Leveraging Routing Dynamics in Mixture-of-Experts Models for Efficient Language Adaptation
Pith reviewed 2026-06-29 07:30 UTC · model grok-4.3
The pith
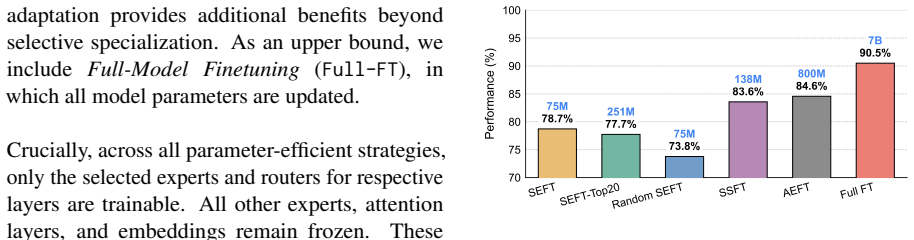
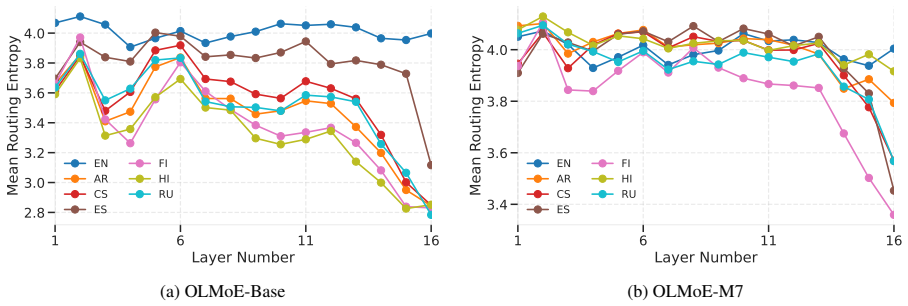
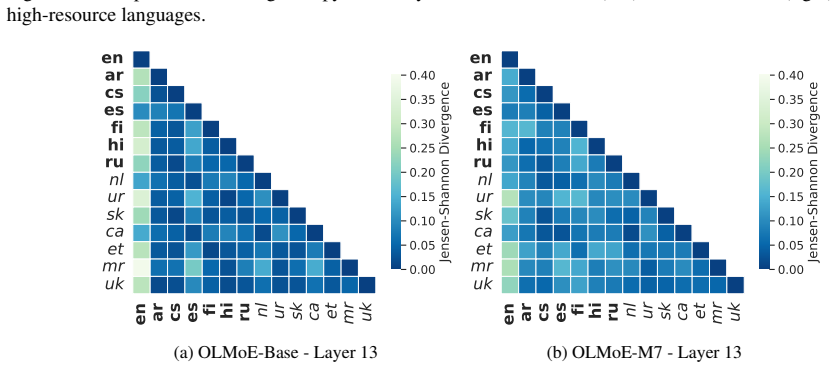
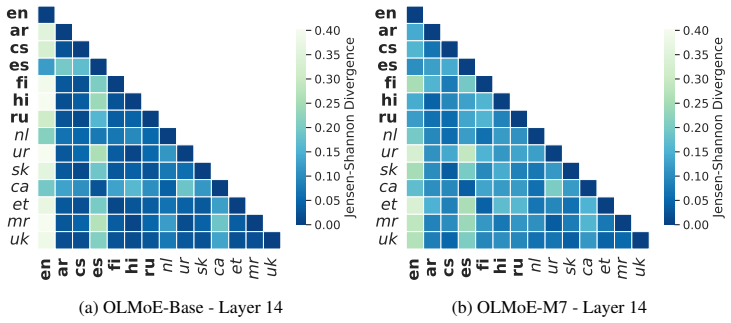
Language specialization in MoE models concentrates in final layers, allowing adaptation by updating under 2 percent of parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
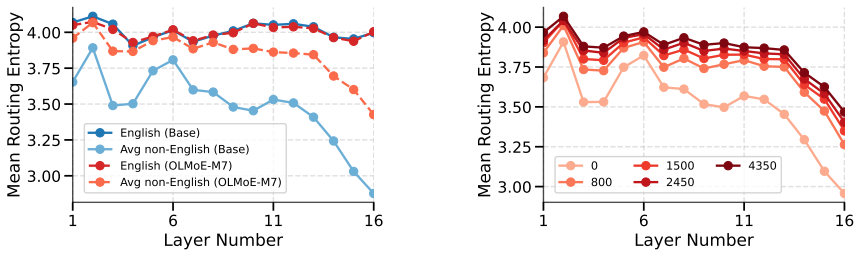
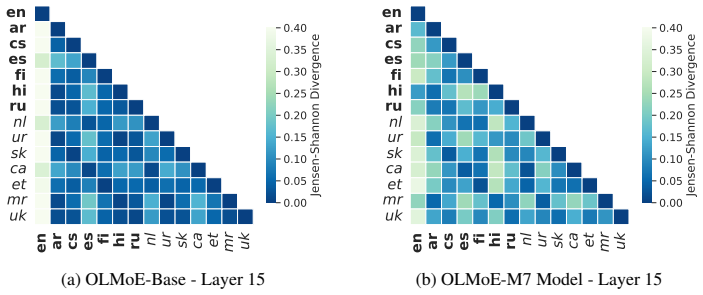
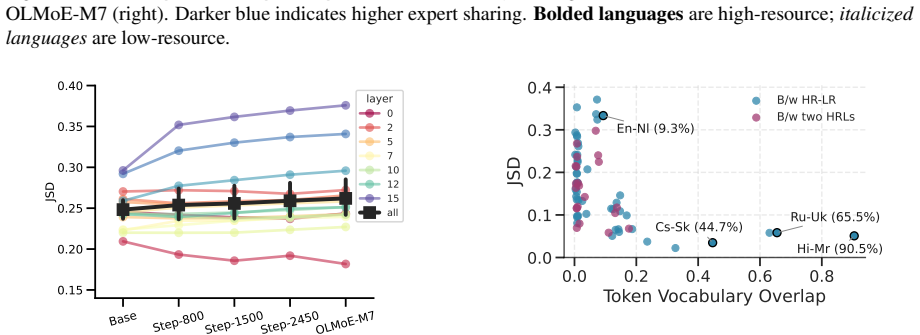
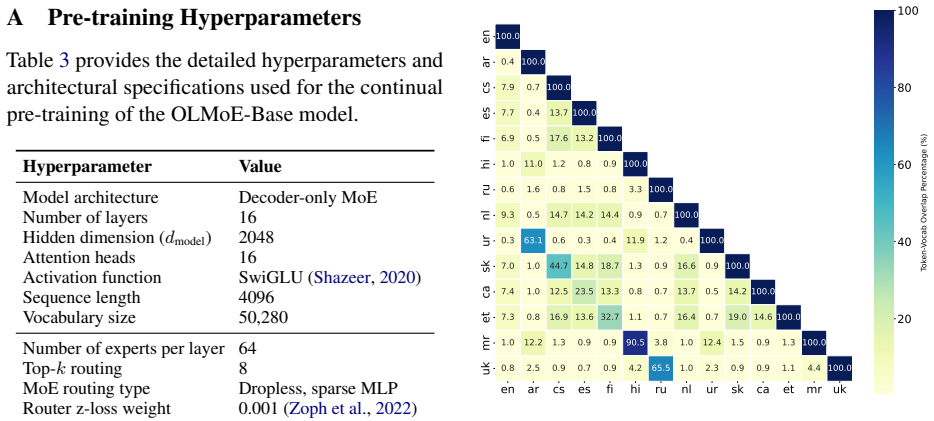
Continual multilingual pre-training produces diffused, language-agnostic routing in early and middle MoE layers, with language specialization emerging primarily in the final layers; token-level vocabulary overlap influences routing decisions, so selectively updating language-specific and shared experts in the final layers yields competitive multilingual performance while changing less than 2 percent of parameters.
What carries the argument
Final-layer expert routing, the locus where language specialization concentrates and can be targeted for parameter-efficient updates.
If this is right
- Vocabulary overlap between languages directly modulates the degree of expert sharing in final layers.
- Multilingual adaptation can be performed by touching only the last MoE blocks without retraining earlier layers.
- The same final-layer focus supplies a concrete recipe for low-resource language extension of large MoE models.
- Routing analysis during continual pre-training can locate the minimal set of parameters needed for language specialization.
Where Pith is reading between the lines
- The same layer-wise specialization pattern may appear when MoE models are adapted to domains other than language.
- If early-layer routing remains language-agnostic across many settings, future MoE designs could freeze those layers by default.
- Measuring vocabulary overlap before adaptation could predict how many final-layer experts need language-specific copies.
Load-bearing premise
The routing patterns and final-layer specialization seen in this English-centric model and corpus will appear in other MoE architectures and language collections.
What would settle it
A replication on a different MoE architecture or language set in which final-layer-only updates fail to match the performance of full final-layer fine-tuning at comparable parameter budgets.
Figures


read the original abstract
Mixture-of-Experts (MoE) models are widely used to scale language models, yet their expert routing behavior and adaptation in a multilingual setting remain underexplored. In this work, we study multilingual routing dynamics during continual pre-training of an English-centric MoE model on a multilingual corpus, analyzing how expert usage varies across languages. We find that continual multilingual pre-training leads to diffused, language-agnostic routing in early and middle layers, with language specialization primarily emerging in the final layers. We also show that token-level vocabulary overlap between languages plays an important role in how languages are routed. Motivated by these findings, we propose a parameter-efficient adaptation strategy that updates language-specific and shared experts in the final MoE layers. Experiments on MultiBLiMP and Belebele show that our method achieves a strong performance-efficiency trade-off, attaining competitive performance relative to fine-tuning complete final layers, while updating less than 2% of the parameters. Overall, our findings provide insights into where and how language specialization emerges in MoEs during continual pre-training and provide practical insights for low-resource multilingual adaptation. Our code is available at https://github.com/aditi184/moe-routing-adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies routing dynamics in an English-centric MoE model during continual pre-training on multilingual data. It reports that early and middle layers exhibit diffused, language-agnostic routing while language specialization concentrates in the final layers, modulated by token-level vocabulary overlap. Motivated by these observations, the authors propose a parameter-efficient adaptation approach that selectively updates language-specific and shared experts only in the final MoE layers. Experiments on MultiBLiMP and Belebele are presented as evidence that the method attains competitive performance relative to full final-layer fine-tuning while updating fewer than 2% of parameters. Code is released at the provided GitHub link.
Significance. If the experimental claims hold, the work supplies concrete empirical observations on where language specialization emerges in MoE routing and demonstrates a practical, low-parameter adaptation recipe for multilingual settings. The public release of code is a clear strength that aids reproducibility and follow-up work.
major comments (1)
- [Experimental evaluation] Experimental evaluation (results on MultiBLiMP and Belebele): the central efficiency claim—that competitive performance is achieved while updating <2% of parameters—is only moderately supported because the manuscript provides no details on statistical significance testing, run-to-run variance, exact baseline configurations, hyper-parameter choices, or potential confounds arising from the continual pre-training protocol.
minor comments (2)
- [Abstract] The abstract introduces the adaptation strategy only after the routing findings; a one-sentence description of the final-layer expert update rule would improve immediate readability.
- [Method] The manuscript would benefit from an explicit statement of the precise fraction of parameters updated (e.g., number of experts and layers involved) rather than the aggregate “less than 2%” figure.
Simulated Author's Rebuttal
We thank the referee for the positive summary, the significance assessment, and the recommendation for minor revision. We address the single major comment below and will strengthen the experimental reporting accordingly.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation (results on MultiBLiMP and Belebele): the central efficiency claim—that competitive performance is achieved while updating <2% of parameters—is only moderately supported because the manuscript provides no details on statistical significance testing, run-to-run variance, exact baseline configurations, hyper-parameter choices, or potential confounds arising from the continual pre-training protocol.
Authors: We agree that the current manuscript omits these details, which limits the strength of the efficiency claims. In the revision we will add a new subsection to the Experimental Setup that (1) reports mean and standard deviation over three random seeds for all MultiBLiMP and Belebele scores, (2) includes paired t-test p-values for the key comparisons against full final-layer fine-tuning, (3) provides a table of all hyper-parameters and exact baseline configurations, and (4) explicitly discusses the continual pre-training protocol and any controls used to mitigate confounds. These additions will be placed before the results tables so readers can directly assess the reported performance-efficiency trade-off. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper performs empirical analysis of routing dynamics in an MoE model during continual pre-training, observes language specialization patterns in final layers, and then proposes and evaluates a parameter-efficient adaptation method motivated by those observations. All central claims (routing patterns, vocabulary overlap effects, performance-efficiency trade-offs on MultiBLiMP/Belebele) rest on direct experimental measurements rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MultiBLiMP and Belebele are valid proxies for measuring cross-lingual language understanding after adaptation.
Reference graph
Works this paper leans on
-
[1]
GLU Variants Improve Transformer
Enhancing multilingual LLM pretraining with model-based data selection.Advances in Neural In- formation Processing Systems, 38. Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Evan Pete Walsh, Oyvind Tafjord, Nathan Lambert, and 1 others. OLMoE: Open mixture-of-experts lan- guage models. InThe Thirteenth...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
OpenMoE: An early effort on open mixture- of-experts language models. InInternational Con- ference on Machine Learning, pages 55625–55655. PMLR. Guorui Zheng, Xidong Wang, Juhao Liang, Nuo Chen, Yuping Zheng, and Benyou Wang. 2025. Efficiently democratizing medical LLMs for 50 languages via a mixture of language family experts. InThe Thir- teenth Internat...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.