AsymVLM: Asymmetric Token Pruning for Efficient Vision-Language Model Inference
Pith reviewed 2026-06-29 08:46 UTC · model grok-4.3
The pith
AsymVLM prunes vision tokens before prefill and text tokens during decoding using separate strategies based on their different properties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AsymVLM applies aggressive pruning to vision tokens before prefill using a learned importance scorer with per-sample adaptive budgeting, and temporal threshold-based eviction to text tokens only when they exceed a fixed budget. Experiments show this yields the highest FLOPs savings among state-of-the-art methods while outperforming them by 2-3 percent on document and chart understanding tasks where visual information is spatially localized and query-specific, and remains competitive on holistic benchmarks. In text-dominated cases the eviction approach also beats standard LLM cache compression by adapting to short VLM contexts.
What carries the argument
The asymmetric pruning mechanism that scores vision tokens for spatial importance with adaptive prefill budgeting and applies budget-threshold eviction to text tokens based on their causal accumulation.
If this is right
- Uniform token compression methods leave efficiency on the table because they ignore modality-specific redundancy patterns.
- Document and chart tasks benefit most because their visual content is localized and query-dependent.
- Text-token eviction remains effective when context stays short, unlike methods tuned for long LLM sequences.
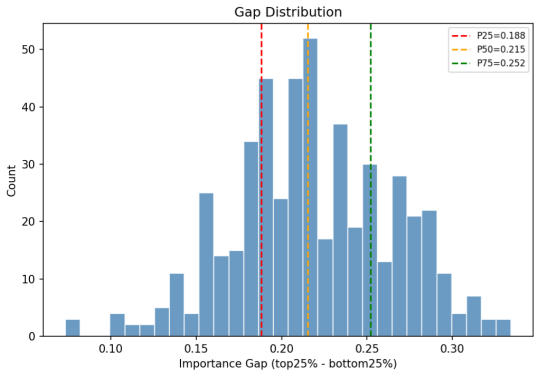
- Overall FLOPs reduction reaches 54 percent while accuracy holds or improves relative to prior compression techniques.
Where Pith is reading between the lines
- The same separation of concerns could be tested on other multimodal models that mix image patches with sequential text.
- Training the importance scorer jointly with the VLM rather than as a separate stage might further reduce information loss.
- The adaptive budgeting rule could be extended to decide pruning ratios based on query length or image complexity at runtime.
Load-bearing premise
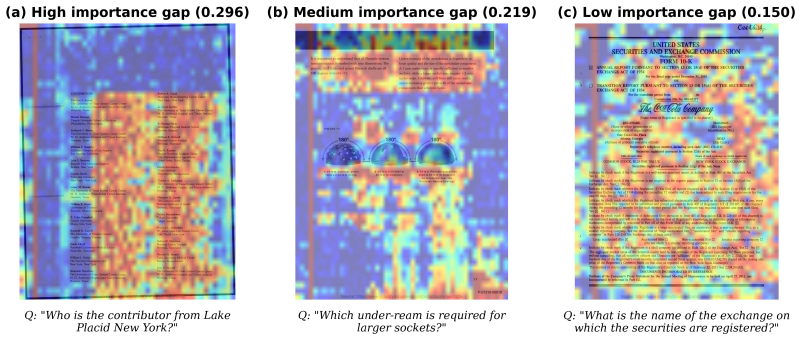
Vision tokens contain enough spatial redundancy that a learned scorer can safely discard most of them before prefill without removing information the query needs.
What would settle it
A controlled test on a chart-understanding query where the scorer removes a token that contains the only instance of a number or label referenced in the question and accuracy falls below the unpruned baseline.
Figures

read the original abstract
Vision-Language Models (VLMs) process thousands of visual tokens per image alongside comparatively few text tokens, yet existing compression methods treat both modalities uniformly. We observe that the two modalities have fundamentally different properties: vision tokens are spatially redundant and dominate prefill, while text tokens are causally dependent and accumulate during decoding. Based on this asymmetry, we propose and empirically evaluate AsymVLM, which applies aggressive pruning to vision tokens before prefill using a learned importance scorer with per-sample adaptive budgeting, and temporal threshold-based eviction to text tokens only when they exceed a fixed budget. Our experiments indicate that AsymVLM achieves the highest FLOPs savings (up to 54%) among state-of-the-art methods while outperforming existing approaches by 2--3% on document and chart understanding tasks where visual information is spatially localized and query-specific, and maintaining competitive accuracy on holistic benchmarks. In text-dominated scenarios, our eviction strategy substantially outperforms standard LLM cache compression methods by adapting to the short-context nature of VLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AsymVLM for efficient VLM inference by exploiting modality asymmetry: aggressive prefill pruning of vision tokens via a learned importance scorer with per-sample adaptive budgeting, combined with temporal threshold-based eviction applied only to text tokens during decoding. It claims up to 54% FLOPs savings (highest among SOTA) while outperforming baselines by 2-3% on document/chart tasks (where visual tokens are spatially localized and query-specific) and remaining competitive on holistic benchmarks; text-eviction also outperforms standard LLM cache methods in short-context VLM settings.
Significance. If the empirical gains hold under reproducible conditions and the pruning demonstrably retains query-critical visual tokens, the asymmetric treatment of modalities could meaningfully advance efficient VLM deployment by avoiding uniform compression. The approach builds on observed differences in spatial redundancy versus causal dependence, but the current lack of inspectable protocols, controls, and scorer details limits assessment of whether the claimed query-specific advantages are realized.
major comments (2)
- [Abstract] Abstract: the central claim of 2--3% outperformance on document/chart tasks (where visual information is spatially localized and query-specific) depends on the prefill pruning step successfully retaining query-relevant vision tokens. The description of the 'learned importance scorer with per-sample adaptive budgeting' does not indicate whether the scorer receives the text query as input; if it operates on image tokens alone, decisions are query-agnostic, directly undermining the premise that the method exploits query-specific localization.
- [Abstract] Abstract: the reported empirical wins (FLOPs savings, accuracy deltas) are presented without any experimental protocol, dataset details, ablation controls, error bars, or baseline implementations. This absence makes the soundness of the 54% savings and 2--3% gains impossible to evaluate from the provided text, rendering the quantitative claims uninspectable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments highlight opportunities to improve clarity regarding the query-awareness of the pruning mechanism and the inspectability of empirical claims. We address each point below and will make revisions to the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 2--3% outperformance on document/chart tasks (where visual information is spatially localized and query-specific) depends on the prefill pruning step successfully retaining query-relevant vision tokens. The description of the 'learned importance scorer with per-sample adaptive budgeting' does not indicate whether the scorer receives the text query as input; if it operates on image tokens alone, decisions are query-agnostic, directly undermining the premise that the method exploits query-specific localization.
Authors: We agree that the abstract does not explicitly state whether the importance scorer receives the text query. This omission creates ambiguity. The full manuscript describes the scorer as taking both vision tokens and text query embeddings as input to enable query-specific token retention. We will revise the abstract to explicitly note that the scorer is conditioned on the text query, thereby supporting the query-specific localization premise. revision: yes
-
Referee: [Abstract] Abstract: the reported empirical wins (FLOPs savings, accuracy deltas) are presented without any experimental protocol, dataset details, ablation controls, error bars, or baseline implementations. This absence makes the soundness of the 54% savings and 2--3% gains impossible to evaluate from the provided text, rendering the quantitative claims uninspectable.
Authors: The abstract is a concise summary and therefore omits full experimental details, which are provided in Sections 4 and 5 of the manuscript (including dataset names such as DocVQA and ChartQA, ablation studies, error bars from repeated runs, and baseline re-implementations). To address inspectability concerns directly in the abstract, we will add a brief reference to the key datasets and evaluation settings while retaining the high-level claims. revision: yes
Circularity Check
No circularity; empirical method with no self-referential equations or fitted predictions
full rationale
The provided abstract and description contain no equations, no fitted parameters renamed as predictions, and no derivation chain. The method is presented as an empirical proposal based on observed modality asymmetry, with performance claims tied to experiments rather than any mathematical reduction to inputs. No self-citations or uniqueness theorems are invoked in a load-bearing way. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Kaitong Cai, Jusheng Zhang, Jing Yang, Yijia Fan, Pengtao Xie, Jian Wang, and Keze Wang. Flashvlm: Text-guided visual token selection for large multimodal models.arXiv preprint arXiv:2512.20561,
-
[4]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gemma Team: Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024a. Ziyu Liu, Tao Chu, Yuhang Zang, Xilin Wei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Yuanjun Xiong, Yu Qiao, Dahua Lin, et al. Mmdu: A multi-tur...
2022
-
[9]
Dezhan Tu, Danylo Vashchilenko, Yuzhe Lu, and Panpan Xu. Vl-cache: Sparsity and modality- aware kv cache compression for vision-language model inference acceleration.arXiv preprint arXiv:2410.23317,
-
[10]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads. arXiv preprint arXiv:2410.10819, 2024a. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks....
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gu- dovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsifica- tion for efficient vision-language model inference.arXiv preprint arXiv:2410.04417,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.