Non-Forgetting Knowledge Allocation with Bi-level Competition for Class-Incremental Learning
Pith reviewed 2026-06-29 08:15 UTC · model grok-4.3
The pith
A recursive least-squares allocator in class-incremental learning matches the accuracy of one trained on all data simultaneously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
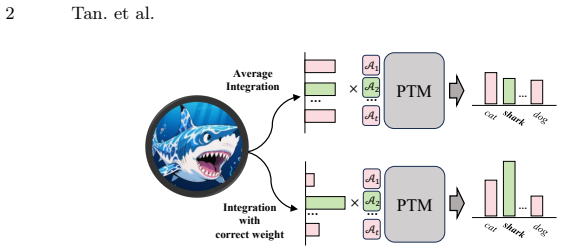
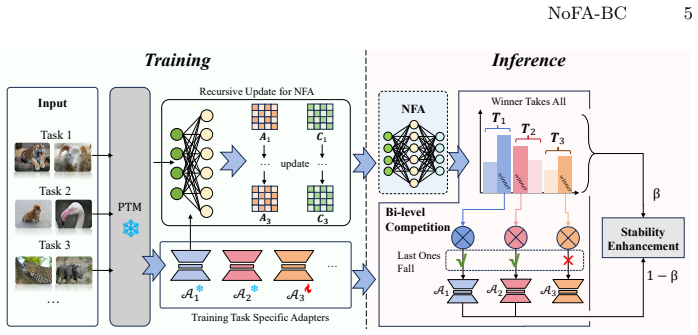
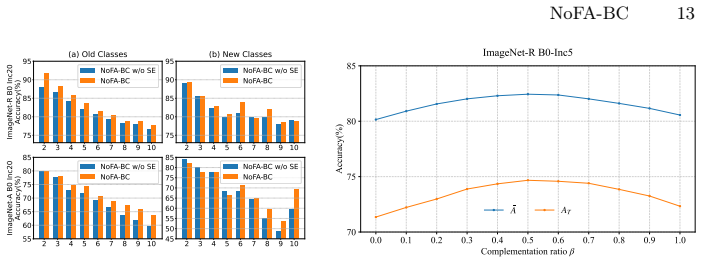
NoFA-BC constructs a non-forgetting allocator (NFA) by transforming the allocator training into a recursive least-squares problem and achieves an allocator equivalent to that trained with all data. Based on the NFA, a Bi-Level Competition (BLC) including an intra-task level Winner-Takes-All (WTA) mechanism and inter-task Last-Ones-Fall (LOF) elimination is proposed to provide better allocation of adapter knowledge. WTA extracts the most significant logit within a task to represent the adapter's contribution and LOF suppresses the irrelevant adapters. With BLC, participation ratio of each adapter can be tailored for each input. Moreover, a Stability Enhancement (SE) process is incorporated to
What carries the argument
The non-forgetting allocator (NFA) obtained by solving a recursive least-squares problem, which maintains equivalence to full-data training while respecting the no-access-to-past-data constraint in class-incremental learning.
If this is right
- The allocator does not forget previous tasks as new ones are added.
- Intra-task Winner-Takes-All selects the most significant logit per task to represent adapter contribution.
- Inter-task Last-Ones-Fall eliminates irrelevant adapters across tasks.
- Participation ratios of adapters are tailored per input.
- Stability Enhancement improves old task performance.
Where Pith is reading between the lines
- The recursive least-squares method could extend to other components prone to forgetting in continual learning setups.
- Bi-level competition might apply to knowledge allocation in other multi-task or incremental scenarios beyond adapters.
- Testing on a wider range of pre-trained models could reveal if the equivalence holds generally.
Load-bearing premise
The recursive least-squares formulation produces an allocator that does not forget previous tasks when new tasks are added sequentially under the class-incremental learning constraint that prevents access to past data.
What would settle it
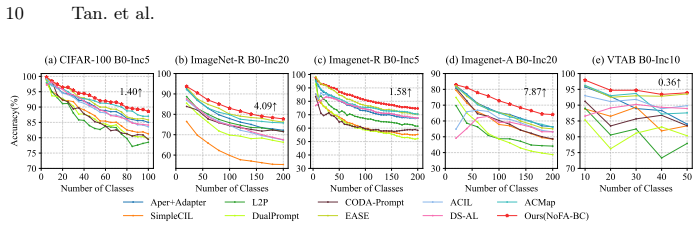
Comparing the allocator trained recursively on sequential tasks to one trained on all tasks combined, using the same evaluation metrics on a held-out test set; a significant performance gap would falsify the equivalence claim.
Figures

read the original abstract
Class-Incremental Learning (CIL) with pre-trained models (PTMs) aims to sequentially adapt PTMs to new categories without forgetting old knowledge. Built upon PTMs, existing adapter-based methods mainly train models via distinct task-specific adapters, and present a uniform knowledge allocation for each adapter during inference. However, this allocation mechanism ignores the nature of task discrepancy and leads to suboptimal utilization of adapters. Also, under CIL constraint, an allocator is prone to forgetting when tasks evolve. To address these issues, we propose a Non-Forgetting Allocation with Bi-Level Competition (NoFA-BC). NoFA-BC constructs a non-forgetting allocator (NFA) by transforming the allocator training into a recursive least-squares problem and achieves an allocator equivalent to that trained with all data. Based on the NFA, a Bi-Level Competition (BLC) including an intra-task level Winner-Takes-All (WTA) mechanism and inter-task Last-Ones-Fall (LOF) elimination is proposed to provide better allocation of adapter knowledge. WTA extracts the most significant logit within a task to represent the adapter's contribution and LOF suppresses the irrelevant adapters. With BLC, participation ratio of each adapter can be tailored for each input. Moreover, a Stability Enhancement (SE) process is incorporated to further improve the performance of old tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes NoFA-BC for class-incremental learning (CIL) with pre-trained models and task-specific adapters. It introduces a Non-Forgetting Allocator (NFA) obtained by recasting allocator training as a recursive least-squares (RLS) problem, claimed to yield an allocator identical to the batch solution trained on all data seen so far. On top of the NFA it defines a Bi-Level Competition (BLC) consisting of an intra-task Winner-Takes-All (WTA) mechanism and an inter-task Last-Ones-Fall (LOF) elimination rule, together with a Stability Enhancement (SE) process, to produce input-dependent participation ratios for the adapters.
Significance. If the RLS equivalence can be shown to hold exactly under the CIL memory constraint and the BLC rules demonstrably improve allocation without introducing new forgetting, the method would supply a principled, memory-bounded alternative to uniform or heuristic adapter selection in PTM-based CIL.
major comments (2)
- [Abstract / §3] Abstract and §3 (NFA construction): the central claim that the RLS formulation produces an allocator 'equivalent to that trained with all data' is load-bearing for the non-forgetting guarantee, yet no derivation, normal-equation update, or proof that the chosen allocator loss admits an exact, fixed-size sufficient-statistic update under sequential task arrival is supplied; any loss of cross-task terms or rank deficiency would invalidate the identity.
- [§4 / Experiments] §4 (BLC) and experimental section: the WTA and LOF rules are presented as improving allocation, but without an ablation that isolates their contribution from the NFA itself or from the SE process, it is impossible to determine whether the reported gains are attributable to the bi-level competition or to other factors.
minor comments (1)
- [Abstract] The abstract contains no quantitative results or dataset names, which is atypical for a methods paper in this area and makes the strength of the empirical claims difficult to gauge from the opening paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the presentation of the NFA equivalence and the empirical validation of BLC.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (NFA construction): the central claim that the RLS formulation produces an allocator 'equivalent to that trained with all data' is load-bearing for the non-forgetting guarantee, yet no derivation, normal-equation update, or proof that the chosen allocator loss admits an exact, fixed-size sufficient-statistic update under sequential task arrival is supplied; any loss of cross-task terms or rank deficiency would invalidate the identity.
Authors: We agree that an explicit derivation is necessary to substantiate the equivalence claim under the memory constraints of CIL. In the revision we will add a dedicated subsection in §3 that derives the RLS update from the normal equations, shows that the chosen allocator loss (quadratic in the participation weights) admits an exact fixed-size sufficient statistic, and proves that no cross-task terms are lost when tasks arrive sequentially. This will directly address potential concerns about rank deficiency or approximation. revision: yes
-
Referee: [§4 / Experiments] §4 (BLC) and experimental section: the WTA and LOF rules are presented as improving allocation, but without an ablation that isolates their contribution from the NFA itself or from the SE process, it is impossible to determine whether the reported gains are attributable to the bi-level competition or to other factors.
Authors: We acknowledge the value of isolating the BLC components. The revised experimental section will include a new ablation table that evaluates (i) NFA alone, (ii) NFA + WTA, (iii) NFA + LOF, (iv) NFA + SE, and (v) the full NoFA-BC, reporting both accuracy and forgetting metrics. This will allow readers to attribute performance gains specifically to the intra-task WTA and inter-task LOF rules. revision: yes
Circularity Check
No circularity: RLS equivalence claim is a standard construction, not a reduction to inputs
full rationale
The abstract states that transforming allocator training into a recursive least-squares problem 'achieves an allocator equivalent to that trained with all data.' This is the standard exact property of RLS when the normal equations are updated via sufficient statistics; it does not reduce the claimed non-forgetting property to a fitted parameter or self-citation by construction. The BLC mechanisms (WTA, LOF) are presented as separate proposals for allocation and do not rely on the equivalence claim for their justification. No equations, self-citations, or ansatzes are quoted that would make any central result tautological. The derivation chain is therefore self-contained against external benchmarks for RLS.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The allocator training can be transformed into a recursive least-squares problem that maintains equivalence to full data training under incremental constraints.
Reference graph
Works this paper leans on
-
[1]
Neural Networks135, 38–54 (2021)
Belouadah, E., Popescu, A., Kanellos, I.: A comprehensive study of class incre- mental learning algorithms for visual tasks. Neural Networks135, 38–54 (2021). https://doi.org/https://doi.org/10.1016/j.neunet.2020.12.003,https: //www.sciencedirect.com/science/article/pii/S0893608020304202
-
[2]
In: Koyejo, S., Mo- hamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Chen, S., GE, C., Tong, Z., Wang, J., Song, Y., Wang, J., Luo, P.: Adaptformer: Adapting vision transformers for scalable visual recognition. In: Koyejo, S., Mo- hamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neu- ral Information Processing Systems. vol. 35, pp. 16664–16678. Curran Associates, Inc. (2022),https://proceedings.neur...
2022
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Chen, X., Chang, X.: Dynamic residual classifier for class incremental learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 18743–18752 (October 2023)
2023
-
[4]
Cover, T.M.: Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE Transactions on Electronic Com- putersEC-14(3), 326–334 (1965).https://doi.org/10.1109/PGEC.1965.264137
-
[5]
In: In- ternational Conference on Learning Representations (2021),https://openreview
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: In- ternational Conference on Learning Representations (2021),https://openreview. net/forum?id=YicbFdNTTy
2021
-
[6]
arXiv preprint arXiv:2408.10349 (2024)
Fang, D., Zhu, Y., Fang, R., Chen, C., Zeng, Z., Zhuang, H.: Air: Analytic imbal- ance rectifier for continual learning. arXiv preprint arXiv:2408.10349 (2024)
-
[7]
In: Proceedings of the IEEE/CVF 16 Tan
Fukuda, T., Kera, H., Kawamoto, K.: Adapter merging with centroid prototype mapping for scalable class-incremental learning. In: Proceedings of the IEEE/CVF 16 Tan. et al. Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4884–4893 (June 2025)
2025
-
[8]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Gao, Q., Zhao, C., Sun, Y., Xi, T., Zhang, G., Ghanem, B., Zhang, J.: A unified continual learning framework with general parameter-efficient tuning. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11483–11493 (October 2023)
2023
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Gao, Z., Jia, W., Zhang, X., Zhou, D., Xu, K., Dawei, F., Dou, Y., Mao, X., Wang, H.: Knowledge memorization and rumination for pre-trained model-based class-incremental learning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20523–20533 (2025)
2025
-
[10]
Guo, P., Lyu, M.R.: A pseudoinverse learning algorithm for feedforward neural networks with stacked generalization applications to software reliability growth data. Neurocomputing56, 101–121 (2004).https://doi.org/https://doi.org/ 10.1016/S0925-2312(03)00385-0,https://www.sciencedirect.com/science/ article/pii/S0925231203003850
- [11]
-
[12]
In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J
He, R., Fang, D., Xu, Y., Cui, Y., Li, M., Chen, C., Zeng, Z., Zhuang, H.: Seman- tic shift estimation via dual-projection and classifier reconstruction for exemplar- free class-incremental learning. In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J. (eds.) Proceedings of the 42nd International Confer...
2025
-
[13]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., Song, D., Steinhardt, J., Gilmer, J.: The many faces of robustness: A critical analysis of out-of-distribution generalization. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8340–8349 (October 2021)
2021
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., Song, D.: Natural adversarial examples. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15262–15271 (June 2021)
2021
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hu, Z., Li, Y., Lyu, J., Gao, D., Vasconcelos, N.: Dense network expansion for class incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11858–11867 (June 2023)
2023
-
[16]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 709–727. Springer Nature Switzerland, Cham (2022)
2022
-
[17]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., Hadsell, R.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences114(13), 3521– 3526 (2017).https://doi.org/10.1073/pnas.161...
-
[18]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images. Tech. rep. (2009)
2009
-
[19]
Li, Z., Hoiem, D.: Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence40(12), 2935–2947 (dec 2017).https://doi. org/10.1109/TPAMI.2017.2773081 NoFA-BC 17
-
[20]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Liu, Y., Su, Y., Liu, A.A., Schiele, B., Sun, Q.: Mnemonics training: Multi-class incremental learning without forgetting. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[21]
Masana, M., Liu, X., Twardowski, B., Menta, M., Bagdanov, A.D., van de Weijer, J.: Class-incremental learning: Survey and performance evaluation on image clas- sification. IEEE Transactions on Pattern Analysis and Machine Intelligence45(5), 5513–5533 (2023).https://doi.org/10.1109/TPAMI.2022.3213473
-
[22]
McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: Thesequentiallearningproblem.In:Psychologyoflearningandmotivation,vol.24, pp. 109–165. Elsevier (1989)
1989
-
[23]
Frontiers in psychology4, 504 (2013)
Mermillod, M., Bugaiska, A., Bonin, P.: The stability-plasticity dilemma: Investi- gating the continuum from catastrophic forgetting to age-limited learning effects. Frontiers in psychology4, 504 (2013)
2013
-
[24]
In: NeurIPS
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. In: NeurIPS. pp. 8026–8037 (2019)
2019
-
[25]
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vish- wanathan, S., Garnett, R
Rebuffi,S.A.,Bilen,H.,Vedaldi,A.:Learningmultiplevisualdomainswithresidual adapters. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vish- wanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Sys- tems. vol. 30. Curran Associates, Inc. (2017),https://proceedings.neurips.cc/ paper _ files / paper / 2017 / file / e7b...
2017
-
[26]
Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: iCaRL: Incremental clas- sifier and representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5533–5542 (Jul 2017). https://doi.org/10.1109/CVPR.2017.587
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Smith, J.S., Karlinsky, L., Gutta, V., Cascante-Bonilla, P., Kim, D., Arbelle, A., Panda, R., Feris, R., Kira, Z.: CODA-Prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11909–11919 (June 2023)
2023
-
[28]
arXiv preprint arXiv:2309.07117 (2023)
Sun, H.L., Zhou, D.W., Ye, H.J., Zhan, D.C.: Pilot: A pre-trained model-based continual learning toolbox. arXiv preprint arXiv:2309.07117 (2023)
-
[29]
Clip model is an efficient continual learner.arXiv preprint arXiv:2210.03114,
Thengane, V., Khan, S., Hayat, M., Khan, F.: Clip model is an efficient continual learner. arXiv preprint arXiv:2210.03114 (2022)
-
[30]
In: Computer Vision – ECCV 2022
Wang, F.Y., Zhou, D.W., Ye, H.J., Zhan, D.C.: FOSTER: Feature boosting and compression for class-incremental learning. In: Computer Vision – ECCV 2022. pp. 398–414. Springer Nature Switzerland, Cham (2022).https://doi.org/10.1007/ 978-3-031-19806-9_23
2022
-
[31]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Wang, Z., Zhang, Z., Ebrahimi, S., Sun, R., Zhang, H., Lee, C.Y., Ren, X., Su, G., Perot,V.,Dy,J.,Pfister,T.:Dualprompt:Complementarypromptingforrehearsal- free continual learning. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 631–648. Springer Nature Switzerland, Cham (2022)
2022
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, Z., Zhang, Z., Lee, C.Y., Zhang, H., Sun, R., Ren, X., Su, G., Perot, V., Dy, J., Pfister, T.: Learning to prompt for continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 139–149 (June 2022)
2022
-
[33]
In: The Thirty-eighthAnnualConferenceonNeuralInformationProcessingSystems(2024) 18 Tan
Xu, Y., Chen, Y., Nie, J., Wang, Y., Zhuang, H., Okumura, M.: Advancing cross- domain discriminability in continual learning of vision-language models. In: The Thirty-eighthAnnualConferenceonNeuralInformationProcessingSystems(2024) 18 Tan. et al
2024
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yan, S., Xie, J., He, X.: DER: Dynamically expandable representation for class incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3014–3023 (Jun 2021)
2021
-
[35]
IEEE Geoscience and Remote Sensing Letters22, 1–5 (2025).https://doi.org/10
Yan, Y., Ji, J., Cheng, Y., Liu, Y., Xiong, P., Zhuang, H.: Crossacl: Analytic continual learning via feature cross for hyperspectral image classification. IEEE Geoscience and Remote Sensing Letters22, 1–5 (2025).https://doi.org/10. 1109/LGRS.2025.3587593
-
[36]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Yue, X., Zhang, X., Chen, Y., Zhang, C., Lao, M., Zhuang, H., Qian, X., Li, H.: MMAL: Multi-modal analytic learning for exemplar-free audio-visual class in- cremental tasks. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 2428–2437. MM ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/10.1145/36...
-
[37]
A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
Zhai, X., Puigcerver, J., Kolesnikov, A., Ruyssen, P., Riquelme, C., Lucic, M., Djo- longa, J., Pinto, A.S., Neumann, M., Dosovitskiy, A., et al.: A large-scale study of representation learning with the visual task adaptation benchmark. arXiv preprint arXiv:1910.04867 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[38]
In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J
Zhang, X., He, R., Jiao, C., Fang, D., Li, M., Zeng, Z., Chen, C., Zhuang, H.: L3A: Label-augmented analytic adaptation for multi-label class incremental learning. In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J. (eds.) Proceedings of the 42nd International Conference on Machine Learning. Proceeding...
2025
-
[39]
Zhao, H., Wang, H., Fu, Y., Wu, F., Li, X.: Memory-efficient class-incremental learningforimageclassification.IEEETransactionsonNeuralNetworksandLearn- ing Systems33(10), 5966–5977 (2022).https://doi.org/10.1109/TNNLS.2021. 3072041
-
[40]
International Journal of Computer Vision (2024)
Zhou, D.W., Cai, Z.W., Ye, H.J., Zhan, D.C., Liu, Z.: Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need. International Journal of Computer Vision (2024)
2024
-
[41]
In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence
Zhou, D.W., Sun, H.L., Ning, J., Ye, H.J., Zhan, D.C.: Continual learning with pre-trained models: a survey. In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. IJCAI ’24 (2024).https://doi.org/ 10.24963/ijcai.2024/924,https://doi.org/10.24963/ijcai.2024/924
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, D.W., Sun, H.L., Ye, H.J., Zhan, D.C.: Expandable subspace ensemble for pre-trained model-based class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 23554–23564 (June 2024)
2024
-
[43]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Zhuang, H., Chen, Y., Fang, D., He, R., Tong, K., Wei, H., Zeng, Z., Chen, C.: Gacl: Exemplar-free generalized analytic continual learning. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neural Information Processing Systems. vol. 37, pp. 83024– 83047. Curran Associates, Inc. (2024).https://doi....
-
[44]
Zhuang, H., Fang, D., Tong, K., Liu, Y., Zeng, Z., Zhou, X., Chen, C.: Online analytic exemplar-free continual learning with large models for imbalanced au- tonomous driving task. IEEE Transactions on Vehicular Technology74(2), 1949– 1958 (Feb 2025).https://doi.org/10.1109/TVT.2024.3483557
-
[45]
Zhuang, H., He, R., Tong, K., Zeng, Z., Chen, C., Lin, Z.: DS-AL: A dual- stream analytic learning for exemplar-free class-incremental learning. Proceedings NoFA-BC 19 of the AAAI Conference on Artificial Intelligence38(15), 17237–17244 (Mar 2024). https://doi.org/10.1609/aaai.v38i15.29670
-
[46]
In: Globerson, A., Mackey, L., Bel- grave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Zhuang, H., Liu, Y., He, R., Tong, K., Zeng, Z., Chen, C., Wang, Y., Chau, L.P.: F-oal: Forward-only online analytic learning with fast training and low mem- ory footprint in class incremental learning. In: Globerson, A., Mackey, L., Bel- grave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neu- ral Information Processing Systems. vol...
2024
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhuang, H., Weng, Z., He, R., Lin, Z., Zeng, Z.: Gkeal: Gaussian kernel embed- ded analytic learning for few-shot class incremental task. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7746–7755 (June 2023)
2023
-
[48]
In: Ad- vances in Neural Information Processing Systems
Zhuang, H., Weng, Z., Wei, H., Xie, R., Toh, K.A., Lin, Z.: ACIL: Analytic class- incremental learning with absolute memorization and privacy protection. In: Ad- vances in Neural Information Processing Systems. vol. 35, pp. 11602–11614. Curran Associates, Inc. (2022)
2022
-
[49]
Zhuang, H., Yan, Y., He, R., Zeng, Z.: Class incremental learning with ana- lytic learning for hyperspectral image classification. Journal of the Franklin In- stitute361(18), 107285 (2024).https://doi.org/https://doi.org/10.1016/j. jfranklin.2024.107285,https://www.sciencedirect.com/science/article/ pii/S0016003224007063 NoFA-BC 1 Non-Forgetting Knowledge...
work page doi:10.1016/j 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.