Access Sets Matter: Budgeting Expert Reads for Scalable Weight-Space Model Merging
Pith reviewed 2026-06-29 09:09 UTC · model grok-4.3
The pith
MergePipe budgets expert weight reads to enable scalable LLM merging with order-of-magnitude I/O savings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
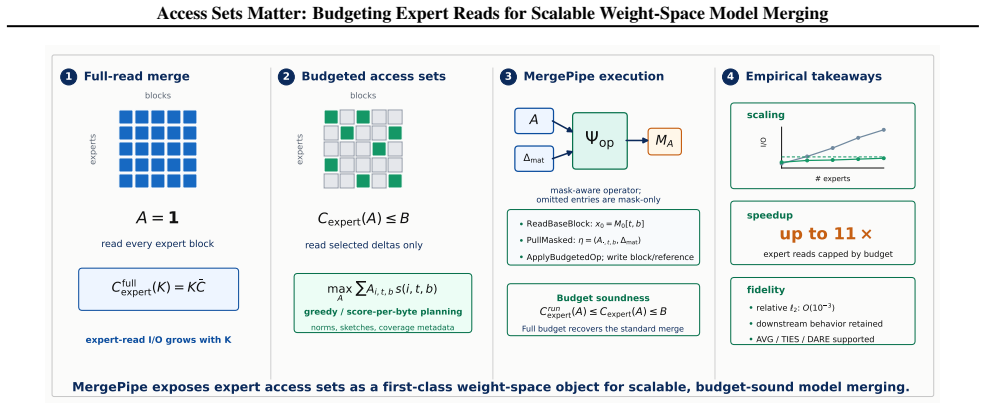
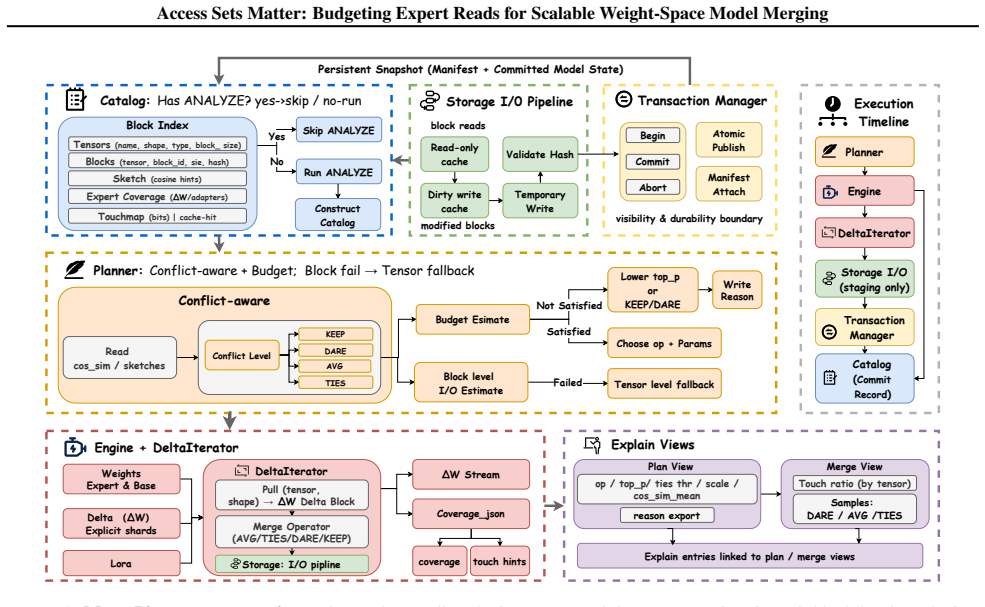
MergePipe indexes parameter blocks, builds deterministic access plans under a stated I/O budget, and executes the resulting budgeted merge via replayable manifests. For fixed-coefficient additive operators the omitted-update error is bounded by the norm of the omitted deltas; the plan recovers the full-read merge exactly when the budget permits full access.
What carries the argument
The expert access-set problem that selects subsets of delta blocks under an explicit I/O budget while preserving merge semantics through deterministic, budget-sound plans.
If this is right
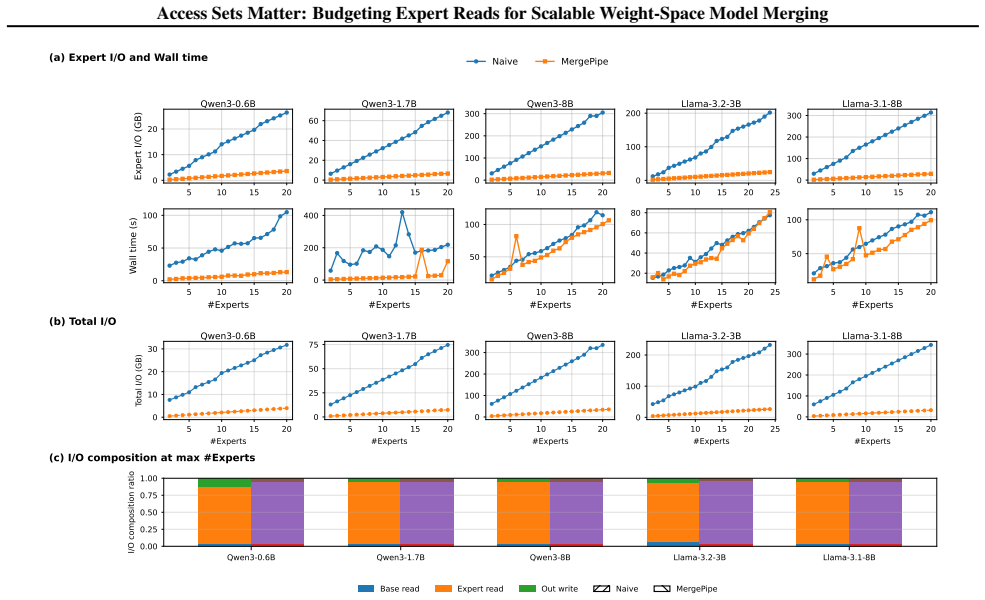
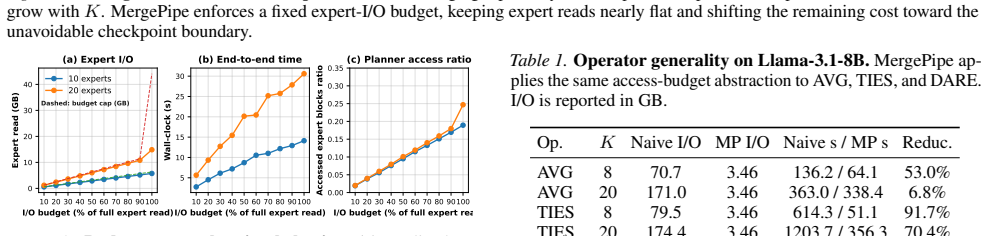
- Expert-read I/O falls by up to an order of magnitude on representative Qwen and Llama merging workloads.
- Execution time improves by up to 11 times compared with full-read baselines.
- Parameter deviation from the full-read result stays at O(10^{-3}) across tested budgets.
- Downstream benchmark scores exhibit no monotonic degradation even when the budget is reduced.
Where Pith is reading between the lines
- The same access-planning layer could be applied to other weight-space operations once error bounds are derived for non-additive operators.
- Access budgeting may become a standard middleware layer for any operation that must combine multiple large checkpoints.
- Hardware with memory too small to hold all checkpoints simultaneously could still perform merges that previously required full simultaneous residency.
Load-bearing premise
The checkpoints occupy a shared weight coordinate system and the merge operators are fixed-coefficient additions of deltas.
What would settle it
A direct run on the same Qwen or Llama workload showing that the budgeted merge deviates by substantially more than 0.001 in parameter norm or produces consistent benchmark degradation relative to the full-access merge.
Figures
read the original abstract
Weight-space model merging is usually formulated as an algebraic operation on checkpoints, yet at LLM scale the limiting resource is often the set of expert weights that must be read. We introduce MergePipe, a budget-aware execution layer that casts LLM merging as an \emph{expert access-set} problem: given a merge operator and a checkpoint family in a shared weight coordinate system, choose which expert delta blocks to access under an explicit I/O budget. MergePipe indexes parameter blocks, builds deterministic access plans, and executes the induced budgeted merge with replayable manifests. The plan is budget-sound by construction and recovers the full-read merge at full budget; for fixed-coefficient additive operators, the omitted-update error is bounded by the norm of omitted deltas. Across Qwen and Llama merging workloads, MergePipe reduces expert-read I/O by up to an order of magnitude and achieves up to $11\times$ speedups. Representative budget sweeps show $O(10^{-3})$ parameter deviation from full-read merges and no monotonic degradation on downstream benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MergePipe, by casting LLM merging as an expert access-set problem and building deterministic access plans under an I/O budget, can reduce expert-read I/O by up to an order of magnitude and achieve up to 11× speedups on Qwen and Llama workloads. It states that the plans are budget-sound by construction, recover the full merge at full budget, and for fixed-coefficient additive operators the omitted-update error is bounded by the norm of omitted deltas, with empirical results showing O(10^{-3}) parameter deviation and no monotonic degradation on downstream benchmarks.
Significance. If the results hold, this work could make weight-space model merging more scalable by addressing the I/O bottleneck at LLM scale. The explicit construction of budget-sound plans and the error bound are notable strengths, as is the empirical demonstration on real models.
major comments (1)
- [Abstract] The error bound for the omitted-update is stated but no derivation or proof is provided, which is central to validating the correctness of the budgeted merge for the restricted operator class.
minor comments (2)
- [Abstract] The experimental protocol, including how budgets are swept and data-exclusion rules, is not described, making it difficult to reproduce the reported speedups and deviation results.
- [Abstract] The specific merge operators and checkpoint families used in the Qwen and Llama experiments are not named, limiting the ability to assess the generality of the claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential significance and for the constructive comment. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] The error bound for the omitted-update is stated but no derivation or proof is provided, which is central to validating the correctness of the budgeted merge for the restricted operator class.
Authors: We agree that the abstract states the bound without an accompanying derivation. The current manuscript provides only an informal justification in the methods section. In the revised version we will add an explicit proof (or detailed derivation) showing that, for fixed-coefficient additive operators, the omitted-update error is bounded by the norm of the omitted deltas. This proof will be placed in the main text (likely as a new subsection or appendix reference) rather than left implicit. revision: yes
Circularity Check
No significant circularity; method is an explicit algorithmic construction
full rationale
The paper defines MergePipe as a budget-aware layer that builds deterministic access plans which are budget-sound by construction and recover the full merge at full budget. This is a definitional property of the proposed execution layer rather than a derived claim. The error bound for fixed-coefficient additive operators is stated directly from the norm of omitted deltas under the shared-coordinate assumption. Empirical results (I/O reduction, speedups, parameter deviation) are reported as measurements on Qwen/Llama workloads, not as predictions obtained by fitting to the same data. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The derivation chain is therefore self-contained as an engineering construction with explicitly stated operating assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Checkpoints reside in a shared weight coordinate system.
invented entities (1)
-
MergePipe
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Chen, M. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dua, D., Wang, Y ., Dasigi, P., Stanovsky, G., Singh, S., and Gardner, M. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378,
2019
-
[3]
InfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models
Gu, Y ., Wang, Y ., Yan, Z., Zhang, Y ., Zhou, Q., Wu, F., and Yang, H. Infifpo: Implicit model fusion via preference optimization in large language models.arXiv preprint arXiv:2505.13878,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
FeatCal: Feature Calibration for Post-Merging Models
Gu, Y ., Cai, S., Wang, Z., Wang, W., Wang, Y ., Wang, P., Huang, S., Lu, S., Wu, J., and Yang, H. Featcal: Fea- ture calibration for post-merging models.arXiv preprint arXiv:2605.13030,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Liu, S., Wu, H., He, B., Han, X., Yuan, M., and Song, L. Sens-merging: Sensitivity-guided parameter balanc- ing for merging large language models.arXiv preprint arXiv:2502.12420, 2025a. Liu, Z., Wu, H., Yao, Y ., She, R., Han, X., Zhong, T., and Yuan, M. Lore-merging: Exploring low-rank estima- tion for large language model merging.arXiv preprint arXiv:25...
-
[6]
H., Alim, K., ArjomandBigdeli, A., Srivastava, A., Ahmed, F., and Azizan, N
Nobari, A. H., Alim, K., ArjomandBigdeli, A., Srivastava, A., Ahmed, F., and Azizan, N. Activation-informed merging of large language models.arXiv preprint arXiv:2502.02421,
-
[7]
Discovering Physical Directions in Weight Space: Composing Neural PDE Experts
Wang, P., Liu, P., Wang, Y ., Chen, G., Ren, X., Li, X., Hao, Z., Kong, Y ., Zhang, Q., and Ni, D. Discovering physical directions in weight space: Composing neural pde experts.arXiv preprint arXiv:2605.14546, 2026a. Wang, W., Gu, Y ., Cai, S., Wang, Y ., Wang, P., Wu, J., and Yang, H. E-pmq: Expert-guided post-merge quan- tization with merged-weight anch...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
Wang, Y ., Lu, S., Gu, Y ., Wang, P., Yang, Y ., Yan, Z., Xie, C., Wu, J., and Yang, H. Not all disagreement is learnable: Token teachability in on-policy distillation, 2026c. Wang, Y ., Yan, Z., Zhang, Y ., Zhou, Q., Gu, Y ., Wu, F., and Yang, H. Infigfusion: Graph-on-logits distillation via efficient gromov-wasserstein for model fusion.Advances in Neura...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
Yang, E., Shen, L., Guo, G., Wang, X., Cao, X., Zhang, J., and Tao, D. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities.arXiv preprint arXiv:2408.07666,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Instruction-Following Evaluation for Large Language Models
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y ., Zhou, D., and Hou, L. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
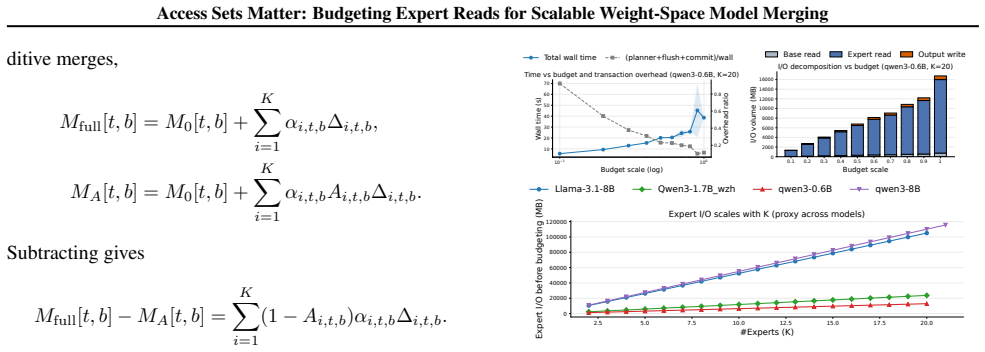
Base reads and output writes are checkpoint-boundary costs, while planning and transac- tional overhead remain small compared with tensor stream- ing
I/O Breakdown and Overhead.Figure 5 shows that the gains come from reducing the expert-read term rather than from metadata effects. Base reads and output writes are checkpoint-boundary costs, while planning and transac- tional overhead remain small compared with tensor stream- ing. C. Limitations MergePipe targets budgeted weight-space access for check- p...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.