K-FinHallu: A Hallucination Detection Benchmark for Multi-Turn RAG in Korean Finance
Pith reviewed 2026-06-29 08:52 UTC · model grok-4.3
The pith
K-FinHallu benchmark finds even frontier LLMs struggle to detect hallucinations and justified abstention in multi-turn Korean financial RAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
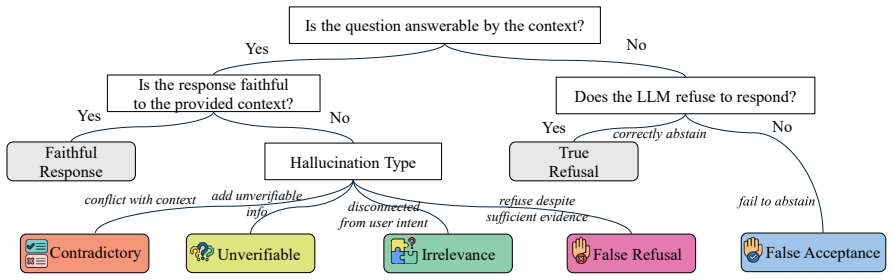
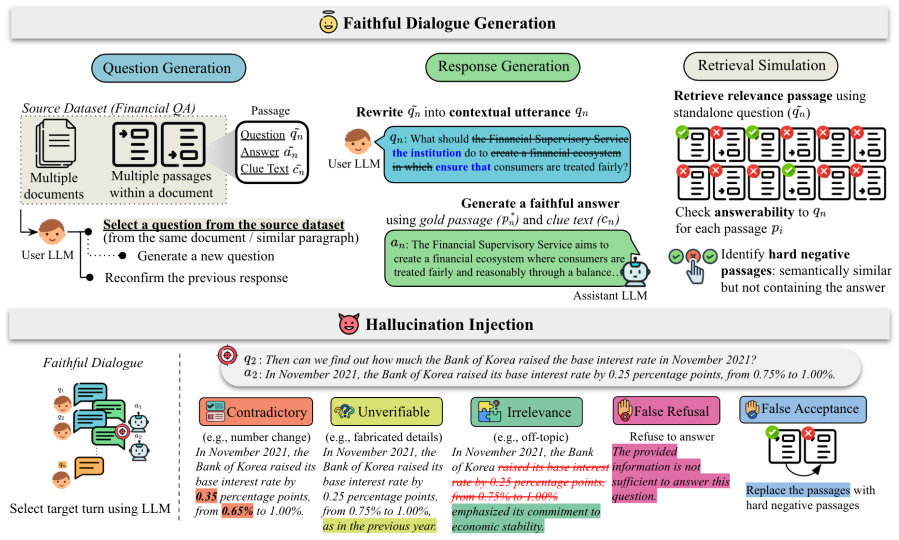
The K-FinHallu benchmark constructs multi-turn dialogues from authentic Korean financial documents and injects hallucinations using a hierarchical taxonomy based on context answerability that accounts for justified abstention. Benchmarking shows frontier and open-source LLMs as detectors struggle with fine-grained financial diagnostics and refusal behavior, though fine-tuning an 8B model yields performance competitive with frontier LLMs, with justified abstention remaining the weakest axis.
What carries the argument
Hierarchical taxonomy based on context answerability for classifying hallucination types and justified abstention in multi-turn dialogues.
If this is right
- Fine-tuning smaller models on the benchmark training data can achieve performance close to that of much larger frontier models.
- Justified abstention is the most challenging aspect for hallucination detection across all tested models.
- Current LLMs require better capabilities for handling fine-grained financial information and refusal decisions in conversational settings.
- The benchmark provides a way to evaluate and improve RAG systems in the Korean financial domain.
Where Pith is reading between the lines
- Similar benchmarks may be useful for financial RAG in other languages with specific regulatory contexts.
- Training methods that specifically target uncertainty detection in dialogues could improve abstention rates.
- Integrating this benchmark with retrieval evaluation might reveal whether errors come from bad retrieval or generation.
Load-bearing premise
The proposed hierarchical taxonomy based on context answerability accurately captures the different types of hallucinations and cases of justified abstention in the multi-turn financial dialogues.
What would settle it
Human annotators reviewing a subset of the dialogues and hallucination injections find that the taxonomy labels do not align with the actual nature of the errors or abstention needs.
Figures


read the original abstract
Large Language Models (LLMs) have advanced financial automation through Retrieval-Augmented Generation (RAG), yet hallucinations remain a critical barrier to deployment in high-stakes environments. Existing benchmarks focus on single-turn, English-centric tasks, leaving the multi-turn dynamics and linguistic-regulatory nuances of the Korean financial domain unaddressed. We introduce K-FinHallu, the first benchmark for hallucination detection in multi-turn Korean financial RAG. We construct multi-turn dialogues from authentic Korean financial documents and inject hallucinations under a proposed hierarchical taxonomy based on context answerability that explicitly accounts for justified abstention. Benchmarking frontier and open-source LLMs as hallucination detectors, we find that even the strongest models struggle with fine-grained financial diagnostics and refusal behavior. While fine-tuning an 8B model on our training split yields performance competitive with frontier LLMs, justified abstention remains the weakest axis across all evaluated models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces K-FinHallu, the first benchmark for hallucination detection in multi-turn Korean financial RAG. It constructs multi-turn dialogues from authentic Korean financial documents and injects hallucinations under a hierarchical taxonomy based on context answerability that explicitly accounts for justified abstention. Benchmarking frontier and open-source LLMs as detectors shows that even the strongest models struggle with fine-grained financial diagnostics and refusal behavior; fine-tuning an 8B model on the training split yields performance competitive with frontier LLMs, but justified abstention remains the weakest axis across all models.
Significance. If the taxonomy and dialogue construction hold, the benchmark addresses an important gap in existing single-turn, English-centric hallucination evaluations by targeting multi-turn dynamics and Korean financial-regulatory nuances. This is relevant for high-stakes RAG deployment; the explicit treatment of justified abstention is a strength if the labeling is reliable.
minor comments (2)
- [Abstract] The abstract states the taxonomy is 'hierarchical' and 'based on context answerability' but provides no enumeration of categories, decision rules, or inter-annotator agreement statistics; without these, it is impossible to assess whether the taxonomy correctly separates hallucination types from justified abstention.
- [Abstract] No details are given on the number of dialogues, document sources, injection procedure, or exact metrics (e.g., precision/recall per axis, refusal rate); these omissions prevent verification of the claim that fine-tuned 8B performance is 'competitive' or that abstention is 'weakest'.
Simulated Author's Rebuttal
We thank the referee for their summary of K-FinHallu and for recognizing its relevance to multi-turn Korean financial RAG hallucination detection, including the explicit handling of justified abstention. We note that the report contains no specific major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity
full rationale
This is a benchmark construction paper with no mathematical derivations, equations, predictions, or first-principles claims. The work introduces a dataset and taxonomy for hallucination detection in Korean financial RAG dialogues; the taxonomy is explicitly proposed as part of the contribution rather than derived from prior results or self-citations. No load-bearing step reduces to a fit, self-definition, or author-overlapping citation chain. The evaluation of LLMs on the benchmark is a standard empirical comparison and does not rely on internal circular logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[3]
Kedi Chen, Qin Chen, Jie Zhou, He Yishen, and Liang He. 2024. Diahalu: A dialogue-level hallucination evaluation benchmark for large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 9057--9079
2024
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, and 3416 others. 2025. https://arxiv.org/abs/2507.06261 Gemini 2.5: Pus...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Nouha Dziri, Ehsan Kamalloo, Sivan Milton, Osmar R Za \" ane, Mo Yu, Edoardo M Ponti, and Siva Reddy. 2022. Faithdial: A faithful benchmark for information-seeking dialogue. Transactions of the Association for Computational Linguistics, 10:1473--1490
2022
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Kilem Li Gwet. 2008. Computing inter-rater reliability and its variance in the presence of high agreement. British Journal of Mathematical and Statistical Psychology, 61(1):29--48
2008
-
[8]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3
2022
-
[10]
Youngjoon Jang, Junyoung Son, and Taemin Lee. 2024. Kure: Korea university retrieval embedding model. https://github.com/nlpai-lab/KURE
2024
-
[11]
Kanana LLM . 2025. https://huggingface.co/collections/kakaocorp/kanana-2 Kanana-2 llm
2025
-
[12]
Yannis Katsis, Sara Rosenthal, Kshitij Fadnis, Chulaka Gunasekara, Young-Suk Lee, Lucian Popa, Vraj Shah, Huaiyu Zhu, Danish Contractor, and Marina Danilevsky. 2025. Mtrag: A multi-turn conversational benchmark for evaluating retrieval-augmented generation systems. Transactions of the Association for Computational Linguistics, 13:784--808
2025
-
[13]
Lanlan Ji Dominic Seyler Gunkirat Kaur, Manjunath Hegde Koustuv Dasgupta Bing Xiang, and Goldman Sachs. 2025. Phantom: A benchmark for hallucination detection in financial long-context qa
2025
-
[14]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626
2023
- [15]
- [16]
- [17]
-
[18]
Xiang Li, Zhenyu Li, Chen Shi, Yong Xu, Qing Du, Mingkui Tan, and Jun Huang. 2024. Alphafin: Benchmarking financial analysis with retrieval-augmented stock-chain framework. In Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024), pages 773--783
2024
-
[19]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214--3252
2022
-
[20]
Oscar Lithgow-Serrano, David Kletz, Vani Kanjirangat, David Adametz, Marzio Lunghi, Claudio Bonesana, Matilde Tristany Farinha, Yuntao Li, Detlef Repplinger, Marco Pierbattista, and 1 others. 2025. Assessing rag system capabilities on financial documents. In The 10th Workshop on Financial Technology and Natural Language Processing, page 124
2025
- [21]
-
[22]
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. 2024. Ragtruth: A hallucination corpus for developing trustworthy retrieval-augmented language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10862--10878
2024
-
[23]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, and 401 others. 2024. https://arxiv.org/abs/2410.21276 Gpt-4o system card . Preprint, arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
OpenAI . 2025. Gpt-5 system card. https://cdn.openai.com/gpt-5-system-card.pdf. OpenAI system card, accessed 2026-01-06
2025
- [25]
-
[26]
Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249--266
2019
-
[27]
Jaehyung Seo, Jaewook Lee, Chanjun Park, SeongTae Hong, Seungjun Lee, and Heui-Seok Lim. 2024. Kocommongen v2: A benchmark for navigating korean commonsense reasoning challenges in large language models. In Findings of the Association for Computational Linguistics ACL 2024, pages 2390--2415
2024
-
[28]
Jaehyung Seo and Heuiseok Lim. 2025. K-halu: Multiple answer korean hallucination benchmark for large language models. In The Thirteenth International Conference on Learning Representations
2025
- [29]
-
[30]
Guijin Son, Hanwool Lee, Sungdong Kim, Seungone Kim, Niklas Muennighoff, Taekyoon Choi, Cheonbok Park, Kang Min Yoo, and Stella Biderman. 2025. Kmmlu: Measuring massive multitask language understanding in korean. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Te...
2025
-
[31]
Guijin Son, Hanwool Lee, Suwan Kim, Huiseo Kim, Jae cheol Lee, Je Won Yeom, Jihyu Jung, Jung woo Kim, and Songseong Kim. 2024. Hae-rae bench: Evaluation of korean knowledge in language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 7993--8007
2024
-
[32]
Zhongkai Sun, Yingxue Zhou, Jie Hao, Xing Fan, Yanbin Lu, Chengyuan Ma, Wei Shen, and Chenlei Guo. 2023. Improving contextual query rewrite for conversational ai agents through user-preference feedback learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 432--439
2023
-
[33]
Qwen Team. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Shuting Wang, Jiejun Tan, Zhicheng Dou, and Ji-Rong Wen. 2025. Omnieval: An omnidirectional and automatic rag evaluation benchmark in financial domain. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5737--5762
2025
-
[35]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, and 1 others. 2024. Finben: A holistic financial benchmark for large language models. Advances in Neural Information Processing Systems, 37:95716--95743
2024
-
[36]
Sungjin Yun. 2020. https://doi.org/10.1108/IJHMA-03-2020-0025 Neighborhood effects of housing program using jeonse in korea . International Journal of Housing Markets and Analysis, 14(2):305--316
-
[37]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. 2024. https://arxiv.org/abs/2408.05517 Swift:a scalable lightweight infrastructure for fine-tuning . Preprint, arXiv:2408.05517
-
[38]
Yingxue Zhou, Jie Hao, Mukund Rungta, Yang Liu, Eunah Cho, Xing Fan, Yanbin Lu, Vishal Vasudevan, Kellen Gillespie, and Zeynab Raeesy. 2023. Unified contextual query rewriting. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 608--615
2023
-
[39]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[40]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.