AgentCVR: Active Multi-Agent Cross-Video Reasoning via Script-Simulated Reinforcement Learning
Pith reviewed 2026-06-29 08:02 UTC · model grok-4.3
The pith
AgentCVR frames cross-video reasoning as active evidence gathering by a master agent coordinating visual and audio specialists, trained efficiently through script-simulated reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
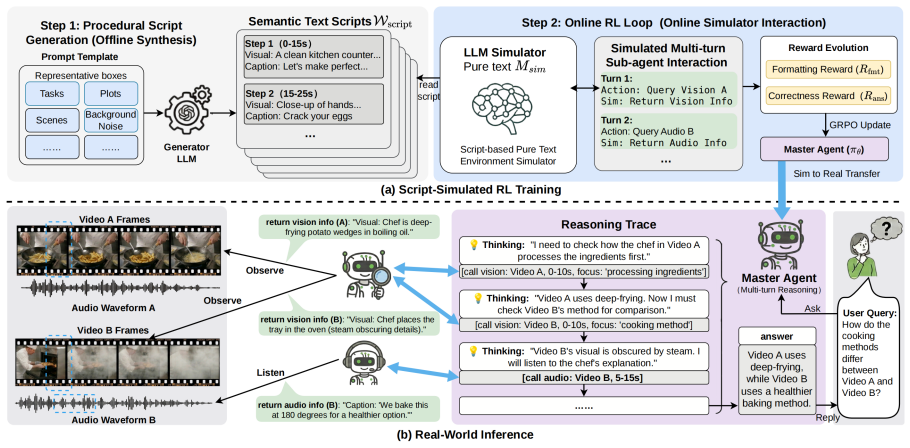
AgentCVR treats CVR as an active evidence-acquisition task. A Master Agent iteratively coordinates specialized Visual and Audio Agents for targeted extraction. Policy optimization occurs through Script-Simulated RL that relies on LLM-generated semantic scripts and a lightweight text-based simulator, bypassing costly multimodal inference during online exploration.
What carries the argument
Script-Simulated RL that optimizes the agent's policy with LLM-generated semantic scripts and a lightweight text-based simulator to enable transfer to real video inputs.
If this is right
- The learned policy transfers from simulation to real videos to improve evidence retrieval in distributed video sets.
- Performance exceeds single-pass baselines on cross-video alignment and localization tasks.
- Results reach levels comparable to state-of-the-art closed-source systems on the CVR benchmark.
- Training proceeds without repeated multimodal inference, lowering the cost of policy search.
Where Pith is reading between the lines
- The same simulation proxy could speed up agent training for tasks that combine video with other modalities such as audio streams or text documents.
- Active multi-agent coordination may help overcome context-length limits when reasoning over hour-long video collections.
- If transfer holds, semantic script proxies might serve as a general way to bootstrap perceptual policies before fine-tuning on real sensor data.
Load-bearing premise
That LLM-generated semantic scripts plus a lightweight text-based simulator provide a sufficiently faithful proxy for real multimodal video evidence during policy optimization.
What would settle it
Measuring whether an agent trained exclusively in the script simulator achieves lower accuracy on real-video CVR benchmarks than an otherwise identical agent trained with actual multimodal video inputs during exploration.
Figures


read the original abstract
Cross-Video Reasoning (CVR) has emerged as a critical frontier in multimodal intelligence, requiring models to retrieve, align, and aggregate evidence distributed across multiple videos. Current Multimodal Large Language Models (MLLMs) often struggle with CVR, as simple single-pass strategies encode multiple videos into a shared compressed context, potentially obscuring rare but critical evidence. In this paper, we propose AgentCVR, a multi-agent framework that treats CVR as an active evidence-acquisition task. AgentCVR employs a Master Agent to iteratively coordinate specialized Visual and Audio Agents for targeted evidence extraction. To ensure efficient training, we introduce Script-Simulated RL, which optimizes the agent's policy with LLM-generated semantic scripts and a lightweight text-based simulator, bypassing costly multimodal inference during online exploration. Experimental results on a comprehensive CVR benchmark show that AgentCVR outperforms single-pass baselines and achieves comparable performance to state-of-the-art closed-source systems, particularly in complex cross-video alignment and localization. To ensure reproducibility, our code is available at https://github.com/wang-jh24/AgentCVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AgentCVR, a multi-agent framework for Cross-Video Reasoning (CVR) in which a Master Agent iteratively coordinates specialized Visual and Audio Agents to perform active evidence acquisition across multiple videos. Training relies on Script-Simulated RL: LLM-generated semantic scripts drive policy optimization inside a lightweight text-only simulator, avoiding multimodal inference during exploration. Experiments on a CVR benchmark are reported to show outperformance over single-pass baselines and comparability to closed-source SOTA systems, with code released at the provided GitHub link.
Significance. If the simulator-to-real transfer holds, the method could enable scalable training of active multimodal agents by sidestepping expensive online MLLM calls during RL. The explicit code release is a clear strength for reproducibility. The result would be of interest to the CVR and agentic multimodal communities provided the performance gains can be attributed to the learned acquisition policy rather than the final MLLM calls alone.
major comments (1)
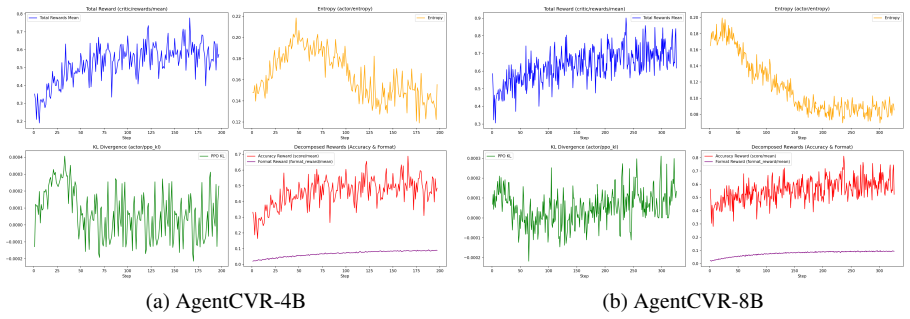
- [Experimental Results] The central methodological claim—that Script-Simulated RL produces transferable policies whose active-acquisition behavior drives the reported gains—rests on an unvalidated sim-to-real assumption. No section (including the Experimental Results) reports a controlled measurement such as action-distribution overlap, evidence-retrieval precision, or end-task delta between simulator rollouts and real-video rollouts on identical queries. Without this, the benchmark numbers cannot be attributed to the proposed training procedure.
minor comments (1)
- [Abstract] The abstract refers to 'a comprehensive CVR benchmark' without naming the dataset, number of videos, or query types; this detail should be added for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of Script-Simulated RL for scalable agent training. We address the concern about sim-to-real validation below.
read point-by-point responses
-
Referee: [Experimental Results] The central methodological claim—that Script-Simulated RL produces transferable policies whose active-acquisition behavior drives the reported gains—rests on an unvalidated sim-to-real assumption. No section (including the Experimental Results) reports a controlled measurement such as action-distribution overlap, evidence-retrieval precision, or end-task delta between simulator rollouts and real-video rollouts on identical queries. Without this, the benchmark numbers cannot be attributed to the proposed training procedure.
Authors: We agree that the manuscript does not report controlled sim-to-real measurements such as action-distribution overlap or end-task deltas on identical queries, which limits direct attribution of the benchmark gains to the learned acquisition policy. In the revised manuscript we will add a dedicated analysis subsection that evaluates policy transfer on a subset of queries: we will report (i) action overlap between simulator and real MLLM rollouts, (ii) evidence-retrieval precision in both environments, and (iii) the performance delta when the same policy is executed in simulation versus on real videos. These additions will strengthen the empirical support for the transfer assumption while preserving the original experimental results. revision: yes
Circularity Check
No circularity; empirical method with no derivations or self-referential reductions
full rationale
The paper presents an empirical multi-agent framework using Script-Simulated RL for policy optimization on LLM-generated text scripts, followed by deployment on real video inputs. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The central performance claims rest on benchmark results rather than any chain that reduces to its own inputs by construction. Absence of mathematical structure means none of the enumerated circularity patterns apply; the sim-to-real transfer concern is a validation gap, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated semantic scripts and lightweight text simulator accurately proxy real multimodal video evidence for agent training
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Shubhang Bhatnagar, Renxiong Wang, Kapil Krishnaku- mar, Adel Ahmadyan, Zhaojiang Lin, Lambert Math- ias, Xin Luna Dong, Babak Damavandi, Narendra Ahuja, and Seungwhan Moon. 2026. VideoMind: Thinking in steps for long video understanding. In Proceedings of the 19th Conference of the European Chapt...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
InProceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 1369–1379
TVQA: Localized, compositional video ques- tion answering. InProceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 1369–1379. Jingyao Li, Jingyun Wang, Molin Tan, Haochen Wang, Cilin Yan, Likun Shi, Jiayin Cai, Xiaolong Jiang, and Yao Hu. 2026. Crossvid: A comprehensive bench- mark for evaluating cross-video reaso...
2018
-
[3]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024. Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-LLaV A: Learn- ing united visual representation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Proces...
2024
-
[4]
WebGPT: Browser-assisted question-answering with human feedback
Agentbench: Evaluating llms as agents. In The Twelfth International Conference on Learning Representations, ICLR 2024. Ilya Loshchilov and Frank Hutter. 2019. Decou- pled weight decay regularization. In7th Inter- national Conference on Learning Representations, ICLR 2019. Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-ChatGPT: To...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Longvideobench: A benchmark for long- context interleaved video-language understanding. InAdvances in Neural Information Processing Sys- tems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024,. Yongliang Wu, Xinting Hu, Yuyang Sun, Yizhou Zhou, Wenbo Zhu, Fengyun Rao, Bernt Schiele, and Xu Yang. 2025. Number it: Temporal gr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20. Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Gra- ham Neubig. 2024. Webarena: A realistic web en- vironment for buildi...
-
[7]
Summarize the full cook- ing procedure. Does it involve rolling spring rolls or similar actions?
Assemble Spring Rolls. 10. Serve. Turn 2 Thinking:Now I need to observe Video 2’s overall workflow (294.71s) to confirm if it involves similar spring roll preparation and rolling actions. Action:[call vision: Video 2, 0-294.71s, focus: "Summarize the full cook- ing procedure. Does it involve rolling spring rolls or similar actions?"] Observation:Visual Ag...
-
[8]
A large oak tree covers the NW corner of View A
**Define Obstacles**: Explicitly state what blocks the view (e.g., "A large oak tree covers the NW corner of View A", "A parked delivery truck blocks the lower lane in View B")
-
[9]
**The "Hidden" Entity**: Ensure at least one key object passes BEHIND an obstacle in one view but remains visible in the other
-
[10]
### Task 1: Generate Synchronized Video Scripts Generate a timeline (0s to <duration>s) with a step of 2 seconds
**Entity Consistency**: Use {A1}={B1}, {A2}={B2} mapping. ### Task 1: Generate Synchronized Video Scripts Generate a timeline (0s to <duration>s) with a step of 2 seconds. For EACH timestamp, provide: * **View A Visual**: Describe positions, relative distances, and **occlusions**. * **View B Visual**: Describe the same reality from the other angle. ### Ta...
-
[11]
**Occlusion Zones**: Define zones where objects vanish in one view but are visible in the other
-
[12]
**Cross-View Transition**: Objects must move from View A’s field of view into View B’s
-
[13]
Count only Red Cars
**Distractors**: Include objects that SHOULD NOT be counted (e.g., "Count only Red Cars", but include Red Trucks and Blue Cars)
-
[14]
{A1} is now {B1}
**Deduplication**: {A1} and {B1} are the SAME physical car. The AI must count it as 1, not 2. ### Task 1: Generate Synchronized Video Scripts Generate a timeline with a step of 2 seconds. Provide View A Visual, View B Visual, and a Tracking Note (e.g., "{A1} is now {B1}"). ### Task 2: Generate 1 Complex MOC Question Create ONE single-choice question focus...
-
[15]
**Strict Structure**: You MUST generate exactly <num_steps>phases
-
[16]
**Focus Adherence**: Your visual descriptions MUST emphasize "<focus>"
-
[17]
**Logical Flow**: The phases must follow the correct timeline (Irreversible logic)
-
[18]
He cooks the meat
**Atomic Detail**: Do NOT write "He cooks the meat". Break it down: "Places pan", "Meat hits pan", "Searing sound", "Flipping meat"
-
[19]
<conflict>
**Dense Visuals**: Describe the **texture, color, and consistency** of the food at that exact moment. Show progression explicitly. ### Output JSON Format Strict JSON format with phases, events, visuals, and captions H.1.4 Plot Inference (Missing Middle) This task requires the generation of a narrative structure containing the beginning and ending seg- men...
-
[20]
NO camera/lighting jargon
**Visual**: Focus ONLY on Narrative Content (Characters, Actions, Environment, Plot). NO camera/lighting jargon
-
[21]
Empty if silent
**Caption**: Dialogue ONLY . Empty if silent. ### Option Generation (Crucial) Generate 6 distinct plot summaries for the missing Act 2. One Correct Answer, 5 plausible but incorrect Distractors. ### Output JSON Format Strict JSON format with question, options, correct_answer, and scripts H.1.5 Movie Understanding (Hard Single-Choice) Aimed at the retrieva...
-
[22]
**Target Video**: Must perfectly integrate ALL the Input Elements into the plot
-
[23]
They should be confusingly similar (e.g., same setting but different action), but MUST FAIL to match the full description
**Distractor Videos**: Must belong to the same Genre and style. They should be confusingly similar (e.g., same setting but different action), but MUST FAIL to match the full description. ### VISUAL & FORMAT CONSTRAINTS
-
[24]
**Independent Durations**: <video_instructions>
-
[25]
**Variable Pacing**: Use natural editing (Short Cuts 3-8s + Long Takes 15-30s)
-
[26]
Parallel Script
**Content Requirements**: A natural, descriptive sentence of what is seen (Action + Camera + Environment) and subtitles/sound effects. ### Output JSON Format Strict JSON format with logic_adaptation, question, correct_answer, and timelines for 4 videos H.1.6 Video Grounding / Alignment This is used to generate two parallel video scripts with subtle visual...
-
[27]
<variation>
**Enforce Variation**: You MUST apply the "<variation>" rule rigorously
-
[28]
<granularity>
**Enforce Granularity**: The descriptions must focus on the "<granularity>" level
-
[29]
Show progression
**Dense Visuals**: Describe texture, color, and consistency. Show progression
-
[30]
Hard Negative
**Micro-Events**: For each step, list 3-8 micro-events for Video A and 3-8 for Video B. ### Output JSON Format Strict JSON format with alignment_steps, function_desc, and dual video events H.1.7 Cooking Action (Hard Negative) Generates dense scripts containing atomic-level micro-actions, used to distinguish highly similar distractor videos. Cooking Prompt...
-
[31]
**Target Scenario**: Describe the target specifically performed in the required manner
-
[32]
Which video depicts a lion resting due to exhaustion rather than just sleeping?
**Distractor Scenarios**: Choose behaviors that fit the same Subject/Setting but imply a **different intent**. ### Step 2: Formulate Question (Intent-Based) Write a concise question focusing on the **Specific Intent** or **Nuance**. (e.g., "Which video depicts a lion resting due to exhaustion rather than just sleeping?") ### Step 3: Script Generation Gene...
-
[33]
**Full Process**: Start from loose parts ->Finish with the completed toy
-
[34]
**Granularity**: ONE clip = ONE distinct action (‘ATTACH‘, ‘DETACH‘, ‘ADJUST‘, ‘INSPECT‘, ‘SEARCH‘, ‘IDLE‘)
-
[35]
video script (Ground Truth)
**Visual Detail**: Describe the hands, specific parts, and physics. **ERROR LOGIC (Apply based on Config):** - **wrong_order**: Attaches B. Realizes A is missing. DETACHES B. Attaches A. Re-attaches B. - **previous_one_is_mistake**: Fails to attach C because B is loose. DETACHES B. Fixes it. Attaches C. - **shouldn’t_have_happened**: Picks up unnecessary ...
-
[36]
Global comparison: Videos 2/4 are friendly
-
[37]
Differential analysis: Video 3 shows standard defensive posture (staring, showing teeth, hackles raised)
-
[38]
Detail review: Video 1 initially was escaping, but when cornered at the end, also turned towards the target and lowered its center of gravity, fitting ’passive defense’ characteristics
-
[39]
, "final_answer
Conclusion: Both Videos 1 and 3 exhibited defensive behavioral intent.", "final_answer": ["A", "C"] } Final Answer Format: Must be in JSON format. Thefinal_answerfield must be a string composed of option letters, directly concatenated without spaces or symbols, and arranged in alphabetical order. Select 1-3 options, no need to not select or select all fou...
-
[41]
action":
get_caption Purpose: Get subtitle text Parameters: ·video_index: int (1, 2, 3, or 4) ·start_time: float (optional) ·end_time: float (optional) Operation Examples (Json Examples) Example 1: Forced Initialization Scenario: Task begins, indiscriminately retrieve dialogues to build the plot skeleton. { "action": "get_caption", "thought": "Task begins. As a fi...
-
[42]
Subtitles suggest V2 and V4 have undercover plots
-
[43]
Turn 5 visual overview confirms Video 4 is undercover escaping successfully, while Video 2 is undercover being executed
-
[44]
Turn 7 detail drilling shows V2 protagonist’s expression before death is relieved
-
[45]
, "final_answer
The question asks ’which video ends in tragedy with protagonist’s sacrifice’, only Video 2 meets the criteria.", "final_answer": "B" } Key Constraints Final Answer Format: Must be in JSON format. If it’s a multiple-choice question, thefinal_answerfield must contain only one uppercase letter (such as "A", "B", "C", "D"). ✓Correct example: "final_answer": "...
-
[47]
action":
get_caption Purpose: Get subtitle text Parameters: ·video_index: int (1, 2, 3, or 4) ·start_time: float (optional) ·end_time: float (optional) Operation Examples (Json Examples) Example 1: Forced Initialization and Subtitle Retrieval Scenario: Task just started, to understand what each of the four videos is doing (or their subtle differences in narration)...
-
[48]
Video 1 (Expert): Actions are smooth and fluid, picks up the bucket and directly aligns it with the slot, succeeds in one attempt, no extra actions
-
[49]
Video 3 (Novice): Hesitates for 5 seconds after picking up the bucket, finds it won’t close after installation, then performs a ’Detach’ action, flips the bucket and reinstalls successfully
-
[50]
Video 2: Actions are fast but rough, forcefully jams the bucket in, no correction
-
[51]
, "final_answer
The question asks ’who made a direction error and corrected it’, only Video 3 matches the description.", "final_answer": "C" } Key Constraints Final Answer Format: Must be in JSON format. If it’s a multiple-choice question, thefinal_answerfield must contain only one uppercase letter (such as "A", "B", "C", "D"). Correct example: "final_answer": "D" All re...
-
[52]
-focus_prompt: str (tell the vision model what to look at, must be specific!)
observe ·Purpose: Observe video frames ·Parameters: -observation_targets: List[Dict] (video_index,start_time,end_time,num_frames) · Tip: List contains 1 object = single video deep dive; List contains >1 objects = multi-video comparison. -focus_prompt: str (tell the vision model what to look at, must be specific!)
-
[53]
what just happened
get_caption ·Purpose: Get subtitle text ·Parameters: -video_index: int (1, 2, 3, or 4) -start_time: float (optional) -end_time: float (optional) Operation Examples (Json Examples) Example 1: Forced Initialization and Getting Key Dialogues Scenario: Task begins. You need to first listen to what people are saying in the ending (Act 3), because dialogues oft...
-
[54]
Subtitle clue: At the ending, the protagonist mentions ’it suddenly jumped out from the ventilation shaft’
-
[55]
Visual comparison: In Video 1, the ventilation cover is intact, in Video 2 the cover is on the floor, and there’s green slime around the ventilation shaft
-
[56]
Detail analysis: The protagonist has scratches on their arm, not burns
-
[57]
, "final_answer
Option matching: These evidences rule out ’earthquake’ (Option A) and ’gas leak’ (Option B), perfectly pointing to ’alien creature attack’ (Option D).", "final_answer": "D" } Key Constraints & Final Answer Format: Must be in JSON format. If it’s a multiple-choice question, thefinal_answerfield must contain only one uppercase letter (such as "A", "B", "C",...
-
[59]
functional semantics
get_caption Purpose: Get subtitle text Parameters: ·video_index: int (1, 2, 3, or 4) ·start_time: float (optional) ·end_time: float (optional) Operation Examples (Json Examples) Example 1: Forced Initialization and Reference Action Semantic Analysis Scenario: Task begins. The question provides an interval [15.5, 22.0] in Video 1 (Reference). You must firs...
-
[60]
Video 1’s reference segment [15.5, 22.0] shows ’manual onion chopping’
-
[61]
Although Video 2 uses a food processor (Visual Variation), it completes the exact same ’onion crushing’ task in the [53.2, 57.8] interval
-
[62]
, "final_answer
Start and end points have been semantically aligned.", "final_answer": [53.2, 57.8] } Key Constraints Final Answer: Only output [start, end] list. CRITICAL EXECUTION RULES (MUST FOLLOW) 1.JSON OUTPUT ONLY: Every single response you generate must be a strict, valid JSON object. Do NOT output any conversational text or internal monologue outside the JSON. 2...
-
[63]
·focus_prompt: str (tell the vision model what to look at, must be specific!)
observe Purpose: Observe video frames Parameters: ·observation_targets: List[Dict] (video_index,start_time,end_time,num_frames) *Tip: List contains 1 object = single video deep dive; List contains >1 objects = multi-video comparison. ·focus_prompt: str (tell the vision model what to look at, must be specific!)
-
[64]
action":
get_caption Purpose: Get subtitle text Parameters: ·video_index: int (1, 2, 3, or 4) ·start_time: float (optional) ·end_time: float (optional) Operation Examples (Json Examples) Example 1: Forced Initialization and Action Labeling Scenario: Received 4 shuffled video segments, first need to know what specific actions are happening in each segment for preli...
-
[65]
View A shows the target entered the tunnel entrance (disappeared)
-
[66]
View B shows no vehicles exited the tunnel exit during the same time period (T=15s-20s)
-
[67]
Combining both perspectives: the target is neither outside the entrance nor outside the exit
-
[68]
, "final_answer
Conclusion: The target is currently located inside the tunnel.", "final_answer": "C" } Key Constraints Only output one JSON at a time. Final Answer Format: "final_answer": "C". CRITICAL EXECUTION RULES (MUST FOLLOW) 1.JSON OUTPUT ONLY: Every single response you generate must be a strict, valid JSON object. Do NOT output any conversational text or internal...
-
[69]
T=0-10s: View A and View B both see a blue truck (ID#1), determined to be the same target
-
[70]
T=15s: View A sees a second blue truck (ID#2) entering, but View B is blocked by trees and didn’t capture it, rely on View A for counting
-
[71]
T=30s: View B sees a third car (ID#3) coming from the opposite direction
-
[72]
, "final_answer
Total: 3 unique blue trucks.", "final_answer": "A" } Key Constraints Only output one JSON at a time. Final Answer Format: "final_answer": "C". CRITICAL EXECUTION RULES (MUST FOLLOW) 1.JSON OUTPUT ONLY: Every single response you generate must be a strict, valid JSON object. Do NOT output any conversational text or internal monologue outside the JSON. 2.MIN...
-
[73]
·focus_prompt: str (tell the vision model what to look at, must be specific!)
observe Purpose: Observe video frames Parameters: ·observation_targets: List[Dict] (video_index,start_time,end_time,num_frames) *Tip: List contains 1 object = single video deep dive; List contains >1 objects = multi-video side-by-side comparison. ·focus_prompt: str (tell the vision model what to look at, must be specific!)
-
[74]
How do the two videos differ in their methods of cooking the chickpeas?
get_caption Purpose: Get subtitle text Parameters: ·video_index: int (1 or 2) ·start_time: float (optional) ·end_time: float (optional) Operation Examples (Json Examples) Example 1: Forced Initialization and Subtitle Retrieval Scenario: Task begins. The open-ended question asks "How do the two videos differ in their methods of cooking the chickpeas?". You...
-
[75]
Subtitles and visual tracking confirmed the chickpea preparation steps in both videos
-
[76]
In Video 1, the chef boils dried chickpeas in a standard pot and adds tea bags for color
-
[77]
In Video 2, the chef uses a pressure cooker to speed up the process and does not add any tea bags
-
[78]
, "final_answer
Both videos ultimately use the chickpeas for chana masala, but the foundational prep completely differs. I will synthesize this into a clear descriptive paragraph.", "final_answer": "Video 1 boils dried chickpeas in a standard pot along with tea bags to impart a darker color, whereas Video 2 utilizes a pressure cooker for a faster cooking process without ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.