Learning Design Skills as Memory Policies for Agentic Photonic Inverse Design
Pith reviewed 2026-06-29 07:59 UTC · model grok-4.3
The pith
SkillPCF formulates photonic crystal fiber inverse design as memory-policy learning to build reusable skills from expert traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
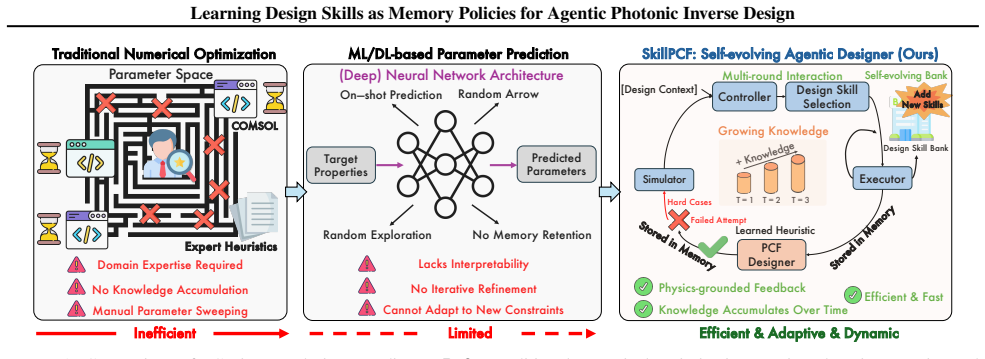
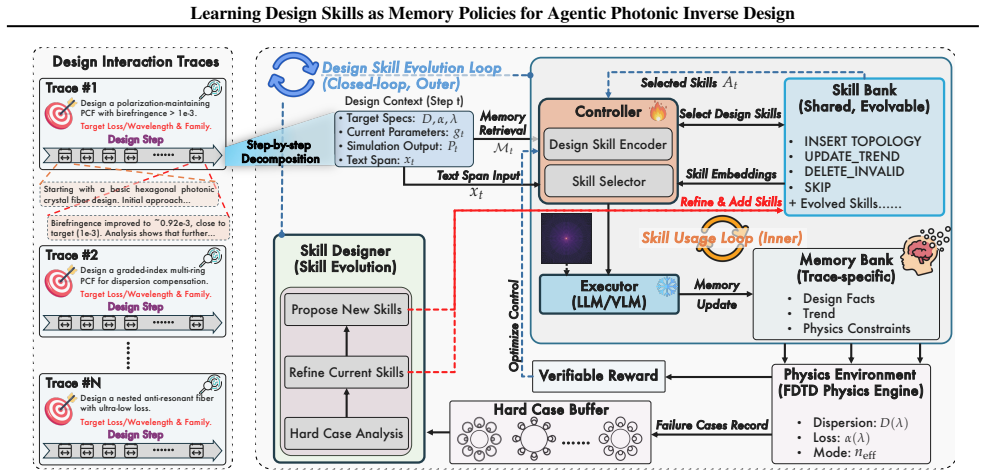
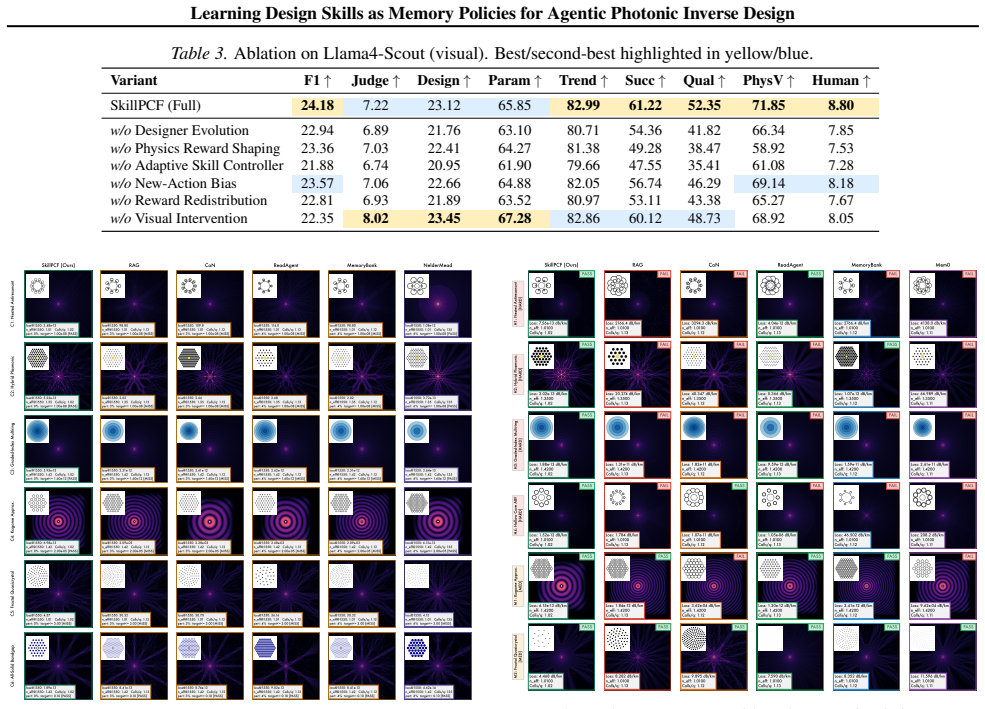
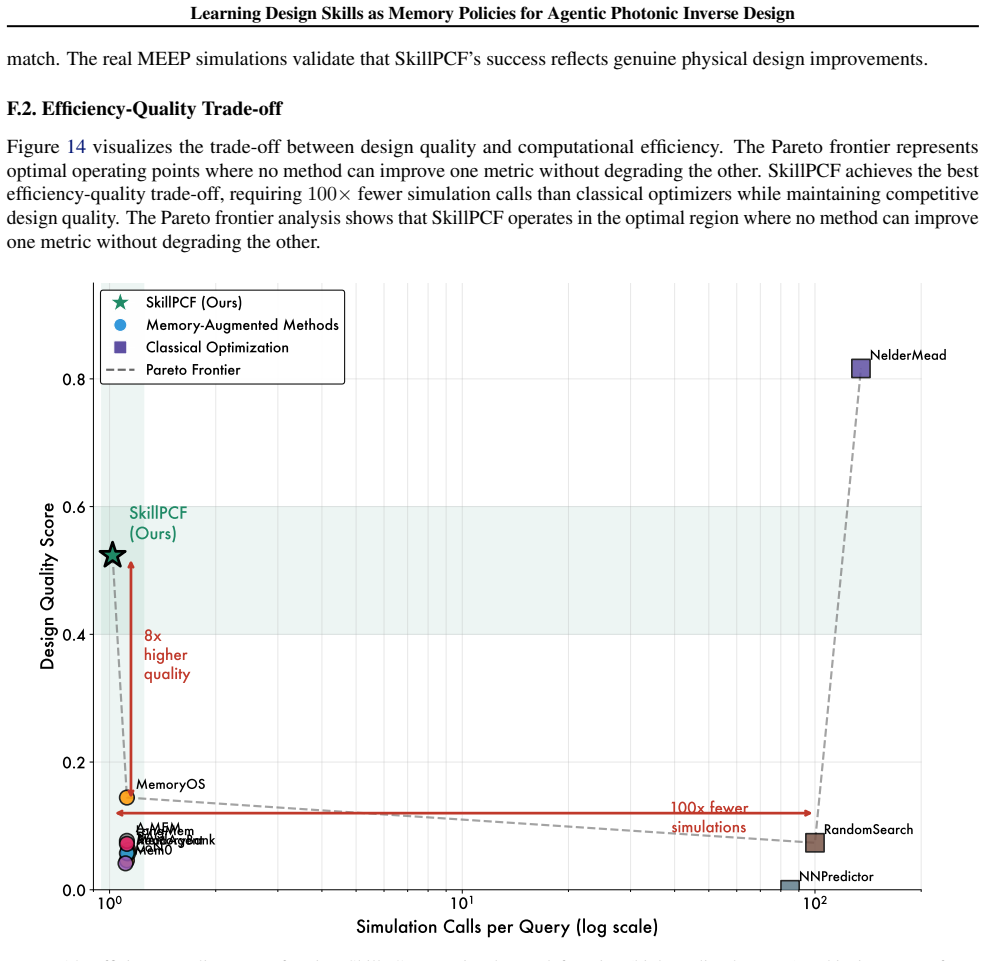
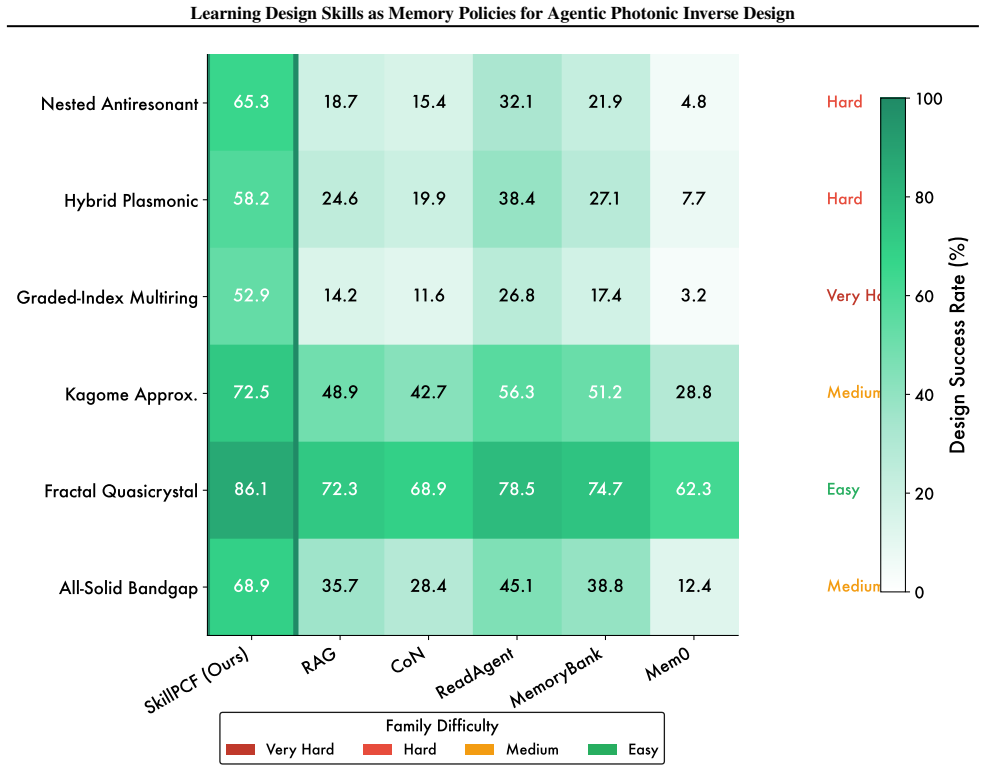
SkillPCF, a closed-loop agent framework that combines a physics-guided memory skill bank, reinforcement-learned skill selection, and simulator-grounded skill evolution, achieves stronger design-quality and efficiency trade-offs under practical simulation budgets when trained on 479 expert interaction traces covering dispersion engineering, loss optimization, and multi-objective design.
What carries the argument
The physics-guided memory skill bank extracted from 479 expert interaction traces, which supplies reusable policies that reinforcement learning selects and evolves inside the closed-loop agent.
If this is right
- The memory-skill paradigm enables accumulation of design knowledge rather than restarting each inverse-design task.
- Reinforcement-learned selection and simulator-grounded evolution together produce measurable gains in quality-efficiency trade-offs.
- The framework operates across multiple LLM backbones while outperforming one-shot parameter recommendation and surrogate-only pipelines.
- Closed-loop interaction allows skills to adapt to coupled targets such as dispersion and loss under realistic simulation limits.
Where Pith is reading between the lines
- The same memory-policy structure could be tested on other inverse-design domains that rely on costly forward simulations.
- Larger or more varied expert-trace collections would provide a direct test of whether the learned skills remain stable outside the original dataset.
- Feeding fabrication outcomes back into the skill-evolution loop could close the loop between simulation and physical realization.
Load-bearing premise
The 479 expert interaction traces form a representative and unbiased basis for learning reusable skills, and reinforcement learning can reliably select and evolve those skills in the high-dimensional, multi-objective PCF design space.
What would settle it
If SkillPCF applied to the 479-trace dataset produces no measurable improvement in design quality per simulation call relative to the classical and LLM baselines, the central claim would be falsified.
Figures





read the original abstract
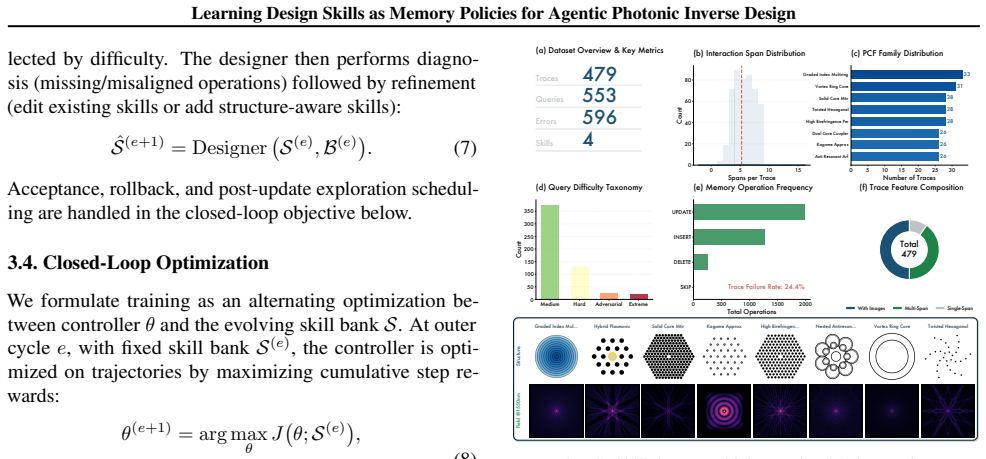
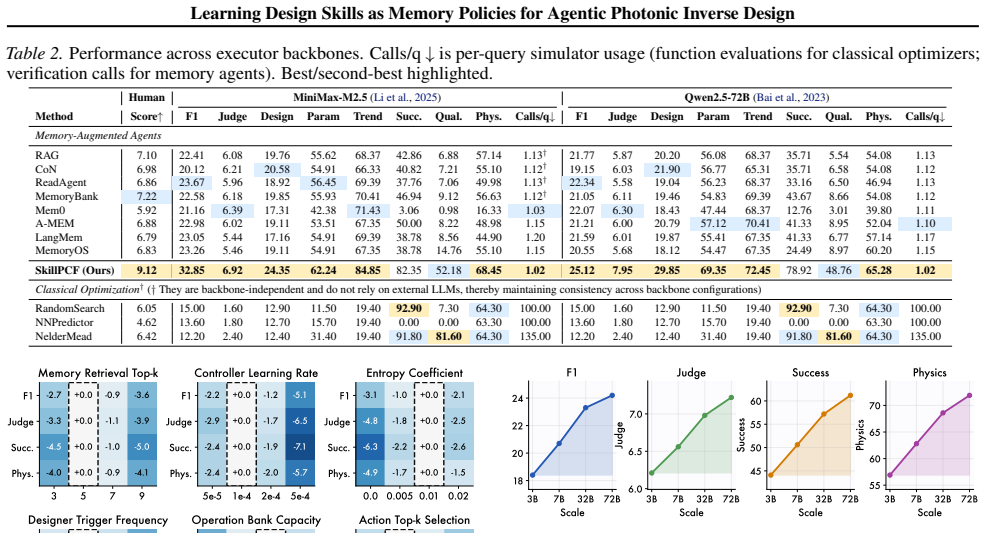
Photonic crystal fiber (PCF) inverse design remains challenging because candidate geometries must satisfy coupled optical targets under expensive electromagnetic simulation. Existing pipelines improve surrogate prediction or one-shot parameter recommendation, but they do not accumulate reusable design knowledge across iterative trials. We formulate PCF inverse design as a memory-policy learning problem and propose SkillPCF, a closed-loop agent framework that combines a physics-guided memory skill bank, reinforcement-learned skill selection, and simulator-grounded skill evolution. We further construct a real-world dataset with 479 expert interaction traces (2,507 spans) and 553 memory-dependent evaluation queries covering dispersion engineering, loss optimization, and multi-objective design. Experiments across multiple LLM backbones and classical baselines show that SkillPCF achieves stronger design-quality and efficiency trade-offs under practical simulation budgets, demonstrating the effectiveness of our proposed memory-skill learning paradigm for physics-aware PCF inverse design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates photonic crystal fiber (PCF) inverse design as a memory-policy learning problem and introduces SkillPCF, an agentic framework combining a physics-guided memory skill bank (built from 479 expert interaction traces comprising 2,507 spans), reinforcement-learned skill selection, and simulator-grounded skill evolution. A dataset of 553 memory-dependent evaluation queries is constructed covering dispersion engineering, loss optimization, and multi-objective design. Experiments across LLM backbones and classical baselines report that SkillPCF yields improved design-quality versus efficiency trade-offs under practical simulation budgets.
Significance. If validated, the memory-skill paradigm could meaningfully advance agentic methods for expensive physics simulations by enabling reuse of design knowledge across trials, moving beyond surrogate or one-shot approaches in PCF design. The explicit construction of an expert-trace dataset and closed-loop evolution mechanism are concrete strengths that could support follow-on work in related inverse-design domains.
major comments (2)
- [Dataset construction (implied in abstract and experiments)] The central claim that SkillPCF achieves stronger trade-offs rests on the 479 expert traces yielding reusable skills that RL can reliably select and evolve. However, no quantitative coverage analysis (e.g., span of dispersion, loss, and multi-objective regimes) or bias assessment of the traces is described, leaving open the possibility that evaluation gains reflect distributional overlap with the 553 queries rather than generalization.
- [RL skill selection and evolution (implied in method and experiments)] The assertion that reinforcement learning reliably performs skill selection and evolution in the high-dimensional, multi-objective PCF parameter space lacks supporting ablations or exploration metrics. Combinatorial selection in such spaces is prone to local optima; without evidence that the RL component overcomes this under limited simulation budgets, the efficiency gains cannot be attributed to the memory-policy paradigm.
minor comments (1)
- The abstract states results 'across multiple LLM backbones and classical baselines' without naming the specific models or baselines; adding these (and any hyperparameter details) would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, providing clarifications and committing to revisions where the manuscript can be strengthened without misrepresenting our contributions.
read point-by-point responses
-
Referee: The central claim that SkillPCF achieves stronger trade-offs rests on the 479 expert traces yielding reusable skills that RL can reliably select and evolve. However, no quantitative coverage analysis (e.g., span of dispersion, loss, and multi-objective regimes) or bias assessment of the traces is described, leaving open the possibility that evaluation gains reflect distributional overlap with the 553 queries rather than generalization.
Authors: We acknowledge that the original manuscript does not include a quantitative coverage analysis or explicit bias assessment of the 479 expert traces. The traces were collected from expert interactions targeting the three regimes (dispersion engineering, loss optimization, multi-objective design) and the 553 queries were constructed as memory-dependent and held-out. To directly address the concern regarding potential overlap versus generalization, we will add a new subsection with coverage statistics (parameter spans, objective distributions) and a bias assessment in the revised manuscript. revision: yes
-
Referee: The assertion that reinforcement learning reliably performs skill selection and evolution in the high-dimensional, multi-objective PCF parameter space lacks supporting ablations or exploration metrics. Combinatorial selection in such spaces is prone to local optima; without evidence that the RL component overcomes this under limited simulation budgets, the efficiency gains cannot be attributed to the memory-policy paradigm.
Authors: The reported experiments compare SkillPCF against classical baselines and LLM variants without the full memory-policy components, showing consistent improvements in design-quality versus efficiency trade-offs. However, we agree that dedicated ablations isolating the RL skill selection module and exploration metrics (e.g., skill usage entropy, convergence behavior) are absent. We will incorporate these ablations and metrics in the revision to provide direct evidence that the RL component contributes to overcoming local optima under the given budgets. revision: yes
Circularity Check
No circularity; empirical framework evaluated on constructed dataset
full rationale
The paper formulates PCF inverse design as a memory-policy learning problem and evaluates SkillPCF empirically on a dataset of 479 expert traces and 553 queries. No derivation chain, equations, or predictions are claimed that reduce to fitted inputs, self-definitions, or self-citation load-bearing premises. Results are presented as experimental outcomes under simulation budgets rather than tautological outputs of the method itself. The central claim rests on observed design-quality trade-offs, which are falsifiable against baselines and do not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Chhikara, P., Khant, D., Aryan, S., Singh, T., and Yadav, D. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Memory os of ai agent
Kang, J., Ji, M., Zhao, Z., and Bai, T. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 25972–25981,
2025
-
[6]
Lee, K.-H., Chen, X., Furuta, H., Canny, J., and Fischer, I. A human-inspired reading agent with gist memory of very long contexts.arXiv preprint arXiv:2402.09727,
-
[7]
MiniMax-01: Scaling Foundation Models with Lightning Attention
Li, A., Gong, B., Yang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., et al. Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Choosing how to remember: Adaptive memory structures for llm agents
Lu, M., Wu, M., Liu, F., Xu, J., Li, W., Wang, H., Hu, Z., Ding, Y ., Sun, Y ., Lu, J., et al. Choosing how to remember: Adaptive memory structures for llm agents. arXiv preprint arXiv:2602.14038,
-
[10]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Wang, G., Liu, J., Chen, S., and Ren, S. Optimizing low- resolution spectral demodulation for long-period fiber gratings using residual convolutional neural networks. Optics Express, 33(4):8225–8238, 2025a. Wang, G., Liu, J., Chen, S., and Ren, S. Towards scal- able and accurate property prediction for photonic crystal fibers with federated learning.Optic...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Xia, P., Chen, J., Wang, H., Liu, J., Zeng, K., Wang, Y ., Han, S., Zhou, Y ., Zhao, X., Chen, H., et al. Skillrl: Evolv- ing agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Chain-of-note: Enhancing robustness in retrieval-augmented language models
Yu, W., Zhang, H., Pan, X., Cao, P., Ma, K., Li, J., Wang, H., and Yu, D. Chain-of-note: Enhancing robustness in retrieval-augmented language models. InProceedings of the 2024 conference on empirical methods in natural language processing, pp. 14672–14685,
2024
-
[15]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Zhang, H., Long, Q., Bao, J., Feng, T., Zhang, W., Yue, H., and Wang, W. Memskill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
11 Learning Design Skills as Memory Policies for Agentic Photonic Inverse Design Appendix For readability and fast lookup, we organize the appendix into six blocks with direct hyperlinks: • Appendix A: System, Data, and Evaluation Protocols • Appendix B: Additional Case Studies • Appendix C: Implementation Details and Evaluation Metrics • Appendix D: Init...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.