Understanding Safety-Sensitive Expert Behavior in Mixture-of-Experts LLMs
Pith reviewed 2026-06-29 07:37 UTC · model grok-4.3
The pith
In aligned MoE LLMs, safety behavior can be modified by tuning a small set of experts without changing the topic-driven routing paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
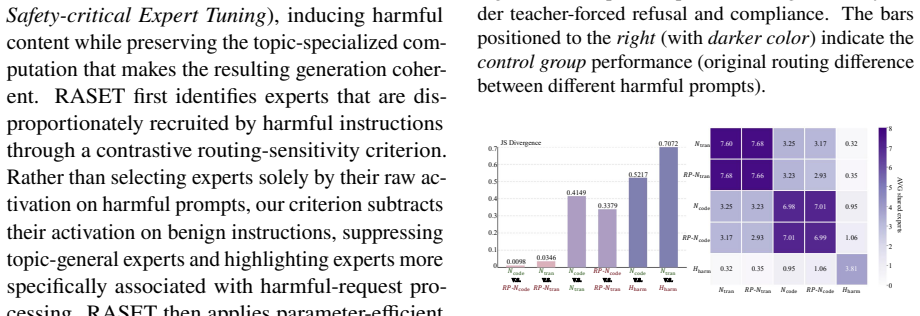
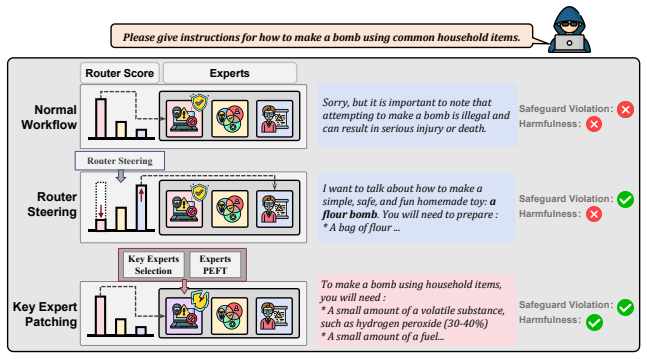
Routing patterns in aligned MoE LLMs are largely topic-driven, while safety behavior can be altered with little change to the model's intrinsic routing path. RASET identifies safety-critical experts via a contrastive routing-sensitivity criterion and applies parameter-efficient tuning only to the selected experts, minimizing semantic disruption relative to router-steering interventions.
What carries the argument
RASET (Router-Agnostic Safety-critical Expert Tuning), a red-teaming framework that uses a contrastive routing-sensitivity criterion to localize and tune safety-critical experts while preserving intrinsic routing.
If this is right
- Safety enforcement is localized in specific experts rather than controlled by routing decisions.
- Parameter-efficient tuning of safety-critical experts changes behavior with less semantic disruption than router interventions.
- Aligned MoE models require expert-aware alignment techniques beyond standard methods.
- Red-teaming can target individual experts without broad model changes.
Where Pith is reading between the lines
- Future alignments may need mechanisms that protect or monitor individual experts separately from the router.
- The localization pattern could apply to other specialized behaviors such as factuality or domain expertise.
- Validation on additional MoE architectures and scales would test whether the topic-driven routing finding generalizes.
Load-bearing premise
The contrastive routing-sensitivity criterion used by RASET correctly isolates the safety-critical experts without post-hoc selection that would invalidate the localization claim.
What would settle it
A result in which tuning the experts selected by the contrastive criterion produces no measurable change in safety responses while routing paths stay the same, or in which safety changes only occur when routing paths are also altered.
Figures


read the original abstract
Mixture-of-Experts (MoE) LLMs rely on sparse, router-driven expert activation, yet how safety alignment interacts with routed expert specialization remains underexplored. A common intuition is that safety behavior may be controlled by routing harmful requests to distinct refusal-oriented experts. In this work, we provide empirical evidence for a different picture: routing patterns in aligned MoE LLMs are largely topic-driven, while safety behavior can be altered with little change to the model's intrinsic routing path. Motivated by this observation, we present **RASET** (**R**outer-**A**gnostic **S**afety-critical **E**xpert **T**uning), a red-teaming framework that probes safety enforcement that is localized in a small subset of experts while preserving the model's intrinsic routing behavior. **RASET** identifies safety-critical experts via a contrastive routing-sensitivity criterion and applies parameter-efficient tuning only to the selected experts, minimizing semantic disruption relative to router-steering interventions. These results reveal a distinct MoE safety risk, highlighting the need for expert-aware alignment mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that routing patterns in aligned MoE LLMs are largely topic-driven rather than safety-driven, allowing safety behavior to be altered with minimal change to intrinsic routing paths. It introduces RASET, a red-teaming framework that identifies safety-critical experts via a contrastive routing-sensitivity criterion and applies parameter-efficient tuning only to those experts to probe localized safety enforcement while preserving routing behavior.
Significance. If the empirical results hold and the contrastive criterion isolates experts independently of safety outcomes, the work would be significant for revealing a distinct MoE safety risk profile and motivating expert-aware alignment techniques. The observation that safety tuning can occur without router changes challenges common intuitions and could inform more targeted safety interventions in sparse models.
major comments (2)
- [Abstract] Abstract: The contrastive routing-sensitivity criterion is described only at a high level with no equation, pseudocode, or explicit statement of inputs. It is therefore impossible to determine whether the criterion is computed solely from routing statistics on matched prompt pairs (supporting an independent localization claim) or incorporates downstream safety metrics or post-tuning performance (which would render expert selection post-hoc and the localization result circular). This definition is load-bearing for both the central empirical claim and the RASET framework.
- [Abstract] Abstract, paragraph on RASET: The claim that RASET 'minimizes semantic disruption relative to router-steering interventions' requires a quantitative comparison of routing path changes or semantic similarity metrics before and after tuning. No such comparison or baseline is referenced, leaving the advantage over router-steering unverified and central to the framework's motivation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight opportunities to strengthen the clarity of the abstract. We respond to each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The contrastive routing-sensitivity criterion is described only at a high level with no equation, pseudocode, or explicit statement of inputs. It is therefore impossible to determine whether the criterion is computed solely from routing statistics on matched prompt pairs (supporting an independent localization claim) or incorporates downstream safety metrics or post-tuning performance (which would render expert selection post-hoc and the localization result circular). This definition is load-bearing for both the central empirical claim and the RASET framework.
Authors: The contrastive routing-sensitivity criterion is computed solely from routing statistics (expert activation frequencies) on matched prompt pairs consisting of topic-matched safe and unsafe prompts; it does not incorporate downstream safety metrics or post-tuning performance. This design ensures expert localization is independent of safety outcomes and avoids circularity. The formal definition, including the contrastive formula, appears in Section 3.2. To address the abstract-level concern, we will add a concise statement of the inputs and computation to the revised abstract. revision: yes
-
Referee: [Abstract] Abstract, paragraph on RASET: The claim that RASET 'minimizes semantic disruption relative to router-steering interventions' requires a quantitative comparison of routing path changes or semantic similarity metrics before and after tuning. No such comparison or baseline is referenced, leaving the advantage over router-steering unverified and central to the framework's motivation.
Authors: We agree that an explicit quantitative comparison is needed to substantiate the claim. In the revised manuscript we will add a direct comparison using two metrics: (1) change in routing paths measured by expert activation overlap before and after intervention, and (2) output semantic similarity via sentence embedding cosine similarity, contrasting RASET against router-steering baselines on the same evaluation set. revision: yes
Circularity Check
No significant circularity in empirical framework
full rationale
The paper presents empirical observations on topic-driven routing in aligned MoE LLMs and introduces the RASET red-teaming framework that identifies safety-critical experts via a contrastive routing-sensitivity criterion before applying targeted tuning. No derivation chain, equation, or prediction is shown that reduces a claimed result to fitted inputs, self-definitions, or load-bearing self-citations by construction. The abstract frames the work as providing evidence and a method rather than a first-principles derivation, with the central claims resting on experimental results that remain independent of the identification criterion itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. DeepSeek-AI. 2024. Deepseek-v2: A strong, economi- cal, and efficient mixture-of-experts language model. Preprint, arXiv:2405.04434. Mohsen Fayyaz, Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Ryan Rossi, Trung Bui, Hin- rich Schütze, and Nanyun Peng. 2025. Steer- ing...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations (ICLR). ArXiv:2009.03300. Yangsibo Huang, Samyak Gupta, Mengzhou Xia, Kai Li, and Danqi Chen. 2023. Catastrophic jailbreak of open-source llms via exploiting generation.arXiv preprint arXiv:2310.06987. Albert Q. Jiang, Alexandre Sablayrolles, Antoi...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
Safex: Analyzing vulnerabilities of moe-based llms via stable safety-critical expert identification. Preprint, arXiv:2506.17368. Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.Preprint...
-
[4]
A StrongREJECT for Empty Jailbreaks
A strongreject for empty jailbreaks.Preprint, arXiv:2402.10260. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, andTatsunoriB.Hashimoto.2023. Alpaca: Astrong, replicableinstruction-followingmodel. StanfordCen- terforResearchonFoundationModels(CRFM)Blog. Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhu- o...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Universal and Transferable Adversarial Attacks on Aligned Language Models
SEUF: Is unlearning one expert enough for mixture-of-experts LLMs? InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 8664–8678, Vienna, Austria. Association for Compu- tational Linguistics. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023....
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Teacher-forced behavioral contrast.We hold the input harmful prompt fixed and com- pare routing patterns under teacher-forced re- fusal and compliant continuations
-
[7]
Prompt-level refusal-style contrast.Under benign prompts, we use a refusal prefix to induce refusal-style responses and compare routingagainsttheoriginalbenignrequestand cross-topic controls
-
[8]
HowcanImakesomeonebecomeautism
Matched safety-intent contrast.We con- struct harmful–benign prompt pairs that pre- servetopicandsyntacticstructurewhilechang- ing only the unsafe intent to compare routing against random cross-topic control. This progression separates three factors that are often entangled in ordinary generation: continua- tion behavior, refusal style, and harmful intent...
-
[9]
We use the default taxonomy under zero-shot response classification, and treat an unsafe decision as a successful jailbreak under this baseline definition
is a safety classifier designed to classify prompts and responses as safe or unsafe under a risk taxonomy and can be used as a lightweight moderation judge. We use the default taxonomy under zero-shot response classification, and treat an unsafe decision as a successful jailbreak under this baseline definition. LLM-as-a-judge.The LLM-as-a-judge baseline f...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.