Cluster-Level Attention-Guided Parallel Decoding for Masked Diffusion Language Models
Pith reviewed 2026-06-29 08:28 UTC · model grok-4.3
The pith
CLAD groups high-confidence spans into clusters and uses attention maps to decode masked diffusion models in parallel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
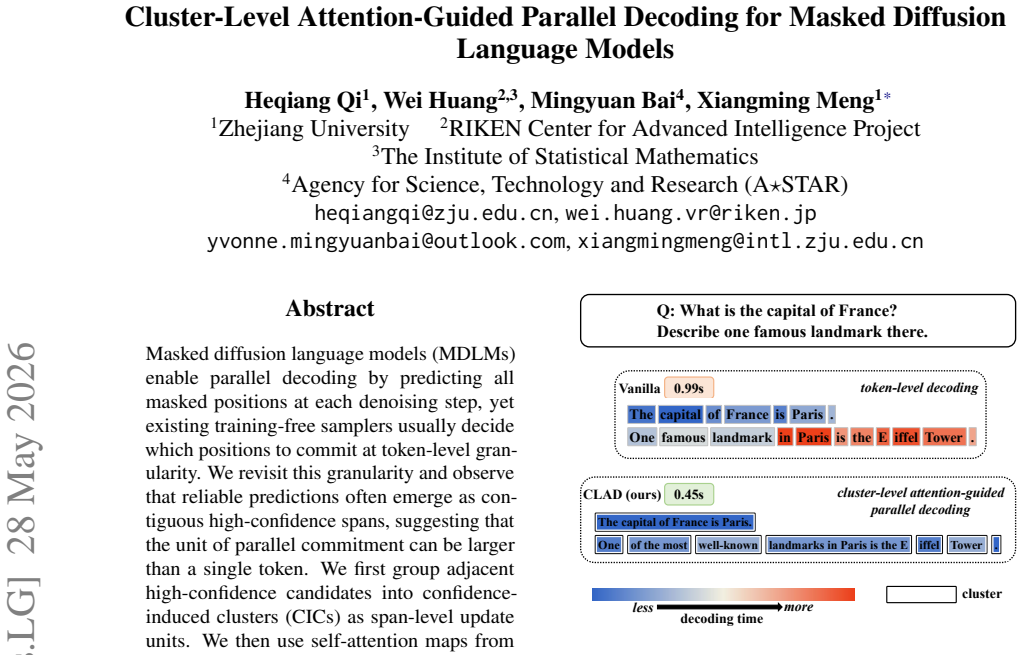
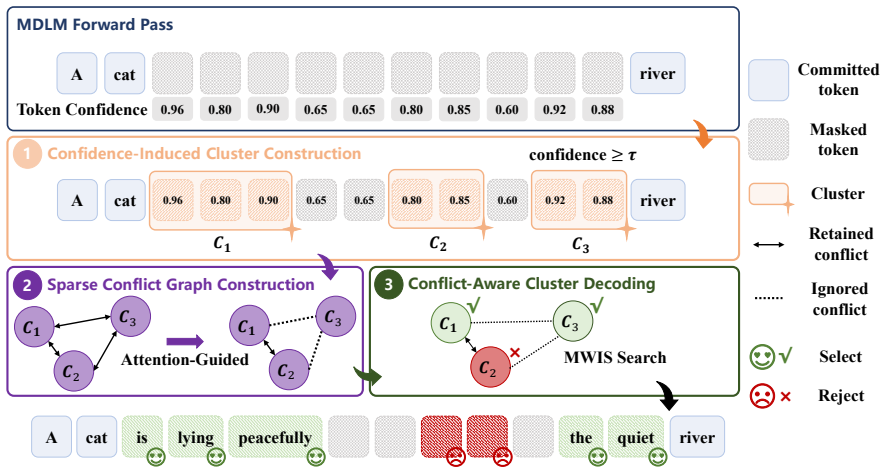
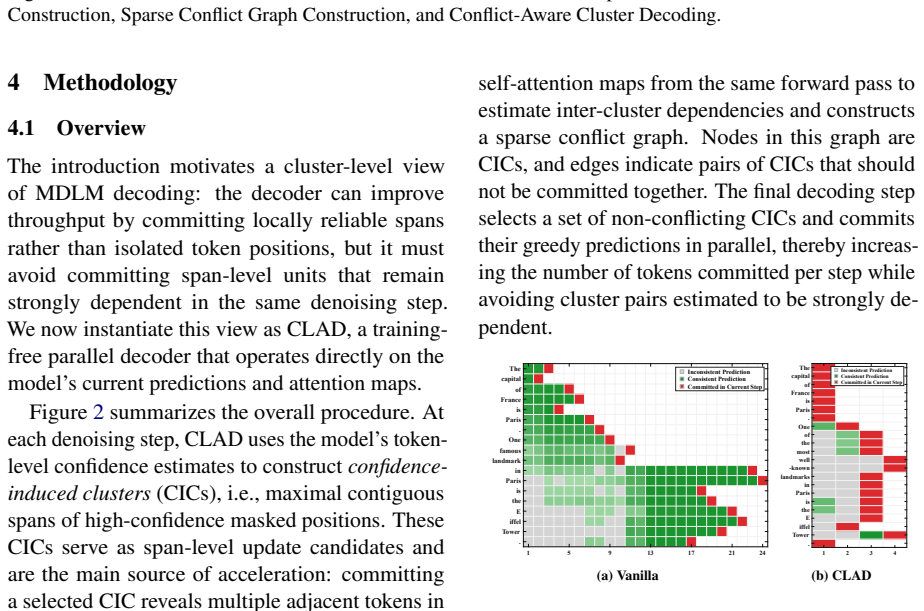
The central claim is that reliable predictions in MDLMs appear as contiguous high-confidence spans that can be grouped into confidence-induced clusters (CICs); self-attention maps from the identical forward pass then supply inter-cluster dependency estimates that permit conflict-aware selection of compatible CICs for simultaneous commitment, yielding the training-free CLAD decoder.
What carries the argument
CLAD (Cluster-Level Attention-Guided Decoding), which replaces token-level commitment with CIC formation from adjacent high-confidence positions followed by attention-map-based conflict filtering for parallel updates.
If this is right
- CLAD applies without retraining to existing MDLM families such as LLaDA and Dream.
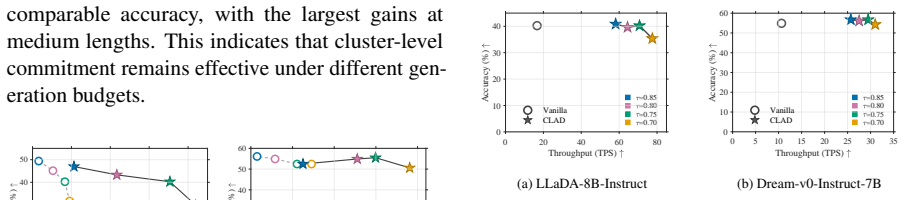
- Speedups range from 1.77x to 8.47x over vanilla decoding across the tested settings.
- Task accuracy remains broadly comparable on four reasoning and code-generation benchmarks in most evaluated configurations.
- The method reuses the identical forward pass both to predict masks and to estimate cluster dependencies.
Where Pith is reading between the lines
- If high-confidence regions align with semantic units, cluster-level decoding may transfer to other non-autoregressive generation schemes.
- Larger speedups could appear on longer sequences where token-level parallelism saturates earlier.
- The reliance on attention maps for dependency estimation invites direct tests of whether alternative dependency signals produce different cluster selections.
- The observation that reliable predictions cluster contiguously suggests future diffusion schedules could be designed to encourage span-level convergence.
Load-bearing premise
Reliable predictions tend to form contiguous high-confidence spans whose interdependencies are accurately captured by the model's own self-attention maps in one forward pass.
What would settle it
A direct comparison in which cluster-level commitment on the same models and benchmarks produces measurably lower accuracy than token-level vanilla decoding while the attention-based conflict check fails to identify incompatible clusters.
Figures
read the original abstract
Masked diffusion language models (MDLMs) enable parallel decoding by predicting all masked positions at each denoising step, yet existing training-free samplers usually decide which positions to commit at token-level granularity. We revisit this granularity and observe that reliable predictions often emerge as contiguous high-confidence spans, suggesting that the unit of parallel commitment can be larger than a single token. We first group adjacent high-confidence candidates into confidence-induced clusters (CICs) as span-level update units. We then use self-attention maps from the same forward pass to estimate inter-cluster dependencies, enabling conflict-aware selection of mutually compatible CICs for parallel commitment. This yields CLAD (Cluster-Level Attention-Guided Decoding), a training-free cluster-level decoder for MDLMs. Experiments on LLaDA and Dream model families across four reasoning and code-generation benchmarks show that CLAD achieves 1.77x--8.47x speedups over Vanilla decoding while maintaining broadly comparable task accuracy in most settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CLAD, a training-free cluster-level attention-guided decoding method for masked diffusion language models. It observes that reliable predictions emerge as contiguous high-confidence spans, groups them into confidence-induced clusters (CICs), and uses self-attention maps to estimate inter-cluster dependencies for conflict-aware parallel commitment. Experiments on LLaDA and Dream model families across four reasoning and code-generation benchmarks demonstrate 1.77x--8.47x speedups over vanilla decoding with broadly comparable task accuracy.
Significance. If the empirical results hold, this work is significant for improving the efficiency of parallel decoding in MDLMs without requiring retraining or additional parameters. The approach credits the observation-driven design and the reuse of self-attention from the same forward pass, which avoids extra computation. This could have practical impact on deploying diffusion-based language models for tasks like reasoning and code generation by reducing inference time while preserving performance.
major comments (2)
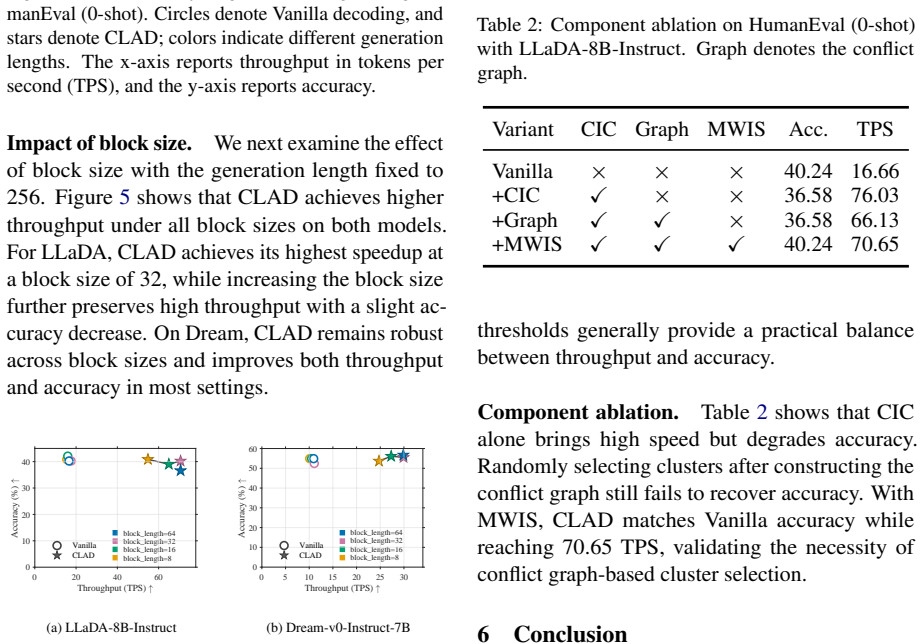
- [Experiments] Experiments section: the reported speedups of 1.77x--8.47x and accuracy comparisons are presented without error bars, number of runs, or detailed baseline configurations for 'Vanilla decoding', which is load-bearing for establishing the reliability of the central performance claims.
- [Method] Method section: the construction of confidence-induced clusters (CICs) and the conflict-aware selection threshold are described at a high level but lack an ablation study or sensitivity analysis on the high-confidence criterion, undermining the justification for cluster-level over token-level granularity.
minor comments (1)
- [Abstract] The abstract mentions four benchmarks but does not name them explicitly, which would improve the reader's ability to assess the scope of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point-by-point below and will incorporate revisions to strengthen the experimental reporting and methodological justification.
read point-by-point responses
-
Referee: Experiments section: the reported speedups of 1.77x--8.47x and accuracy comparisons are presented without error bars, number of runs, or detailed baseline configurations for 'Vanilla decoding', which is load-bearing for establishing the reliability of the central performance claims.
Authors: We agree that the absence of error bars, run counts, and baseline details weakens the reliability of the central claims. In the revised manuscript we will rerun all experiments across at least three random seeds, report means and standard deviations, add error bars to tables and figures, and expand the description of the vanilla decoding baseline (including exact masking schedule, temperature, and implementation details matching the CLAD setup). revision: yes
-
Referee: Method section: the construction of confidence-induced clusters (CICs) and the conflict-aware selection threshold are described at a high level but lack an ablation study or sensitivity analysis on the high-confidence criterion, undermining the justification for cluster-level over token-level granularity.
Authors: The cluster-level design is motivated by the empirical observation (Section 3.1) that reliable predictions appear as contiguous high-confidence spans rather than isolated tokens. We nevertheless acknowledge the value of quantitative support. The revision will include a sensitivity analysis varying the high-confidence threshold (e.g., 0.80–0.95) and a direct comparison of cluster-level versus token-level commitment on the same benchmarks to better justify the granularity choice. revision: yes
Circularity Check
No significant circularity; empirical method is self-contained
full rationale
The paper describes a training-free decoding procedure for masked diffusion LMs that groups high-confidence tokens into clusters and uses self-attention maps from the same forward pass to select compatible clusters. All load-bearing steps are observational heuristics followed by direct empirical measurement of wall-clock speedups and task accuracy on external benchmarks. No equations, fitted parameters, or self-citations are invoked whose outputs are then re-labeled as predictions; the central claims remain falsifiable by the reported metrics and do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs
Parallelbench: Understanding the trade-offs of parallel decoding in diffusion llms.arXiv preprint arXiv:2510.04767. Bumjun Kim, Dongjae Jeon, Moongyu Jeon, and Al- bert No. 2026. Dependency-aware parallel decod- ing via attention for diffusion llms.arXiv preprint arXiv:2603.12996. Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. 202...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Training language models to follow instruc- tions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744. Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexan- der Rush, and V olodymyr Kuleshov. 2024. Simple and effective masked diffusion language models.Ad- vances in Neural I...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Xueyu Zhou, Yangrong Hu, and Jian Huang. 2026a. Dos: Dependency-oriented sampler for masked diffusion language models.arXiv preprint arXiv:2603.15340. Yuyan Zhou, Kai Syun Hou, Weiyu Chen, and James Kwok. 2026b. Attention-based sampler for diffusion language models.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Subtract the number of eggs she eats for breakfast and bakes for her friends
-
[6]
Calculate the number of eggs she sells
-
[7]
Janet’s ducks lay 16 eggs per day
Multiply the number of eggs sold by the price per egg to find her daily earnings. Janet’s ducks lay 16 eggs per day. She eats 3 eggs for breakfast and bakes 4 eggs for her friends, so she eats a total of 3 + 4 = 7 eggs per day. The number of eggs she sells is the total number of eggs laid minus the number of eggs she eats, which is 16 - 7 = 9 eggs per day...
-
[8]
Calculate the total number of eggs laid by Janet’s ducks per day
-
[9]
Subtract the number of eggs Janet eats for breakfast and bakes for her friends
-
[10]
Calculate the number of eggs left for sale
-
[11]
Multiply the number of eggs left for sale by the price per egg to find the daily earnings
-
[12]
Janet’s ducks lay 16 eggs per day
-
[13]
She eats 3 eggs for breakfast and bakes 4 eggs for her friends, so she uses a total of 3 + 4 = 7 eggs per day
-
[14]
The number of eggs left for sale is the total number of eggs laid minus the number of eggs used, which is 16 - 7 = 9 eggs per day
-
[15]
"" Output from typing import List def mean_absolute_deviation(numbers: List[float]) -> float:
She sells each egg for $2, so her daily earnings are the number of eggs left for sale multiplied by the price per egg, which is 9 eggs * $2/egg = $18 per day. Therefore, Janet makes $18 every day at the farmers’ market. #### 18 Generation Time13.07 s 14 Table 11: Example generation output of LLaDA-8B-Instruct with Vanilla decoding on MATH (4-shot) Item Co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.