Momentum Based Reward Design for Low Emission Traffic Signal Control
Pith reviewed 2026-06-29 08:56 UTC · model grok-4.3
The pith
A momentum-based reward for traffic signal reinforcement learning improves throughput-emission trade-offs and learning stability over delay or queue penalties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
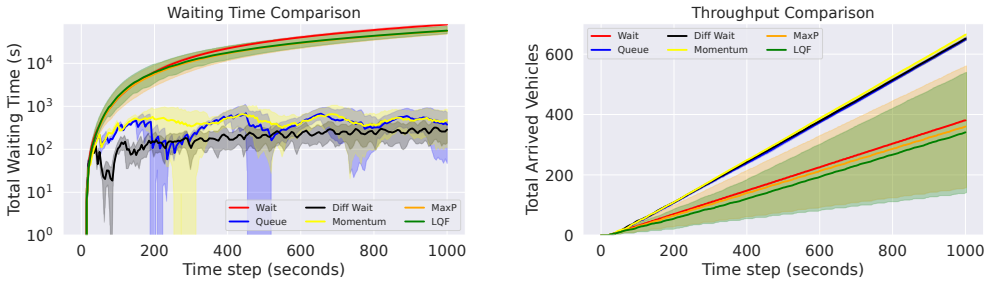
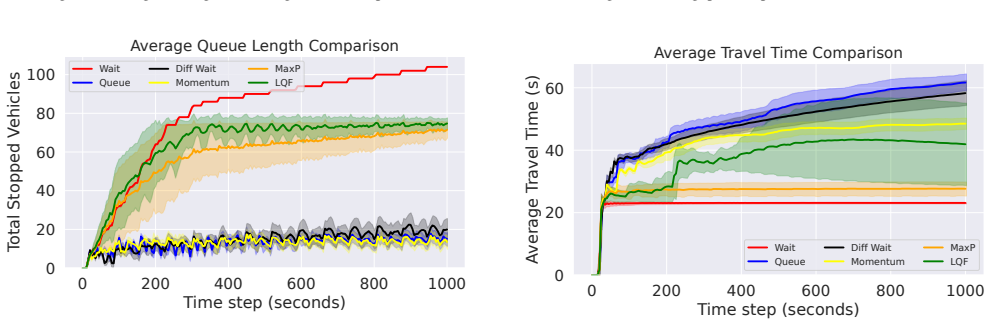
The Momentum-Based Reward Function produces policies with better throughput-emission trade-offs and more stable learning behavior than delay or queue-based rewards, as well as classical controllers such as Max Pressure and LQF.
What carries the argument
The Momentum-Based Reward Function (MBRF), which rewards continuous vehicle movement rather than penalizing congestion alone.
If this is right
- DRL agents learn policies that sustain higher throughput while lowering CO2 emissions in the tested scenarios.
- Training exhibits more stable behavior with reduced variance compared to delay or queue rewards.
- The method outperforms Max Pressure and LQF controllers on standard traffic metrics in SUMO.
- Adaptive signal control can respond to dynamic conditions while targeting both flow and emissions.
Where Pith is reading between the lines
- The same momentum principle could be tested in other flow-control tasks such as energy systems or supply chains.
- Combining MBRF with multi-intersection coordination might extend gains to larger urban networks.
- Direct comparison against emission-specific rewards would clarify whether momentum is the key driver.
Load-bearing premise
That performance differences observed inside the SUMO simulator will translate to real-world traffic networks and that the momentum-based reward will not introduce unintended side effects such as unsafe signal timings.
What would settle it
A deployment on a real intersection or higher-fidelity simulator where MBRF policies produce higher emissions, lower throughput, or less stable behavior than delay-based rewards or Max Pressure.
Figures



read the original abstract
Urban traffic congestion is a growing global issue contributing significantly to long commute times and environmental pollution. Traditional traffic signal control systems often fail to adapt to dynamic traffic conditions. Adaptive traffic signal control can improve urban traffic without changing road infrastructure. Deep Reinforcement Learning (DRL) has shown strong performance for this task, but existing delay and queue-based rewards often produce short-sighted or unstable policies. This paper proposes a Momentum-Based Reward Function (MBRF) that encourages vehicles to keep moving rather than penalizing congestion alone. The method is evaluated in SUMO (Simulation of Urban MObility) using standard traffic metrics such as waiting time, queue length, throughput, and CO2 emissions. Results show that the proposed reward produces better throughput-emission trade-offs and more stable learning behavior than delay or queue-based rewards, as well as classical controllers such as Max Pressure and LQF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Momentum-Based Reward Function (MBRF) for deep reinforcement learning in adaptive traffic signal control. The MBRF encourages continuous vehicle movement rather than solely penalizing delay or queues, with the goal of achieving superior throughput-emission trade-offs and more stable learning dynamics. Evaluation occurs in the SUMO simulator using metrics such as waiting time, queue length, throughput, and CO2 emissions, with comparisons to delay/queue-based rewards and classical controllers including Max Pressure and LQF.
Significance. If the simulation results hold under scrutiny, the work could contribute to improved reward engineering for RL-based traffic systems, addressing known limitations of myopic rewards while targeting emission reductions. The use of a standard simulator and conventional metrics provides a reproducible baseline for comparison.
major comments (3)
- [Abstract] Abstract: The central claim of better throughput-emission trade-offs and more stable learning is asserted without any quantitative results, error bars, statistical tests, or training details, so the data cannot be checked against the claim.
- [Experiments] Experiments/Results sections: No analysis is provided on whether performance differences survive domain shift to real-world networks or remain safe under sensor noise, pedestrian presence, or non-ideal vehicle dynamics; this is load-bearing for the engineering conclusion that MBRF yields low-emission control.
- [Method] Method section: The precise formulation of the momentum term (e.g., how velocity or movement history enters the reward) is not visible, preventing assessment of whether it genuinely mitigates the short-sightedness attributed to delay/queue rewards.
minor comments (2)
- Add explicit discussion of hyperparameter sensitivity for the momentum coefficient and any ablation studies isolating its contribution.
- Ensure all figures include error bars or confidence intervals and that tables report exact numerical values rather than qualitative descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions have been or will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of better throughput-emission trade-offs and more stable learning is asserted without any quantitative results, error bars, statistical tests, or training details, so the data cannot be checked against the claim.
Authors: We agree that the abstract would be strengthened by including quantitative support. The results section reports metrics with error bars from five independent runs and includes statistical comparisons. In the revised manuscript, we have updated the abstract to summarize key quantitative findings on throughput-emission trade-offs and learning stability. revision: yes
-
Referee: [Experiments] Experiments/Results sections: No analysis is provided on whether performance differences survive domain shift to real-world networks or remain safe under sensor noise, pedestrian presence, or non-ideal vehicle dynamics; this is load-bearing for the engineering conclusion that MBRF yields low-emission control.
Authors: We acknowledge that robustness under real-world conditions is important for the engineering claims. Our evaluation follows the standard practice in the field by focusing on controlled SUMO simulations for reward design comparison. We have added a dedicated limitations paragraph in the discussion section that explicitly addresses domain shift, sensor noise, pedestrians, and non-ideal dynamics, along with suggested future validation steps. revision: partial
-
Referee: [Method] Method section: The precise formulation of the momentum term (e.g., how velocity or movement history enters the reward) is not visible, preventing assessment of whether it genuinely mitigates the short-sightedness attributed to delay/queue rewards.
Authors: The momentum term is defined in the Method section (see Equation 3 and surrounding text) as an additive component that incorporates recent velocity history to reward sustained movement. We will revise the section to present the formulation more prominently, with an expanded derivation showing how it differs from pure delay or queue penalties, and we will include a short algorithmic outline for clarity. revision: yes
- Empirical evaluation of MBRF performance under real-world domain shifts, sensor noise, pedestrian interactions, or non-ideal vehicle dynamics (these would require new experiments outside the current simulation study).
Circularity Check
No circularity: empirical reward proposal with simulation evaluation
full rationale
The paper introduces a Momentum-Based Reward Function (MBRF) as a design choice to encourage continuous vehicle movement and reports comparative SUMO simulation outcomes on throughput, emissions, waiting time, and learning stability versus delay/queue rewards and Max-Pressure/LQF. No derivation chain, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatz smuggling is present; the performance claims rest on external simulator benchmarks rather than reducing to the reward definition itself by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Co2 emissions from cars: facts and figures (infographics),
European Parliament, “Co2 emissions from cars: facts and figures (infographics),” https://www.europarl.europa.eu/topics/en/article/20190313STO31218/co2- emissions-from-cars-facts-and-figures-infographics, 2019
-
[2]
Traffic congestion costs u.s. cities billions of dollars every year [infographic]),
Niall McCarthy, “Traffic congestion costs u.s. cities billions of dollars every year [infographic]),” https://www.forbes.com/sites/niallmccarthy/2020/03/10/traffic- congestion-costs-us-cities-billions-of-dollars-every-year-infographic/, 2020
2020
-
[3]
Design and application of real-time traffic simulation platform based on utc/scoot and vissim,
K. Liu, “Design and application of real-time traffic simulation platform based on utc/scoot and vissim,”Journal of Simulation, vol. 18, no. 4, pp. 539–556, 2024. [Online]. Available: https://doi.org/10.1080/17477778.2023.2233464
-
[4]
A stable longest queue first signal scheduling algorithm for an isolated intersection,
R. Wunderlich, I. Elhanany, and T. Urbanik, “A stable longest queue first signal scheduling algorithm for an isolated intersection,” in International Conference on Vehicular Electronics and Safety, 2007, pp. 1–6
2007
-
[5]
A survey on traffic signal control methods,
H. Wei, G. Zheng, V . Gayah, and Z. Li, “A survey on traffic signal control methods,” 2020. [Online]. Available: https://arxiv.org/abs/1904.08117
-
[6]
Multi-agent deep reinforce- ment learning for large-scale traffic signal control,
T. Chu, J. Wang, L. Codec `a, and Z. Li, “Multi-agent deep reinforce- ment learning for large-scale traffic signal control,”IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 3, pp. 1086–1095, 2020
2020
-
[7]
A deep reinforcement learning network for traffic light cycle control,
X. Liang, X. Du, G. Wang, and Z. Han, “A deep reinforcement learning network for traffic light cycle control,”IEEE Transactions on Vehicular Technology, vol. 68, no. 2, pp. 1243–1253, 2019
2019
-
[8]
Traffic light control using deep policy-gradient and value-function-based reinforcement learning,
S. S. Mousavi, M. Schukat, and E. Howley, “Traffic light control using deep policy-gradient and value-function-based reinforcement learning,”IET Intelligent Transport Systems, vol. 11, no. 7, pp. 417–423, 2017. [Online]. Avail- able: https://ietresearch.onlinelibrary.wiley.com/doi/abs/10.1049/iet- its.2017.0153
-
[9]
Intellilight: A reinforcement learning approach for intelligent traffic light control,
H. Wei, G. Zheng, H. Yao, and Z. Li, “Intellilight: A reinforcement learning approach for intelligent traffic light control,” inProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018, pp. 2496–2505
2018
-
[10]
Traffic signal control based on deep reinforcement learning using state fusion and trend reward,
X. Tan, Y . Zhou, and X. Jiao, “Traffic signal control based on deep reinforcement learning using state fusion and trend reward,”Engineering Applications of Artificial Intelligence, vol. 159, p. 111701, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0952197625017038
2025
-
[11]
Blindlight: High robustness reinforcement learning method to solve partially blinded traffic signal control problem,
Q. Jiang, M. Qin, H. Zhang, X. Zhang, and W. Sun, “Blindlight: High robustness reinforcement learning method to solve partially blinded traffic signal control problem,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 11, pp. 16 625–16 641, 2024
2024
-
[12]
Deep reinforcement learning-based vehicle driving strategy to reduce crash risks in traffic oscillations,
M. Li, Z. Li, C. Xu, and T. Liu, “Deep reinforcement learning-based vehicle driving strategy to reduce crash risks in traffic oscillations,” Transportation Research Record: Journal of the Transportation Re- search Board, vol. 2674, p. 036119812093797, 08 2020
2020
-
[13]
Carbon emission reduction in traffic control: A signal timing optimization method based on rainbow dqn,
J. Lv, Z. Wang, and J. Ma, “Carbon emission reduction in traffic control: A signal timing optimization method based on rainbow dqn,”Applied Sciences, vol. 15, no. 3, 2025. [Online]. Available: https://www.mdpi.com/2076-3417/15/3/1101
2025
-
[14]
Zhang, F
G. Zhang, F. Chang, J. Jin, F. Yang, and H. Huang, “Multi- objective deep reinforcement learning approach for adaptive traffic signal control system with concurrent optimization of safety, efficiency, and decarbonization at intersections,”Accident Analysis & Prevention, vol. 199, p. 107451, 2024. [Online]. Available: https://www.sciencedirect.com/science/...
2024
-
[15]
Presslight: Learning max pressure control to coordinate traffic signals in arterial network,
H. Wei, C. Chen, G. Zheng, K. Wu, V . Gayah, K. Xu, and Z. Li, “Presslight: Learning max pressure control to coordinate traffic signals in arterial network,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1290–1298. [Online]...
-
[16]
The max-pressure controller for arbitrary networks of signalized intersections
P. Varaiya, “The max-pressure controller for arbitrary networks of signalized intersections.” Springer Nature, mar 2013, pp. 27–66
2013
-
[17]
Deep reinforcement learning for traffic signal control model and adaptation study,
J. Tan, Q. Yuan, W. Guo, N. Xie, F. Liu, J. Wei, and X. Zhang, “Deep reinforcement learning for traffic signal control model and adaptation study,”Sensors, vol. 22, no. 22, 2022. [Online]. Available: https://www.mdpi.com/1424-8220/22/22/8732
2022
-
[18]
Deep reinforcement learning based approach for traffic signal control,
K. B ´alint, T. Tam ´as, and B. Tam ´as, “Deep reinforcement learning based approach for traffic signal control,”Transportation Research Procedia, vol. 62, pp. 278–285, 2022, 24th Euro Working Group on Transportation Meeting. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2352146522001624
2022
-
[19]
Integrated routing and traffic signal control for cavs via reinforcement learning approach,
J. Park, G. Zhang, C. Wang, H. Wang, and Z.-P. Jiang, “Integrated routing and traffic signal control for cavs via reinforcement learning approach,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC), 2024, pp. 558–563
2024
-
[20]
Integrated freeway traffic control using q-learning with adjacent arterial traffic considerations,
T. Yuan and P. A. Ioannou, “Integrated freeway traffic control using q-learning with adjacent arterial traffic considerations,”IEEE Trans. on Intelligent Transportation Systems, vol. 26, no. 6, pp. 7655–7666, 2025
2025
-
[21]
Deep reinforcement learning- based intelligent traffic signal controls with optimized co2 emissions,
P. Agand, A. Iskrov, and M. Chen, “Deep reinforcement learning- based intelligent traffic signal controls with optimized co2 emissions,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 5495–5500
2023
-
[22]
SUMO-RL,
L. N. Alegre, “SUMO-RL,” https://github.com/LucasAlegre/sumo-rl, 2019
2019
-
[23]
Learning an interpretable traffic signal control policy,
J. Ault, J. P. Hanna, and G. Sharon, “Learning an interpretable traffic signal control policy,” inProceedings of the 19th International Con- ference on Autonomous Agents and MultiAgent Systems, ser. AAMAS ’20. Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems, 2020, p. 88–96
2020
-
[24]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, 2nd ed. The MIT Press, 2018. [Online]. Available: http://incompleteideas.net/book/the-book-2nd.html
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.