ConMoE: Expert-Pool Consolidation via Prototype Reassignment for MoE Compression
Pith reviewed 2026-06-29 07:53 UTC · model grok-4.3
The pith
MoE compression succeeds by keeping fewer experts as reusable prototypes and remapping the rest deterministically without weight updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
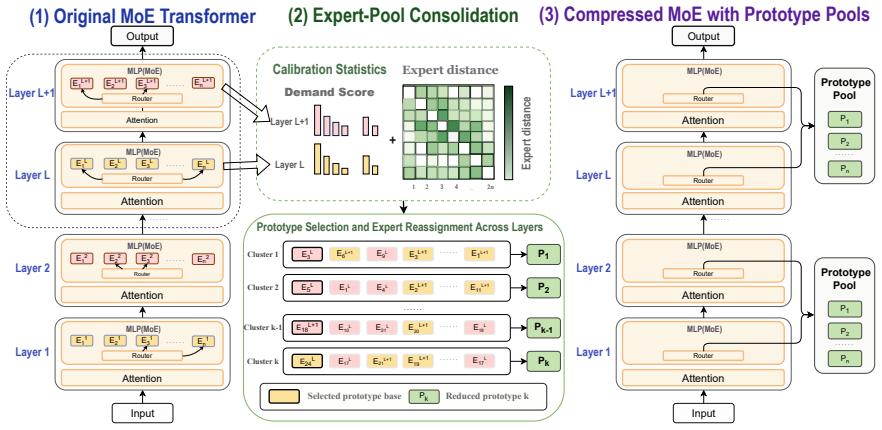
We formulate post-training MoE compression as expert-pool consolidation: retaining a smaller set of pretrained experts as reusable prototypes and deterministically remapping each original expert reference to one selected prototype. This view separates the reduced expert pool from the reuse structure that represents the original expert slots, and allows prototype sharing within local layer scopes while preserving the original router interface. We propose ConMoE, a train-free prototype remapping framework that selects retained experts using calibration-based contribution and replaceability signals, then redirects original expert calls to the selected prototypes without weight updates or post-c
What carries the argument
expert-pool consolidation via prototype reassignment, which uses calibration signals to choose retained experts and then applies deterministic remapping of all original expert calls
If this is right
- ConMoE matches or outperforms strong pruning and merging baselines in several settings on three pretrained MoE models.
- It achieves the best average score on deepseek-moe-16b-base at both 25 percent and 50 percent routed-expert reduction.
- It remains competitive on Qwen3-30B-A3B and OLMoE-1B-7B-0125 under the same reductions.
- Deterministic reassignment is the most stable component of the method.
- Broader cross-layer sharing and post-hoc weight fusion show model-dependent effects.
Where Pith is reading between the lines
- The results imply that many expert behaviors in these models overlap enough to be captured by a smaller prototype pool selected from the original set.
- If the calibration signals prove reliable across more models, the same selection step could be reused for other compression ratios or for combining with quantization.
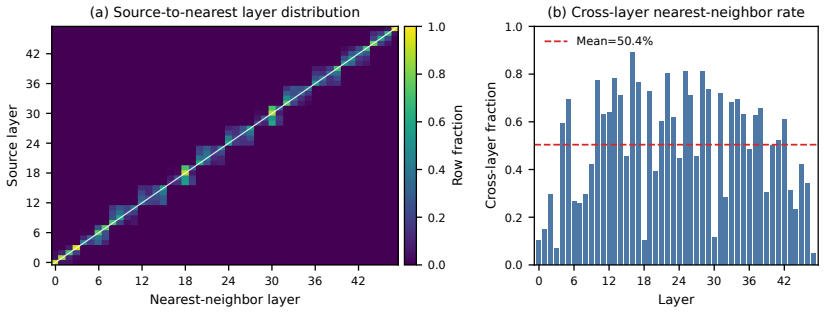
- The separation of pool size from reuse structure opens a path to layer-specific sharing ratios without changing the router.
- Applying the same remapping logic at inference time on hardware with limited expert cache could reduce loading costs.
Load-bearing premise
Calibration-based contribution and replaceability signals from a small dataset are enough to pick a reusable prototype set whose deterministic remapping preserves model behavior without weight updates or fine-tuning.
What would settle it
A clear performance drop on a held-out evaluation set after applying the remapping to a new pretrained MoE model, compared with the original model and with pruning baselines, would show the method does not preserve behavior.
Figures
read the original abstract
Mixture-of-Experts (MoE) language models reduce per-token computation but still require storing and serving all experts, making deployment memory-intensive. Existing post-training compression methods mainly shrink this cost by pruning experts or merging their weights. We formulate post-training MoE compression as expert-pool consolidation: retaining a smaller set of pretrained experts as reusable prototypes and deterministically remapping each original expert reference to one selected prototype. This view separates the reduced expert pool from the reuse structure that represents the original expert slots, and allows prototype sharing within local layer scopes while preserving the original router interface. We propose ConMoE, a train-free prototype remapping framework that selects retained experts using calibration-based contribution and replaceability signals, then redirects original expert calls to the selected prototypes without weight updates or post-compression fine-tuning. Experiments on three pretrained MoE language models show that ConMoE matches or outperforms strong pruning and merging baselines in several settings, achieving the best average score on deepseek-moe-16b-base at both 25% and 50% routed-expert reduction, while remaining competitive on Qwen3-30B-A3B and OLMoE-1B-7B-0125. Ablations indicate that deterministic reassignment is the most stable component, whereas broader cross-layer sharing and post-hoc weight fusion are model-dependent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConMoE, a train-free post-training compression framework for Mixture-of-Experts (MoE) language models. It reformulates compression as expert-pool consolidation: a smaller set of pretrained experts is retained as prototypes based on calibration-derived contribution and replaceability signals, after which each original expert reference is deterministically remapped to one of the prototypes. This preserves the original router interface, permits local layer-scope prototype sharing, and requires no weight updates or fine-tuning. Experiments on DeepSeek-MoE-16B-Base, Qwen3-30B-A3B, and OLMoE-1B-7B-0125 report that ConMoE matches or exceeds strong pruning and merging baselines at 25% and 50% routed-expert reduction, attaining the best average score on DeepSeek-MoE-16B-Base at both ratios; ablations indicate deterministic reassignment is the most stable component while cross-layer sharing and weight fusion are model-dependent.
Significance. If the empirical claims hold under detailed scrutiny, the work supplies a lightweight, training-free compression technique that decouples the reduced expert pool from the reuse mapping and keeps the router unchanged. The explicit separation of prototype selection from remapping structure, together with the reported stability of the deterministic component, constitutes a practical contribution for memory-constrained MoE deployment. The purely empirical, calibration-driven nature and the component-wise ablations are strengths that allow direct comparison with existing pruning/merging methods.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that ConMoE 'matches or outperforms' baselines and achieves 'the best average score' on DeepSeek-MoE-16B-Base rests on high-level summary only; no numerical tables, exact baseline scores, dataset sizes, number of runs, or error bars are referenced, so the magnitude and statistical reliability of the reported gains cannot be assessed.
- [§3] §3 (Method): the replaceability and contribution signals are computed on an unspecified small calibration corpus; because expert activations are known to be input-dependent, the manuscript must demonstrate that these proxies remain predictive of functional equivalence under deterministic remapping on held-out data, or the train-free preservation claim is unsupported.
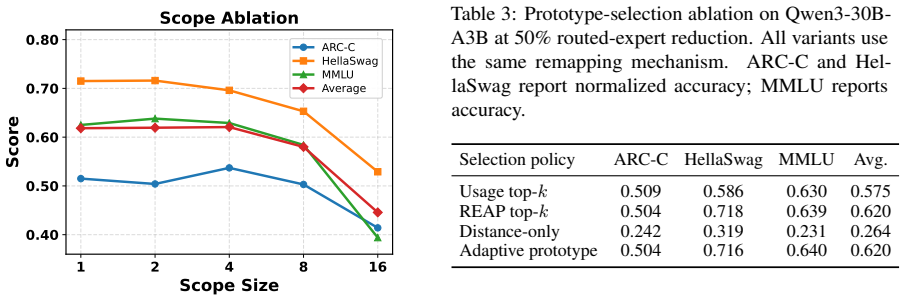
- [§4.3] §4.3 (Ablations): the statement that 'deterministic reassignment is the most stable component' is presented without quantitative comparison of performance variance across random seeds or across different calibration-set sizes; this directly affects the reliability of the core design choice.
minor comments (2)
- [§3] Notation for the contribution and replaceability scores should be defined once with explicit formulas rather than described only in prose.
- [§4] The manuscript should state the exact calibration corpus (size, domain, number of tokens) used for all reported runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to improve clarity, specificity, and empirical support in the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that ConMoE 'matches or outperforms' baselines and achieves 'the best average score' on DeepSeek-MoE-16B-Base rests on high-level summary only; no numerical tables, exact baseline scores, dataset sizes, number of runs, or error bars are referenced, so the magnitude and statistical reliability of the reported gains cannot be assessed.
Authors: We agree that the abstract and opening of §4 would benefit from explicit references to numerical results. The full results appear in Tables 1–3 of §4 (including exact scores for ConMoE and all baselines on the three models, with dataset details in §4.1). In the revision we will (i) insert key numerical values and table references into the abstract and §4 introduction, (ii) state that all scores are averaged over three independent evaluation runs, and (iii) ensure standard deviations are reported in the tables where they were previously omitted from the summary text. revision: yes
-
Referee: [§3] §3 (Method): the replaceability and contribution signals are computed on an unspecified small calibration corpus; because expert activations are known to be input-dependent, the manuscript must demonstrate that these proxies remain predictive of functional equivalence under deterministic remapping on held-out data, or the train-free preservation claim is unsupported.
Authors: We will revise §3.2 to explicitly state the calibration corpus details (size, source, and sampling procedure). To address input dependence, we will add a controlled experiment that recomputes prototype selection on a held-out portion of the same data distribution and reports the resulting end-to-end performance after deterministic remapping. This will directly test whether the signals remain predictive outside the calibration set. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): the statement that 'deterministic reassignment is the most stable component' is presented without quantitative comparison of performance variance across random seeds or across different calibration-set sizes; this directly affects the reliability of the core design choice.
Authors: We accept that the current ablation lacks quantitative variance metrics. In the revised §4.3 we will report mean and standard deviation of downstream scores across five random seeds for deterministic reassignment versus the compared alternatives, and we will repeat the ablation for calibration-set sizes of 256, 512, and 1024 samples. These additions will provide the requested quantitative support for the stability claim. revision: yes
Circularity Check
No significant circularity; method is purely empirical
full rationale
The paper describes a train-free empirical procedure for expert consolidation using calibration signals and deterministic remapping, evaluated via experiments on external pretrained models. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. All load-bearing claims rest on external benchmarks rather than internal reduction to inputs. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Minbin Huang, Han Shi, Chuanyang Zheng, Yimeng Wu, Guoxuan Chen, Xintong Yu, Yichun Yin, and Hong Cheng. 2026. Unipool: A globally shared expert pool for mixture-of-experts.Preprint, arXiv:2605.06665. Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanc...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[2]
Zongfang Liu, Shengkun Tang, Boyang Sun, Zhiqiang Shen, and Xin Yuan
Merge, then compress: Demystify efficient smoe with hints from its routing policy.Preprint, arXiv:2310.01334. Zongfang Liu, Shengkun Tang, Boyang Sun, Zhiqiang Shen, and Xin Yuan. 2026. Evoesap: Non- uniform expert pruning for sparse moe.Preprint, arXiv:2603.06003. Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, and Hongsheng Li
-
[3]
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 6159–6172, Bangkok, Thailand. Association for Computational Linguistics. Ruijie Miao, Yilun Yao, Zihan Wang, Zhiming Wang, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.