User-Aware Active Knowledge Acquisition for Emotional Support Dialogue
Pith reviewed 2026-06-29 07:27 UTC · model grok-4.3
The pith
Emotional support dialogues improve when AI actively models uncertainty about user needs and selects responses to draw out clearer feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
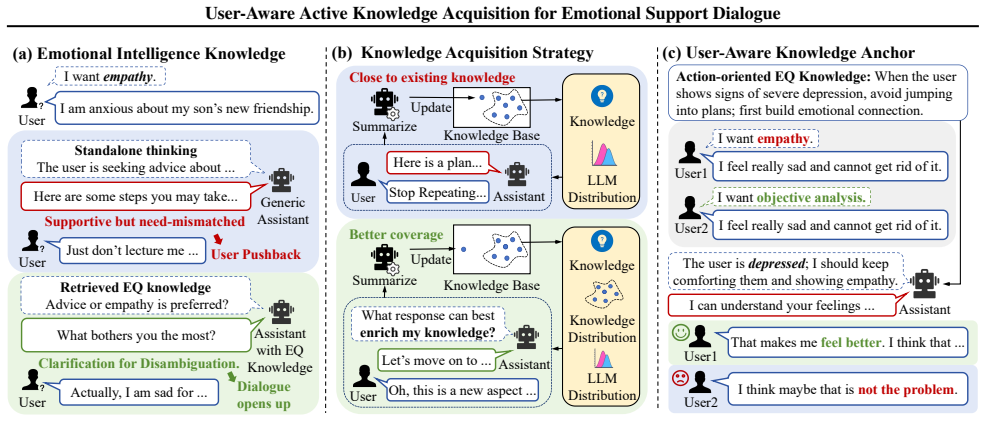
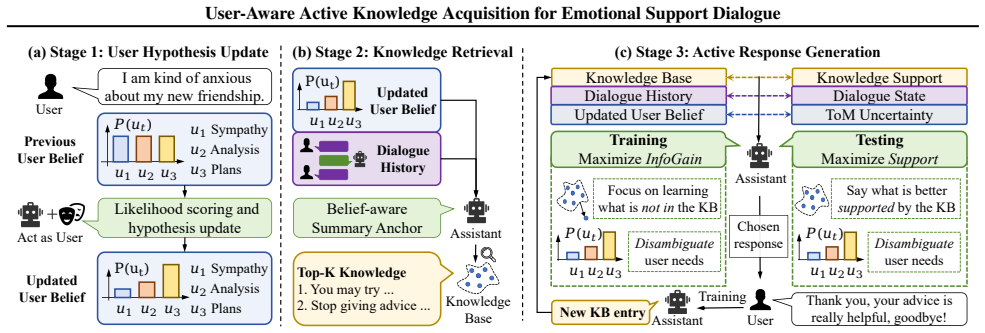
We introduce User-Aware Active Knowledge Acquisition (UKA), a gradient-free active dialogue learning framework that explicitly represents uncertainty about user needs and incorporates active learning into both knowledge acquisition and response selection. We propose a Theory-of-Mind uncertainty estimation mechanism that allows the model to prioritize responses, thereby eliciting more informative user feedback. UKA is capable of efficiently exploring user-aligned conversational knowledge during training while maintaining robustness at test time.
What carries the argument
User-Aware Active Knowledge Acquisition (UKA) framework, which uses a Theory-of-Mind uncertainty estimation mechanism to guide active learning in knowledge acquisition and response selection.
If this is right
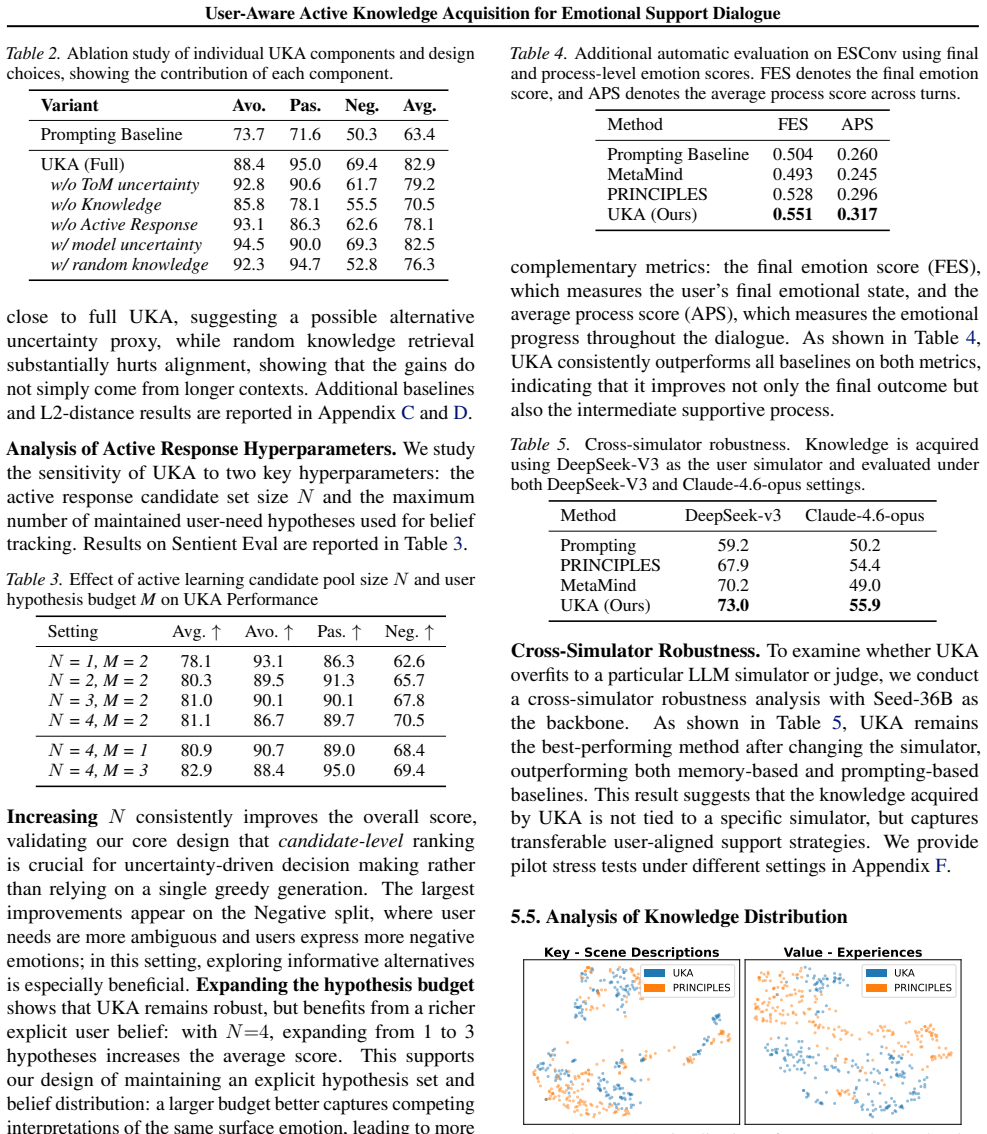
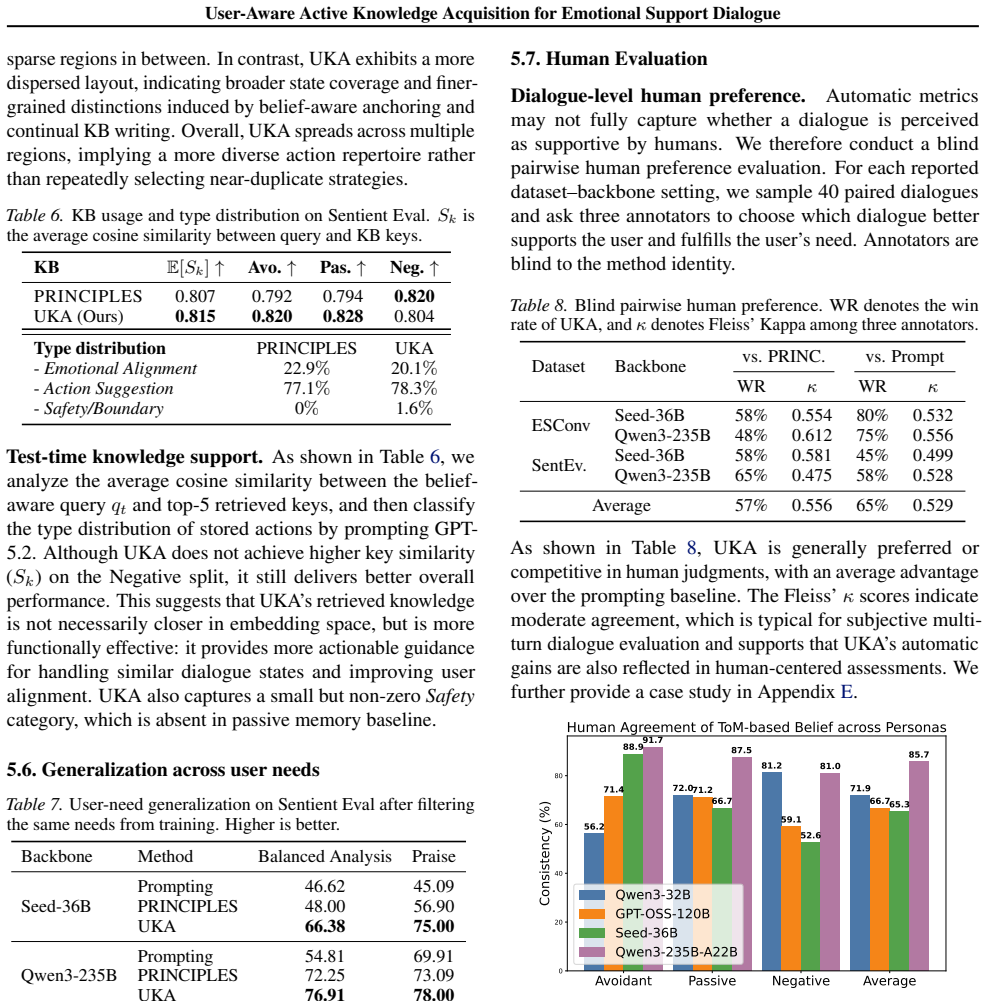
- The method outperforms strong baselines in dialogue quality and user alignment across multiple benchmarks.
- It explores user-aligned knowledge efficiently during training.
- It maintains robustness when applied at test time.
- It works across different model architectures.
- It better handles evolving and implicit user needs in multi-turn emotional support conversations.
Where Pith is reading between the lines
- The same active uncertainty approach could be tested in other conversational settings where intent is implicit, such as tutoring or health advice.
- It may allow conversational models to reach useful alignment with less static training data.
- Real-user deployment studies could check whether the estimated uncertainty matches actual user experiences over time.
Load-bearing premise
Signals about user needs are weak and indirect and can be clarified only through multi-turn interaction, with the uncertainty mechanism able to choose responses that reliably produce more informative feedback.
What would settle it
A controlled comparison in which responses chosen by the Theory-of-Mind uncertainty mechanism receive no more informative user replies than baseline selection methods, or in which UKA shows no consistent gains over strong baselines on dialogue quality and alignment metrics.
Figures
read the original abstract
Emotional support plays an important role in dialogue systems, and its success depends on adapting to a user's evolving and implicit needs across multi-turn interactions while leveraging the strong reasoning capacity of large language models. However, since signals about user needs are often weak, indirect, and can only be disambiguated through multi-turn interaction, existing emotional support methods often struggle to acquire and generalize relevant conversational knowledge efficiently. To bridge this gap, we introduce User-Aware Active Knowledge Acquisition (UKA), a gradient-free active dialogue learning framework that explicitly represents uncertainty about user needs and incorporates active learning into both knowledge acquisition and response selection.We propose a Theory-of-Mind uncertainty estimation mechanism that allows the model to prioritize responses, thereby eliciting more informative user feedback. UKA is capable of efficiently exploring user-aligned conversational knowledge during training while maintaining robustness at test time. Experiments across multiple dialogue benchmarks and model architectures demonstrate that our approach consistently outperforms strong baselines in dialogue quality and user alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces User-Aware Active Knowledge Acquisition (UKA), a gradient-free active dialogue learning framework for emotional support dialogues. It explicitly represents uncertainty about user needs via a Theory-of-Mind mechanism that prioritizes responses to elicit informative feedback, enabling efficient exploration of user-aligned knowledge during training while remaining robust at test time. The central empirical claim is that UKA consistently outperforms strong baselines in dialogue quality and user alignment across multiple dialogue benchmarks and model architectures.
Significance. If the outperformance claims hold under standard benchmark comparisons, the work could advance active learning methods for handling weak, indirect user signals in multi-turn emotional support dialogues by integrating uncertainty estimation with response selection, offering a practical way to improve adaptation without gradient-based updates.
major comments (1)
- [Abstract] Abstract: the claim of 'consistent outperformance' on dialogue quality and user alignment is presented without any experimental details, baselines, metrics, result tables, or statistical analysis, preventing assessment of whether the data supports the central claim.
Simulated Author's Rebuttal
We thank the referee for their feedback. Below we address the single major comment point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance' on dialogue quality and user alignment is presented without any experimental details, baselines, metrics, result tables, or statistical analysis, preventing assessment of whether the data supports the central claim.
Authors: Abstracts are conventionally limited to a concise overview of the contribution and high-level findings to allow readers to quickly assess relevance. The experimental details—including the specific baselines compared, evaluation metrics for dialogue quality and user alignment, full result tables, and any statistical significance tests—are provided in the Experiments section of the manuscript (with additional analysis in the appendix). This structure follows standard practice in the field. We do not believe the abstract requires expansion with these details, as doing so would violate length constraints and reduce readability. revision: no
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical active-learning framework (UKA) for emotional support dialogues and validates it via benchmark experiments showing outperformance. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises appear in the abstract or described approach. The central claim rests on standard empirical comparisons, which are externally falsifiable and independent of any internal self-definition or renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Findings of the Association for Computational Lin- guistics: EMNLP 2025
URL https://aclanthology.org/2024. findings-emnlp.529/. Cheng, M., Luo, Y ., Ouyang, J., Liu, Q., Liu, H., Li, L., Yu, S., Zhang, B., Cao, J., Ma, J., and Wang, D. A survey on knowledge-oriented retrieval-augmented generation, 2025a. URL https://arxiv.org/ abs/2503.10677. Cheng, Y ., Mao, K., Zhao, Z., Dong, G., Qian, H., Wu, Y ., Sakai, T., Wen, J.-R., a...
-
[2]
emnlp-industry.108/
URL https://aclanthology.org/2024. emnlp-industry.108/. Choi, Y ., Li, C., Yang, Y ., and Jin, Z. Agent-to-agent theory of mind: Testing interlocutor awareness among large lan- guage models. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp....
2024
-
[3]
Mitigating catastrophic forgetting in large language models with forgetting-aware pruning
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[4]
URL https://aclanthology.org/2025. emnlp-main.1471/. Cross, L., Xiang, V ., Bhatia, A., Yamins, D., and Haber, N. Hypothetical minds: Scaffolding theory of mind for multi- agent tasks with large language models. InInternational Conference on Learning Representations, volume 2025, pp. 6507–6546, 2025. URL https://openreview. net/forum?id=otW0TJOUYF. Cruz B...
-
[5]
Retrieval-Augmented Generation for Large Language Models: A Survey
URL https://aclanthology.org/2024. acl-long.73.pdf. Dong, H., Xiong, W., Pang, B., Wang, H., Zhao, H., Zhou, Y ., Jiang, N., Sahoo, D., Xiong, C., and Zhang, T. RLHF workflow: From reward modeling to online RLHF: A comprehensive practical alignment recipe of iterative preference learning.Transactions on Machine Learning Research, 2024. URL https://openrev...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.naacl-long 2024
-
[6]
LLM-blender: Ensembling large language models with pairwise ranking and generative fusion
URL https://aclanthology.org/2025. naacl-long.499/. Huang, Q., Fu, S., Liu, X., Wang, W., Ko, T., Zhang, Y ., and Tang, L. Learning retrieval augmentation for personalized dialogue generation. In Bouamor, H., Pino, J., and Bali, K. (eds.),Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 2523–2540, Singapore, Dece...
-
[7]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al
URL https://dl.acm.org/doi/10.5555/ 188490.188495. Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024. URLhttps://arxiv.org/abs/2412.19437. Liu, B., Yu, T., Lane, I., and Mengshoel, O. Customized nonlinear bandits for online response selec...
-
[8]
php/AAAI/article/view/12028/11887
URL https://ojs.aaai.org/index. php/AAAI/article/view/12028/11887. Liu, S., Zheng, C., Demasi, O., Sabour, S., Li, Y ., Yu, Z., Jiang, Y ., and Huang, M. Towards emotional support dialog systems. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Process...
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://aclanthology.org/2024. findings-emnlp.622/. Seed, B. Seed-OSS open-source models. https: //github.com/ByteDance-Seed/seed-oss, 2025. Settles, B. Active learning literature survey. Technical Report 1648, University of Wisconsin–Madison, De- partment of Computer Sciences, 2009. URL http: //digital.library.wisc.edu/1793/60660. Shao, Z., Wang, P.,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
URL https://aclanthology.org/2025. findings-acl.839/. Team, Q. Qwen3 technical report, 2025. URL https: //arxiv.org/abs/2505.09388. Vera, H. S., Dua, S., Zhang, B., Salz, D., Mullins, R., Panyam, S. R., Smoot, S., Naim, I., Zou, J., Chen, F., et al. EmbeddingGemma: Powerful and lightweight text representations.arXiv preprint arXiv:2509.20354, 2025. URLhtt...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
acl-long.844.pdf
URL https://aclanthology.org/2024. acl-long.844.pdf. Wu, D., Wang, H., Yu, W., Zhang, Y ., Chang, K., and Yu, D. LongMemEval: Benchmarking chat assistants on long-term interactive memory. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24- 28, 2025. OpenReview.net, 2025. URL https:// openreview.net/forum...
2024
-
[13]
InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
URL https://aclanthology.org/2025. findings-acl.1234.pdf. Yan, Y ., Jiang, L., Jiang, J., Li, S., Wen, Z., Zhang, Z., Zhou, J., Shao, J., Zhuang, Y ., and Shen, Y . InftyThink+: Effective and efficient infinite-horizon reasoning via reinforcement learning.arXiv preprint arXiv:2602.06960, 2026. URL https://arxiv. org/pdf/2602.06960. Yang, B., Guo, J., Iwas...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-emnlp 2025
-
[14]
URL https://aclanthology.org/2024. findings-emnlp.678/. Yue, Y . and Joachims, T. Interactively optimizing infor- mation retrieval systems as a dueling bandits problem. InProceedings of the 26th International Conference on Machine Learning (ICML), pp. 1201–1208, 2009. doi: 10.1145/1553374.1553527. URL https://dl.acm. org/doi/10.1145/1553374.1553527. Zhang...
-
[15]
I don’t really want to talk about it. It’s fine
URL https://proceedings.mlr.press/ v235/zhu24o.html. 13 User-Aware Active Knowledge Acquisition for Emotional Support Dialogue A. Implementation Details A.1. Benchmarks ESConv.ESConv is a crowd-sourced multi-turn Emotional Support Conversation (ESC) dataset, where aseekerdescribes distressing situations and asupporterresponds with supportive utterances. T...
2021
-
[16]
Potential Player Responses Based on Emotional State - **High Emotional Stability (Calm, Relaxed):**
-
[17]
Wang Xiaoyun’s Reactions to NPC Responses - **NPC Responses Aligned with the Hidden Theme (Emotion Increases):** If the NPC provides insights into possible reasons for Zhang Hao’s behavior—perhaps analyzing misinterpretations or underlying circum- stances—Wang Xiaoyun may feel a sense of relief, finding their observations enlightening or validating. - **N...
-
[18]
Which parts align with the character’s conversation goal and hidden goal? Which parts may not align, or may even trigger emotional fluctuations in the character?
Based on the NPC’s latest reply and the context, analyze what the NPC is trying to express. Which parts align with the character’s conversation goal and hidden goal? Which parts may not align, or may even trigger emotional fluctuations in the character?
-
[19]
If it does, specify exactly which parts of the character’s goals it matches; if it does not, specify the concrete reasons
Based on what the NPC expresses, analyze whether the NPC’s reply matches the character’s conversation goal and hidden goal. If it does, specify exactly which parts of the character’s goals it matches; if it does not, specify the concrete reasons
-
[20]
Based on the character’s personality traits in the profile and the possible reactions and hidden theme defined in the conversation background, combined with the character’s current emotion value, profile and describe the character’s current psychological activity in response to the NPC’s reply
-
[21]
Based on the possible reactions and hidden theme defined in the conversation background, combined with the profiled psychological activity and the analysis of the NPC’s reply, derive the character’s feelings toward the NPC’s reply at this moment
-
[22]
#Output:
Based on the previous steps, use a positive/negative value to represent the change in the character’s emotion. #Output:
-
[23]
What the NPC is trying to express
-
[24]
Whether the NPC’s reply matches the character’s conversation goal and hidden goal
-
[25]
The character’s current psychological activity
-
[26]
The character’s feelings toward the NPC’s reply
-
[27]
LOL”, “wow
A positive/negative value representing the change in the character’s emotion (Note: output the value only; do not output reasons or descriptions) #Output format: Content: [NPC’s intended message] TargetCompletion: [Whether the character’s conversation goal is achieved] Activity: [Psychological activity] Analyse: [The character’s feelings toward the NPC’s ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.