Enhancing Factuality through Consensus and Consistency in Summarization Using Minimum Bayes Risk Decoding
Pith reviewed 2026-06-29 07:36 UTC · model grok-4.3
The pith
Reranking summaries by source consistency plus consensus among candidates improves factuality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
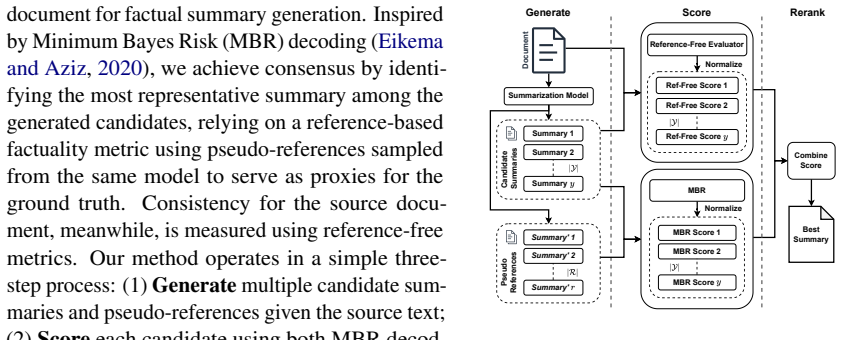
ConSUM reranks candidate summaries by establishing consensus via Minimum Bayes Risk decoding over the set of generated summaries while enforcing consistency through factuality-aware metrics that compare each summary to the source document, resulting in outputs that are competitive with existing methods and preferred in human evaluations.
What carries the argument
Minimum Bayes Risk decoding applied to the set of generated candidate summaries to quantify consensus, combined with factuality metrics that score alignment to the source document.
If this is right
- The selected summaries achieve higher human preference scores than prior reranking systems.
- Automatic factuality metrics show performance on par with existing methods.
- The method applies to any summarization model that can generate multiple candidates.
- Consensus is computed without additional training or external models beyond the factuality metrics.
Where Pith is reading between the lines
- The same dual-criterion reranking could be tested on tasks like question answering or dialogue generation where multiple outputs are available.
- If consensus among candidates correlates with factuality, it might reduce the need for expensive reference-based metrics in some settings.
- Extending the approach to longer documents would require checking whether MBR consensus remains stable as candidate length increases.
Load-bearing premise
That measuring agreement among multiple generated candidates will reliably identify summaries that are more faithful to the source than source-only selection.
What would settle it
A direct comparison where summaries chosen by the consensus-plus-consistency method receive lower factuality scores or human ratings than those chosen by source-only reranking on the same set of candidates.
Figures

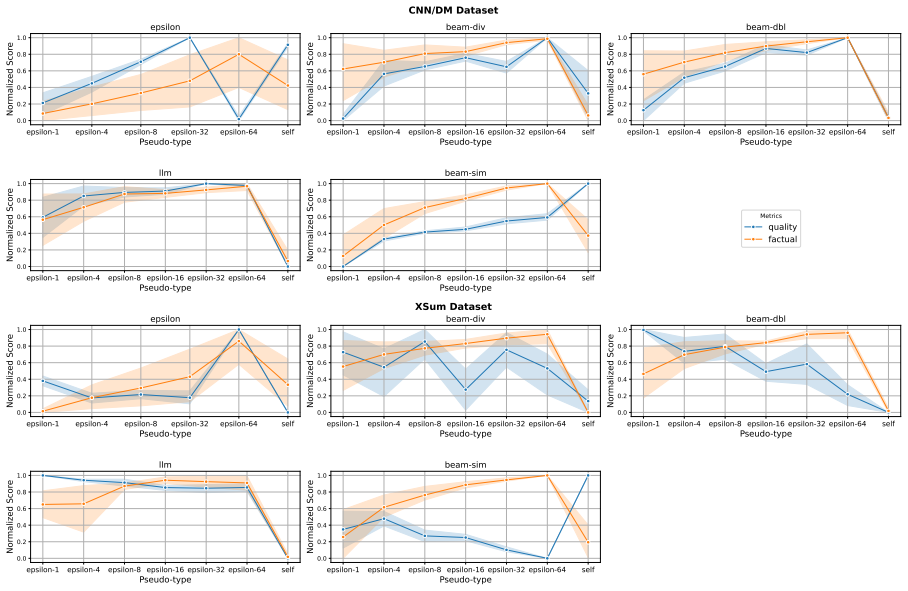
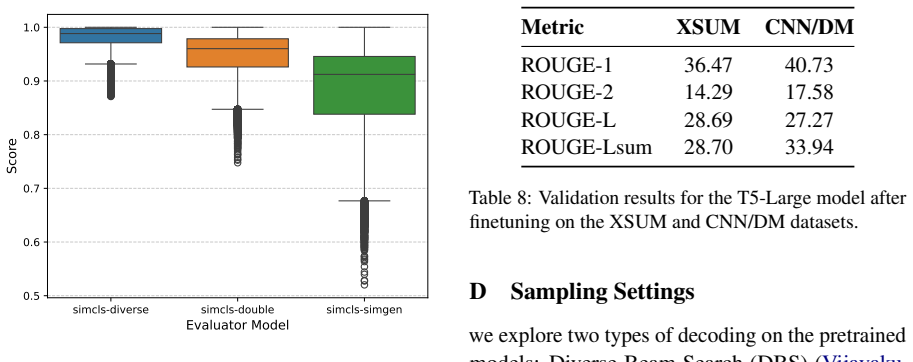

read the original abstract
Improving the quality of model-generated summaries, especially factuality, the accuracy of a summary with respect to its source content, remains a challenge. While reranking could select the optimal output from multiple generated candidates, it is limited to only using the source as guidance, resulting in unreliable summaries. To address this limitation, we propose ConSUM that reranks candidate summaries by considering two factors: consistency to the source document and consensus among the other candidates. Consensus is established using Minimum Bayes Risk (MBR) decoding over the set of generated summaries, while ensuring consistency by employing factuality-aware metrics that compare the summary against the source. Rigorous testing demonstrates that our system is competitive with existing methods, with human evaluations further confirming that its generated summaries are preferred over those from other systems. Our code is available at https://github.com/naist-nlp/ConSUM .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConSUM, a reranking approach for model-generated summaries that combines consistency to the source document (via factuality-aware metrics) with consensus among multiple candidate summaries (via Minimum Bayes Risk decoding). It claims this yields summaries competitive with existing methods and preferred in human evaluations, with code released at a GitHub link.
Significance. If the empirical results hold and the MBR term demonstrably adds value beyond source metrics, the method would provide a practical, reproducible technique for improving factuality in summarization without requiring new model training. The open code is a clear strength for verification.
major comments (2)
- [Abstract] Abstract: the central claim that 'rigorous testing demonstrates that our system is competitive with existing methods' and that 'human evaluations further confirming' preference is unsupported by any numbers, baselines, datasets, or error analysis in the provided text, preventing assessment of whether the reported gains are real or meaningful.
- Abstract / method description: the claim that combining source-consistency metrics with MBR consensus improves factuality rests on the untested assumption that the MBR term supplies information orthogonal to the source metrics. No ablations isolating the consensus contribution (or showing that MBR does not simply reinforce correlated model errors) are described, which is load-bearing for the stated advantage over source-only reranking.
minor comments (1)
- [Abstract] Abstract: the description of the utility function inside MBR and the specific factuality metrics used could be stated more explicitly even at this level.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address each major comment below, indicating planned revisions where appropriate. The full manuscript contains the empirical results referenced in the abstract; we will strengthen the abstract and add requested analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'rigorous testing demonstrates that our system is competitive with existing methods' and that 'human evaluations further confirming' preference is unsupported by any numbers, baselines, datasets, or error analysis in the provided text, preventing assessment of whether the reported gains are real or meaningful.
Authors: Abstracts are intentionally concise and do not typically embed full numerical results, baselines, or error analyses, which are instead reported in the main body (Sections 4 and 5, with tables comparing against multiple baselines on CNN/DM and XSum, plus human preference scores). The claims in the abstract are therefore summaries of those detailed findings rather than standalone assertions. To improve clarity for readers who encounter only the abstract, we will revise it to include one or two key quantitative results (e.g., factuality metric gains and human preference rates) while preserving length constraints. revision: yes
-
Referee: [—] Abstract / method description: the claim that combining source-consistency metrics with MBR consensus improves factuality rests on the untested assumption that the MBR term supplies information orthogonal to the source metrics. No ablations isolating the consensus contribution (or showing that MBR does not simply reinforce correlated model errors) are described, which is load-bearing for the stated advantage over source-only reranking.
Authors: The referee correctly identifies that the current manuscript does not present explicit ablations that isolate the incremental contribution of the MBR consensus term over source-consistency metrics alone, nor does it directly test for reinforcement of correlated model errors. This is a substantive gap for the central claim. We will add these ablations in the revision (new subsection comparing source-only reranking, MBR-only, and the combined ConSUM objective, plus analysis of error overlap across candidates) to demonstrate orthogonality where it exists. revision: yes
Circularity Check
No circularity: empirical reranking method with external validation
full rationale
The paper presents an empirical proposal (ConSUM) that combines existing MBR decoding for candidate consensus with standard factuality metrics against the source document, followed by experimental comparisons and human evaluation. No derivation chain, equations, or fitted parameters are described that reduce by construction to the method's own inputs. Reliance on prior MBR literature and external metrics constitutes normal citation rather than self-referential load-bearing. The central claim rests on empirical results, not on any self-definition or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amanda Bertsch, Alex Xie, Graham Neubig, and Matthew Gormley. 2023. https://doi.org/10.18653/v1/2023.bigpicture-1.9 It's MBR All the Way Down : Modern Generation Techniques Through the Lens of Minimum Bayes Risk . In Proceedings of the Big Picture Workshop , pages 108--122, Singapore. Association for Computational Linguistics
-
[2]
Yanran Chen and Steffen Eger. 2023. https://doi.org/10.1162/tacl_a_00576 MENLI : Robust Evaluation Metrics from Natural Language Inference . Transactions of the Association for Computational Linguistics, 11:804--825
-
[3]
Julius Cheng and Andreas Vlachos. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.767 Faster Minimum Bayes Risk Decoding with Confidence-based Pruning . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 12473--12480, Singapore. Association for Computational Linguistics
-
[4]
Anshuman Chhabra, Hadi Askari, and Prasant Mohapatra. 2024. https://doi.org/10.18653/v1/2024.naacl-short.1 Revisiting zero-shot abstractive summarization in the era of large language models from the perspective of position bias . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan...
-
[5]
Hiroyuki Deguchi, Yusuke Sakai, Hidetaka Kamigaito, and Taro Watanabe. 2024. https://doi.org/10.18653/v1/2024.emnlp-demo.37 mbrs: A library for minimum B ayes risk decoding . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 351--362, Miami, Florida, USA. Association for Computational L...
-
[6]
Tanay Dixit, Fei Wang, and Muhao Chen. 2023. https://doi.org/10.18653/v1/2023.acl-short.78 Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ( Volume 2: Short Papers ) , pages 902--913, Toronto, Canada. Association for Computati...
-
[7]
Bryan Eikema and Wilker Aziz. 2020. https://doi.org/10.18653/v1/2020.coling-main.398 Is MAP Decoding All You Need ? The Inadequacy of the Mode in Neural Machine Translation . In Proceedings of the 28th International Conference on Computational Linguistics , pages 4506--4520, Barcelona, Spain (Online). International Committee on Computational Linguistics
-
[8]
Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev
Alexander R. Fabbri, Wojciech Kry \'s ci \'n ski, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. 2021. https://doi.org/10.1162/tacl_a_00373 SummEval : Re-evaluating Summarization Evaluation . Transactions of the Association for Computational Linguistics, 9:391--409
-
[9]
Markus Freitag, Behrooz Ghorbani, and Patrick Fernandes. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.617 Epsilon Sampling Rocks : Investigating Sampling Strategies for Minimum Bayes Risk Decoding for Machine Translation . In Findings of the Association for Computational Linguistics : EMNLP 2023 , pages 9198--9209, Singapore. Association for Comp...
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. https://openreview.net/forum?id=XPZIaotutsD Deberta: Decoding-enhanced bert with disentangled attention . In International Conference on Learning Representations
2021
-
[12]
John Hewitt, Christopher Manning, and Percy Liang. 2022. https://doi.org/10.18653/v1/2022.findings-emnlp.249 Truncation sampling as language model desmoothing . In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 3414--3427, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[13]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. https://openreview.net/forum?id=rygGQyrFvH The curious case of neural text degeneration . In International Conference on Learning Representations
2020
-
[14]
Hidetaka Kamigaito, Hiroyuki Deguchi, Yusuke Sakai, Katsuhiko Hayashi, and Taro Watanabe. 2025. https://aclanthology.org/2025.acl-long.1410/ Diversity explains inference scaling laws: Through a case study of minimum B ayes risk decoding . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pa...
2025
-
[15]
M.G. Kendall. 1948. https://books.google.co.jp/books?id=hiBMAAAAMAAJ Rank Correlation Methods . C. Griffin
1948
-
[16]
Philipp Koehn. 2004. https://aclanthology.org/W04-3250/ Statistical significance tests for machine translation evaluation . In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 388--395, Barcelona, Spain. Association for Computational Linguistics
2004
-
[17]
Geza Kovacs, Daniel Deutsch, and Markus Freitag. 2024. https://doi.org/10.18653/v1/2024.wmt-1.109 Mitigating Metric Bias in Minimum Bayes Risk Decoding . In Proceedings of the Ninth Conference on Machine Translation , pages 1063--1094, Miami, Florida, USA. Association for Computational Linguistics
-
[18]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. https://doi.org/10.18653/v1/2020.acl-main.703 BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation , Translation , and Comprehension . In Proceedings of the 58th Annual Meeting of the Associ...
-
[19]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[20]
Yixin Liu, Budhaditya Deb, Milagro Teruel, Aaron Halfaker, Dragomir Radev, and Ahmed Hassan Awadallah. 2023. https://doi.org/10.18653/v1/2023.acl-long.844 On Improving Summarization Factual Consistency from Natural Language Feedback . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pag...
-
[21]
Yixin Liu and Pengfei Liu. 2021. https://doi.org/10.18653/v1/2021.acl-short.135 SimCLS : A Simple Framework for Contrastive Learning of Abstractive Summarization . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing ( Volume 2: Short Papers ) ...
-
[22]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. https://doi.org/10.18653/v1/2020.acl-main.173 On faithfulness and factuality in abstractive summarization . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906--1919, Online. Association for Computational Linguistics
-
[23]
Mathias Müller and Rico Sennrich. 2021. https://doi.org/10.18653/v1/2021.acl-long.22 Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translation . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing ( Volume 1: Lo...
-
[24]
Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, C a g lar Gu l c ehre, and Bing Xiang. 2016. https://doi.org/10.18653/v1/K16-1028 Abstractive text summarization using sequence-to-sequence RNN s and beyond . In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning , pages 280--290, Berlin, Germany. Association for Computatio...
-
[25]
Hardt, M., Recht, B., and Singer, Y
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. https://doi.org/10.18653/v1/D18-1206 Don`t Give Me the Details , Just the Summary ! Topic-Aware Convolutional Neural Networks for Extreme Summarization . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 1797--1807, Brussels, Belgium. Association for C...
-
[26]
Koki Natsumi, Hiroyuki Deguchi, Yusuke Sakai, Hidetaka Kamigaito, and Taro Watanabe. 2025. https://doi.org/10.18653/v1/2025.ijcnlp-short.39 Agreement-constrained probabilistic minimum B ayes risk decoding . In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Ass...
-
[27]
Ani Nenkova and Rebecca Passonneau. 2004. https://aclanthology.org/N04-1019/ Evaluating Content Selection in Summarization : The Pyramid Method . In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics : HLT - NAACL 2004 , pages 145--152, Boston, Massachusetts, USA. Associat...
2004
-
[28]
Atsumoto Ohashi, Ukyo Honda, Tetsuro Morimura, and Yuu Jinnai. 2024. https://doi.org/10.18653/v1/2024.naacl-short.38 On the True Distribution Approximation of Minimum Bayes - Risk Decoding . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies ( Volume 2: Short P...
-
[29]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2023. https://doi.org/10.48550/arXiv.1910.10683 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer . Preprint, arXiv:1910.10683
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1910.10683 2023
-
[30]
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. 2022. https://doi.org/10.18653/v1/2022.acl-long.309 SummaReranker : A Multi-Task Mixture-of-Experts Re-ranking Framework for Abstractive Summarization . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 4504--4524, Dublin, Ireland. Assoc...
-
[31]
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. 2023. https://doi.org/10.18653/v1/2023.findings-acl.529 Unsupervised summarization re-ranking . In Findings of the Association for Computational Linguistics: ACL 2023, pages 8341--8376, Toronto, Canada. Association for Computational Linguistics
-
[32]
Sangwon Ryu, Heejin Do, Yunsu Kim, Gary Lee, and Jungseul Ok. 2024. https://doi.org/10.18653/v1/2024.acl-long.319 Multi- Dimensional Optimization for Text Summarization via Reinforcement Learning . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 5858--5871, Bangkok, Thailand. Ass...
-
[33]
Alessandro Scir \`e , Karim Ghonim, and Roberto Navigli. 2024. https://doi.org/10.18653/v1/2024.findings-acl.841 FENICE : Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction . In Findings of the Association for Computational Linguistics : ACL 2024 , pages 14148--14161, Bangkok, Thailand. Association for Computat...
-
[34]
Jeewoo Sul and Yong Suk Choi. 2023. https://doi.org/10.18653/v1/2023.acl-short.56 Balancing Lexical and Semantic Quality in Abstractive Summarization . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ( Volume 2: Short Papers ) , pages 637--647, Toronto, Canada. Association for Computational Linguistics
-
[35]
Mirac Suzgun, Luke Melas-Kyriazi, and Dan Jurafsky. 2023. https://doi.org/10.18653/v1/2023.findings-acl.262 Follow the wisdom of the crowd: Effective text generation via minimum B ayes risk decoding . In Findings of the Association for Computational Linguistics: ACL 2023, pages 4265--4293, Toronto, Canada. Association for Computational Linguistics
-
[36]
Firas Trabelsi, David Vilar, Mara Finkelstein, and Markus Freitag. 2024. https://doi.org/10.48550/arXiv.2406.02832 Efficient Minimum Bayes Risk Decoding using Low-Rank Matrix Completion Algorithms . Preprint, arXiv:2406.02832
-
[37]
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Ashwin K. Vijayakumar, Michael Cogswell, Ramprasath R. Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. 2018. https://doi.org/10.48550/arXiv.1610.02424 Diverse Beam Search : Decoding Diverse Solutions from Neural Sequence Models . arXiv preprint. ArXiv:1610.02424 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.02424 2018
-
[38]
Joonho Yang, Seunghyun Yoon, ByeongJeong Kim, and Hwanhee Lee. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.3 FIZZ : Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 30--45, Miami, Florida, USA. Association for Computational Linguistics
-
[39]
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J. Liu. 2020. https://doi.org/10.48550/arXiv.1912.08777 PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization . Preprint, arXiv:1912.08777
-
[40]
Weinberger, and Yoav Artzi
Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. 2020. https://openreview.net/forum?id=SkeHuCVFDr Bertscore: Evaluating text generation with bert . In International Conference on Learning Representations
2020
-
[41]
Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B. Hashimoto. 2024. https://doi.org/10.1162/tacl_a_00632 Benchmarking Large Language Models for News Summarization . Transactions of the Association for Computational Linguistics, 12:39--57
-
[42]
Wei Zhao, Maxime Peyrard, Fei Liu, Yang Gao, Christian M. Meyer, and Steffen Eger. 2019. https://doi.org/10.18653/v1/D19-1053 MoverScore : Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference ...
-
[43]
Ming Zhong, Yang Liu, Da Yin, Yuning Mao, Yizhu Jiao, Pengfei Liu, Chenguang Zhu, Heng Ji, and Jiawei Han. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.131 Towards a Unified Multi - Dimensional Evaluator for Text Generation . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 2023--2038, Abu Dhabi, Unite...
-
[44]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[45]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.