ReactBench: A Cause-Driven Benchmark for Multimodal Hallucination via Systematic Evaluation
Pith reviewed 2026-06-29 08:23 UTC · model grok-4.3
The pith
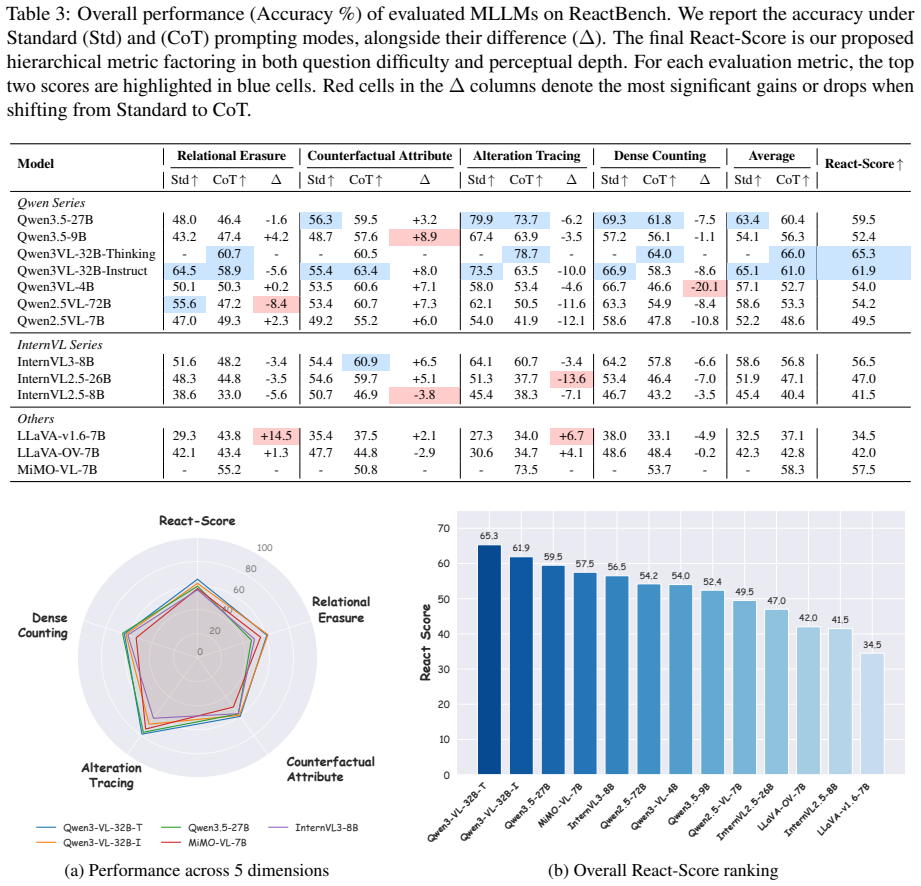
ReactBench introduces four cause-specific tasks that expose how multimodal models hallucinate due to co-occurrence bias, language priors, and perceptual limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReactBench generates adversarial images and hallucination-inducing queries for the tasks Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting. These systematically target co-occurrence bias, language priors, cross-image comparative perception deficiencies, and fine-grained perceptual bottlenecks. Beyond accuracy scores, Chain-of-Thought reasoning traces fine-grained sub-causes, and evaluations show current MLLMs remain vulnerable to these specific triggers.
What carries the argument
ReactBench benchmark consisting of four tasks that pair generated adversarial images with cause-targeted queries and use Chain-of-Thought evaluation to attribute hallucinations.
If this is right
- Developers can diagnose and target specific hallucination causes rather than treating all failures uniformly.
- Training methods can incorporate the four tasks to reduce co-occurrence bias and fine-grained perception errors.
- Future benchmarks can adopt the adversarial generation and CoT attribution approach to test other model weaknesses.
- Model comparisons become more interpretable by reporting performance broken down by cause.
Where Pith is reading between the lines
- The benchmark could be extended to measure how well fine-tuning on one task reduces errors on the others.
- Integration into model release pipelines would allow users to check robustness against these exact triggers before deployment.
- Similar cause-driven designs might apply to hallucinations in other modalities such as audio or video.
Load-bearing premise
The adversarial images and queries isolate the four intended causes without introducing other uncontrolled factors that would mix up the attribution.
What would settle it
A controlled experiment in which models achieve high accuracy on all four ReactBench tasks yet continue to produce the corresponding hallucinations when the same causes appear in unmodified real-world images would undermine the benchmark's isolation of causes.
Figures





















read the original abstract
While multimodal large language models (MLLMs) have achieved rapid progress in vision-language understanding, they remain prone to multimodal hallucinations, producing responses that are inconsistent with the visual input. Existing benchmarks predominantly focus on detecting hallucination outcomes rather than evaluating the underlying causes of these failures. Moreover, many benchmarks rely on simplistic scenarios and limited evaluation formats that no longer challenge state-of-the-art models. To address these limitations, we introduce ReactBench, a cause-driven hallucination benchmark featuring multiple tasks and an exam-style evaluation format. By generating adversarial images and hallucination-inducing queries, ReactBench introduces four targeted tasks: Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting. These tasks systematically expose co-occurrence bias, language priors, cross-image comparative perception deficiencies, and fine-grained perceptual bottlenecks. Beyond standard accuracy-based evaluation, we leverage Chain-of-Thought reasoning to identify fine-grained sub-causes of hallucination within each task. Extensive evaluations reveal that current MLLMs remain notably vulnerable to cause-specific hallucination triggers, demonstrating the value of ReactBench as a systematic and interpretable testbed for diagnosing and improving multimodal model robustness. The project page is available at https://reactbench.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReactBench, a cause-driven benchmark for multimodal hallucinations in MLLMs. It defines four tasks—Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting—generated via adversarial images and queries to target co-occurrence bias, language priors, cross-image comparative perception deficiencies, and fine-grained perceptual bottlenecks. The benchmark employs an exam-style format and Chain-of-Thought reasoning to identify sub-causes, with evaluations claiming that current MLLMs remain vulnerable to these specific triggers, positioning ReactBench as a systematic diagnostic testbed.
Significance. If the tasks cleanly isolate the four claimed causes without confounding artifacts from image synthesis or query construction, ReactBench would provide a more interpretable alternative to outcome-focused hallucination benchmarks and could guide targeted robustness improvements in vision-language models.
major comments (1)
- [Abstract] Abstract: the central claim that the four tasks 'systematically expose' the intended causes (co-occurrence bias, language priors, cross-image perception, fine-grained bottlenecks) rests on unshown validation. No quantitative isolation check, human study of cause purity, or ablation removing only the target factor is referenced, so model failures cannot be attributed to the claimed mechanisms rather than generation artifacts.
minor comments (2)
- The project page URL is given but no details on how the adversarial image generation pipeline or query templates can be reproduced or extended.
- Notation for the four causes and their mapping to tasks could be tabulated for clarity in the task overview section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of cause isolation. We address the single major comment below and will revise the manuscript to strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the four tasks 'systematically expose' the intended causes (co-occurrence bias, language priors, cross-image perception, fine-grained bottlenecks) rests on unshown validation. No quantitative isolation check, human study of cause purity, or ablation removing only the target factor is referenced, so model failures cannot be attributed to the claimed mechanisms rather than generation artifacts.
Authors: We agree that the abstract's phrasing asserts systematic exposure of the four targeted causes, and the manuscript does not include an explicit quantitative isolation check, human study of cause purity, or ablation that removes only the target factor. Task construction (Sections 3.1–3.4) relies on adversarial image generation and query design intended to isolate each cause (e.g., Relational Erasure removes relational cues while preserving object identity and attributes), and Section 4 reports elevated hallucination rates together with CoT sub-cause analysis. However, these elements do not constitute the formal validation the referee requests. We will add a new subsection (and corresponding appendix) containing (i) a human study in which annotators rate whether each task instance primarily triggers the intended cause and (ii) an ablation comparing targeted versus non-targeted variants. The abstract will be updated to reflect the added evidence. This addresses the concern directly. revision: yes
Circularity Check
No circularity: benchmark construction without derivation or self-referential reduction
full rationale
The paper defines ReactBench via four explicit tasks (Relational Erasure, Counterfactual Attribute, Alteration Tracing, Dense Counting) that generate adversarial images and queries to target specific hallucination causes. No equations, fitted parameters, or predictions appear; the central claim is simply that the constructed benchmark exposes the named causes. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The evaluation results on existing MLLMs are independent measurements and do not reduce to the benchmark definition by construction. This is a standard self-contained benchmark proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversarial images and queries can be constructed to target isolated hallucination causes without confounding effects
Reference graph
Works this paper leans on
-
[1]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930. Assaf Ben-Kish, Moran Yanuka, Morris Alper, Raja Giryes, and Hadar Averbuch-Elor. 2024. Mitigating open-vocabulary caption hallucinations. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22680–22698. Nitzan Bitton-...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14303–14312
Multi-modal hallucination control by vi- sual information grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14303–14312. Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, and 1 others. 2024. Hallusionbench: an advanced diagnos...
2024
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Hongyu Hu, Jiyuan Zhang, Minyi Zhao, and Zhenbang Sun. 2023. Ciem: Contrastive instruction evaluation method for better instruction tuning.arXiv preprint arXiv:2309.02301. Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, a...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
InProceedings of the 32nd ACM International Conference on Multimedia, pages 525– 534
Hal-eval: A universal and fine-grained hallu- cination evaluation framework for large vision lan- guage models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 525– 534. Prannay Kaul, Zhizhong Li, Hao Yang, Yonatan Dukler, Ashwin Swaminathan, CJ Taylor, and Stefano Soatto
-
[5]
When Prompts Override Vision: Prompt-Induced Hallucinations in LVLMs
Throne: An object-based hallucination bench- mark for the free-form generations of large vision- language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 27228–27238. Pegah Khayatan, Jayneel Parekh, Arnaud Dapogny, Mustafa Shukor, Alasdair Newson, and Matthieu Cord. 2026. When prompts override vision: P...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Choose exactly ONE primary sub-cause (SC-1, SC-2, or SC-3)
-
[7]
Base your judgment on BOTH the image (spatial layout of objects) AND the model's reasoning text (what strategy the model used)
-
[8]
If the model's reasoning shows BOTH shortcut calculation AND enumeration errors, choose the one that is the PRIMARY driver of the wrong answer
-
[9]
"" USER_PROMPT_TEMPLATE =
Output your answer in the required JSON format.""" USER_PROMPT_TEMPLATE = """## Task Information - **Object to count**: {object_name} - **Ground truth count**: {gt_count} - **Question**: {question} - **Question type**: {question_type} ## Model's Response (WRONG) {model_response} ## Model's Answer: {extracted_answer} ## Correct Answer: {ground_truth} --- P...
1967
-
[10]
Was the specified object correctly and completely removed in the edited image?
-
[11]
Are there obvious visual artifacts, unnatural patches, or ghostly remnants at the deletion area?
-
[12]
Is the rest of the scene (background, other objects) properly preserved?
-
[13]
Would these issues affect the ability to ask clear questions about the deleted object? === PHASE 2: SCENE ANALYSIS (focus on EDITED image) ===
-
[14]
Describe the PRECISE spatial location where the deleted object used to be (look at original image for reference, describe relative to landmarks visible in BOTH images)
-
[15]
Be very specific — look at the edited image pixel-level
In the EDITED image, what is ACTUALLY VISIBLE at that exact location now? (e.g., background wall revealed, floor surface, another object that was behind/beneath, or truly empty space). Be very specific — look at the edited image pixel-level
-
[16]
Does the SAME TYPE of object (as the deleted one) still exist ANYWHERE ELSE in the edited image? Look very carefully at every part of the image
-
[17]
none"}} discard_instance: {{yes / no}} discard_reason: {{reason if yes, or
If yes: describe exactly where, and assess whether the deleted location vs. remaining location can be UNAMBIGUOUSLY distinguished using language alone (without coordinates). === PHASE 3: STRUCTURED OUTPUT === Output ALL fields below, strictly one per line, no markdown, no asterisks, no extra text before or after the fields. IMPORTANT: ALL field values MUS...
-
[18]
After editing, the object must still be clearly recognizable as the original object
-
[19]
The counter-commonsense aspect should be reflected in a key attribute, not by turning it into an entirely different object
-
[20]
Preserve the target object's core identity features, main structure, and recognition cues
-
[21]
Keep the background, composition, position, pose, proportions, and surrounding objects unchanged
-
[22]
counter-commonsense
The editing result must look like a real photograph. Task Requirements: You are now a senior image-editing expert. I will provide an image and a [target object name]. You need to observe the image, locate the object, and determine whether it is suitable for editing. [Step 1: Suitability Assessment] If any of the following conditions apply, output directly...
-
[23]
Requirement: The object's identity and main structure must still be preserved after replacement
[Material Replacement] Change the object to a material that genuinely exists but would not normally be used for this object. Requirement: The object's identity and main structure must still be preserved after replacement
-
[24]
Requirement: After the color change, it should look as if the object was originally this color, not as if a coat of paint was applied over it
[Color Shift] Change the object to a color that genuinely exists, is naturally subdued, but should not appear on this object. Requirement: After the color change, it should look as if the object was originally this color, not as if a coat of paint was applied over it
-
[25]
Requirement: The texture should look as if it is natively part of the object, not pasted on
[Surface Texture / Pattern] Give the object a surface texture, pattern, or skin characteristic that genuinely exists on other objects. Requirement: The texture should look as if it is natively part of the object, not pasted on
-
[26]
Requirement: Moderate in degree; it should look like a natural real-world state, not a disaster special effect
[State Anomaly] Change the object to a state that this object would not normally be in, but that other real-world objects could plausibly exhibit. Requirement: Moderate in degree; it should look like a natural real-world state, not a disaster special effect
-
[27]
Requirement: Must still be photorealistic and natural
[Finish / Gloss Reversal] Change the object to a surface finish or gloss state that clearly does not match its nature but genuinely exists. Requirement: Must still be photorealistic and natural
-
[28]
Requirement: The change must be natural and recognizable; it must not turn the object into an obviously different class of object
[Shape / Structure Counter-Commonsense] Make a counter-commonsense change to the object's shape, proportions, contour, or structure. Requirement: The change must be natural and recognizable; it must not turn the object into an obviously different class of object. Priority guidelines by object type: - Natural creations / food / plants / fruits and vegetabl...
-
[29]
a different new object
Do not turn the target into "a different new object"
-
[30]
No high-saturation, high-purity, fluorescent, electric, or neon colors
-
[31]
No sci-fi elements, glowing elements, LEDs, circuit-trace patterns, or holographic effects
-
[32]
No obviously surreal physical states, e.g., jelly-like, gel-like, liquefied, lava-like, crystallized, etc
-
[33]
No dramatized, disaster-style, or wreckage-style treatments
-
[34]
No metaphorical writing
-
[35]
The original object must remain identifiable after editing
-
[36]
Do not change the target to an attribute that is already commonly reasonable in reality
-
[37]
Do not edit only a trivial small detail Editing Granularity Requirements: - Editing must target the object as a whole, or one complete major region / major surface - Do not change only a tiny corner - But also do not erase the object's identity for the sake of a whole-object edit Instruction Writing Standards:
-
[38]
Must precisely specify the target object's location in the image to avoid ambiguity
-
[39]
Must use concrete, physical, photorealistic descriptions
-
[40]
Descriptions should be moderately specific; do not pile on adjectives
-
[41]
Each instruction must end with a protection statement that explicitly lists by name the specific objects adjacent to the target object in the image
-
[42]
"" Figure 19: Prompt template forCounterfactual Attributeinstruction generation. 23 #QA generation —— Attribute1 SYSTEM_PROMPT =
Protection statement format must be: Preserve the [object 1], [object 2], [object 3], and other surrounding objects in the image unchanged; do not alter the background of the image under any circumstances. Output Requirements: Output only the following two lines. Do not output any analysis, explanation, or Markdown: Image editing instruction A: {text} Ima...
-
[43]
If the instruction text conflicts with the visible result, describe the visible result
Trust the IMAGES over the instruction text. If the instruction text conflicts with the visible result, describe the visible result
-
[44]
a", "an", or
A_object must be attribute-neutral: - object noun or noun phrase only - no determiners like "a", "an", or "the" - avoid color/material/size/texture words unless they are part of a standard object/part name - avoid pure scene-location words - no B or C words if avoidable - if the edited target is a part, subpart, attached component, local surface region, m...
-
[45]
First identify the counter-commonsense edited attribute explicitly described in the editing_instruction. If that instructed edited attribute is visually consistent with Image 2, prioritize it: - use it as the basis for C_new_attribute - choose attribute_type to match that instructed edited attribute - if the instruction describes a non-color change such a...
-
[46]
Only if the instruction-side attribute is clearly inconsistent with the visible edited result, ignore the instruction and instead describe the actually visible edited attribute from Image 2
-
[47]
B_original_attribute and C_new_attribute must: - be visually grounded - describe the same attribute type - come from Image 1 and Image 2 respectively - be comparable in granularity when possible, but accuracy is more important than brevity - do NOT shorten C_new_attribute merely to match the length of B_original_attribute
-
[48]
For C_new_attribute specifically: - prioritize fidelity to the editing_instruction and the visible edited result over brevity - C_new_attribute may be a medium-length descriptive phrase if needed - preserve essential modifiers such as material, finish, texture, pattern, transparency, geometry, coating, or condition when visually supported - do NOT replace...
-
[49]
B_original_attribute must be concrete and visually specific. - Do NOT use vague words such as: natural, normal, ordinary, regular, typical, standard, default, plain, usual, common - Use a concrete visible descriptor in the same slot as C_new_attribute - B_original_attribute may be shorter than C_new_attribute if the original state is visually simpler
-
[50]
Prefer one of these if appropriate: {attribute_type_suggestions}
attribute_type should be a short natural phrase. Prefer one of these if appropriate: {attribute_type_suggestions}
-
[51]
What is the [attribute_type] of the [A_object] [D_location]?
Same-slot self-check: After you choose attribute_type, B_original_attribute, and C_new_attribute, internally re-check whether BOTH B and C can naturally answer the SAME question: "What is the [attribute_type] of the [A_object] [D_location]?" If either B or C does NOT naturally fit that same question, revise attribute_type and/or B and/or C until they are ...
-
[52]
the [A_object] [D_location]
Part-target / self-reference check: After choosing A_object and D_location, internally re-check whether the phrase "the [A_object] [D_location]" naturally refers to the edited target. - If the edited target is only a part, subpart, attached component, local surface region, marking, or contained content of a larger host object, prefer naming that edited ta...
-
[53]
E_absurd_same_slot must be: - clearly wrong / absurd for this object - NOT be in the same attribute slot as B, C, or absurd_attribute_2 - it may describe a different kind of property entirely - different from both B and C
-
[54]
absurd_attribute_2 must be: - clearly wrong / absurd for this object - NOT be in the same attribute slot as B, C, or E_absurd_same_slot - it can be an absurd NOUN for this object - different from B, C, E_absurd_same_slot, plausible_wrong_attribute_1, and plausible_wrong_attribute_2
-
[55]
plausible_wrong_attribute_1 and plausible_wrong_attribute_2 must be: - same attribute type as B and C - plausible but wrong - different from B, C, E_absurd_same_slot, and absurd_attribute_2
-
[56]
D_location must: - refer to the target object in the edited image - be specific enough to identify the edited target - if only a part, subpart, attachment, marking, local surface region, or contained content is edited, locate that edited target relative to the host object or scene - do NOT create self-referential phrases where the object seems to be locat...
-
[57]
D_alt_location is a probe region used only for Q7 and Q11
-
[58]
By default, make D_alt_location a viewer-centric image-region phrase, such as: - in the upper half of the image - in the lower right of the image - near the center of the image - across the bottom of the image - in the foreground - in the background
-
[59]
It should: - not equal D_location - start with a locative preposition - preferably be broader than D_location - preferably include the area of D_location
Strongly prefer this kind of global image-region D_alt_location first. It should: - not equal D_location - start with a locative preposition - preferably be broader than D_location - preferably include the area of D_location
-
[60]
In that fallback case, D_alt_location: - must not equal D_location - must start with a locative preposition - must contain NO A_object whose attribute_type is B_original_attribute
Only if such a global image-region D_alt_location would still contain any A_object whose attribute_type remains B_original_attribute, then use a non-global fallback region instead. In that fallback case, D_alt_location: - must not equal D_location - must start with a locative preposition - must contain NO A_object whose attribute_type is B_original_attribute
-
[61]
wrong_location_1, wrong_location_2, wrong_location_3 must: - each be a locative phrase - each start with a locative preposition - each be clearly wrong for the B-attribute location question in Q11 - all be different from one another - all be different from D_location and D_alt_location
-
[62]
no" unless absolutely necessary. Only use usable =
Avoid usable = "no" unless absolutely necessary. Only use usable = "no" if you truly cannot determine visually grounded values reliably
-
[63]
usable":
All text values must be in English. Output strict JSON only, no markdown, no explanation. JSON schema: {{ "usable": "yes" or "no", "unusable_reason": "...", "A_object": "...", "A_number": "singular" or "plural" or "mass", "attribute_type": "...", "B_original_attribute": "...", "C_new_attribute": "...", "D_location": "...", "D_alt_location": "...", "plausi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.