Improving CLIP Adaptation by Breaking Tail Alignment for Source-Free Cross-Domain Few-Shot Learning
Pith reviewed 2026-06-29 08:14 UTC · model grok-4.3
The pith
Pushing low-similarity image tokens away from text embeddings improves CLIP adaptation under domain shift and few shots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
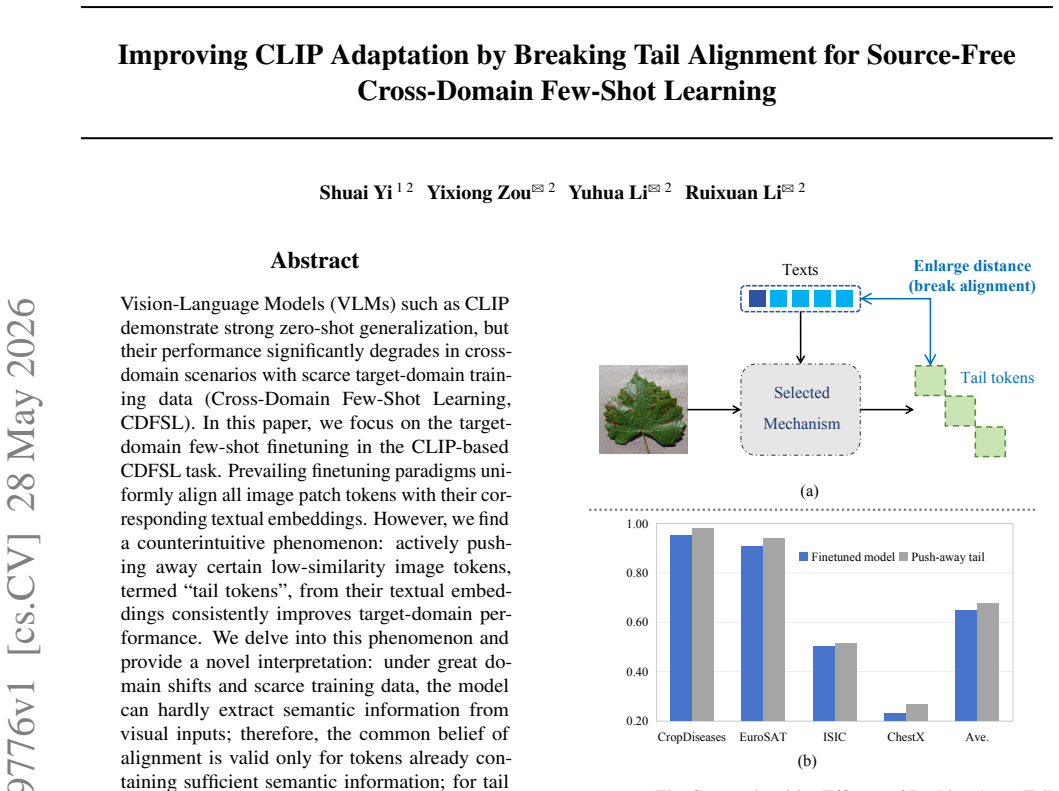
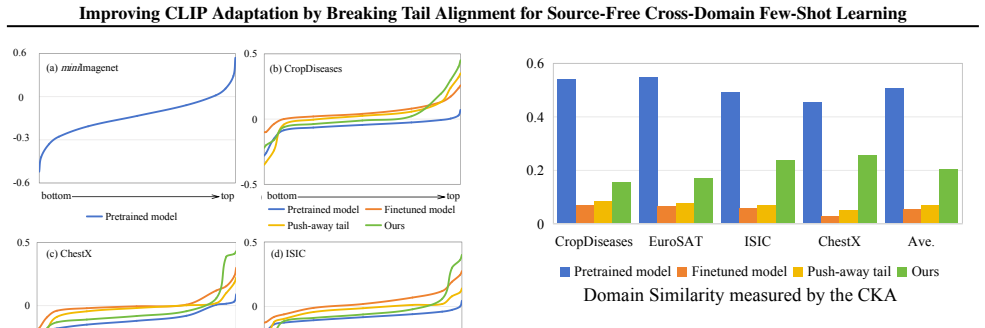
Under large domain shifts and scarce target data the model cannot extract reliable semantics from most visual tokens, so the usual alignment objective is beneficial only for tokens that already carry sufficient information. For the remaining tail tokens, enforcing alignment produces excessive overfitting to the few available examples; deliberately breaking the alignment for those tokens while preserving or strengthening it for the rest yields better target-domain generalization.
What carries the argument
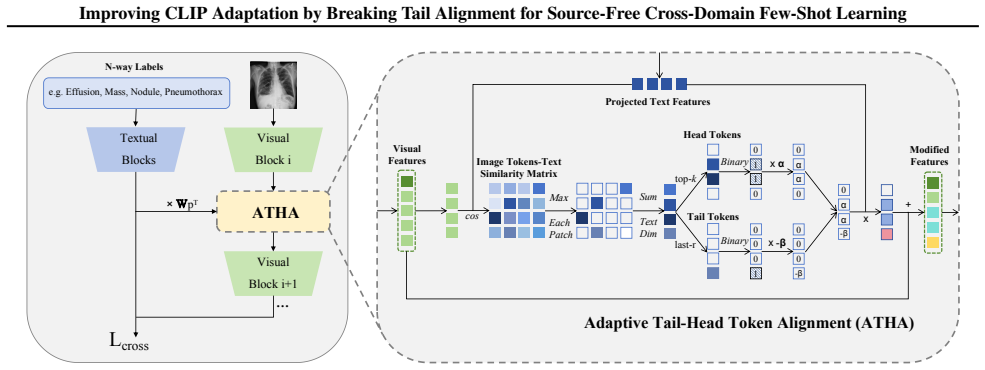
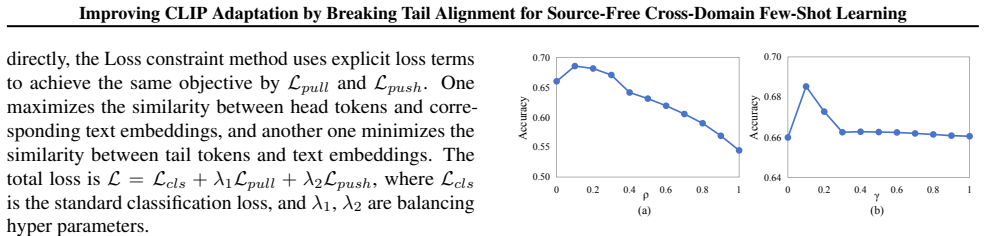
Adaptive Tail-Head Alignment (ATHA), a finetuning rule that first ranks image tokens by similarity to the corresponding text embedding and then applies alignment strengthening to head tokens and alignment weakening to tail tokens.
If this is right
- Target-domain accuracy rises relative to uniform-alignment baselines on standard CDFSL benchmarks.
- Overfitting to the scarce labeled samples is reduced by avoiding forced alignment on uninformative tokens.
- The performance gap between head and tail tokens becomes a practical signal for deciding which alignments to enforce.
- The same adaptive rule can be applied during both the few-shot finetuning stage and any subsequent inference.
Where Pith is reading between the lines
- The same selective-breaking idea could be tested on other vision-language models that rely on patch-to-text alignment.
- One could measure whether the head-tail distinction remains stable when the number of shots or the magnitude of domain shift is varied systematically.
- The approach might extend to other multimodal losses where uniform alignment is currently assumed to be optimal.
Load-bearing premise
When domain shift is large and training examples are few, most image tokens carry too little semantic information for alignment to be useful.
What would settle it
Measure whether target accuracy drops or stays flat when the weakening step for tail tokens is removed on the same four CDFSL benchmarks with identical few-shot splits.
Figures
read the original abstract
Vision-Language Models (VLMs) such as CLIP demonstrate strong zero-shot generalization, but their performance significantly degrades in cross-domain scenarios with scarce target-domain training data (Cross-Domain Few-Shot Learning, CDFSL). In this paper, we focus on the target-domain few-shot finetuning in the CLIP-based CDFSL task. Prevailing finetuning paradigms uniformly align all image patch tokens with their corresponding textual embeddings. However, we find a counterintuitive phenomenon: actively pushing away certain low-similarity image tokens, termed "tail tokens", from their textual embeddings consistently improves target-domain performance. We delve into this phenomenon and provide a novel interpretation: under great domain shifts and scarce training data, the model can hardly extract semantic information from visual inputs; therefore, the common belief of alignment is valid only for tokens already containing sufficient semantic information; for tail tokens, forcing the alignment would lead to excessive overfitting to the scarce training, while breaking the alignment is more useful. Motivated by this, we propose Adaptive Tail-Head Alignment (ATHA), a novel fine-tuning strategy for CLIP that transforms the conventional uniform alignment paradigm to an adaptive alignment paradigm, with both alignment strengthening and weakening. Extensive experiments on four challenging CDFSL benchmarks validate our state-of-the-art performance. Our code is available at https://github.com/shuaiyi308/ATHA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes that uniform alignment of all image patch tokens to textual embeddings during CLIP fine-tuning for source-free cross-domain few-shot learning (CDFSL) can degrade target performance. It identifies low-similarity 'tail tokens' and claims that actively pushing them away from text embeddings (while strengthening alignment for others) mitigates overfitting to scarce target data under domain shift. Motivated by this, it proposes Adaptive Tail-Head Alignment (ATHA) and reports state-of-the-art results on four CDFSL benchmarks.
Significance. If the empirical gains hold and the semantic rationale for selective misalignment is supported, the work challenges the prevailing uniform-alignment paradigm in VLM adaptation and offers a practical, adaptive strategy for low-data domain transfer. The availability of code strengthens reproducibility.
major comments (1)
- [Abstract] Abstract: the central claim that tail tokens 'lack sufficient semantic information' (so that alignment overfits) while high-similarity tokens do not rests on an untested partition. Similarity is computed from the source-adapted or frozen CLIP space; under large domain shift this may reflect domain-specific appearance rather than target semantics, yet no direct validation (e.g., human inspection, downstream semantic probes, or controlled ablation of the similarity threshold) is described to confirm the partition is semantically meaningful rather than spurious.
minor comments (1)
- The abstract states 'extensive experiments on four challenging CDFSL benchmarks' but provides no quantitative details, ablation tables, or statistical significance tests; these should be expanded in the main text with clear baselines and variance reporting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify our work. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that tail tokens 'lack sufficient semantic information' (so that alignment overfits) while high-similarity tokens do not rests on an untested partition. Similarity is computed from the source-adapted or frozen CLIP space; under large domain shift this may reflect domain-specific appearance rather than target semantics, yet no direct validation (e.g., human inspection, downstream semantic probes, or controlled ablation of the similarity threshold) is described to confirm the partition is semantically meaningful rather than spurious.
Authors: We acknowledge that the manuscript does not include direct human inspection or downstream semantic probes to validate that the low-similarity partition corresponds to semantically meaningless tokens rather than domain artifacts. The similarity computation occurs in the CLIP space (pre-trained for cross-modal semantics), and our ablations demonstrate consistent target-domain gains from selectively weakening alignment on tail tokens across four benchmarks; this empirical pattern supports the practical utility of the adaptive strategy even if the semantic interpretation is indirect. In revision we will add (i) visualizations of representative tail tokens and (ii) a controlled sensitivity study on the similarity threshold to provide stronger evidence for the partition. revision: partial
Circularity Check
No circularity: empirical observation and method validated externally
full rationale
The paper reports an empirical finding that selectively breaking alignment for low-similarity tail tokens improves target performance, then proposes the ATHA fine-tuning strategy motivated by that observation. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or result to the inputs by construction. The central claims rest on experiments across four CDFSL benchmarks, which constitute independent external validation rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A., Minderer, M., Blun- dell, C., Pascanu, R., et al
Bica, I., Ili ´c, A., Bauer, M., Erdogan, G., Bo ˇsnjak, M., Kaplanis, C., Gritsenko, A. A., Minderer, M., Blun- dell, C., Pascanu, R., et al. Improving fine-grained un- derstanding in image-text pre-training.arXiv preprint arXiv:2401.09865,
-
[2]
Contrastive localized language-image pre-training.arXiv preprint arXiv:2410.02746,
Chen, H.-Y ., Lai, Z., Zhang, H., Wang, X., Eichner, M., You, K., Cao, M., Zhang, B., Yang, Y ., and Gan, Z. Contrastive localized language-image pre-training.arXiv preprint arXiv:2410.02746,
-
[3]
E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., Kittler, H., and Halpern, A
Codella, N., Rotemberg, V ., Tschandl, P., Celebi, M. E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., Kittler, H., and Halpern, A. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic),
2018
-
[4]
Ma, R., Zou, Y ., Li, Y ., and Li, R. Reconstruction target matters in masked image modeling for cross-domain few- shot learning.arXiv preprint arXiv:2412.19101,
-
[5]
ISSN 1664-462X. doi: 10.3389/fpls.2016.01419. Publisher Copyright: © 2016 Mohanty, Hughes and Salath´e. Mukhoti, J., Lin, T.-Y ., Poursaeed, O., Wang, R., Shah, A., Torr, P. H., and Lim, S.-N. Open vocabulary semantic segmentation with patch aligned contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,...
-
[6]
URL http://dx.doi.org/ 10.1109/CVPR.2017.369
doi: 10.1109/cvpr.2017.369. URL http://dx.doi.org/ 10.1109/CVPR.2017.369. Xu, H., Liu, L., Liu, T., Zhi, S., Sun, S., and Cheng, M.- M. Step-wise distribution alignment guided style prompt tuning for source-free cross-domain few-shot learning. arXiv preprint arXiv:2411.10070, 2024a. Xu, H., Liu, L., Zhi, S., Fu, S., Su, Z., Cheng, M.-M., and Liu, Y . Enha...
-
[7]
Random registers for cross-domain few-shot learning.arXiv preprint arXiv:2506.02843, 2025
Yi, S., Zou, Y ., Li, Y ., and Li, R. Random registers for cross-domain few-shot learning.arXiv preprint arXiv:2506.02843, 2025a. Yi, S., Zou, Y ., Li, Y ., and Li, R. Revisiting continuity of image tokens for cross-domain few-shot learning.arXiv preprint arXiv:2506.03110, 2025b. Yi, S., Zou, Y ., Li, Y ., and Li, R. Addressing exacerbated at- tention sin...
-
[8]
Clip in medical imaging: A comprehensive sur- vey.arXiv preprint arXiv:2312.07353, 2023
Zhao, Z., Liu, Y ., Wu, H., Wang, M., Li, Y ., Wang, S., Teng, L., Liu, D., Cui, Z., Wang, Q., et al. Clip in med- ical imaging: A comprehensive survey.arXiv preprint arXiv:2312.07353,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.