ReasonLight: A Multimodal Foundation Model-Enhanced Reinforcement Learning Framework for Zero-Shot Traffic Signal Control
Pith reviewed 2026-06-29 07:30 UTC · model grok-4.3
The pith
ReasonLight refines RL-proposed traffic phases with multimodal semantics to enable zero-shot handling of unseen events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
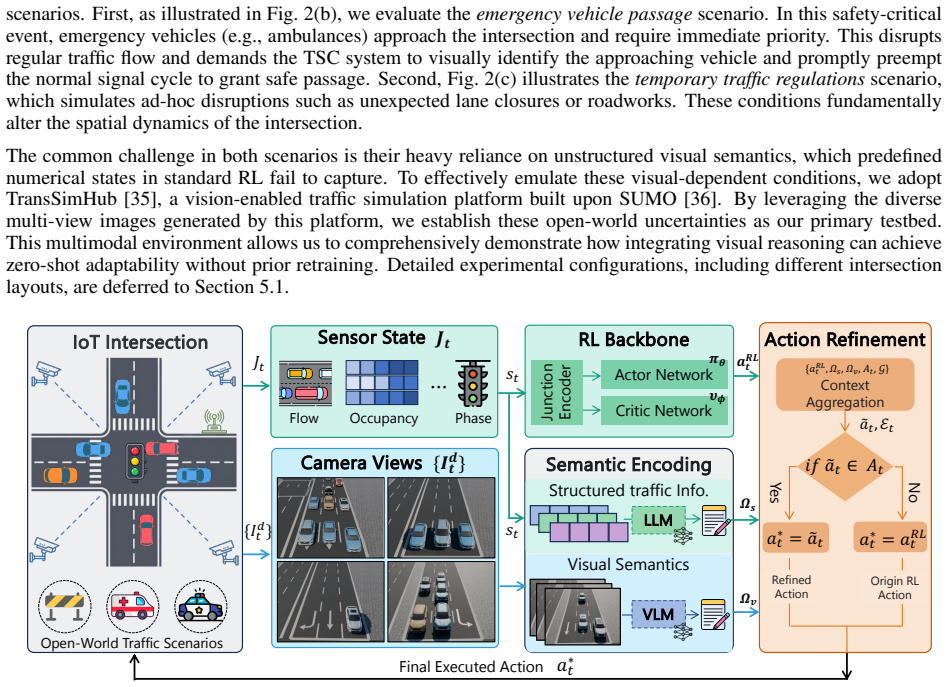
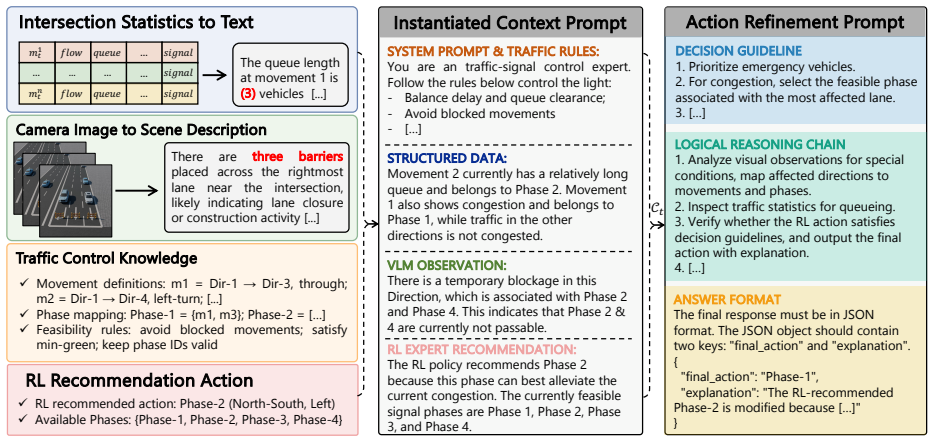
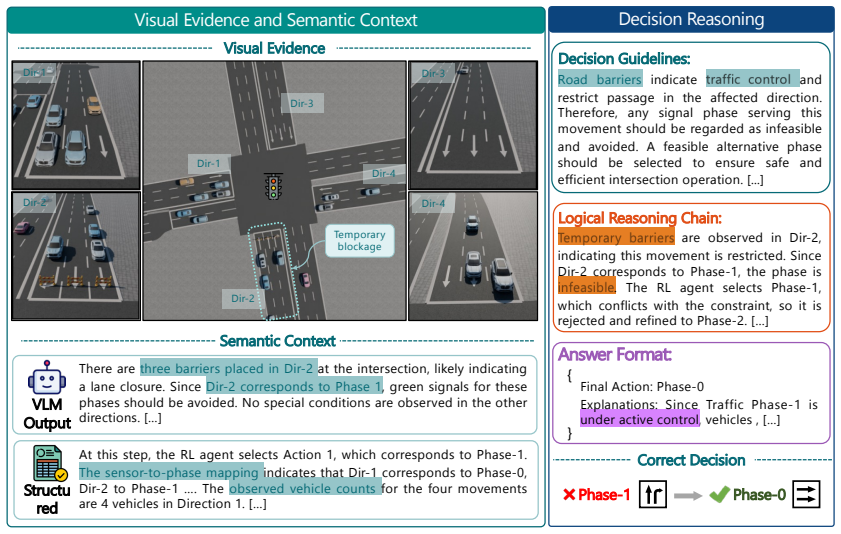
ReasonLight integrates structured traffic measurements, multi-view camera observations, and candidate phase decisions from a pre-trained RL controller. Given an RL-proposed phase, it extracts visual semantics from images and aligns them with compact sensor-derived scene descriptions. This alignment feeds a semantic-guided refinement module that preserves or adjusts the action according to traffic rules and event semantics, with all outputs constrained to the set of available phases and invalid decisions rejected in favor of the original RL action.
What carries the argument
Semantic-guided refinement module that aligns visual semantics from multi-view images with sensor descriptions to preserve or adjust RL-proposed phases.
If this is right
- Zero-shot adaptation occurs without any retraining on the new events.
- Emergency vehicle waiting time drops by up to 88.7 percent relative to the RL backbone.
- Routine traffic performance remains comparable to the original RL controller.
- Invalid refined actions are rejected and the system reverts to the RL proposal.
- The same pipeline applies to both emergency priority and temporary traffic regulation cases.
Where Pith is reading between the lines
- The same alignment step could be applied to other sensor-rich domains such as adaptive building energy control when rare occupancy patterns appear.
- If the fallback mechanism proves reliable, it lowers the safety barrier for deploying foundation-model refinements in regulated infrastructure.
- Extending the visual-semantic alignment to longer time horizons might allow anticipation of cascading events like secondary accidents.
- The approach suggests that pre-trained models can serve as a lightweight interface layer between existing RL agents and new observation modalities.
Load-bearing premise
The pre-trained multimodal foundation model can reliably extract and align visual semantics from multi-view images with sensor descriptions and traffic rules for events absent from the RL training distribution.
What would settle it
A test case where an unseen event such as an emergency vehicle appears and the refined action fails to reduce its waiting time below the RL-only baseline on a majority of trials.
Figures
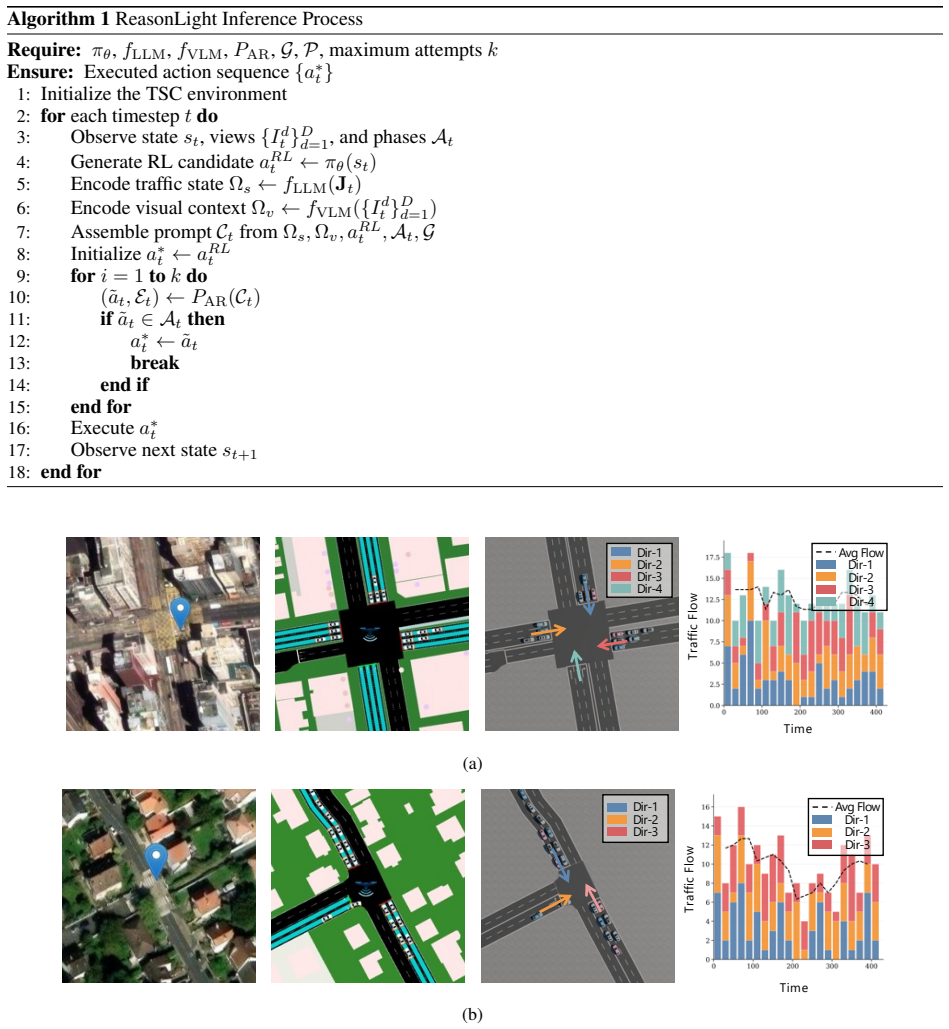
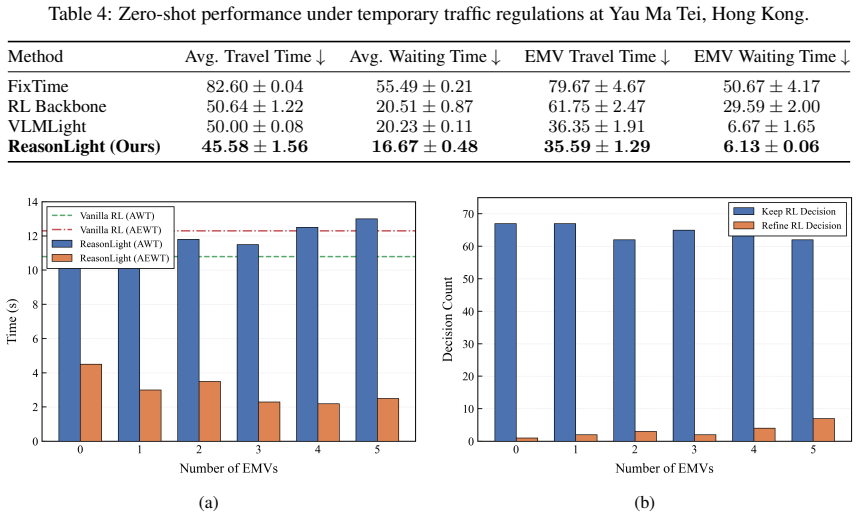
read the original abstract
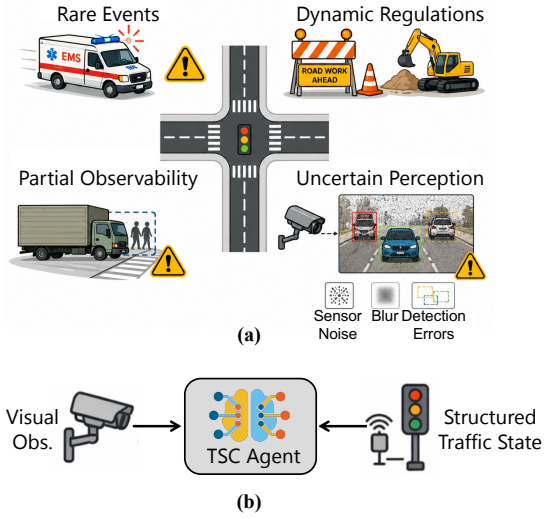
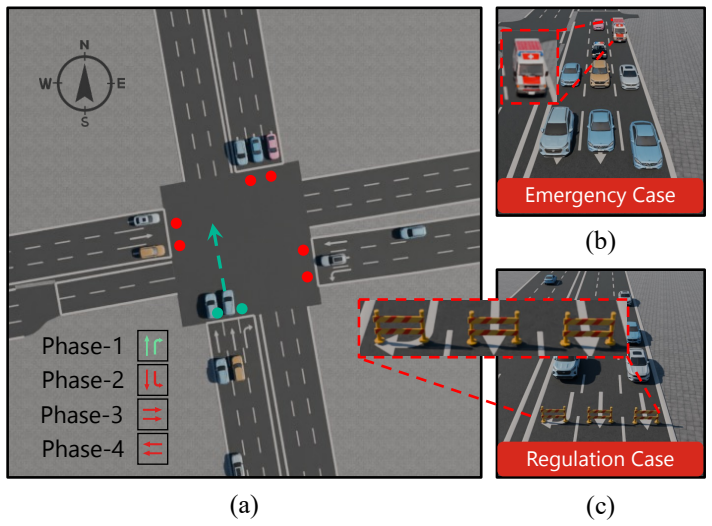
Reinforcement learning (RL) has shown promise in traffic signal control (TSC). However, its reliance on predefined states limits responsiveness to observable open-world events that are absent from training data. IoT-enabled intersections provide heterogeneous observations from roadside sensors and cameras, creating opportunities to improve RL adaptability to such events. To this end, we propose ReasonLight, a multimodal foundation model-enhanced RL framework for zero-shot TSC. ReasonLight integrates three sources of information: structured traffic measurements, multi-view camera observations, and candidate phase decisions from a pre-trained RL controller. Given an RL-proposed phase, ReasonLight extracts visual semantics from multi-view images and aligns them with compact sensor-derived scene descriptions. This alignment enables a semantic-guided refinement module to either preserve or adjust the proposed action according to traffic rules and event semantics. To ensure operational reliability, refined actions are constrained by the set of available phases. Any invalid decision is rejected, and the system falls back to the original RL action. We evaluate ReasonLight on two types of rare events not seen during RL training: emergency vehicle priority and temporary traffic regulation. Experimental results show that ReasonLight achieves zero-shot adaptation without retraining. It reduces emergency vehicle waiting time by up to 88.7% compared with the RL-only backbone while preserving comparable routine traffic performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReasonLight, a multimodal foundation model-enhanced RL framework for zero-shot traffic signal control. It integrates structured traffic measurements, multi-view camera observations, and candidate phases from a pre-trained RL controller. Visual semantics are extracted from images and aligned with compact sensor-derived scene descriptions to enable a semantic-guided refinement module that preserves or adjusts the proposed phase according to traffic rules and event semantics. Refined actions are constrained to available phases, with fallback to the original RL action for invalid decisions. The paper claims zero-shot adaptation without retraining on two rare event types absent from RL training (emergency vehicle priority and temporary traffic regulation), achieving up to 88.7% reduction in emergency vehicle waiting time while preserving comparable routine traffic performance.
Significance. If the alignment module reliably handles novel events and the reported gains are reproducible, the work would offer a practical route to improving RL-based TSC adaptability in open-world settings by leveraging foundation models for semantic reasoning, potentially reducing retraining costs for rare but safety-critical scenarios.
major comments (2)
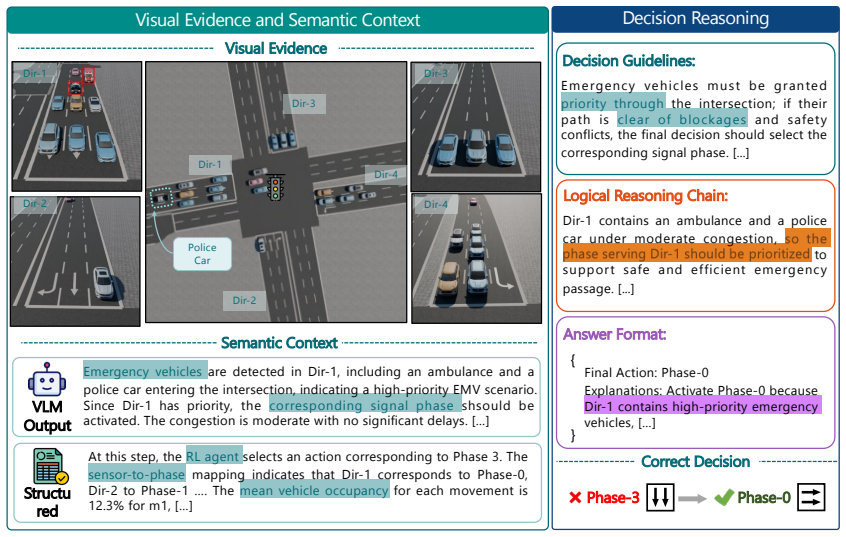
- [Abstract] Abstract: the central quantitative claim of an 88.7% reduction in emergency vehicle waiting time is presented without any experimental details (baselines, datasets, error bars, trial counts, or validation of the alignment module), which is load-bearing for the zero-shot adaptation result.
- [Results] Results section: the zero-shot claim for events absent from the RL training distribution requires that the multimodal alignment correctly extracts semantics and that errors are routed to fallback without erasing gains or producing unsafe actions; however, no alignment accuracy metrics, confusion matrices on held-out event classes, or ablations isolating the foundation-model component versus the fallback rule are supplied.
minor comments (1)
- The abstract references evaluation on two event types but does not name the simulation platform, sensor configurations, or camera viewpoints used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and results sections. We address each major comment point by point below and outline the revisions we will make to improve clarity and support for the zero-shot claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claim of an 88.7% reduction in emergency vehicle waiting time is presented without any experimental details (baselines, datasets, error bars, trial counts, or validation of the alignment module), which is load-bearing for the zero-shot adaptation result.
Authors: We agree that the abstract presents the key result without accompanying experimental context. Abstracts are space-constrained, and full details (RL-only baseline, SUMO-based datasets, multiple random seeds with error bars) appear in the Results section. To strengthen the abstract, we will revise it to briefly note the evaluation context and trial count while preserving conciseness. revision: partial
-
Referee: [Results] Results section: the zero-shot claim for events absent from the RL training distribution requires that the multimodal alignment correctly extracts semantics and that errors are routed to fallback without erasing gains or producing unsafe actions; however, no alignment accuracy metrics, confusion matrices on held-out event classes, or ablations isolating the foundation-model component versus the fallback rule are supplied.
Authors: The referee correctly notes that direct metrics on alignment accuracy and component ablations are absent. The current results focus on end-to-end traffic metrics and the fallback rule's role in safety. We will add an ablation study isolating the foundation-model refinement versus fallback, plus alignment accuracy and confusion matrices on held-out emergency and regulation events, to better substantiate the zero-shot adaptation. revision: yes
Circularity Check
No circularity: framework description contains no derivations or equations
full rationale
The paper describes an architectural framework integrating RL proposals with multimodal foundation-model alignment and fallback rules. No equations, parameter-fitting steps, or derivation chains appear in the abstract or described content. Performance numbers (e.g., 88.7% reduction) are presented as empirical evaluation outcomes rather than outputs of any self-referential definition or fitted-input prediction. No self-citation is invoked as a load-bearing uniqueness theorem or ansatz. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal foundation models can extract traffic-relevant semantics from camera images that align with sensor data and traffic rules for unseen events.
Reference graph
Works this paper leans on
-
[1]
SCATS, sydney co-ordinated adaptive traffic system: A traffic responsive method of controlling urban traffic,
P. Lowrie, “SCATS, sydney co-ordinated adaptive traffic system: A traffic responsive method of controlling urban traffic,”Roads and Traffic Authority NSW, Traffic Control Section (Darlinghurst, NSW), 1990
1990
-
[2]
Traffic signal timing manual
P. Koonce and L. Rodegerdts, “Traffic signal timing manual.” United States. Federal Highway Administration, Tech. Rep., 2008
2008
-
[3]
A survey on traffic signal control methods,
H. Wei, G. Zheng, V . Gayah, and Z. Li, “A survey on traffic signal control methods,”arXiv preprint arXiv:1904.08117, 2019
-
[4]
Hgat and multi-agent rl-based method for multi-intersection traffic signal control,
Z. Zhai, R. Hao, B. Cui, and S. Wang, “Hgat and multi-agent rl-based method for multi-intersection traffic signal control,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 5, pp. 6848–6864, 2025
2025
-
[5]
Reinforcement learning in urban network traffic signal control: A systematic literature review,
M. Noaeen, A. Naik, L. Goodman, J. Crebo, T. Abrar, Z. S. H. Abad, A. L. Bazzan, and B. Far, “Reinforcement learning in urban network traffic signal control: A systematic literature review,”Expert Systems with Applica- tions, vol. 199, p. 116830, 2022
2022
-
[6]
A survey on deep reinforcement learning approaches for traffic signal control,
H. Zhao, C. Dong, J. Cao, and Q. Chen, “A survey on deep reinforcement learning approaches for traffic signal control,”Engineering Applications of Artificial Intelligence, vol. 133, p. 108100, 2024
2024
-
[7]
Digital-twin-based deep reinforcement learning approach for adaptive traffic signal control,
H. Kamal, W. Y ´anez, S. Hassan, and D. Sobhy, “Digital-twin-based deep reinforcement learning approach for adaptive traffic signal control,”IEEE Internet of Things Journal, vol. 11, no. 12, pp. 21 946–21 953, 2024
2024
-
[8]
Reinforcement learning-based traffic signal control using delayed observations for v2x,
A. Pang, Z. Xu, M. Wang, M.-O. Pun, and Y . Kan, “Reinforcement learning-based traffic signal control using delayed observations for v2x,” inICC 2023 - IEEE International Conference on Communications, 2023, pp. 4020–4025
2023
-
[9]
M. Wang, Y . Chen, Y . Kan, C. Xu, L. Michael, M.-O. Pun, and X. Xiong, “Traffic Signal Cycle Con- trol with Centralized Critic and Decentralized Actors under Varying Intervention Frequencies,”arXiv preprint arXiv:2406.08248, 2024
-
[10]
UniTSA: A universal Reinforcement Learning Framework for V2X Traffic Signal Control,
M. Wang, X. Xiong, Y . Kan, C. Xu, and M.-O. Pun, “UniTSA: A universal Reinforcement Learning Framework for V2X Traffic Signal Control,”IEEE Transactions on Vehicular Technology, pp. 1–16, 2024
2024
-
[11]
Challenges of real- world reinforcement learning: definitions, benchmarks and analysis,
G. Dulac-Arnold, N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester, “Challenges of real- world reinforcement learning: definitions, benchmarks and analysis,”Machine Learning, vol. 110, no. 9, pp. 2419–2468, 2021
2021
-
[12]
Efficient rl with impaired observability: Learning to act with delayed and missing state observations,
M. Chen, Y . Bai, H. V . Poor, and M. Wang, “Efficient rl with impaired observability: Learning to act with delayed and missing state observations,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[13]
Multimodal foundation models: From specialists to general-purpose assistants,
C. Li, Z. Gan, Z. Yang, J. Yang, L. Li, L. Wang, and J. Gao, “Multimodal foundation models: From specialists to general-purpose assistants,”Foundations and Trends in Computer Graphics and Vision, vol. 16, no. 1-2, pp. 1–214, 2024
2024
-
[14]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-VL technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
A. Pang, M. Wang, M.-O. Pun, C. S. Chen, and X. Xiong, “iLLM-TSC: Integration reinforcement learning and large language model for traffic signal control policy improvement,”arXiv preprint arXiv:2407.06025, 2024
-
[16]
T. Cui, X. Lin, S. Li, M. Chen, Q. Yin, Q. Li, and K. Xu, “Trafficllm: Enhancing large language models for network traffic analysis with generic traffic representation,”arXiv preprint arXiv:2504.04222, 2025
-
[17]
Llmlight: Large language models as traffic signal control agents,
S. Lai, Z. Xu, W. Zhang, H. Liu, and H. Xiong, “Llmlight: Large language models as traffic signal control agents,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, 2025, pp. 2335–2346
2025
-
[18]
Collmlight: Cooperative large language model agents for network-wide traffic signal control,
Z. Yuan, S. Lai, and H. Liu, “Collmlight: Cooperative large language model agents for network-wide traffic signal control,”arXiv preprint arXiv:2503.11739, 2025
-
[19]
Traffic-r1: Reinforced llms bring human- like reasoning to traffic signal control systems,
X. Zou, Y . Yang, Z. Chen, X. Hao, Y . Chen, C. Huang, and Y . Liang, “Traffic-r1: Reinforced llms bring human- like reasoning to traffic signal control systems,”arXiv preprint arXiv:2508.02344, 2025. 15
-
[20]
Sl-seg: A cnn-transformer fusion network for road surface and lane segmentation in complex scenarios,
C. Meng, X. Wang, Q. Tu, Z. Mao, and J. Shen, “Sl-seg: A cnn-transformer fusion network for road surface and lane segmentation in complex scenarios,”IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[21]
Multimodal traffic speed monitoring: A real-time system based on passive wi-fi and bluetooth sensing technology,
Z. Pu, Z. Cui, J. Tang, S. Wang, and Y . Wang, “Multimodal traffic speed monitoring: A real-time system based on passive wi-fi and bluetooth sensing technology,”IEEE Internet of Things Journal, vol. 9, no. 14, pp. 12 413– 12 424, 2022
2022
-
[22]
Scalable Reinforcement Learning Framework for Traffic Signal Control under Communication Delays,
A. Pang, M. Wang, Y . Chen, M.-O. Pun, and M. Lepech, “Scalable Reinforcement Learning Framework for Traffic Signal Control under Communication Delays,”IEEE Open Journal of Vehicular Technology, 2024
2024
-
[23]
Attendlight: Universal attention-based reinforcement learning model for traffic signal control,
A. Oroojlooy, M. Nazari, D. Hajinezhad, and J. Silva, “Attendlight: Universal attention-based reinforcement learning model for traffic signal control,”Advances in Neural Information Processing Systems, vol. 33, pp. 4079–4090, 2020
2020
-
[24]
TS-PVL: Two-stage deep-reinforcement-learning-based traffic light with pedestrian-vehicle control in mixed-autonomy traffic,
G. Zhang, H. Huang, and F. Chang, “TS-PVL: Two-stage deep-reinforcement-learning-based traffic light with pedestrian-vehicle control in mixed-autonomy traffic,”IEEE Internet of Things Journal, vol. 12, no. 15, pp. 31 001–31 014, 2025
2025
-
[25]
EMVLight: A decentralized reinforcement learning framework for efficient passage of emergency vehicles,
H. Su, Y . D. Zhong, B. Dey, and A. Chakraborty, “EMVLight: A decentralized reinforcement learning framework for efficient passage of emergency vehicles,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, 2022, pp. 4593–4601
2022
-
[26]
Difflight: integrating content and detail for low-light image enhancement,
Y . Feng, S. Hou, H. Lin, Y . Zhu, P. Wu, W. Dong, J. Sun, Q. Yan, and Y . Zhang, “Difflight: integrating content and detail for low-light image enhancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6143–6152
2024
-
[27]
M. Wang, A. Pang, Y . Kan, M.-O. Pun, C. S. Chen, and B. Huang, “LLM-Assisted Light: Leveraging Large Language Model Capabilities for Human-Mimetic Traffic Signal Control in Complex Urban Environments,” arXiv preprint arXiv:2403.08337, 2024
-
[28]
VLMLight: Safety-critical traffic signal control via vision-language meta-control and dual-branch reasoning architecture,
M. Wang, Y . Chen, A. Pang, Y . Cai, C. S. Chen, Y . Kan, and M.-O. Pun, “VLMLight: Safety-critical traffic signal control via vision-language meta-control and dual-branch reasoning architecture,” inProceedings of the Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[29]
Improve vision language model chain-of-thought reasoning,
R. Zhang, B. Zhang, Y . Li, H. Zhang, Z. Sun, Z. Gan, Y . Yang, R. Pang, and Y . Yang, “Improve vision language model chain-of-thought reasoning,”arXiv preprint arXiv:2410.16198, 2024
-
[30]
Vlm-ad: End-to-end autonomous driving through vision-language model supervision,
Y . Xu, Y . Hu, Z. Zhang, G. P. Meyer, S. K. Mustikovela, S. Srinivasa, E. M. Wolff, and X. Huang, “Vlm-ad: End-to-end autonomous driving through vision-language model supervision,”arXiv preprint arXiv:2412.14446, 2024
-
[31]
A survey on multimodal large language models,
S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, and E. Chen, “A survey on multimodal large language models,” National Science Review, vol. 11, no. 12, p. nwae403, 2024
2024
-
[32]
Vlm-driver: Human-like autonomous driving decision-making via vision language model,
R. Zhao, Q. Yuan, J. Li, Z. Wang, Y . Li, Z. Gao, H. Hu, and F. Gao, “Vlm-driver: Human-like autonomous driving decision-making via vision language model,”IEEE Transactions on Vehicular Technology, 2025
2025
-
[33]
End-to-end autonomous driving: From classic paradigm to large model empowerment—a comprehensive survey,
W. Dong, S. Lu, X. Chen, S. Zhang, Q. Liu, Z. Liu, L. Chen, H. Wang, and Y . Cai, “End-to-end autonomous driving: From classic paradigm to large model empowerment—a comprehensive survey,”IEEE Internet of Things Journal, vol. 13, no. 3, pp. 3870–3898, 2026
2026
-
[34]
MSET: Multimodal semantic-enhanced real-world beam prediction via temporal modeling with visual foundation models,
F. Liu, X. Li, W. Gao, J. Xiong, G. Niu, and C. S. Chen, “MSET: Multimodal semantic-enhanced real-world beam prediction via temporal modeling with visual foundation models,”IEEE Internet of Things Journal, pp. 1–1, 2026
2026
-
[35]
Transimhub: A unified air-ground simulation platform for multi-modal perception and decision-making,
M. Wang, Y . Chen, Y . Cai, A. Pang, Y . Xie, Z. Ma, C. Xu, K. Jiang, D. Wang, L. Roulletet al., “Transimhub: A unified air-ground simulation platform for multi-modal perception and decision-making,”arXiv preprint arXiv:2510.15365, 2025
-
[36]
Traffic modeling with SUMO: A tutorial,
D. A. Guastella, E. Montero-Porras, A. Morales-Hern ´andez, and G. Bontempi, “Traffic modeling with SUMO: A tutorial,”arXiv preprint arXiv:2304.05982, 2023
-
[37]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Traffic signal settings,
F. V . Webster, “Traffic signal settings,” Road Research Laboratory, Road Research Technical Paper No. 39, 1958
1958
-
[40]
Max pressure control of a network of signalized intersections,
P. Varaiya, “Max pressure control of a network of signalized intersections,”Transportation Research Part C: Emerging Technologies, vol. 36, pp. 177–195, 2013. 16
2013
-
[41]
Intellilight: A reinforcement learning approach for intelligent traffic light control,
H. Wei, G. Zheng, H. Yao, and Z. Li, “Intellilight: A reinforcement learning approach for intelligent traffic light control,” inProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 2496–2505
2018
-
[42]
Traffic signal cycle control with cen- tralized critic and decentralized actors under varying intervention frequencies,
M. Wang, Y . Chen, Y . Kan, C. Xu, M. Lepech, M.-O. Pun, and X. Xiong, “Traffic signal cycle control with cen- tralized critic and decentralized actors under varying intervention frequencies,”IEEE Transactions on Intelligent Transportation Systems, 2024. 17
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.