Reliable Reasoning with Large Language Models via Preference-Based Maximum Satisfiability
Pith reviewed 2026-06-29 07:05 UTC · model grok-4.3
The pith
LLMs generate code for preference-based MaxSAT problems that exact solvers solve and independent verification confirms as feasible and optimal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
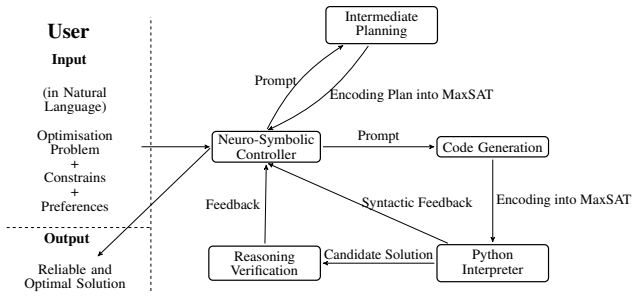
Given a natural language problem description, an LLM generates Python code that encodes user-defined constraints and preferences as a preference-based Maximum Satisfiability problem, which is solved by an exact MaxSAT solver; solutions are then independently verified for feasibility and optimality against a canonical MaxSAT encoding, allowing for different encodings and multiple optimal solutions, and this pipeline produces substantially higher acceptance rates than direct-answer, chain-of-thought, or program-of-thought baselines.
What carries the argument
LLM-generated Python code that formulates the input as a preference-based MaxSAT instance, which an exact solver resolves and which is then checked against a canonical encoding for feasibility and optimality.
If this is right
- LLMs become usable for complex optimization by producing solver-ready encodings rather than final answers.
- Solutions remain acceptable even when multiple optima exist or encodings differ, provided verification passes.
- The method applies across open-source and closed-access LLMs on families of preference reasoning tasks.
- Correctness is measured under independently verified reference semantics instead of surface-level output matching.
Where Pith is reading between the lines
- The separation of code generation from solving could extend to other exact solvers for different problem classes.
- Verification against a canonical encoding provides a practical route to trustworthy LLM outputs on structured tasks.
- The approach suggests testing whether LLMs can also generate the canonical encodings themselves for fully automated pipelines.
Load-bearing premise
The LLM-generated code must correctly encode the natural language constraints and preferences so that its solutions match the reference semantics when verified against the canonical MaxSAT formulation.
What would settle it
A new collection of preference-based tasks on which the MaxSAT pipeline produces verified feasible and optimal solutions at rates no higher than the direct LLM, chain-of-thought, and program-of-thought baselines.
Figures
read the original abstract
Large Language Models (LLMs) excel at understanding natural language but struggle with optimisation tasks involving multiple constraints and user-defined preferences, which commonly arise in domains such as robotics. We propose a hybrid reasoning approach in which LLMs externalise reasoning through code generation. Given a natural language problem description, an LLM generates Python code that encodes user-defined constraints and preferences as a preference-based Maximum Satisfiability (MaxSAT) problem, which is then solved by an exact MaxSAT solver. To ensure correctness, solutions returned by the model-generated code are independently verified for feasibility and optimality against a canonical MaxSAT encoding, allowing for different encodings and multiple optimal solutions. We evaluate our approach using both open-source and closed-access LLMs on three families of preference-based reasoning tasks, and compare it against direct-answer, chain-of-thought, and program-of-thought baselines using the same models. While these baselines rarely produce feasible solutions, the MaxSAT-based pipeline achieves substantially higher acceptance rates, in some cases exceeding 80%. Our results demonstrate that LLM-driven code generation combined with preference-based MaxSAT enables solver-verifiable optimisation with respect to generated encodings, and substantially improves correctness under independently verified reference semantics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid approach in which LLMs generate Python code to encode natural-language preference-based optimization problems as MaxSAT instances; these are solved by an exact MaxSAT solver and the returned solutions are checked for feasibility and optimality against a canonical MaxSAT encoding (allowing different encodings and multiple optima). On three families of preference-based reasoning tasks the MaxSAT pipeline yields acceptance rates substantially higher than direct-answer, chain-of-thought and program-of-thought baselines, in some cases exceeding 80%.
Significance. If the verification procedure is robust, the work offers a concrete route to solver-verifiable optimization with user preferences, a setting common in robotics and planning. The explicit use of an exact MaxSAT solver together with independent feasibility/optimalty checks against a reference encoding is a methodological strength that supplies falsifiable correctness guarantees not present in pure LLM baselines.
major comments (1)
- [Abstract] Abstract: the central claim that the method 'substantially improves correctness under independently verified reference semantics' rests on the canonical MaxSAT encoding serving as an unbiased reference. The manuscript must specify (in the evaluation or method section) how the canonical encodings for the three task families are constructed, whether they were validated by independent parties, and how allowance for 'different encodings' is operationalized in the acceptance metric; without this the high acceptance rates may simply indicate that the LLM matched the authors' chosen encoding rather than solving the underlying preference problem.
minor comments (1)
- [Abstract] The abstract should name the three task families and the concrete LLMs used so that readers can immediately assess the scope of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about the canonical encodings is valid and we will revise the manuscript to provide the requested details on their construction and the acceptance metric.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'substantially improves correctness under independently verified reference semantics' rests on the canonical MaxSAT encoding serving as an unbiased reference. The manuscript must specify (in the evaluation or method section) how the canonical encodings for the three task families are constructed, whether they were validated by independent parties, and how allowance for 'different encodings' is operationalized in the acceptance metric; without this the high acceptance rates may simply indicate that the LLM matched the authors' chosen encoding rather than solving the underlying preference problem.
Authors: We agree that explicit details are required. In the revised manuscript we will add a dedicated subsection (Evaluation, §4.2) describing the construction process: for each task family the canonical encoding is derived directly from the formal problem definition by (i) mapping user preferences to a fixed set of hard clauses (feasibility) and soft clauses (optimality) using standard MaxSAT modeling, (ii) assigning a canonical variable ordering and clause representation, and (iii) confirming that the encoding produces the expected optimal cost on a small set of hand-verified instances. These encodings were developed by the authors following the task specifications; no external independent validation was performed, but the verification pipeline itself is solver-independent. The acceptance metric operationalizes 'different encodings' by checking equivalence of the returned solution: after mapping variables via a bijection (when needed), we verify that the LLM-generated solution satisfies all hard clauses of the canonical encoding and attains an identical optimal soft-clause cost; multiple optima are accepted if they share the same cost. This procedure ensures the metric evaluates preference satisfaction rather than syntactic identity with the authors' encoding. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical pipeline where LLMs generate Python code to encode problems as preference-based MaxSAT instances, solved by external exact MaxSAT solvers, with solutions verified for feasibility and optimality against a separately constructed canonical encoding (explicitly allowing different encodings and multiple optima). Acceptance rates are measured by whether generated solutions pass these external checks, then compared to direct/CoT/PoT baselines. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the central claims rest on independent solver verification and external benchmarks rather than internal construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fahiem Bacchus, Matti Järvisalo, and Ruben Martins. Maximum satisfiability. In Armin Biere, Marijn Heule, Hans van Maaren, and Toby Walsh, editors,Handbook of Satisfiability - Second Edition, volume 336 ofFrontiers in Artificial Intelligence and Applications, pages 929–991. IOS Press, 2021. doi: 10.3233/FAIA201008
-
[2]
IOS Press, 2009
Armin Biere, Marijn Heule, Hans van Maaren, and Toby Walsh, editors.Handbook of Sat- isfiability, volume 185 ofFrontiers in Artificial Intelligence and Applications. IOS Press, 2009
2009
-
[3]
Logically consistent language models via neuro-symbolic integration
Diego Calanzone, Stefano Teso, and Antonio Vergari. Logically consistent language models via neuro-symbolic integration. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[4]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.Trans. Mach. Learn. Res., 2023, 2023. 10
2023
-
[5]
Pal: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. InInternational Conference on Machine Learning, pages 10764–10799. PMLR, 2023
2023
-
[6]
Pddl—the planning domain definition language.Technical Report, Tech
Malik Ghallab, Adele Howe, Craig Knoblock, ISI Drew McDermott, Ashwin Ram, Manuela Veloso, Daniel Weld, David Wilkins Sri, Anthony Barrett, Dave Christianson, et al. Pddl—the planning domain definition language.Technical Report, Tech. Rep., 1998
1998
-
[7]
Gemini-3.1-Pro https://blog.google/innovation-and-ai/ models-and-research/gemini-models/gemini-3-1-pro/ , 2026
Google. Gemini-3.1-Pro https://blog.google/innovation-and-ai/ models-and-research/gemini-models/gemini-3-1-pro/ , 2026. Released: 2026-02- 19
2026
-
[8]
Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning.Advances in Neural Information Processing Systems, 36:79081–79094, 2023
2023
-
[9]
Large language models can solve real-world planning rigorously with formal verification tools
Yilun Hao, Yongchao Chen, Yang Zhang, and Chuchu Fan. Large language models can solve real-world planning rigorously with formal verification tools. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL, pages 3434–3483. Association for Computation...
2025
-
[10]
Planning anything with rigor: General-purpose zero-shot planning with llm-based formalized programming
Yilun Hao, Yang Zhang, and Chuchu Fan. Planning anything with rigor: General-purpose zero-shot planning with llm-based formalized programming. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[11]
https://huggingface.co, 2026
HuggingFace. .https://huggingface.co, 2026. [Online; accessed 21-January-2026]
2026
-
[12]
PySAT: A python toolkit for prototyping with SAT oracles
Alexey Ignatiev, António Morgado, and João Marques-Silva. PySAT: A python toolkit for prototyping with SAT oracles. In Olaf Beyersdorff and Christoph M. Wintersteiger, editors, Theory and Applications of Satisfiability Testing - SAT 2018, volume 10929 ofLecture Notes in Computer Science, pages 428–437. Springer, 2018. doi: 10.1007/978-3-319-94144-8_26
-
[13]
RC2: an efficient MaxSAT solver
Alexey Ignatiev, António Morgado, and João Marques-Silva. RC2: an efficient MaxSAT solver. J. Satisf. Boolean Model. Comput., 11(1):53–64, 2019
2019
-
[14]
Exploiting maxsat for preference-based planning
Farah Juma, Eric I Hsu, and Sheila A McIlraith. Exploiting maxsat for preference-based planning. InProceedings of the ICAPS-11 Workshop on Constraint Satisfaction Techniques for Planning and Scheduling Problems (COPLAS), 2011
2011
-
[15]
Hsu, and Sheila A
Farah Juma, Eric I. Hsu, and Sheila A. McIlraith. Preference-based planning via maxsat. InAdvances in Artificial Intelligence - 25th Canadian Conference on Artificial Intelligence, Canadian AI 2012, Toronto, ON, Canada, May 28-30, 2012. Proceedings, volume 7310 of Lecture Notes in Computer Science, pages 109–120. Springer, 2012
2012
-
[16]
Position: Llms can’t plan, but can help planning in llm-modulo frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Paul Saldyt, and Anil B Murthy. Position: Llms can’t plan, but can help planning in llm-modulo frameworks. InForty-first International Conference on Machine Learning, 2024
2024
-
[17]
Maxsat, hard and soft constraints
Chu Min Li and Felip Manya. Maxsat, hard and soft constraints. InHandbook of satisfiability, pages 613–631. IOS Press, 2009
2009
-
[18]
Liang, Chenyang Yang, and Brad A
Jenny T. Liang, Chenyang Yang, and Brad A. Myers. A large-scale survey on the usability of AI programming assistants: Successes and challenges. InICSE 2024, pages 52:1–52:13. ACM,
2024
-
[19]
doi: 10.1145/3597503.3608128
-
[20]
Zebralogic: On the scaling limits of llms for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning. In Forty-second International Conference on Machine Learning, 2025
2025
-
[21]
Truthfulqa: Measuring how models mimic hu- man falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic hu- man falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022. 11
2022
-
[22]
Llama-3.3 https://www.llama.com/docs/model-cards-and-prompt-formats/ llama3_3/, 2024
Meta. Llama-3.3 https://www.llama.com/docs/model-cards-and-prompt-formats/ llama3_3/, 2024. Released: 2024-12
2024
-
[23]
GPT5.5 https://openai.com/index/introducing-gpt-5-5/ , 2026
OpenAI. GPT5.5 https://openai.com/index/introducing-gpt-5-5/ , 2026. Released: 2026-04-23
2026
-
[24]
Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning
Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 3806–3824, 2023
2023
-
[25]
PhD thesis, University of Cambridge, UK, 2012
Richard Anthony Russell.Planning with preferences using maximum satisfiability. PhD thesis, University of Cambridge, UK, 2012. URL https://ethos.bl.uk/OrderDetails. do?uin=uk.bl.ethos.610496
2012
-
[26]
Ranjan Sapkota, Konstantinos I Roumeliotis, and Manoj Karkee. Vibe coding vs. agentic coding: Fundamentals and practical implications of agentic ai.arXiv preprint arXiv:2505.19443, 2025
-
[27]
Constraintllm: A neuro-symbolic framework for industrial-level constraint programming
Weichun Shi, Minghao Liu, Wanting Zhang, Langchen Shi, Fuqi Jia, Feifei Ma, and Jian Zhang. Constraintllm: A neuro-symbolic framework for industrial-level constraint programming. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16010–16030, 2025
2025
-
[28]
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. InNeurIPS 2025, 2025
2025
-
[29]
Mcp-solver: Integrating language models with constraint programming systems
Stefan Szeider. Mcp-solver: Integrating language models with constraint programming systems. arXiv preprint arXiv:2501.00539, 2024
-
[30]
On the planning abilities of large language models-a critical investigation.Advances in Neural Information Processing Systems, 36:75993–76005, 2023
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. On the planning abilities of large language models-a critical investigation.Advances in Neural Information Processing Systems, 36:75993–76005, 2023
2023
-
[31]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[32]
Aristotle: Mastering logical reasoning with a logic- complete decompose-search-resolve framework
Jundong Xu, Hao Fei, Meng Luo, Qian Liu, Liangming Pan, William Yang Wang, Preslav Nakov, Mong-Li Lee, and Wynne Hsu. Aristotle: Mastering logical reasoning with a logic- complete decompose-search-resolve framework. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3052–3075, 2025
2025
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Satlm: Satisfiability-aided language models using declarative prompting.Advances in Neural Information Processing Systems, 36: 45548–45580, 2023
Xi Ye, Qiaochu Chen, Isil Dillig, and Greg Durrett. Satlm: Satisfiability-aided language models using declarative prompting.Advances in Neural Information Processing Systems, 36: 45548–45580, 2023
2023
-
[35]
Multilingual machine translation with large language models: Empirical results and analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. Multilingual machine translation with large language models: Empirical results and analysis. InFindings of the association for computational linguistics: NAACL 2024, pages 2765–2781, 2024. 12 A Prompt Templates This appendix summarises the prompt temp...
2024
-
[36]
Soft constraints / preferences
-
[37]
Objective (weighted MaxSAT)
-
[38]
objective_cost
Output schema (repeat the JSON schema to emit) Do NOT write code. Do NOT use external data. The generated plan is provided verbatim to the subsequent code-generation step. A.2 RC2 Solver Usage Prompt The following prompt is provided verbatim to the LLMSto explain how to use the RC2 MaxSAT solver through thePySATAPI: # RC2 / WCNF usage # IMPORTANT: The cal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.