DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
Pith reviewed 2026-06-29 07:10 UTC · model grok-4.3
The pith
DeepSurvey generates deeper automated surveys by extracting full-text keynotes and enforcing evidence-based citations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
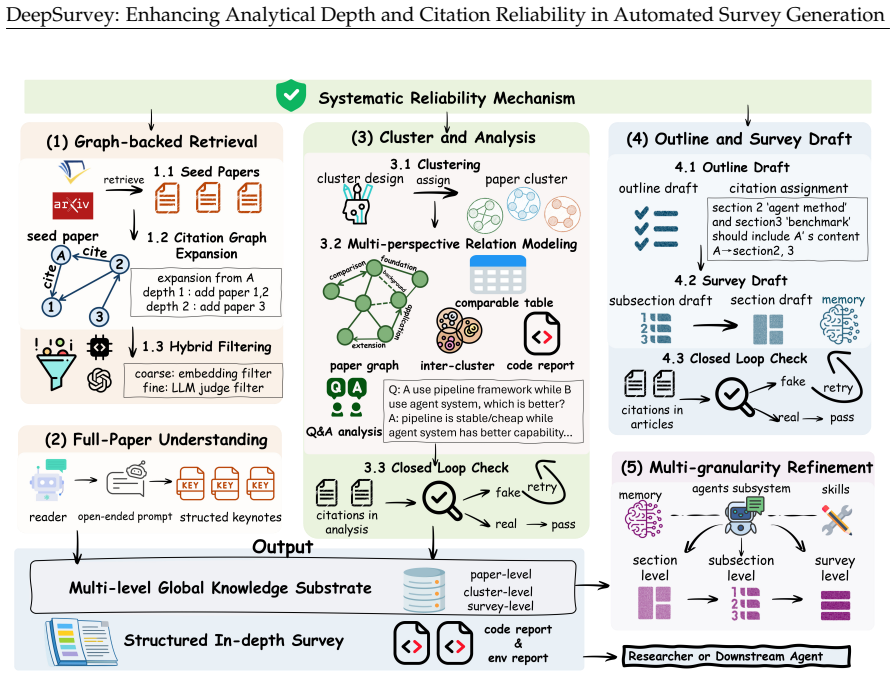
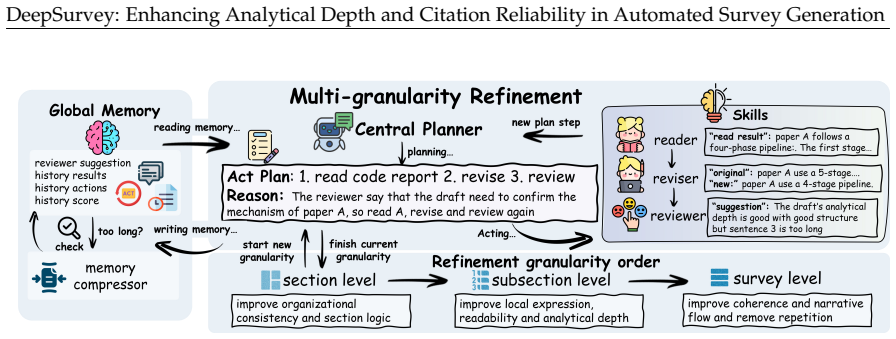
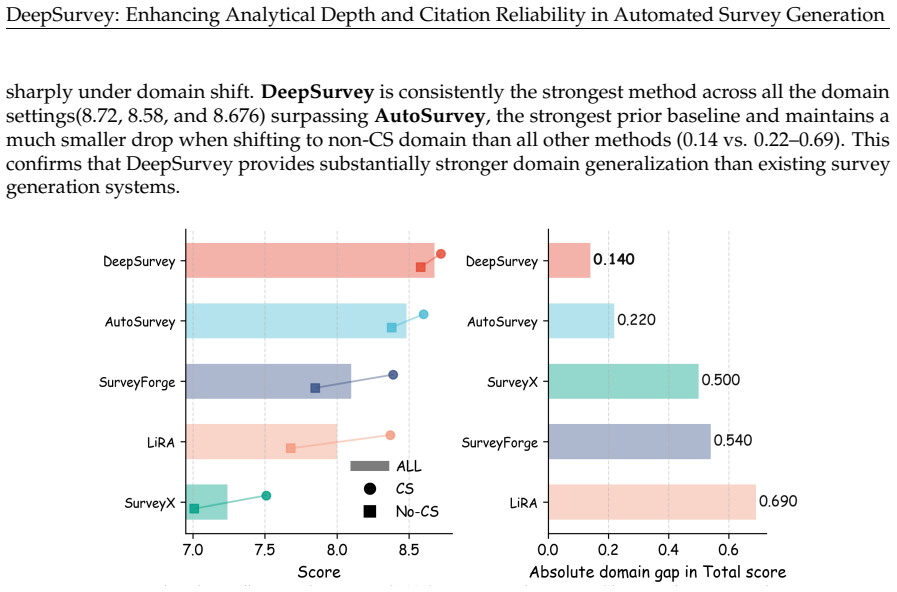
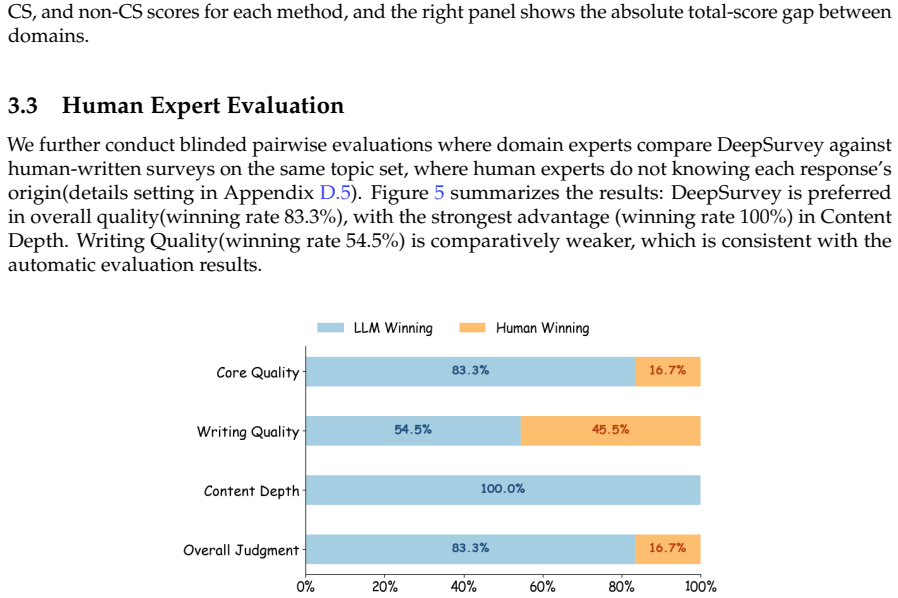
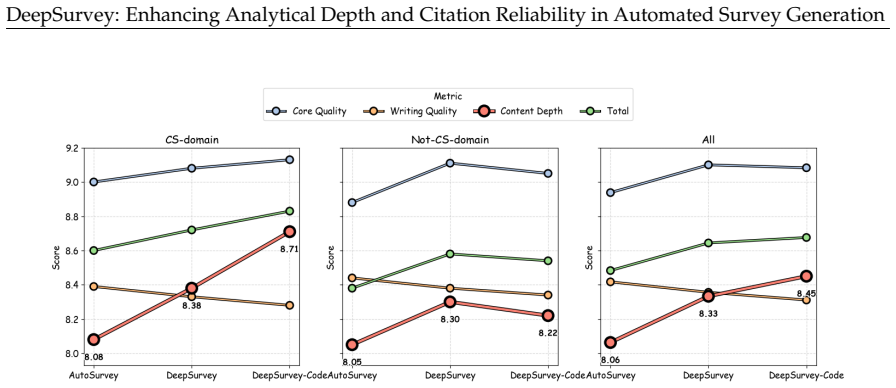
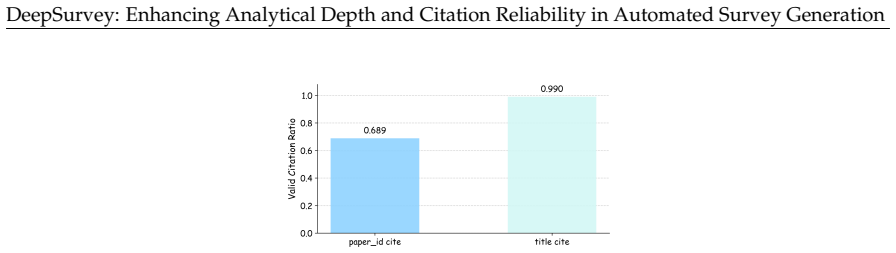
DeepSurvey is an agentic system that improves analytical depth by extracting structured keynotes from full-text papers, modeling relationships through clustering and comparative analysis, and incorporating code-repository details, while strengthening citation reliability through citation-graph expansion with hybrid filtering, evidence-constrained assignment, and multi-granularity agentic refinement, yielding the highest content score of 8.644 out of 10, citation quality gains of 12.3 percent recall and 9.3 percent precision over the strongest baseline, reduced performance drop across domains, and 83.3 percent overall quality preference from domain experts.
What carries the argument
The agentic pipeline that extracts full-text keynotes, clusters cross-paper relationships, integrates code analysis, expands citation graphs with filters, and validates citations through evidence constraints and multi-granularity refinement.
If this is right
- Automated surveys will reach higher measured content depth and citation alignment than prior systems.
- Performance will degrade less when moving from computer science to other domains.
- Domain experts will select the generated surveys over human-written ones at the reported rates for overall quality and content depth.
- Citation recall and precision will increase by the stated margins relative to baselines.
Where Pith is reading between the lines
- The same pipeline could be tested on literature in rapidly evolving fields to check whether code-repository integration adds measurable value beyond text analysis.
- If the evidence constraints scale, they might reduce the rate at which generated surveys introduce unsupported claims when the source corpus grows.
- Combining the clustering step with temporal ordering of papers could allow the system to surface how ideas evolve across time.
Load-bearing premise
The experimental comparisons with baselines and human raters accurately reflect true gains in analytical depth and citation reliability.
What would settle it
A blinded replication study in which independent domain experts rate surveys generated by DeepSurvey and by the strongest baseline on a fresh set of papers, scoring depth and citation accuracy without knowing the source.
Figures


read the original abstract
As scientific literature grows rapidly, automated survey generation has become a key capability for AI scientists and human researchers. However, existing systems suffer from limited analytical depth due to reliance on abstracts and isolated paper processing, and unreliable citations from imprecise retrieval and post-hoc grounding, producing superficial surveys and may mislead researchers. We present DeepSurvey, an agentic system that addresses both. To enhance depth, DeepSurvey extracts structured keynotes from full-text papers, models cross-paper relationships through clustering and comparative analysis, and integrates code-repository analysis to recover implementation-level details. To fortify reliability, it combines citation-graph expansion with hybrid filtering for topic-focussed retrieval, enforces evidence-constrained citation assignment, and deploys multi-granularity agentic refinement to validate citation-claim alignment. Experiments show that DeepSurvey achieves the highest content score (8.644/10) and citation quality (12.3% and 9.3% recall and precision gains over the strongest baseline), generalizes more robustly across domains (0.14 vs 0.22 to 0.69 CS-to-non-CS drop), and is preferred over human-written surveys by domain experts (83.3% overall quality, 100% content depth).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeepSurvey, an agentic system for automated survey generation from scientific literature. It claims to improve analytical depth via extraction of structured keynotes from full-text papers, cross-paper clustering and comparative analysis, and integration of code-repository analysis; and to improve citation reliability via citation-graph expansion with hybrid filtering, evidence-constrained citation assignment, and multi-granularity agentic refinement. The abstract reports that DeepSurvey achieves the highest content score (8.644/10), citation quality gains (12.3% recall and 9.3% precision over the strongest baseline), more robust cross-domain generalization (0.14 drop vs. 0.22–0.69 for baselines), and is preferred by domain experts over human-written surveys (83.3% overall quality, 100% content depth).
Significance. If the reported experimental gains can be substantiated with transparent methodology, baselines, and controls, the work would address two central limitations in automated literature synthesis—superficial depth from abstract-only processing and unreliable citations—and could provide a practical advance for AI-assisted research tools. The combination of full-text keynotes, clustering, code analysis, and constrained citation mechanisms is a coherent agentic design whose attribution to the claimed components would be a notable contribution if isolated from confounds.
major comments (2)
- [Abstract] Abstract: The manuscript states specific quantitative outcomes (content score 8.644/10, 12.3%/9.3% citation gains, 0.14 domain-drop, 83.3%/100% expert preference) but supplies no description of the evaluation datasets, baseline implementations, scoring rubrics for 'analytical depth' or 'citation quality', ground-truth citation sets, human-rater selection/blinding procedures, or statistical tests. These omissions make it impossible to determine whether the numerical deltas are attributable to the proposed components (full-text keynotes, clustering, code analysis, hybrid filtering, evidence-constrained assignment) or to uncontrolled factors such as prompt engineering or base-model differences.
- [Abstract] Abstract: The generalization and preference claims presuppose controlled comparisons (CS-to-non-CS domain shift, expert raters with domain expertise, blinding to system identity). Without any protocol details, the reported margins cannot be treated as evidence that the agentic pipeline improves robustness or depth beyond what simpler baselines achieve.
minor comments (1)
- [Abstract] Abstract, sentence 3: 'producing superficial surveys and may mislead researchers' is grammatically incomplete; rephrase to 'which may mislead researchers'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments regarding the need for greater methodological transparency. We agree that the abstract and current manuscript text omit key details on datasets, baselines, rubrics, protocols, and controls, which prevents proper assessment of whether the reported gains can be attributed to the proposed components. We will perform a major revision to add these descriptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states specific quantitative outcomes (content score 8.644/10, 12.3%/9.3% citation gains, 0.14 domain-drop, 83.3%/100% expert preference) but supplies no description of the evaluation datasets, baseline implementations, scoring rubrics for 'analytical depth' or 'citation quality', ground-truth citation sets, human-rater selection/blinding procedures, or statistical tests. These omissions make it impossible to determine whether the numerical deltas are attributable to the proposed components (full-text keynotes, clustering, code analysis, hybrid filtering, evidence-constrained assignment) or to uncontrolled factors such as prompt engineering or base-model differences.
Authors: We agree with this assessment. The current manuscript does not supply the requested descriptions of datasets, baselines, rubrics, ground-truth sets, rater procedures, or statistical tests. We will revise the manuscript by adding a dedicated subsection in Experiments that fully documents these elements (including dataset sources and sizes, exact baseline implementations and prompts, rubrics for depth and citation quality, ground-truth construction, rater selection and blinding, and statistical tests) and will update the abstract to reference this section. This will enable readers to evaluate attribution to the agentic components versus confounds. revision: yes
-
Referee: [Abstract] Abstract: The generalization and preference claims presuppose controlled comparisons (CS-to-non-CS domain shift, expert raters with domain expertise, blinding to system identity). Without any protocol details, the reported margins cannot be treated as evidence that the agentic pipeline improves robustness or depth beyond what simpler baselines achieve.
Authors: We agree that the absence of protocol details prevents treating the reported margins as evidence. The manuscript currently lacks explicit descriptions of the domain-shift setup, rater expertise criteria, and blinding procedures. We will revise by adding these protocol details to the Experiments section (specifying how domain shift was controlled, rater qualifications, and blinding methods) and will include a concise summary in the abstract. This will clarify how the comparisons isolate the contribution of the proposed pipeline. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical description of an agentic survey-generation system and reports experimental metrics (content scores, citation recall/precision, domain generalization, expert preference) without any equations, mathematical derivations, fitted parameters presented as predictions, or first-principles claims. No self-definitional reductions, ansatzes smuggled via citation, or uniqueness theorems appear in the provided abstract or described structure. The central claims rest on experimental comparisons rather than any chain that reduces to its own inputs by construction; therefore the paper is self-contained against the circularity criteria.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
Xcientist externalizes research synthesis and validation in AI scientists via contract-governed artifacts to maintain traceable trajectories and avoid claim drift across three domains.
Reference graph
Works this paper leans on
-
[1]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
C. Lu, C. Lu, R. T. Langeet al., “The ai scientist: Towards fully automated open-ended scientific discovery,” ArXiv, vol. abs/2408.06292, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:271854887
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Y. Yamada, R. T. Lange, C. Luet al., “The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search,”ArXiv, vol. abs/2504.08066, 2025. [Online]. Available: https: //api.semanticscholar.org/CorpusID:277741107
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Autosurvey: Large language models can automatically write surveys,
Y. Wang, Q. Guo, W. Yaoet al., “Autosurvey: Large language models can automatically write surveys,” ArXiv, vol. abs/2406.10252, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:270560509
-
[4]
Surveyforge: On the outline heuristics, memory-driven generation, and multi-dimensional evaluation for automated survey writing,
X. Yan, S. Feng, J. Yuanet al., “Surveyforge: On the outline heuristics, memory-driven generation, and multi-dimensional evaluation for automated survey writing,” inAnnual Meeting of the Association for Computational Linguistics, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:276813240
2025
-
[5]
Surveyx: Academic survey automation via large language models,
X. Liang, J. Yang, Y. Wanget al., “Surveyx: Academic survey automation via large language models,”ArXiv, vol. abs/2502.14776, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:276482768
-
[6]
Lira: A multi-agent framework for reliable and readable literature review generation,
G. H. T. Go, K. Ly, A. Sogaardet al., “Lira: A multi-agent framework for reliable and readable literature review generation,” inAAAI Conference on Artificial Intelligence, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281886200
2025
-
[7]
Llm ×mapreduce-v3: Enabling interactive in-depth survey generation through a mcp-driven hierarchically modular agent system,
Y. Chao, S. Lin, X. Wanget al., “Llm ×mapreduce-v3: Enabling interactive in-depth survey generation through a mcp-driven hierarchically modular agent system,” inConference on Empirical Methods in Natural Language Processing, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:282057493
2025
-
[8]
M.-A. Nguye, M. D. Nguyen, H. L. N.T.et al., “Surveyg: A multi-agent llm framework with hierarchical citation graph for automated survey generation,”ArXiv, vol. abs/2510.07733, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281951129
-
[9]
Autosurvey2: Empowering researchers with next level automated literature surveys,
S. Wu, C. X. Liang, Z. Biet al., “Autosurvey2: Empowering researchers with next level automated literature surveys,”ArXiv, vol. abs/2510.26012, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID: 282592838
-
[10]
Scisage: A multi-agent framework for high-quality scientific survey generation,
X. Shi, Q. Kou, Y. Liet al., “Scisage: A multi-agent framework for high-quality scientific survey generation,” ArXiv, vol. abs/2506.12689, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:279402998
-
[11]
SurGE: A Benchmark and Evaluation Framework for Scientific Survey Generation
W. Su, A. Xie, Q. Aiet al., “Surge: A benchmark and evaluation framework for scientific survey generation,” arXiv preprint arXiv:2508.15658, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
SurveyGen: Quality-aware scientific survey generation with large language models,
T. Bao, M. T. Nayeem, D. Rafieiet al., “SurveyGen: Quality-aware scientific survey generation with large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Roseet al., Eds. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 2712–2736. [...
2025
-
[13]
LLM ×MapReduce: Simplified long-sequence processing using large language models,
Z. Zhou, C. Li, X. Chenet al., “LLM ×MapReduce: Simplified long-sequence processing using large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutovaet al., Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 27 664–27 ...
2025
-
[14]
Agentic autosurvey: Let llms survey llms,
Y. Liu, Y. Wu, D. Zhanget al., “Agentic autosurvey: Let llms survey llms,”ArXiv, vol. abs/2509.18661, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281495800
-
[15]
The semantic scholar academic graph (s2ag),
A. D. Wade, “The semantic scholar academic graph (s2ag),”Companion Proceedings of the Web Conference 2022,
2022
-
[16]
Available: https://api.semanticscholar.org/CorpusID:251597885
[Online]. Available: https://api.semanticscholar.org/CorpusID:251597885
-
[17]
S2ORC: The semantic scholar open research corpus,
K. Lo, L. L. Wang, M. Neumannet al., “S2ORC: The semantic scholar open research corpus,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluteret al., Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 4969–4983. [Online]. Available: https://aclanthology.org/2020.acl...
2020
-
[18]
Explicit semantic ranking for academic search via knowledge graph embedding,
C. Xiong, R. Power, and J. Callan, “Explicit semantic ranking for academic search via knowledge graph embedding,”Proceedings of the 26th International Conference on World Wide Web, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:1644335
2017
-
[19]
Scientific article summarization using citation-context and article’s discourse structure,
A. Cohan and N. Goharian, “Scientific article summarization using citation-context and article’s discourse structure,” inProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, L. Màrquez, C. Callison-Burch, and J. Su, Eds. Lisbon, Portugal: Association for Computational Linguistics, Sep. 2015, pp. 390–400. [Online]. Availa...
2015
-
[20]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewittet al., “Lost in the middle: How language models use long contexts,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259360665
2023
-
[21]
Context length alone hurts llm performance despite perfect retrieval,
Y. Du, M. Tian, S. Ronankiet al., “Context length alone hurts llm performance despite perfect retrieval,” ArXiv, vol. abs/2510.05381, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281826429
-
[22]
Towards long context hallucination detection,
S. Liu, K. Halder, Z. Qiet al., “Towards long context hallucination detection,” inNorth American Chapter of the Association for Computational Linguistics, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID: 278165123
2025
-
[23]
MiMo-V2-Flash Technical Report
X. Xiao, B. Xia, B. Yanget al., “Mimo-v2-flash technical report,”ArXiv, vol. abs/2601.02780, 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:284513060
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W.-L. Chiang, Y. Shenget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”ArXiv, vol. abs/2306.05685, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259129398
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
G-eval: NLG evaluation using gpt-4 with better human alignment,
Y. Liu, D. Iter, Y. Xuet al., “G-eval: NLG evaluation using gpt-4 with better human alignment,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 2511–2522. [Online]. Available: https://aclanthology.org/2023.e...
2023
-
[26]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631,
L. Zhu, X. Wang, and X. Wang, “Judgelm: Fine-tuned large language models are scalable judges,”ArXiv, vol. abs/2310.17631, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:264490588
-
[27]
Prometheus 2: An open source language model specialized in evaluating other language models,
S. Kim, J. Suk, S. Longpreet al., “Prometheus 2: An open source language model specialized in evaluating other language models,”ArXiv, vol. abs/2405.01535, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:269502688
-
[28]
Mathematical contributions to the theory of evolution.—on a form of spurious correlation which may arise when indices are used in the measurement of organs,
K. Pearson, “Mathematical contributions to the theory of evolution.—on a form of spurious correlation which may arise when indices are used in the measurement of organs,”Proceedings of the royal society of london, vol. 60, no. 359-367, pp. 489–498, 1897
-
[29]
Use of coefficient of variation in assessing variability of quantitative assays,
G. F. Reed, F. Lynn, and B. D. Meade, “Use of coefficient of variation in assessing variability of quantitative assays,”Clinical and Vaccine Immunology, vol. 9, pp. 1235 – 1239, 2002. [Online]. Available: https://api.semanticscholar.org/CorpusID:231319
2002
-
[30]
Interval estimation and optimal design for the within-subject coefficient of variation for continuous and binary variables,
M. M. Shoukri, N. Elkum, and S. D. Walter, “Interval estimation and optimal design for the within-subject coefficient of variation for continuous and binary variables,”BMC Medical Research Methodology, vol. 6, pp. 24 – 24, 2006. [Online]. Available: https://api.semanticscholar.org/CorpusID:264815049
2006
-
[31]
A coefficient of agreement for nominal scales,
J. Cohen, “A coefficient of agreement for nominal scales,”Educational and Psychological Measurement, vol. 20, pp. 37 – 46, 1960. [Online]. Available: https://api.semanticscholar.org/CorpusID:15926286
1960
-
[32]
Measuring nominal scale agreement among many raters
J. L. Fleiss, “Measuring nominal scale agreement among many raters.”Psychological Bulletin, vol. 76, pp. 378–382, 1971. [Online]. Available: https://api.semanticscholar.org/CorpusID:143544759
1971
-
[33]
The automatic creation of literature abstracts,
H. P . Luhn, “The automatic creation of literature abstracts,”IBM J. Res. Dev., vol. 2, pp. 159–165, 1958. [Online]. Available: https://api.semanticscholar.org/CorpusID:15475171
1958
-
[34]
A trainable document summarizer,
J. Kupiec, J. O. Pedersen, and F. R. Chen, “A trainable document summarizer,” inAnnual International ACM SIGIR Conference on Research and Development in Information Retrieval, 1995. [Online]. Available: https://api.semanticscholar.org/CorpusID:5775833 14 DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
1995
-
[35]
LexRank: Graph-based Lexical Centrality as Salience in Text Summarization
G. Erkan and D. R. Radev, “Lexrank: Graph-based lexical centrality as salience in text summarization,” CoRR, vol. abs/1109.2128, 2011. [Online]. Available: http://arxiv.org/abs/1109.2128
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[36]
E. Garfield, “Citation indexes for science,”Science, vol. 122, no. 3159, pp. 108–111, 1955. [Online]. Available: https://www.science.org/doi/abs/10.1126/science.122.3159.108
-
[37]
Co-citation in the scientific literature: A new measure of the relationship between two documents,
H. Small, “Co-citation in the scientific literature: A new measure of the relationship between two documents,” Journal of the American Society for Information Science, vol. 24, no. 4, pp. 265–269, July 1973. [Online]. Available: https://ideas.repec.org/a/bla/jamest/v24y1973i4p265-269.html
1973
-
[38]
Citationas: A tool of automatic survey generation based on citation content,
J. Wang, C. Zhang, M. Zhanget al., “Citationas: A tool of automatic survey generation based on citation content,”Journal of Data and Information Science, vol. 3, pp. 20–37, 06 2018
2018
-
[39]
Networks of scientific papers,
D. J. de Solla Price, “Networks of scientific papers,”Science, vol. 149, no. 3683, pp. 510–515, 1965. [Online]. Available: https://www.science.org/doi/abs/10.1126/science.149.3683.510
-
[40]
Scientific Paper Summarization Using Citation Summary Networks
V . Qazvinian and D. R. Radev, “Scientific paper summarization using citation summary networks,”CoRR, vol. abs/0807.1560, 2008. [Online]. Available: http://arxiv.org/abs/0807.1560
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[41]
Coherent citation-based summarization of scientific papers,
A. Abu-Jbara and D. Radev, “Coherent citation-based summarization of scientific papers,” inProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, D. Lin, Y. Matsumoto, and R. Mihalcea, Eds. Portland, Oregon, USA: Association for Computational Linguistics, Jun. 2011, pp. 500–509. [Online]. Avai...
2011
-
[42]
Efficient estimation of word representations in vector space,
T. Mikolov, K. Chen, G. S. Corradoet al., “Efficient estimation of word representations in vector space,” inInternational Conference on Learning Representations, 2013. [Online]. Available: https://api.semanticscholar.org/CorpusID:5959482
2013
-
[43]
Distributed representations of sentences and documents,
Q. V . Le and T. Mikolov, “Distributed representations of sentences and documents,” inInternational Conference on Machine Learning, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:2407601
2014
-
[44]
Universal sentence encoder for English,
D. Cer, Y. Yang, S.-y. Konget al., “Universal sentence encoder for English,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, E. Blanco and W. Lu, Eds. Brussels, Belgium: Association for Computational Linguistics, Nov. 2018, pp. 169–174. [Online]. Available: https://aclanthology.org/D18-2029/
2018
-
[45]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), K. Inui, J. Jiang, V . Nget al., Eds. Hong Kong, China: Association for Computation...
2019
-
[46]
SPECTER: Document-level representation learning using citation-informed transformers,
A. Cohan, S. Feldman, I. Beltagyet al., “SPECTER: Document-level representation learning using citation-informed transformers,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluteret al., Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 2270–2282. [Online]. Avail...
2020
-
[47]
Mineru: An open-source solution for precise document content extraction,
B. Wang, C. Xu, X. Zhaoet al., “Mineru: An open-source solution for precise document content extraction,”
-
[48]
MinerU: An Open-Source Solution for Precise Document Content Extraction
[Online]. Available: https://arxiv.org/abs/2409.18839
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P . Lewis, E. Perez, A. Piktuset al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” ArXiv, vol. abs/2005.11401, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:218869575
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[50]
R. M. Kinney, C. Anastasiades, R. Authuret al., “The semantic scholar open data platform,”ArXiv, vol. abs/2301.10140, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:256194545
-
[51]
H. Wang, Y. Fu, Z. Zhanget al., “Llm ×mapreduce-v2: Entropy-driven convolutional test-time scaling for generating long-form articles from extremely long resources,” 2025. [Online]. Available: https://arxiv.org/abs/2504.05732
-
[52]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
P . Manakul, A. Liusie, and M. J. F. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,”ArXiv, vol. abs/2303.08896, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257557820 15 DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Lost in inference: Rediscovering the role of natural language inference for large language models,
L. Madaan, D. Esiobu, P . Stenetorpet al., “Lost in inference: Rediscovering the role of natural language inference for large language models,”ArXiv, vol. abs/2411.14103, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:274165430
-
[54]
Explainable hallucination through natural language inference mapping,
W.-F. Chen, Z. Zhao, A. Karimiet al., “Explainable hallucination through natural language inference mapping,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutovaet al., Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 1888–1896. [Online]. Available: https://aclanthology.org/2...
2025
-
[55]
Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers,
W. Wang, H. Bao, S. Huanget al., “Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers,”ArXiv, vol. abs/2012.15828, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:229923069
-
[56]
A. Singh, A. Fry, A. Perelmanet al., “Openai gpt-5 system card,” 2026. [Online]. Available: https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
DeepSeek-AI, A. Liu, B. Fenget al., “Deepseek-v3 technical report,”ArXiv, vol. abs/2412.19437, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:275118643 16 DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation Appendix A Theoretical And Technical Base This section introduces the theoretical and ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
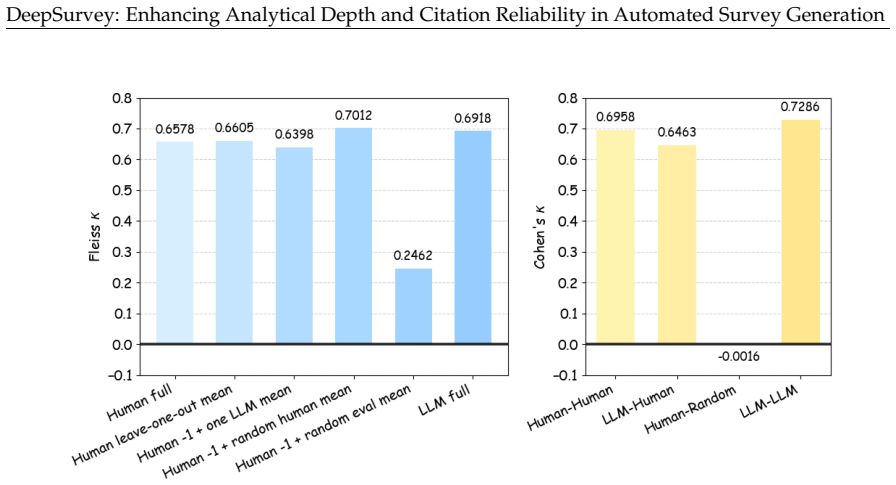
[58]
Key aspects: synthesis, organization, comprehensiveness, relevance
Core Quality Measures whether the review stays closely on topic, effectively integrates the literature, and builds a systematic synthesis. Key aspects: synthesis, organization, comprehensiveness, relevance. Staying on-topic and building a systematic synthesis. Synthesis: integrates papers into a coherent whole, not just listing Organization: logical secti...
-
[59]
Key aspects: readability, academic rigor, clarity & coherence
Writing Quality Measures whether the language expression is clear, rigorous, and coherent, and whether technical details are accurately conveyed. Key aspects: readability, academic rigor, clarity & coherence. Clear, rigorous, and coherent writing. Readability: fluent, natural, easy to follow Academic Rigor: precise, well-supported academic expression Clar...
-
[60]
Content Depth Measures whether the review goes beyond simple summary to offer critical analysis, unique insights, and actionable research suggestions. 25 DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation Key aspects: critical analysis, novelty & insights, specificity, future directions. Going beyond summary to ...
-
[61]
**Modular Agent Architectures**: Separation of planning, retrieval, and generation components
-
[62]
**Hybrid Local/Cloud**: Local models for privacy with cloud APIs for capability
-
[63]
**Evaluation-First Design**: Built-in benchmarking and metrics collection ... 36 DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation H Case Study H.1 Comparison between DeepSurvey and the baseline To further evaluate the quality and depth of the generated surveys, we compare DeepSurvey with the strongest performi...
-
[64]
cluster_name
triggers alignment corrections via [26], followed by [10] evaluation of the refined output, as sketched in Direction 1 of the Code Report. This directly counters the'dimensional poverty' critique by demonstrating how multi-dimensional scoring can be operationalized in a single, actionable system. Concretely, [9]'s six-stage pipeline (task formulation, dec...
-
[65]
The outline should contain multiple sections, subsections and their descriptions
-
[66]
The output outline should have excellent organization and meet academic standards
-
[67]
The outline should exhibit excellent rigor: ensuring that the content of each subsection falls within the scope of the current section
-
[68]
The outline should ensure that it covers a wide range of content under the topic while staying within the scope of the topic
-
[69]
Keep existing sections/subsections unless updated or merged
Use the current outline as the base structure. Keep existing sections/subsections unless updated or merged. If the current outline is empty, create a new outline from scratch
-
[70]
The outline should contain a **Conclusion** section and a **Future Work** section/subsection
-
[71]
The outline should exhibit good logic to ensure the entire survey flows smoothly
-
[72]
Ensure a balanced number of subsections in the main sections (excluding the conclusion and introduction)
-
[73]
Make sure most of the corresponding new paper in **new paper keynotes** can be included in at least one subsection or section of the outline
-
[74]
You are provided with other relevant papers which is retrieved from database, you can use them to better understand and generate
-
[75]
Maintain clarity, logical structure, and a survey-style narrative
-
[76]
Conclusion
Ensure logical coherence between the sections, avoiding excessive independence and fragmentation. For instance, do not add a "Conclusion" subsection to every section, which lead to logical fragmentation between different sections
-
[77]
title" :
Output strictly in JSON format, as shown below. **Input:** - current outline: {current_outline} - key papers: {paper_keynotes} - key papers analysis: {papers_analysis} - other relevant papers: {other_relevant_papers} **Output JSON format:** {{ "title" : "Survey_Title", "sections": [ {{ "title": "Section_title", "description": "Summary of content to includ...
-
[78]
Assign papers based on their relevance to the section and subsection topics
-
[79]
**Requirements:**
Make sure citing according to you assignment is reasonable and appropriate and help to provide insights in the survey. **Requirements:**
-
[80]
Assign EVERY paper in **key papers** to be assigned to one or more corresponding sections or subsections
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.