. Brierley-Croft, P. D. Olmsted, P. J. Hine, R. J. Mandle, A. Cha plin, J. Grasmeder, and J. Mattsson. Polymer informatics method for fast and accurate p rediction of the glass tran- sition temperature from chemical structure. Macromolecules, 58(13):6407–6417, 07 2025
2025
-
[9]
H. Cai, H. Zhang, D. Zhao, J. Wu, and L. Wang. FP-GNN: a versat ile deep learning architec- ture for enhanced molecular property prediction. Briefings in Bioinformatics , 23(6):bbac408, 09 2022
2022
-
[10]
Cheng, Y
Y. Cheng, Y. Gong, Y. Liu, B. Song, and Q. Zou. Molecular design in drug discovery: a comprehensive review of deep generative models. Briefings in Bioinformatics , 22(6):bbab344, 08 2021
2021
-
[11]
Cherkasov, E
A. Cherkasov, E. N. Muratov, D. Fourches, A. Varnek, I. I. Baskin, M. Cronin, J. Dearden, P. Gramatica, Y. C. Martin, R. Todeschini, et al. QSAR modeling: wher e have you been? where are you going to? Journal of Medicinal Chemistry , 57(12):4977–5010, 2014
2014
-
[12]
J. G. Coldstream, P. J. Camp, D. J. Phillips, and P. J. Dowding. Gr adient copolymers versus block copolymers: self-assembly in solution and surface adsorption . Soft Matter, 18:6538–6549, 2022
2022
-
[13]
E. F. Connor, I. Lees, and D. Maclean. Polymers as drugs—adv ances in therapeutic appli- cations of polymer binding agents. Journal of Polymer Science Part A: Polymer Chemistry , 55(18):3146–3157, 2017
2017
-
[14]
IBM ILOG CPLEX Optimization Studio, 2025
2025
-
[15]
A. Das, T. Ringu, S. Ghosh, and N. Pramanik. A comprehensive r eview on recent advances in preparation, physicochemical characterization, and bioenginee ring applications of biopoly- mers. Polymer Bulletin , 80(7):7247–7312, 2023
2023
-
[16]
P. J. Flory. Principles of polymer chemistry . Cornell university press, 1953. 2LMM copolymer mv v5: May 29, 2026 25
1953
-
[17]
Gao and D
C. Gao and D. Yan. Hyperbranched polymers: from synthesis t o applications. Progress in Polymer Science , 29(3):183–275, 2004
2004
-
[18]
J. Gasteiger, S. Giri, J. T. Margraf, and S. G¨ unnemann. Fast and uncertainty-aware directional message passing for non-equilibrium molecules. arXiv:2011.14115, 20 22
-
[19]
Grimme, C
S. Grimme, C. Bannwarth, and P. Shushkov. A robust and accu rate tight-binding quantum chemical method for structures, vibrational frequencies, and n oncovalent interactions of large molecular systems parametrized for all spd-block elements (z = 1–8 6). Journal of Chemical Theory and Computation , 13(5):1989–2009, 05 2017
1989
-
[20]
GitHub - grimme-lab/xtb: Semiempirical Extended Tight-Binding P rogram Package, 2024
2024
-
[21]
R. Ido, N. A. Azam, J. Zhu, H. Nagamochi, and T. Akutsu. A dyn amic programming algorithm for generating chemical isomers based on frequency vectors. Scientific Reports , 15(1):22214, 2025
2025
-
[22]
R. Ido, S. Cao, J. Zhu, N. A. Azam, K. Haraguchi, L. Zhao, H. N agamochi, and T. Akutsu. A method for inferring polymers based on linear regression and integ er programming. IEEE/ACM Transactions on Computational Biology and Bioinf ormatics, 21(6):1623–1632, 2024
2024
-
[23]
Ikebata, K
H. Ikebata, K. Hongo, T. Isomura, R. Maezono, and R. Yoshid a. Bayesian molecular design with a chemical language model. Journal of Computer-aided Molecular Design , 31:379–391, 2017
2017
-
[24]
R. Ito, N. A. Azam, C. Wang, A. Shurbevski, H. Nagamochi, and T. Akutsu. A novel method for the inverse QSAR/QSPR to monocyclic chemical compounds base d on artificial neural networks and integer programming. In Advances in Computer Vision and Computational Biology: Proceedings from IPCV’20, HIMS’20, BIOCOMP’20, a nd BIOENG’20, pages 641–
-
[25]
E. A. Jackson and M. A. Hillmyer. Nanoporous membranes derive d from block copolymers: From drug delivery to water filtration. ACS Nano , 4(7):3548–3553, 07 2010
2010
-
[26]
A. Jain, R. Gurnani, A. Rajan, H. J. Qi, and R. Ramprasad. A phy sics-enforced neural network to predict polymer melt viscosity. npj Computational Materials , 11(1):42, 2025
2025
-
[27]
H. Kaneko. Molecular descriptors, structure generation, an d inverse QSAR/QSPR based on SELFIES. ACS Omega, 8(24):21781–21786, 06 2023
2023
-
[28]
A. Khan, L. K. Kian, M. Jawaid, A. A. P. Khan, M. M. Alotaibi, A. M. Asiri, and H. M. Mar- wani. Preparation of styrene-butadiene rubber (SBR) composite incorporated with collagen- functionalized graphene oxide for green tire application. Gels, 8(3), 2022
2022
-
[29]
S. B. Kharchenko, R. M. Kannan, J. J. Cernohous, and S. Ven kataramani. Role of architecture on the conformation, rheology, and orientation behavior of linear, star, and hyperbranched polymer melts. 1. synthesis and molecular characterization. Macromolecules, 36(2):399–406, 01 2003
2003
-
[30]
Kumar, S
L. Kumar, S. Singh, A. Horechyy, A. Fery, and B. Nandan. Bloc k copolymer template-directed catalytic systems: Recent progress and perspectives. Membranes, 11(5), 2021. 2LMM copolymer mv v5: May 29, 2026 26
2021
-
[31]
M. D. Lefebvre, M. Olvera de la Cruz, and K. R. Shull. Phase segr egation in gradient copoly- mer melts. Macromolecules, 37(3):1118–1123, 02 2004
2004
-
[32]
X. Li, J. Huang, Y. Chen, F. Zhu, Y. Wang, W. Wei, and Y. Feng. P olymer-based electronic packaging molding compounds, specifically thermal performance imp rovement: An overview. ACS Applied Polymer Materials , 6(24):14948–14969, 12 2024
2024
-
[33]
J. W. Lim. Polymer materials for optoelectronics and energy app lications. Materials, 17(15), 2024
2024
-
[34]
Y.-C. Lo, S. E. Rensi, W. Torng, and R. B. Altman. Machine learnin g in chemoinformatics and drug discovery. Drug Discovery Today , 23(8):1538–1546, 2018
2018
-
[35]
M. A. R. Meier and C. Barner-Kowollik. A new class of materials: Se quence-defined macro- molecules and their emerging applications. Advanced Materials, 31(26):1806027, 2019
2019
-
[36]
L. A. Miccio and G. A. Schwartz. From chemical structure to qu antitative polymer properties prediction through convolutional neural networks. Polymer, 193:122341, 2020
2020
-
[37]
Miyao, H
T. Miyao, H. Kaneko, and K. Funatsu. Inverse QSPR/QSAR ana lysis for chemical structure generation (from y to x). Journal of Chemical Information and Modeling , 56(2):286–299, 2016
2016
-
[38]
D. A. Olson, L. Chen, and M. A. Hillmyer. Templating nanoporous p olymers with ordered block copolymers. Chemistry of Materials , 20(3):869–890, 02 2008
2008
-
[39]
R. A. Patel, C. H. Borca, and M. A. Webb. Featurization strate gies for polymer sequence or composition design by machine learning. Mol. Syst. Des. Eng. , 7:661–676, 2022
2022
-
[40]
M. Reis, F. Gusev, N. G. Taylor, S. H. Chung, M. D. Verber, Y. Z . Lee, O. Isayev, and F. A. Leibfarth. Machine-learning-guided discovery of 19F MRI age nts enabled by automated copolymer synthesis. Journal of the American Chemical Society , 143(42):17677–17689, 10 2021
2021
-
[41]
Rodriguez, C
F. Rodriguez, C. Cohen, C. K. Ober, and L. Archer. Principles of polymer systems . CRC press, 2014
2014
-
[42]
Rupakheti, A
C. Rupakheti, A. Virshup, W. Yang, and D. N. Beratan. Strate gy to discover diverse optimal molecules in the small molecule universe. Journal of Chemical Information and Modeling , 55(3):529–537, 2015
2015
-
[43]
J. L. Self, A. J. Zervoudakis, X. Peng, W. R. Lenart, C. W. Mac osko, and C. J. Ellison. Linear, graft, and beyond: Multiblock copolymers as next-genera tion compatibilizers. JACS Au, 2(2):310–321, 02 2022
2022
-
[44]
Y. Shi, J. Zhu, N. A. Azam, K. Haraguchi, L. Zhao, H. Nagamoch i, and T. Akutsu. An inverse QSAR method based on a two-layered model and integer programmin g. International Journal of Molecular Sciences , 22(6):2847, 2021
2021
-
[45]
Shino and H
Y. Shino and H. Kaneko. Improving molecular design with direct inv erse analysis of QSAR/QSPR model. Molecular Informatics, 44(1):e202400227, 2025
2025
-
[46]
Sinclair, X
A. Sinclair, X. Zhou, S. Tangpong, D. S. Bajwa, M. Quadir, and L . Jiang. High-performance styrene-butadiene rubber nanocomposites reinforced by surfa ce-modified cellulose nanofibers. ACS Omega, 4(8):13189–13199, 08 2019. 2LMM copolymer mv v5: May 29, 2026 27
2019
-
[47]
M. I. Skvortsova, I. I. Baskin, O. L. Slovokhotova, V. A. Paly ulin, and N. S. Zefirov. Inverse problem in QSAR/QSPR studies for the case of topological indexes ch aracterizing molecular shape (Kier indices). Journal of Chemical Information and Computer Sciences , 33(4):630–634, 1993
1993
-
[48]
M. P. Stoykovich, H. Kang, K. C. Daoulas, G. Liu, C.-C. Liu, J. J. de Pablo, M. M¨ uller, and P. F. Nealey. Directed self-assembly of block copolymers for nanolit hography: Fabrication of isolated features and essential integrated circuit geometries. ACS Nano , 1(3):168–175, 10 2007
2007
-
[49]
N. Q. Su and X. Xu. Insights into direct methods for predictions of ionization potential and electron affinity in density functional theory. The Journal of Physical Chemistry Letters , 10(11):2692–2699, 06 2019
2019
-
[50]
Tanaka, J
K. Tanaka, J. Zhu, N. A. Azam, K. Haraguchi, L. Zhao, H. Naga mochi, and T. Akutsu. An inverse QSAR method based on decision tree and integer program ming. In Intelligent Computing Theories and Application: 17th International Co nference, ICIC 2021, Shenzhen, China, August 12–15, 2021, Proceedings, Part II , pages 628–644. Springer, 2021
2021
-
[51]
L. Tao, J. Byrnes, V. Varshney, and Y. Li. Machine learning str ategies for the structure- property relationship of copolymers. iScience, 25(7):104585, 2022
2022
-
[52]
I. V. Tetko and O. Engkvist. From big data to artificial intelligenc e: chemoinformatics meets new challenges. Journal of Cheminformatics , 12:1–3, 2020
2020
-
[53]
Trucillo
P. Trucillo. Biomaterials for drug delivery and human applications. Materials, 17(2), 2024
2024
-
[54]
Vogel and J
G. Vogel and J. M. Weber. Inverse design of copolymers includin g stoichiometry and chain architecture. Chemical Science, 16(3):1161–1178, 2025
2025
-
[55]
Wilbraham, R
L. Wilbraham, R. S. Sprick, K. E. Jelfs, and M. A. Zwijnenburg. M apping binary copolymer property space with neural networks. Chemical Science, 10:4973–4984, 2019
2019
-
[56]
T. Yue, L. Tao, V. Varshney, and Y. Li. Benchmarking study of deep generative models for inverse polymer design. Digital Discovery , 4:910–926, 2025
2025
-
[57]
Y. Zhai, C. Li, and L. Gao. Degradable block copolymer-derived n anoporous membranes and their applications. Giant, 16:100183, 2023
2023
-
[58]
Zhang, J
F. Zhang, J. Zhu, R. Chiewvanichakorn, A. Shurbevski, H. Nag amochi, and T. Akutsu. A new approach to the design of acyclic chemical compounds using ske leton trees and integer linear programming. Applied Intelligence, 52(15):17058–17072, 2022
2022
-
[59]
Zhang, Y
S. Zhang, Y. Liu, and L. Xie. A universal framework for accura te and efficient geometric deep learning of molecular systems. Scientific Reports , 13(1):19171, 2023
2023
-
[60]
Zhang, J.-C
X. Zhang, J.-C. Daigle, and K. Zaghib. Comprehensive review of p olymer architecture for all-solid-state lithium rechargeable batteries. Materials, 13(11), 2020
2020
-
[61]
Y. Zhao, R. J. Mulder, S. Houshyar, and T. C. Le. A review on th e application of molecular descriptors and machine learning in polymer design. Polymer Chemistry , 14:3325–3346, 2023. 2LMM copolymer mv v5: May 29, 2026 28
2023
-
[62]
J. Zhu. Novel Methods for Chemical Compound Inference Based on Mach ine Learning and Mixed Integer Linear Programming . PhD thesis, Kyoto University, 9 2023
2023
-
[63]
J. Zhu, N. A. Azam, S. Cao, R. Ido, K. Haraguchi, L. Zhao, H. N agamochi, and T. Akutsu. Quadratic descriptors and reduction methods in a two-layered mod el for compound inference. Frontiers in Genetics , 15:1483490, 2025
2025
-
[64]
J. Zhu, N. A. Azam, K. Haraguchi, L. Zhao, and T. Akutsu. Com bining graph neural net- works and mixed integer linear programming for molecular inference u nder the two-layered model. In Proceedings of the 2025 9th International Conference on Com putational Biology and Bioinformatics, ICCBB ’25, pages 1–7, New York, NY, USA, 2026. Association for C omputi...
2025
-
[65]
J. Zhu, N. A. Azam, K. Haraguchi, L. Zhao, H. Nagamochi, and T . Akutsu. An inverse QSAR method based on linear regression and integer programming. Frontiers in Bioscience- Landmark, 27(6):188, 2022
2022
-
[66]
J. Zhu, M. Takekida, N. A. Azam, K. Haraguchi, L. Zhao, and T. Akutsu. Toward environment-sensitive molecular inference via mixed integer linear pr ogramming. ACS Omega, 10(40):46467–46481, 10 2025
2025
-
[67]
J. Zhu, C. Wang, A. Shurbevski, H. Nagamochi, and T. Akutsu. A novel method for inference of chemical compounds of cycle index two with desired properties ba sed on artificial neural networks and integer programming. Algorithms, 13(5):124, 2020. 2LMM copolymer mv v5: May 29, 2026 29 Appendix A Preliminary We give some notions and terminologies on graphs in...
2020
-
[68]
interior
For any subset V ′ ⊆ V (G), the graph G − V ′ is obtained by removing all vertices in V ′ along with any edges incident to them. An edge uv incident to a leaf-vertex v is called a leaf-edge. We denote the sets of leaf-vertices and leaf-edges in G by Vleaf (G) and Eleaf (G), respectively. For a graph G (possibly rooted), a sequence of graphs Gi,i ∈ Z+ is d...
2026
-
[69]
[22], we treat the two connecting-edges as a single edge e∗ 1 to simplify the representation of the polymer, as illustrated in Figure A11(b)
Following Ido et al. [22], we treat the two connecting-edges as a single edge e∗ 1 to simplify the representation of the polymer, as illustrated in Figure A11(b). The resulting graph is called the monomer representation of the polymer, and edge e∗ 1 is also called a link-edge. In what follows, we represent polymers by their monomer representations C. The ...
2026
-
[70]
dcp 1(C): the number |V (H)| − |VH| of non-hydrogen atoms in C
-
[71]
dcp 2(C): the number |V int(C)| of interior-vertices in C
-
[72]
This descriptor is only for the case of polymers
dcp 3(C): the number |Elnk(C)| of link-edges in C. This descriptor is only for the case of polymers
-
[73]
dcp 4(C): the average ms(C) of mass ∗ over all atoms in C; i.e., ms(C) ≜ 1 |V (H)| ∑ v∈V (H) mass∗ (α (v))
-
[74]
dcp i(C), i = 4 + d,d ∈ [1, 4]: the number dg H d(C) of non-hydrogen vertices v ∈ V (H) \VH of degree deg ⟨C⟩(v) = d in the hydrogen-suppressed chemical graph ⟨C⟩
-
[75]
dcp i(C), i = 8 + d,d ∈ [1, 4]: the number dg int d (C) of interior-vertices of interior-degree degCint(v) = d in the interior Cint = (V int(C),E int(C)) of C
-
[76]
dcp i(C),i = 12 +m,m ∈ [2, 3]: the number bd int m (C) of interior-edges with bond multiplicity m in C; i.e., bd int m (C) ≜ |{e ∈ Eint(C) |β (e) = m}|
-
[77]
dcp i(C),i = 14 + [a]int, a ∈ Λ int(Dπ ): the frequency na int a (C) = |Va(C) ∩V int(C)|of chemical element a in the set V int(C) of interior-vertices in C
-
[78]
dcp i(C),i = 14 + |Λ int(Dπ )|+ [a]ex, a ∈ Λ ex(Dπ ): the frequency na ex a (C) = |Va(C) ∩ V ex(C)| of chemical element a in the set V ex(C) of exterior-vertices in C
-
[79]
2LMM copolymer mv v5: May 29, 2026 35
dcp i(C), i = 14 + |Λ int(Dπ )|+ |Λ ex(Dπ )|+ [γ], γ ∈ Γ int(Dπ ): the frequency ec γ (C) of edge- configuration γ in the set Eint(C) of interior-edges in C. 2LMM copolymer mv v5: May 29, 2026 35
2026
-
[80]
This descriptor is only for the case of polymers
dcp i(C), i = 14 + |Λ int(Dπ )|+ |Λ ex(Dπ )|+ |Γ int(Dπ )|+ [γ], γ ∈ Γ lnk(Dπ ): the frequency ecγ (C) of edge-configuration γ in the set Elnk(C) of link-edges in C. This descriptor is only for the case of polymers
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.