EarthShift: a benchmark for measuring robustness to real-world distribution shifts in Earth observation
Pith reviewed 2026-06-29 08:39 UTC · model grok-4.3
The pith
Geospatial foundation models perform 15-20% worse out-of-distribution on Earth observation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
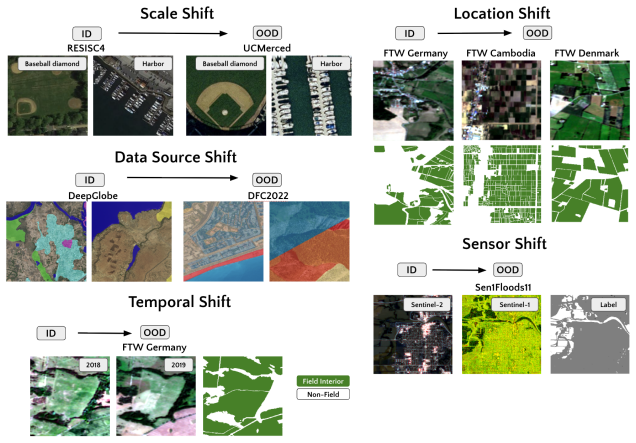
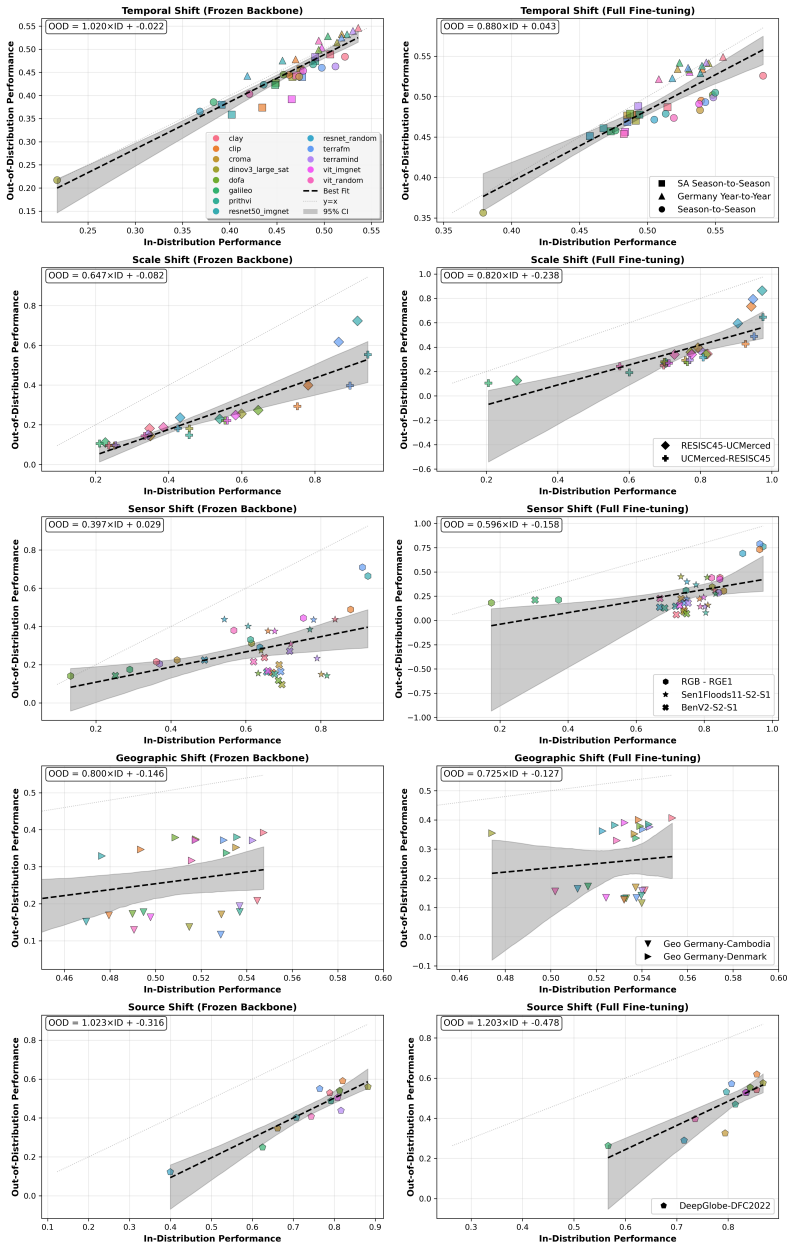
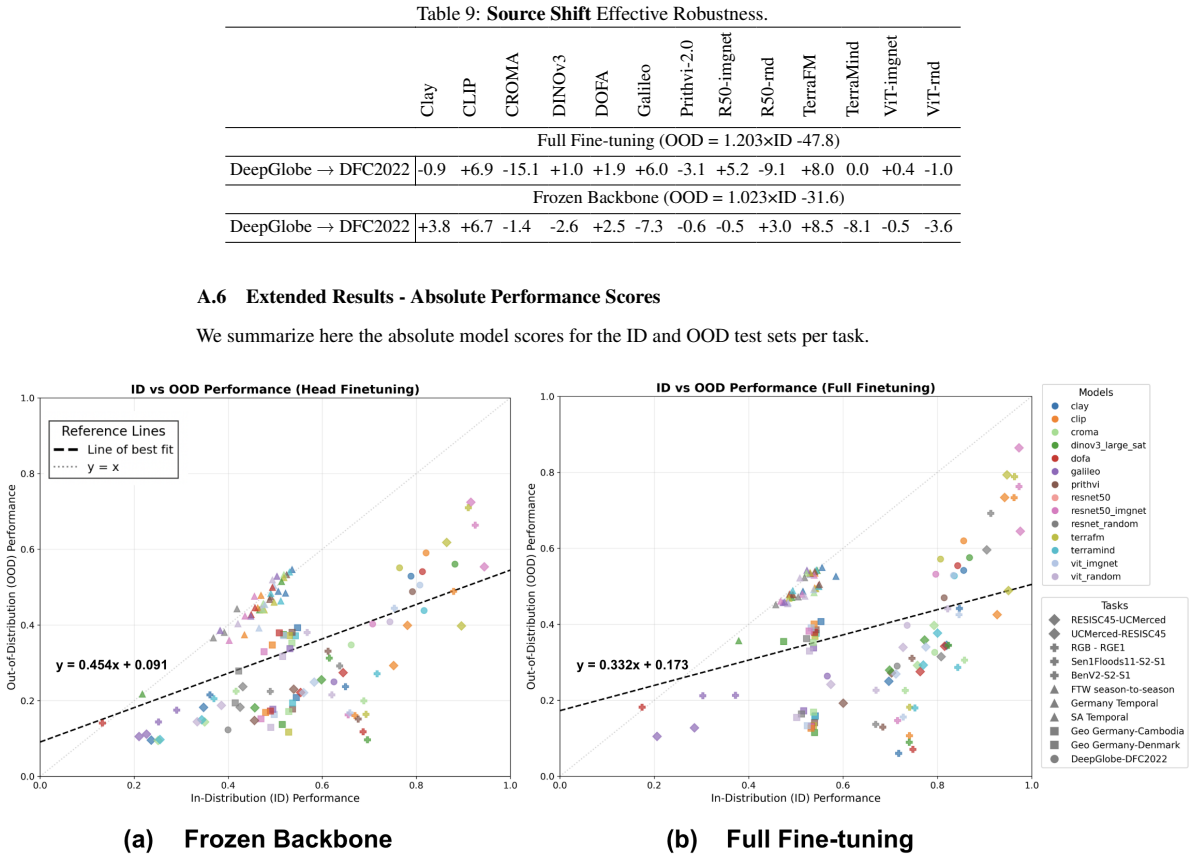
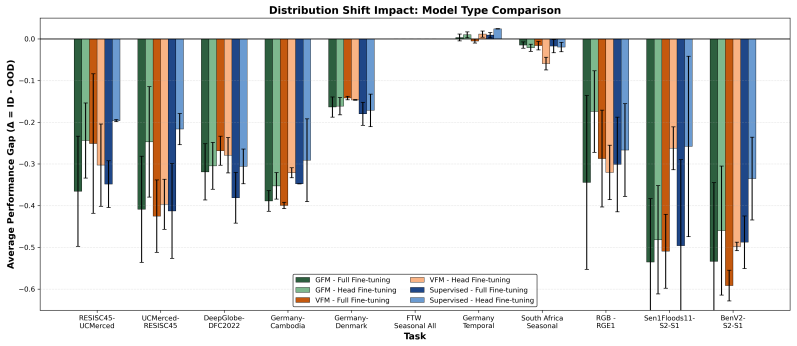
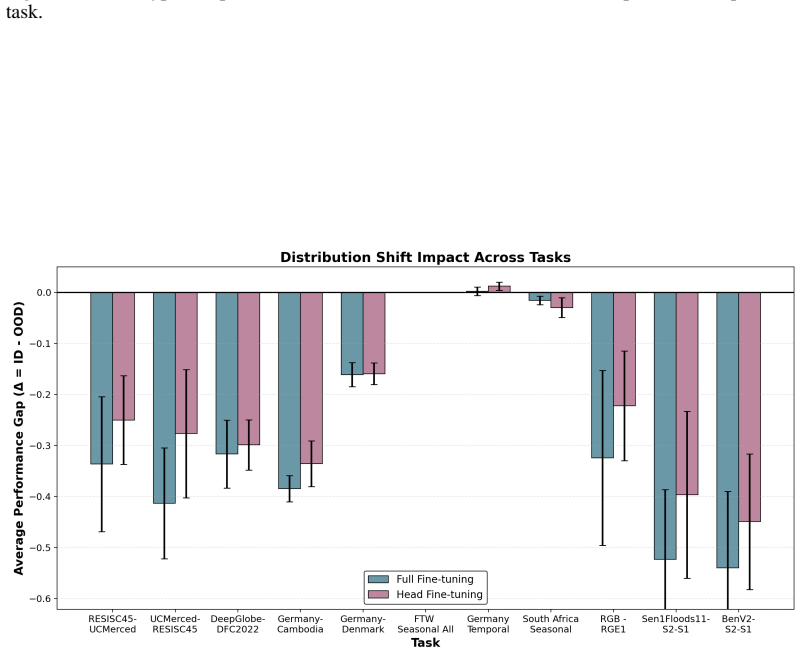
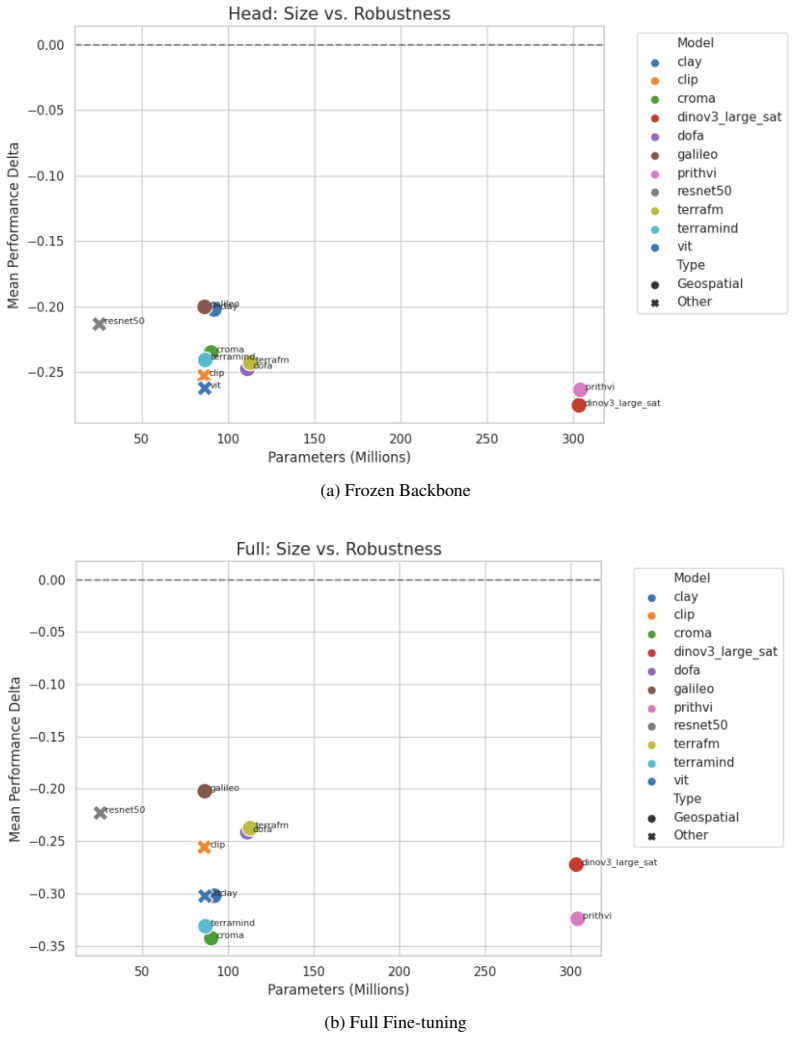
EarthShift enables measuring distributional robustness by comparing in- and out-of-distribution performance on paired datasets differing in sources, temporal windows, geographic locations, and sensors. Experiments demonstrate that eight geospatial foundation models perform 15-20% worse out-of-distribution on average across 11 tasks, with robustness levels comparable to generic vision foundation models and fully-supervised models.
What carries the argument
The EarthShift benchmark, which uses paired datasets from different sources, temporal windows, geographic locations, and sensors to compare in- and out-of-distribution performance.
If this is right
- Research should aim to improve distributional robustness in addition to in-distribution performance for foundation models.
- Robustness levels are similar between geospatial foundation models, generic vision models, and fully-supervised models.
- EarthShift provides a testbed for developing more reliable models for real-world remote sensing applications.
- The need for robustness improvements is highlighted as a key direction for future work.
Where Pith is reading between the lines
- Improving robustness could enhance the reliability of models in dynamic applications such as climate change tracking.
- The benchmark could be used to test specific techniques for mitigating particular shift types like sensor or temporal changes.
- Similar benchmarks might be valuable in other domains facing distribution shifts in imagery data.
Load-bearing premise
The paired datasets from different sources, temporal windows, geographic locations, and sensors accurately capture the distribution shifts models will encounter in real-world deployment scenarios.
What would settle it
A new model achieving similar performance on both in-distribution and out-of-distribution pairs within EarthShift would challenge the claim of a general robustness deficit.
Figures
read the original abstract
Current Earth observation benchmarks focus on measuring performance on diverse tasks and applications, typically measuring generalization in-distribution. But when models are deployed, they must generalize to myriad out-of-distribution scenarios, such as new time periods, geographies, scales, and sensors. We introduce EarthShift: the first public testbed for benchmarking robustness across multiple realistic distribution shifts encountered in remote sensing. EarthShift enables users to measure distributional robustness by comparing performance in- and out-of-distribution using datasets from paired datasets from different sources, temporal windows, geographic locations, and sensors. Our experiments on 8 geospatial foundation models (GFMs) and 11 tasks covering 5 shift types show that GFMs consistently perform 15-20% worse out-of-distribution on average regardless of model architecture, size, pre-training or fine-tuning strategy. We show that GFM robustness is similar to that of generic vision foundation models, and even fully-supervised models. This highlights a need for future research to strive for improvements in distributional robustness, not just performance, which can be benchmarked using EarthShift. We release our code and datasets to provide a testbed to guide future work to create foundation models that are robust and reliable in real-world applications. Code and data for EarthShift are available at: https://earthshift.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EarthShift, the first public benchmark for measuring robustness of geospatial foundation models (GFMs) to realistic distribution shifts in Earth observation. It constructs paired in-distribution (ID) and out-of-distribution (OOD) datasets differing in sources, temporal windows, geographic locations, and sensors across 5 shift types. Experiments on 8 GFMs and 11 tasks report a consistent 15-20% average performance drop OOD, independent of architecture, size, pre-training, or fine-tuning, and comparable to generic vision models and fully supervised baselines. The work releases code and datasets to support future robustness research.
Significance. If the reported OOD drops can be attributed to the intended shifts, the benchmark provides a valuable, reproducible testbed that shifts focus from in-distribution accuracy to distributional robustness in remote sensing. The public release of paired datasets, code, and the testbed itself is a concrete strength that enables community follow-up and falsifiable comparisons.
major comments (1)
- [Dataset construction / Experiments] § on dataset construction and pairing (described in abstract and methods): The central claim of a 15-20% OOD drop 'regardless of model architecture, size, pre-training or fine-tuning strategy' requires that the measured gaps arise from the intended shifts rather than incidental mismatches. No quantitative controls, statistics, or ablations are reported verifying that spatial resolution, class balance, or annotation quality are matched within each ID/OOD pair. Without such evidence, the performance gap cannot be confidently attributed to distributional robustness alone.
minor comments (1)
- [Abstract] Abstract: the 15-20% figure should explicitly state the performance metric (e.g., accuracy, mIoU, F1) and the precise aggregation method across the 11 tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Dataset construction / Experiments] § on dataset construction and pairing (described in abstract and methods): The central claim of a 15-20% OOD drop 'regardless of model architecture, size, pre-training or fine-tuning strategy' requires that the measured gaps arise from the intended shifts rather than incidental mismatches. No quantitative controls, statistics, or ablations are reported verifying that spatial resolution, class balance, or annotation quality are matched within each ID/OOD pair. Without such evidence, the performance gap cannot be confidently attributed to distributional robustness alone.
Authors: We agree that explicit verification is required to attribute the observed gaps to the intended distribution shifts. In the revised manuscript we will add a new subsection with quantitative controls for each ID/OOD pair, reporting (i) spatial-resolution statistics (mean, std, and range in meters), (ii) class-balance ratios and Earth-mover distance between label distributions, and (iii) annotation-quality proxies (e.g., inter-source label agreement or expert review scores where available). These statistics will be computed directly from the released paired datasets and will be accompanied by a short ablation confirming that performance gaps remain after subsampling to enforce exact resolution and class-balance matching. We believe this addition will allow confident attribution to distributional robustness. revision: yes
Circularity Check
No circularity: results are direct empirical measurements on released paired datasets
full rationale
The paper constructs paired ID/OOD datasets from different sources, times, locations, and sensors, then reports measured performance gaps (15-20% OOD drop) across 8 GFMs and 11 tasks. These are straightforward empirical computations with no equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The central claim reduces only to running models on the benchmark data and averaging accuracies, which is self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Domain adaptation for the classification of remote sensing data: An overview of recent advances.IEEE Geoscience and Remote Sensing Magazine, 4(2):41–57, 2016
Devis Tuia, Claudio Persello, and Lorenzo Bruzzone. Domain adaptation for the classification of remote sensing data: An overview of recent advances.IEEE Geoscience and Remote Sensing Magazine, 4(2):41–57, 2016
2016
-
[2]
Position: Mission critical–satellite data is a distinct modality in machine learning
Esther Rolf, Konstantin Klemmer, Caleb Robinson, and Hannah Kerner. Position: Mission critical–satellite data is a distinct modality in machine learning. InForty-first International Conference on Machine Learning
-
[3]
Geo-bench-2: From performance to capability, rethinking evaluation in geospatial ai, 2026
Naomi Simumba, Nils Lehmann, Paolo Fraccaro, Hamed Alemohammad, Geeth De Mel, Salman Khan, Manil Maskey, Nicolas Longepe, Xiao Xiang Zhu, Hannah Kerner, Juan Bernabe- Moreno, and Alexandre Lacoste. Geo-bench-2: From performance to capability, rethinking evaluation in geospatial ai, 2026
2026
-
[4]
Benchmarking neural network robustness to common corruptions and perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. InProceedings of the International Conference on Learning Representations, 2019
2019
-
[5]
Temme, Jonas Rauber, Heiko H
Robert Geirhos, Carlos R. Temme, Jonas Rauber, Heiko H. Schütt, Matthias Bethge, and Felix A. Wichmann. Generalisation in humans and deep neural networks.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[6]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InProceedings of the International Conference on Learning Representations, 2017
2017
-
[7]
Wichmann, and Wieland Brendel
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. InProceedings of the International Conference on Learning Representations, 2018
2018
-
[8]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), October 2017
2017
-
[9]
Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016
2016
-
[10]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. InEuropean Conference on Computer Vision (ECCV), pages 443–450. Springer, 2016
2016
-
[11]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization. InarXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[12]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[13]
WILDS: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weixin Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. WILDS: A benchmark of in-the-wild distribution shifts. InInternational Conference on Machine Learning, pages 5637–5664. PMLR, 2021
2021
-
[14]
Evaluating machine accuracy on ImageNet
Vaishaal Shankar, Rebecca Roelofs, Horia Mania, Alex Fang, Benjamin Recht, and Ludwig Schmidt. Evaluating machine accuracy on ImageNet. InInternational Conference on Machine Learning, pages 8634–8644. PMLR, 2020. 10
2020
-
[15]
ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.Advances in Neural Information Processing Systems, 32, 2019
Andrei Barbu, David Mayo, Julian Alverio, William Luo, Chenyun Wang, Dan Gutfreund, Joshua Tenenbaum, and Boris Katz. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[16]
Sahil Sachdeva, Ivan Lopez, Chandrashekhar Biradar, and David Lobell. A distribution shift benchmark for small-holder agroforestry: Do foundation models improve geographic gener- alization? InNeurIPS 2024 Workshop on Tackling Climate Change with Machine Learning, 2024
2024
-
[17]
Measuring robustness to natural distribution shifts in image classification
Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. Measuring robustness to natural distribution shifts in image classification. InAdvances in Neural Information Processing Systems, volume 33, pages 18583–18599, 2020
2020
-
[18]
Assessing out-of-domain generalization for robust building damage detection.arXiv preprint, 2020
Veit Benson and Alexander Ecker. Assessing out-of-domain generalization for robust building damage detection.arXiv preprint, 2020
2020
-
[19]
Multi-region transfer learning for segmen- tation of crop field boundaries in satellite images with limited labels
Hannah Kerner, Siddharth Sundar, and Mohit Satish. Multi-region transfer learning for segmen- tation of crop field boundaries in satellite images with limited labels. InAAAI Conference on Artificial Intelligence (AAAI) Workshops, 2023
2023
-
[20]
Geocrossbench: Cross-band generalization for remote sensing.arXiv preprint arXiv:2511.02831, 2025
Hakob Tamazyan, Ani Vanyan, Alvard Barseghyan, Anna Khosrovyan, Evan Shelhamer, and Hrant Khachatrian. Geocrossbench: Cross-band generalization for remote sensing.arXiv preprint arXiv:2511.02831, 2025
-
[21]
Earthnets: Empowering AI in earth observation.arXiv preprint arXiv:2210.04936, 2022
Zhitong Xiong, Fahong Zhang, Yi Wang, Yilei Shi, and Xiao Xiang Zhu. Earthnets: Empowering AI in earth observation.arXiv preprint arXiv:2210.04936, 2022
-
[22]
Geo-bench: Toward foundation models for earth monitoring, 2023
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan David Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Andrew Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, Mehmet Gunturkun, Gabriel Huang, David Vazquez, Dava Newman, Yoshua Bengio, Stefano Ermon, and Xiao Xiang Zhu. Geo-bench: Toward foundation models for earth monitoring, 2023
2023
-
[23]
Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017
2017
-
[24]
Bag-of-visual-words and spatial extensions for land-use classifi- cation
Yi Yang and Shawn Newsam. Bag-of-visual-words and spatial extensions for land-use classifi- cation. InACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2010
2010
-
[25]
Lavista Ferres, and Jennifer Marcus
Hannah Kerner, Snehal Chaudhari, Aninda Ghosh, Caleb Robinson, Adeel Ahmad, Eddie Choi, Nathan Jacobs, Chris Holmes, Matthias Mohr, Rahul Dodhia, Juan M. Lavista Ferres, and Jennifer Marcus. Fields of the world: A machine learning benchmark dataset for global agricultural field boundary segmentation, 2024
2024
-
[26]
Kai Norman Clasen, Leonard Hackel, Tom Burgert, Gencer Sumbul, Begüm Demir, and V olker Markl. reBEN: Refined BigEarthNet dataset for remote sensing image analysis.arXiv preprint arXiv:2407.03653, 2024
-
[27]
Sen1floods11: a georeferenced dataset to train and test deep learning flood algorithms for sentinel-1
Derrick Bonafilia, Beth Tellman, Tyler Anderson, and Erica Issenberg. Sen1floods11: a georeferenced dataset to train and test deep learning flood algorithms for sentinel-1. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 835–845, 2020
2020
-
[28]
Do imagenet classifiers generalize to imagenet?, 2019
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet?, 2019
2019
-
[29]
Deepglobe 2018: A challenge to parse the earth through satellite images
Ilke Demir, Krzysztof Koperski, David Lindenbaum, Guan Pang, Jing Huang, Saikat Basu, Forest Hughes, Devis Tuia, and Ramesh Raskar. Deepglobe 2018: A challenge to parse the earth through satellite images. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018
2018
-
[30]
Data fusion contest 2022 (dfc2022), January 2022
Ronny Hänsch, Claudio Persello, Gemine Vivone, Javiera Castillo Navarro, Alexandre Boulch, Sebastien Lefevre, and Bertrand Le Saux. Data fusion contest 2022 (dfc2022), January 2022. 11
2022
-
[31]
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J Stewart, Joëlle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, and Xiao Xiang Zhu. Neural plasticity-inspired foundation model for observing the Earth crossing modalities.arXiv preprint arXiv:2403.15356, 2024
-
[32]
Anthony Fuller, Koreen Millard, and James R. Green. Croma: Remote sensing representations with contrastive radar-optical masked autoencoders, 2023
2023
-
[33]
Clay foundation model: An open source ai model for earth, 2024
Clay Foundation. Clay foundation model: An open source ai model for earth, 2024. Apache-2.0 License
2024
-
[34]
Prithvi-eo-2.0: A versatile multi-temporal foundation model for earth observation applications, 2025
Daniela Szwarcman, Sujit Roy, Paolo Fraccaro, Þorsteinn Elí Gíslason, Benedikt Blumenstiel, Rinki Ghosal, Pedro Henrique de Oliveira, Joao Lucas de Sousa Almeida, Rocco Sedona, Yanghui Kang, Srija Chakraborty, Sizhe Wang, Carlos Gomes, Ankur Kumar, Myscon Truong, Denys Godwin, Hyunho Lee, Chia-Yu Hsu, Ata Akbari Asanjan, Besart Mujeci, Disha Shid- ham, Tr...
2025
-
[35]
Muhammad Sohail Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Muham- mad Haris Khan, Rao Muhammad Anwer, Jorma Laaksonen, Fahad Shahbaz Khan, and Salman Khan. Terrafm: A scalable foundation model for unified multisensor earth observation.arXiv preprint arXiv:2506.06281, 2025
-
[36]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
2025
-
[37]
Green, Evan Shelhamer, Hannah Kerner, and David Rolnick
Gabriel Tseng, Anthony Fuller, Marlena Reil, Henry Herzog, Patrick Beukema, Favyen Bastani, James R. Green, Evan Shelhamer, Hannah Kerner, and David Rolnick. Galileo: Learning global and local features of many remote sensing modalities, 2025
2025
-
[38]
Terramind: Large-scale generative multimodality for earth observation, 2025
Johannes Jakubik, Felix Yang, Benedikt Blumenstiel, Erik Scheurer, Rocco Sedona, Stefano Maurogiovanni, Jente Bosmans, Nikolaos Dionelis, Valerio Marsocci, Niklas Kopp, Rahul Ramachandran, Paolo Fraccaro, Thomas Brunschwiler, Gabriele Cavallaro, Juan Bernabe- Moreno, and Nicolas Longépé. Terramind: Large-scale generative multimodality for earth observation, 2025
2025
-
[39]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
2015
-
[40]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021
2021
-
[41]
Ramesh, Gabriel Goh, Sandish Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandish Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[42]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[43]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255. IEEE, 2009
2009
-
[44]
S. T. Brown, P. Buitrago, E. Hanna, S. Sanielevici, R. Scibek, and N. A. Nystrom. Bridges-2: A platform for rapidly-evolving and data intensive research. InPractice and Experience in Advanced Research Computing, pages 1–4, 2021. 12
2021
-
[45]
licence ouverte
Douglas M. Jennewein, Johnathan Lee, Chris Kurtz, Will Dizon, Ian Shaeffer, Alan Chapman, Alejandro Chiquete, Josh Burks, Amber Carlson, Natalie Mason, Arhat Kobwala, Thirugnanam Jagadeesan, Praful Barghav, Torey Battelle, Rebecca Belshe, Debra McCaffrey, Marisa Brazil, Chaitanya Inumella, Kirby Kuznia, Jade Buzinski, Sean Dudley, Dhruvil Shah, Gil Speyer...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.