UI-KOBE: Knowledge-Oriented Behavior Exploration for Lightweight Graph-Guided GUI Agents
Pith reviewed 2026-06-29 07:07 UTC · model grok-4.3
The pith
Lightweight mobile GUI agents improve by using app-specific graphs to guide their runtime choices instead of planning everything from screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
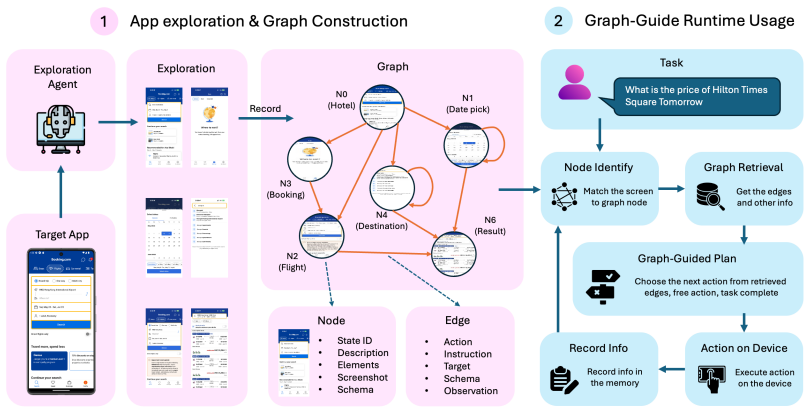
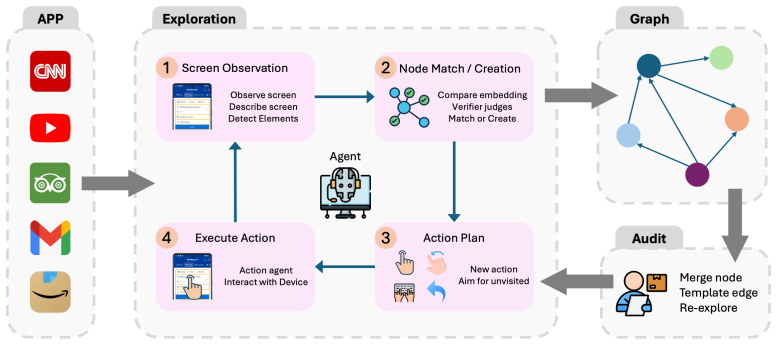
UI-KOBE first autonomously explores a mobile application and constructs an app knowledge graph, where nodes represent distinct UI states and edges represent executable transitions. At runtime, a lightweight GUI agent uses the graph as external guidance: given a user task and the current screenshot, it identifies the current graph node and selects among self-loop actions, neighboring transitions, task completion, or fallback free actions associated with that node.
What carries the argument
The app knowledge graph, where nodes represent distinct UI states and edges represent executable transitions; it supplies node-specific action options to reduce the agent's planning scope at runtime.
Load-bearing premise
The lightweight agent must correctly map each screenshot to its matching graph node and the explored graph must contain the transitions required to finish the target tasks.
What would settle it
A test showing frequent node misidentification from screenshots or tasks failing due to missing graph edges would disprove the effectiveness of the guidance mechanism.
Figures
read the original abstract
Recent advances in mobile GUI agents have shown strong potential for automating mobile tasks, but most effective systems still depend on large vision-language models for screenshot understanding and long-horizon planning. Small GUI agents that can be deployed directly on mobile devices are more attractive for practical use, offering lower inference cost and better protection of sensitive on-device information. However, due to limited model capacity, such lightweight agents remain unreliable when planning and executing GUI tasks end-to-end from screenshots alone. We propose Knowledge-Oriented Behavior Exploration (\textbf{UI-KOBE}), a framework that improves lightweight mobile GUI agents with reusable app-specific graph knowledge. UI-KOBE first autonomously explores a mobile application and constructs an app knowledge graph, where nodes represent distinct UI states and edges represent executable transitions. At runtime, a lightweight GUI agent uses the graph as external guidance: given a user task and the current screenshot, it identifies the current graph node and selects among self-loop actions, neighboring transitions, task completion, or fallback free actions associated with that node. By supporting runtime decisions with app-specific graph guidance, UI-KOBE reduces the burden of end-to-end GUI planning and helps lightweight models perform mobile GUI tasks more effectively, offering a practical step toward efficient, interpretable, and privacy-conscious on-device GUI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UI-KOBE, a framework that autonomously explores a mobile app to construct a knowledge graph (nodes as UI states, edges as transitions) and then guides a lightweight GUI agent at runtime: the agent identifies the current node from a screenshot and restricts its choices to the node's self-loops, neighbors, task-completion action, or fallback free actions.
Significance. If the node-identification step is reliable and the graph covers required transitions, the approach could meaningfully reduce planning load for capacity-limited on-device agents, yielding gains in inference cost, privacy, and interpretability over pure end-to-end VLM planning.
major comments (2)
- [Abstract (runtime node identification paragraph)] Abstract (runtime node identification paragraph): the claimed reduction in planning burden rests entirely on the lightweight model correctly mapping the current screenshot to the right graph node so that only the node's local actions are considered. No matching procedure, accuracy metric, or ablation on identification failure is supplied; low recall would cause reversion to unrestricted free actions and erase the benefit.
- [Abstract (graph construction and usage)] Abstract (graph construction and usage): the framework assumes the autonomously built graph contains the transitions needed for target tasks, yet no coverage statistics, task-completion rates, or comparison against an unguided baseline are reported. Without these, the practical utility of the external guidance cannot be assessed.
minor comments (1)
- The abstract states that the graph is 'reusable' but provides no mechanism or experiment showing reuse across tasks or apps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly highlight areas where the abstract and supporting evidence could be strengthened. We address each major comment below and commit to revisions that add the requested details without altering the core claims.
read point-by-point responses
-
Referee: [Abstract (runtime node identification paragraph)] Abstract (runtime node identification paragraph): the claimed reduction in planning burden rests entirely on the lightweight model correctly mapping the current screenshot to the right graph node so that only the node's local actions are considered. No matching procedure, accuracy metric, or ablation on identification failure is supplied; low recall would cause reversion to unrestricted free actions and erase the benefit.
Authors: We agree that the abstract does not detail the node-identification procedure or its reliability. The full manuscript describes the procedure in Section 3.3 (embedding-based visual similarity plus UI-element overlap), but we acknowledge the absence of quantitative accuracy metrics and failure ablations. In the revision we will add a new subsection reporting node-identification precision/recall on held-out screenshots and an ablation measuring end-to-end task success when identification is artificially degraded, thereby quantifying the benefit of the guidance mechanism. revision: yes
-
Referee: [Abstract (graph construction and usage)] Abstract (graph construction and usage): the framework assumes the autonomously built graph contains the transitions needed for target tasks, yet no coverage statistics, task-completion rates, or comparison against an unguided baseline are reported. Without these, the practical utility of the external guidance cannot be assessed.
Authors: The referee is correct that the abstract and current results section do not explicitly report graph coverage statistics or direct unguided-baseline comparisons. While the manuscript contains task-completion experiments, we will revise both the abstract and the experimental section to include (1) coverage metrics (fraction of required task transitions present in the constructed graph) and (2) side-by-side success rates versus an unguided lightweight agent, making the utility of the external guidance measurable. revision: yes
Circularity Check
No circularity: descriptive framework with no equations or self-referential reductions.
full rationale
The paper describes a procedural system (autonomous exploration to build an app knowledge graph, followed by runtime node identification and restricted action selection) without any mathematical derivations, fitted parameters, or predictions that reduce to the inputs by construction. No equations appear in the abstract or described method. No self-citations are invoked as load-bearing premises. The central claim is an empirical engineering proposal whose validity rests on external evaluation rather than definitional equivalence. This matches the default expectation of a non-circular systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lightweight models benefit from external structured knowledge to compensate for limited planning capacity
invented entities (1)
-
App knowledge graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Androidworld: A dynamic benchmarking environment for autonomous agents.Preprint, arXiv:2405.14573. Yuchen Sun, Shanhui Zhao, Tao Yu, Hao Wen, Samith Va, Mengwei Xu, Yuanchun Li, and Chongyang Zhang. 2025. Gui-xplore: Empowering generaliz- able gui agents with one exploration. InProceedings of the computer vision and pattern recognition con- ference, pages...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mai-ui technical report: Real-world centric foundation gui agents.Preprint, arXiv:2512.22047. 10 A Appendix A.1 Empirical Study of Design Choices We further study several alternative design choices for graph retrieval and graph construction. These preliminary experiments help explain why UI- KOBE adopts screenshot-based node matching and one-step edge con...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.