Xetrieval: Mechanistically Explaining Dense Retrieval
Pith reviewed 2026-06-29 07:16 UTC · model grok-4.3
The pith
Xetrieval explains individual dense retrieval decisions by enriching embeddings with single-pass reasoning approximations then decomposing them into sparse interpretable features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
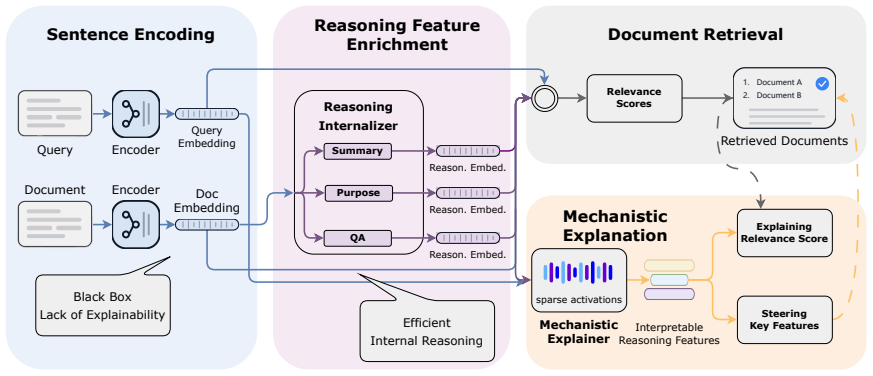
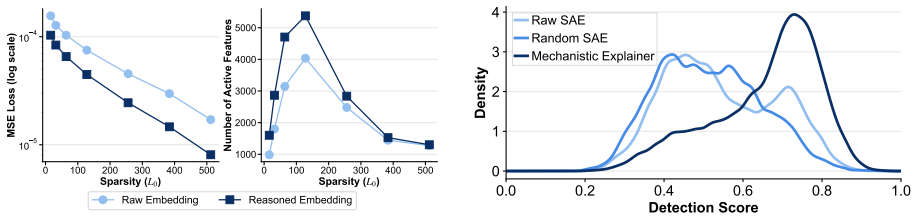
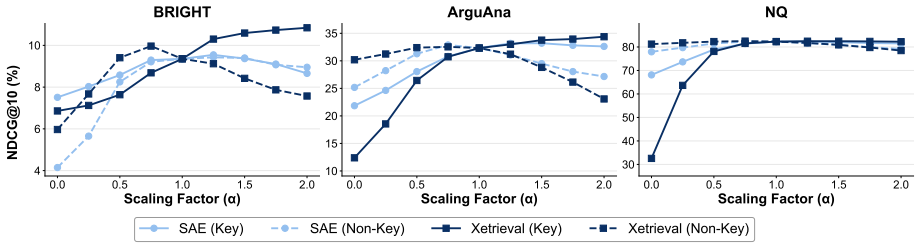
Xetrieval first introduces a lightweight reasoning internalizer that approximates Chain-of-Thought reasoning directly in the embedding space with a single forward pass, enriching sentence embeddings with reasoning-oriented information while avoiding expensive autoregressive generation. It then decomposes these reasoning-enhanced embeddings into sparse, human-interpretable features, each associated with a coherent natural language description. By aggregating sparse feature overlaps across multiple document-side views, Xetrieval provides feature-level explanations of individual retrieval decisions.
What carries the argument
Lightweight reasoning internalizer that produces reasoning-enriched embeddings, followed by their decomposition into sparse features with natural-language labels whose overlaps explain retrieval scores.
If this is right
- The same enriched embeddings yield coherent interpretable features across multiple retrievers and benchmarks.
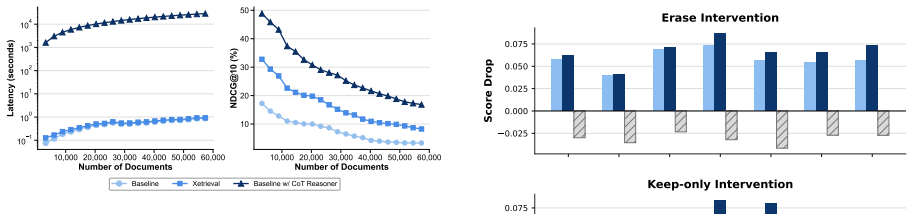
- Pair-level interventions on the identified features produce stronger effects on retrieval scores than surface-signal baselines.
- Task-level steering becomes possible by amplifying or suppressing specific sparse features.
- Explanations remain available without any autoregressive generation at inference time.
Where Pith is reading between the lines
- The same decomposition could be applied to embedding-based models outside retrieval, such as rerankers or dense passage encoders in question answering.
- If the sparse features prove stable across retraining runs, they could serve as a diagnostic for systematic retrieval biases.
- Feature-level steering might allow lightweight editing of retrieval behavior without full model retraining.
- Extending the internalizer to multi-turn or multi-document reasoning chains would test whether the single-pass approximation scales.
Load-bearing premise
The single-forward-pass internalizer actually injects reasoning information that remains both faithful to explicit Chain-of-Thought and useful for the later sparse decomposition step.
What would settle it
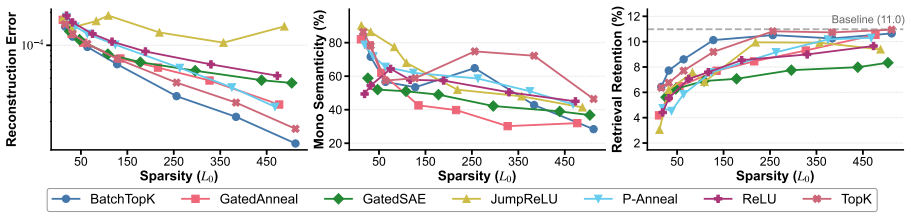
Human raters find no coherent natural-language descriptions for the extracted sparse features, or targeted interventions on those features produce no measurable change in the original retriever's relevance scores.
Figures


read the original abstract
Explaining why dense retrievers assign high relevance scores remains challenging because retrieval decisions are made through opaque high-dimensional embeddings. Existing explanations often focus on surface signals, such as lexical matches, token alignments, or post-hoc textual rationales, and thus provide limited insight into the latent factors that shape dense retrieval behavior at the embedding level. We propose \textit{Xetrieval}, an embedding-level mechanistic framework for explaining dense retrieval. \textit{Xetrieval} first introduces a lightweight reasoning internalizer that approximates Chain-of-Thought reasoning directly in the embedding space with a single forward pass, enriching sentence embeddings with reasoning-oriented information while avoiding expensive autoregressive generation. It then decomposes these reasoning-enhanced embeddings into sparse, human-interpretable features, each associated with a coherent natural language description. By aggregating sparse feature overlaps across multiple document-side views, \textit{Xetrieval} provides feature-level explanations of individual retrieval decisions. Experiments on diverse retrievers and benchmarks show that \textit{Xetrieval} uncovers coherent interpretable features, yields stronger pair-level intervention effects, and supports task-level feature steering. The project page and source code are available at https://hihiczx.github.io/Xetrieval .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Xetrieval, a framework for mechanistic explanations of dense retrieval. It proposes a lightweight reasoning internalizer that enriches embeddings with Chain-of-Thought-like information via a single forward pass, followed by sparse decomposition into interpretable features with natural language descriptions, and aggregation of feature overlaps across document views to explain individual retrieval decisions. Experiments on multiple retrievers and benchmarks claim coherent features, stronger pair-level intervention effects, and support for task-level feature steering.
Significance. If the internalizer faithfully injects reasoning information that remains linearly separable and the feature overlaps causally relate to retrieval scores, the work would provide a rare embedding-level mechanistic account of retrieval, moving beyond lexical or post-hoc textual explanations. The public code release is a positive contribution for reproducibility.
major comments (2)
- [Method section (lightweight reasoning internalizer)] Method section (lightweight reasoning internalizer): The core claim that a single non-autoregressive forward pass approximates multi-step Chain-of-Thought reasoning is load-bearing for the subsequent sparse decomposition and feature-overlap explanations, yet the manuscript provides no direct test (e.g., comparison of enriched embeddings against autoregressive CoT trajectories on the same inputs or ablation removing sequential dependencies) showing preservation of causal structure rather than surface correlations.
- [Experiments section (intervention effects)] Experiments section (intervention effects): The reported stronger pair-level intervention effects are central to validating the explanations, but without an ablation that isolates the contribution of the reasoning internalizer versus the sparse decomposition alone, it is unclear whether the observed effects follow from the claimed mechanistic enrichment.
minor comments (1)
- [Abstract and Method] The abstract and method descriptions use the term 'approximates Chain-of-Thought' without a precise operational definition or reference to how faithfulness is measured.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify important gaps in validation of the lightweight reasoning internalizer and in isolating its contribution to the reported intervention effects. We address each point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Method section (lightweight reasoning internalizer)] The core claim that a single non-autoregressive forward pass approximates multi-step Chain-of-Thought reasoning is load-bearing for the subsequent sparse decomposition and feature-overlap explanations, yet the manuscript provides no direct test (e.g., comparison of enriched embeddings against autoregressive CoT trajectories on the same inputs or ablation removing sequential dependencies) showing preservation of causal structure rather than surface correlations.
Authors: We agree that a direct comparison between the single-pass internalizer outputs and autoregressive CoT trajectories would provide stronger evidence that causal structure is preserved rather than surface correlations. Our current support for the claim rests on indirect downstream indicators: the enriched embeddings produce more coherent natural-language features and yield larger pair-level intervention effects than non-enriched baselines. We will revise the method section to explicitly acknowledge this limitation, add a discussion of why a direct autoregressive comparison is non-trivial (different output spaces and computational cost), and include a new small-scale experiment that measures embedding similarity or downstream retrieval alignment between internalizer outputs and CoT-augmented embeddings on a subset of the data. revision: partial
-
Referee: [Experiments section (intervention effects)] The reported stronger pair-level intervention effects are central to validating the explanations, but without an ablation that isolates the contribution of the reasoning internalizer versus the sparse decomposition alone, it is unclear whether the observed effects follow from the claimed mechanistic enrichment.
Authors: We accept this criticism. The current experiments compare full Xetrieval against non-enriched baselines but do not hold the sparse decomposition fixed while toggling the internalizer. We will add a controlled ablation in the experiments section that applies the same sparse decomposition pipeline to both original and internalizer-enriched embeddings and reports the resulting intervention effect sizes. This will directly isolate the internalizer's contribution to the observed gains. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The manuscript describes Xetrieval as a two-stage framework (lightweight reasoning internalizer followed by sparse decomposition and feature-overlap aggregation) whose central claims rest on experimental outcomes rather than on any closed mathematical loop. No equations appear in the supplied text, no parameters are fitted to a target quantity and then re-used as a 'prediction,' and no self-citations are invoked to justify uniqueness or to smuggle in an ansatz. The internalizer is introduced as an engineering choice whose faithfulness is asserted to be demonstrated by downstream intervention results; nothing in the text reduces that claim to a definitional identity or to a prior result authored by the same team. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embeddings produced by a single forward pass through a lightweight module can faithfully approximate the information that would be obtained from full autoregressive Chain-of-Thought generation.
- domain assumption The resulting enriched embeddings admit a sparse decomposition into features that each possess a coherent natural-language description and whose overlaps across query and document sides causally explain retrieval scores.
invented entities (1)
-
lightweight reasoning internalizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hao Kang, Tevin Wang, and Chenyan Xiong
Laser: Internalizing explicit reasoning into latent space for dense retrieval.arXiv preprint arXiv:2603.01425. Hao Kang, Tevin Wang, and Chenyan Xiong. 2025. In- terpret and control dense retrieval with sparse latent features. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associ- ation for Computational Linguistics: Hu...
-
[2]
Chain Of Thought Compression: A Theoretical Analysis
Measuring progress in dictionary learning for language model interpretability with board game models.Advances in Neural Information Processing Systems, 37:83091–83118. Omar Khattab and Matei Zaharia. 2020. Colbert: Effi- cient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conf...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Lucas Moeller, Dmitry Nikolaev, and Sebastian Padó
dictionary_learning. Lucas Moeller, Dmitry Nikolaev, and Sebastian Padó
-
[4]
arXiv preprint arXiv:2310.05703
An attribution method for siamese encoders. arXiv preprint arXiv:2310.05703. Dmitry Nikolaev and Sebastian Padó. 2023. Investi- gating semantic subspaces of transformer sentence embeddings through linear structural probing.arXiv preprint arXiv:2310.11923. Juri Opitz and Anette Frank. 2022. Sbert studies mean- ing representations: Decomposing sentence embe...
-
[5]
Gonçalo Paulo, Alex Mallen, Caden Juang, and Nora Belrose
Decoding dense embeddings: Sparse au- toencoders for interpreting and discretizing dense retrieval.arXiv preprint arXiv:2506.00041. Gonçalo Paulo, Alex Mallen, Caden Juang, and Nora Belrose. 2024. Automatically interpreting millions of features in large language models.arXiv preprint arXiv:2410.13928. Xubo Qin, Jun Bai, Jiaqi Li, Zixia Jia, and Zilong Zheng
-
[6]
Tongsearch-qr: Reinforced query reasoning for retrieval.arXiv preprint arXiv:2506.11603. Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. 2024a. Improving dictionary learning with gated sparse autoencoders. arXiv preprint arXiv:2404.16014. Senthooran Rajamanoharan, Tom Lieberum, Ni...
-
[7]
InTREC, volume 409, page 410
Trec 2019 news track overview. InTREC, volume 409, page 410. Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S Siegel, Michael Tang, and 1 others
2019
-
[8]
10 Axel Suarez, Dyaa Albakour, David Corney, Miguel Martinez, and José Esquivel
Bright: A realistic and challenging bench- mark for reasoning-intensive retrieval.arXiv preprint arXiv:2407.12883. 10 Axel Suarez, Dyaa Albakour, David Corney, Miguel Martinez, and José Esquivel. 2018. A data collection for evaluating the retrieval of related tweets to news articles. InEuropean Conference on Information Retrieval, pages 780–786. Ellen V o...
-
[9]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Retrieval of the best counterargument without prior topic knowledge. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 241–251. Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly- supervised contrastive pre-training.arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. 2024. Arctic-embed 2.0: Multilingual retrieval without compromise.arXiv preprint arXiv:2412.04506. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, and 1 others. 2025a....
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.