GAPD: Gold-Action Policy Distillation for Agentic Reinforcement Learning in Knowledge Base Question Answering
Pith reviewed 2026-06-29 07:22 UTC · model grok-4.3
The pith
GAPD distills gold action sequences into RL policies for KBQA by matching intermediate entities as state anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
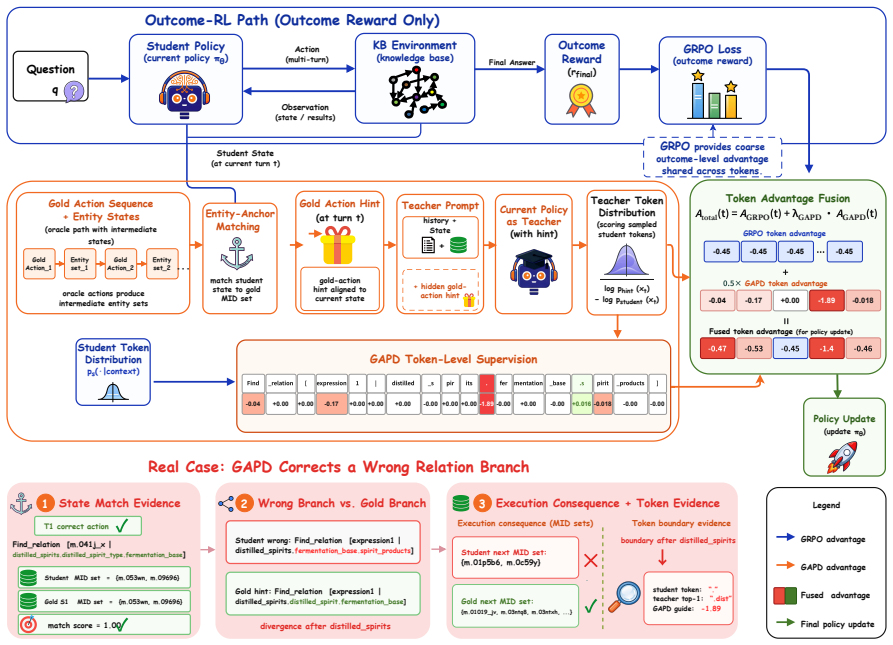
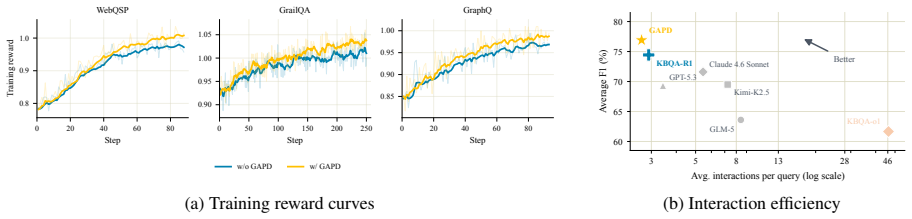
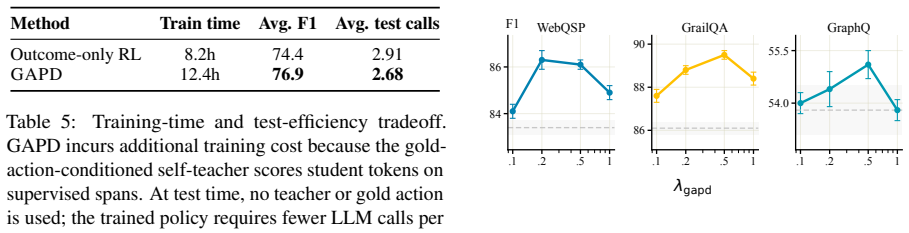
GAPD converts gold logical forms into executable action sequences and applies mid-anchor matching on the intermediate entities reached during gold execution and student exploration; the resulting aligned gold actions serve as a stop-gradient teacher whose token distribution is distilled into the ordinary student policy over generated action-token spans, producing consistent gains over prior state-of-the-art methods on WebQSP, GrailQA, and GraphQ.
What carries the argument
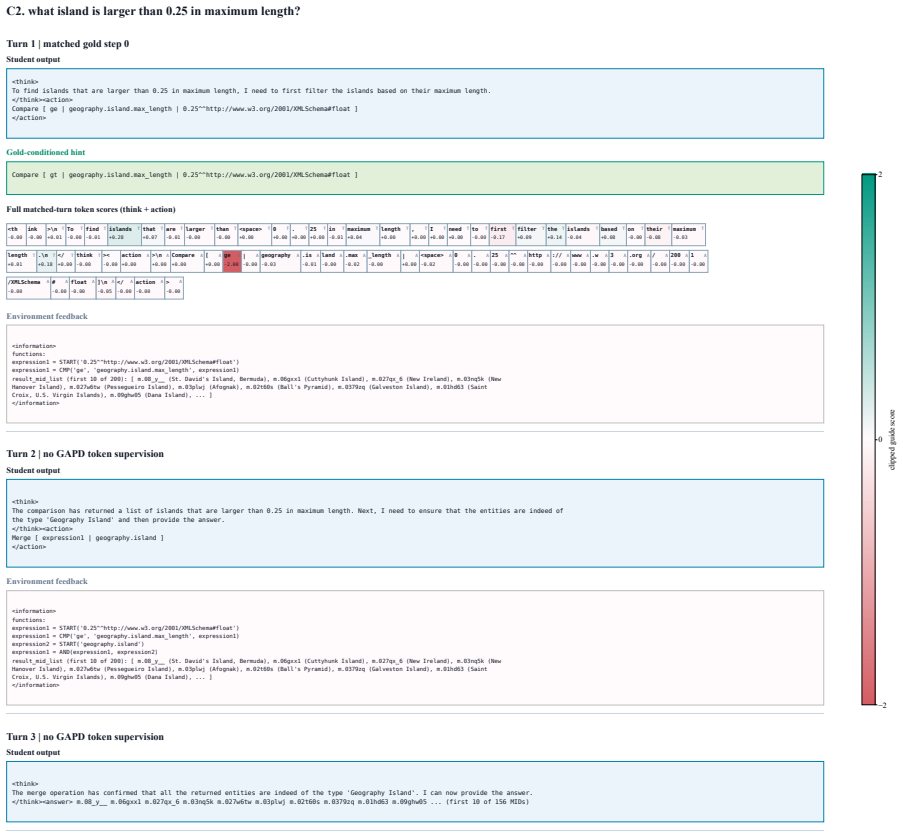
Mid-anchor matching, which identifies intermediate entities reached in both gold and student paths as state anchors to align gold actions with on-policy rollouts for distillation.
If this is right
- RL agents in KBQA receive token-level supervision in addition to sparse final-answer rewards.
- Gold logical forms shift from warm-start data construction to active on-policy updates.
- Policy distillation becomes possible even when student and gold trajectories diverge in length or order.
- Performance improvements appear on standard logical-form-annotated KBQA benchmarks.
Where Pith is reading between the lines
- The same entity-anchor alignment technique could transfer to other agentic RL domains that possess partial gold trajectories.
- Mid-anchor matching may reduce the amount of random exploration needed in sparse-reward settings by supplying early corrective signals.
- If entity sets prove too coarse, future work could test finer-grained anchors such as relation sequences or partial answer sets.
Load-bearing premise
Gold logical forms can be turned into executable action sequences whose intermediate entities give reliable state anchors that match student rollouts without systematic misalignment or bias during distillation.
What would settle it
Running the full GAPD pipeline on WebQSP, GrailQA, or GraphQ and finding no accuracy gain over prior outcome-only RL baselines, or finding that the entity-based matching step produces systematically misaligned gold actions.
Figures




read the original abstract
Reinforcement learning (RL) is a natural fit for agentic knowledge base question answering (KBQA), where a model must issue executable actions, observe knowledge-base feedback, and eventually return an answer. However, current RL-based KBQA systems mainly optimize sparse rewards from the final answer, leaving intermediate action errors weakly supervised. This is especially limiting for logical-form annotated KBQA benchmarks: gold logical forms can be converted into executable action sequences, but existing pipelines use them mainly for warm-start data construction rather than for on-policy RL updates. We propose GAPD, a training-time Gold-Action Policy Distillation framework that adds dense token-level guidance to outcome-based RL. To align gold actions with on-policy student rollouts, GAPD uses MID-ANCHOR MATCHING: it treats the intermediate entities reached during student exploration and gold execution as state anchors, and matches student states to gold states through these explored entity sets. The current policy conditioned on this aligned gold action serves as a stop-gradient teacher, whose token distribution is distilled back to the ordinary student policy over generated action-token spans. GAPD consistently surpasses the current state of the art on WebQSP, GrailQA, and GraphQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GAPD, a Gold-Action Policy Distillation framework for agentic RL in KBQA. Gold logical forms are converted to executable action sequences; mid-anchor matching uses shared intermediate entities from student rollouts and gold executions as state anchors to align on-policy states with gold actions. A stop-gradient teacher policy conditioned on the aligned gold action provides token-level distillation to the student policy. The paper claims this yields consistent SOTA improvements over prior methods on WebQSP, GrailQA, and GraphQ.
Significance. If the alignment procedure supplies reliable supervision without introducing systematic bias, GAPD would offer a practical way to convert logical-form annotations into dense on-policy signals for RL, potentially raising sample efficiency in sparse-reward agentic settings. Demonstrated gains across three standard KBQA benchmarks would be a concrete empirical contribution to the intersection of RL and semantic parsing.
major comments (1)
- [Mid-anchor matching procedure] Mid-anchor matching (described in the abstract and method): the procedure equates states via shared intermediate entity sets and selects the corresponding gold action for distillation. In KB graphs, however, distinct action sequences can reach identical entity sets through alternate relations or ordering; nothing in the description shows that entity overlap selects the continuation that would have been optimal from the student's actual prefix. If mismatches occur systematically, the stop-gradient teacher supplies incorrect token distributions, converting the claimed dense signal into a source of bias. This directly threatens the central claim of consistent SOTA gains over outcome-only RL and requires either a formal argument that such collisions are negligible or an empirical audit of matching fidelity.
minor comments (1)
- [Abstract] The abstract states that GAPD 'consistently surpasses' prior work but supplies no quantitative deltas, standard deviations, or statistical tests; these details belong in the results section to allow readers to judge the practical magnitude of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the careful analysis of the mid-anchor matching procedure. The comment raises a substantive point about potential mismatches that we address directly below.
read point-by-point responses
-
Referee: [Mid-anchor matching procedure] Mid-anchor matching (described in the abstract and method): the procedure equates states via shared intermediate entity sets and selects the corresponding gold action for distillation. In KB graphs, however, distinct action sequences can reach identical entity sets through alternate relations or ordering; nothing in the description shows that entity overlap selects the continuation that would have been optimal from the student's actual prefix. If mismatches occur systematically, the stop-gradient teacher supplies incorrect token distributions, converting the claimed dense signal into a source of bias. This directly threatens the central claim of consistent SOTA gains over outcome-only RL and requires either a formal argument that such collisions are negligible or an empirical audit of matching fidelity.
Authors: We acknowledge that KB graphs admit multiple paths to the same intermediate entity set and that entity overlap alone does not guarantee the gold continuation is optimal from the student's exact prefix. Our design selects the gold action from the single gold logical-form execution that shares the observed entity set at the anchor point; this supplies a valid (if not necessarily shortest) continuation rather than an arbitrary one. While a general formal guarantee of negligible collisions would require strong assumptions on the KB structure that we do not claim, the consistent empirical gains over outcome-only RL baselines across WebQSP, GrailQA, and GraphQ suggest that any residual bias is not dominant. To strengthen the manuscript we will add (i) a brief discussion of the collision issue and (ii) a quantitative audit of matching fidelity on held-out rollouts. revision: partial
Circularity Check
No circularity: self-contained training procedure with independent empirical claims
full rationale
The paper presents GAPD as a novel training-time framework that converts gold logical forms to action sequences and applies mid-anchor matching on intermediate entities to enable token-level distillation from a stop-gradient teacher into an on-policy student. This is described as an additive dense signal on top of standard outcome-based RL, with no equations, fitted parameters, or self-citations shown to reduce the claimed SOTA gains to quantities defined by the inputs by construction. The central premise (entity-set anchors reliably align gold actions) is an empirical modeling choice whose correctness can be tested externally rather than a definitional or self-referential reduction. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal adaptive retrieval augmented generation through internal representation learning. Preprint, arXiv:2603.00511. Bowen Fang, Wen Ye, Yunyue Su, Jinghao Zhang, Qiang Liu, Yesheng Liu, Xin Sun, Shu Wu, Jiabing Yang, Baole Wei, and Liang Wang. 2026. Tool- weaver: Weaving collaborative semantics for scal- able tool use in large language models.Preprin...
-
[2]
Kimi K2.5: Visual Agentic Intelligence
Logical form generation via multi-task learn- ing for complex question answering over knowledge bases. InProceedings of the 29th International Con- ference on Computational Linguistics, pages 1687– 1696, Gyeongju, Republic of Korea. International Committee on Computational Linguistics. Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
arXiv preprint arXiv:2501.18922 , year=
Curran Associates, Inc. Kun Li, Tianhua Zhang, Xixin Wu, Hongyin Luo, James R. Glass, and Helen M. Meng. 2025a. De- coding on graphs: Faithful and sound reasoning on knowledge graphs through generation of well-formed chains. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 24349–243...
-
[4]
PullNet: Open domain question answering with iterative retrieval on knowledge bases and text. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Lan- guage Processing (EMNLP-IJCNLP), pages 2380– 2390, Hong Kong, China. Association for Computa- tional Linguistics. H...
2019
-
[5]
InProceed- ings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4231–4242, Brussels, Belgium
Open domain question answering using early fusion of knowledge bases and text. InProceed- ings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4231–4242, Brussels, Belgium. Association for Computational Linguistics. Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung- Yeung Shum...
2018
-
[6]
Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation
Predict the retrieval! test time adapta- tion for retrieval augmented generation.Preprint, arXiv:2601.11443. Xin Sun, Zhongqi Chen, Xing Zheng, Qiang Liu, Shu Wu, Bowen Song, Zilei Wang, Weiqiang Wang, and Liang Wang. 2025a. Kbqa-r1: Reinforcing large language models for knowledge base question an- swering.arXiv preprint arXiv:2512.10999. Xin Sun, Qiang L...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
time.time_zone.day_dst_ends
exposes KB interaction APIs to the LLM and decomposes complex questions through multi-turn tool use.ToG(Sun et al., 2024) andPoG(Chen et al., 2024) are prompting-based graph reason- ing agents that perform test-time graph exploration or planning; their reported Hits@1 results are not mixed into our F1/EM main tables. KBQA-R1 Harness with commercial LLMs. ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.