Not All Inputs Are Valid: Towards Open-Set Video Moment Retrieval Using Language
Pith reviewed 2026-06-29 08:05 UTC · model grok-4.3
The pith
OpenVMR is the first model to reject out-of-distribution queries in video moment retrieval before performing any retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
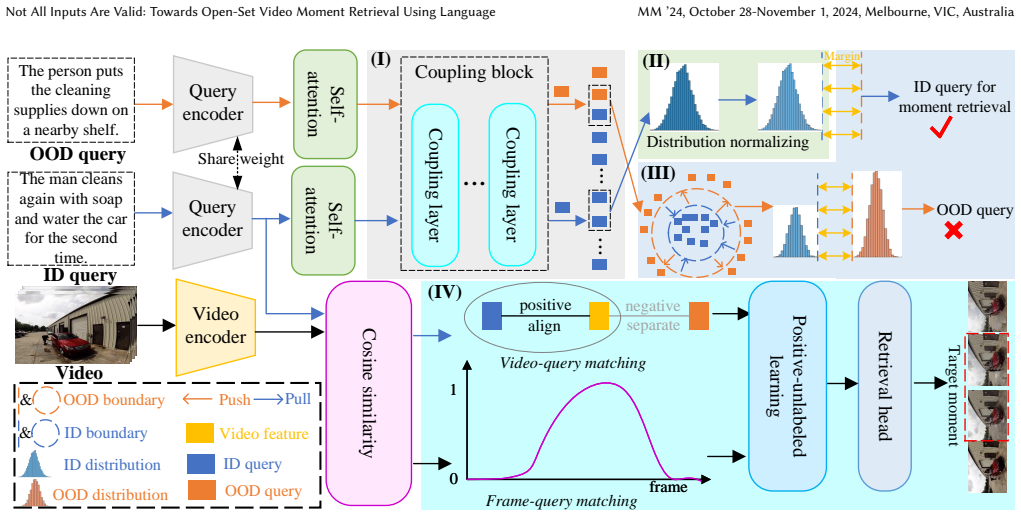
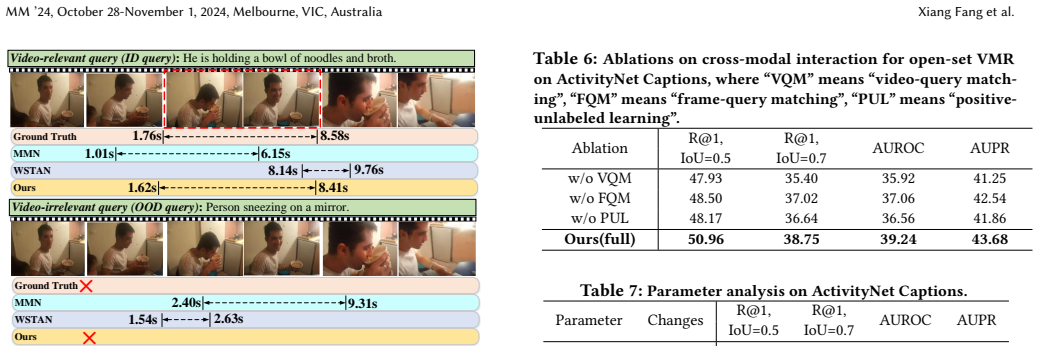
OpenVMR first distinguishes ID and OOD queries based on the normalizing flow technology, and then conducts moment retrieval based on ID queries. It learns the ID distribution by constructing a normalizing flow and assumes the ID query distribution obeys the multi-variate Gaussian distribution. An uncertainty score is introduced to search the ID-OOD separating boundary, which is refined by pulling together ID query features. Video-query matching and frame-query matching handle coarse-grained and fine-grained cross-modal interaction, and a positive-unlabeled learning module performs the final moment retrieval.
What carries the argument
Normalizing flow that models the distribution of video-relevant queries and supplies an uncertainty score used to set the ID-OOD decision boundary.
If this is right
- Moment retrieval occurs only after a query passes the ID-OOD test, preventing retrieval on irrelevant inputs.
- The uncertainty score derived from the flow supplies an explicit, tunable criterion for accepting or rejecting a query.
- Boundary refinement by pulling ID features closer together improves separation before retrieval begins.
- Separate coarse video-query and fine frame-query matching stages allow retrieval to use both global and local alignment signals.
- Positive-unlabeled learning enables moment localization when only positive pairs are labeled.
Where Pith is reading between the lines
- The same normalizing-flow rejection step could be inserted into other vision-language retrieval pipelines that currently assume every query is valid.
- Evaluating the uncertainty score against queries that are only partially irrelevant would test whether the boundary remains stable under graded relevance.
- Replacing the Gaussian assumption with a more flexible density estimator might extend the method to query distributions that deviate from normality.
Load-bearing premise
The distribution of video-relevant queries follows a multivariate Gaussian that a normalizing flow can capture well enough for its uncertainty score to mark a reliable boundary between relevant and irrelevant queries.
What would settle it
A test set of queries in which uncertainty scores for video-relevant and video-irrelevant queries overlap so heavily that no single threshold cleanly separates the two classes.
Figures


read the original abstract
Video Moment Retrieval (VMR) targets to retrieve the specific moment corresponding to a sentence query from an untrimmed video. Although recent works have made remarkable progress in this task, they implicitly are rooted in the closed-set assumption that all the given queries as video-relevant\footnote{In this paper, we treat ``video-relevant query'' as ``in-distribution (ID) query'' and ``video-irrelevant query'' as ``out-of-distribution (OOD) query''.}. Given an OOD query in open-set scenarios, they still utilize it for wrong retrieval, which might lead to irrecoverable losses in high-risk scenarios, \textit{e.g.}, criminal activity detection. To this end, we creatively explore a brand-new VMR setting termed Open-Set Video Moment Retrieval (OS-VMR), where we should not only retrieve the precise moments based on ID query, but also reject OOD queries. In this paper, we make the first attempt to step toward OS-VMR and propose a novel model \textbf{OpenVMR}, which first distinguishes ID and OOD queries based on the normalizing flow technology, and then conducts moment retrieval based on ID queries. Specifically, we first learn the ID distribution by constructing a normalizing flow, and assume the ID query distribution obeys the multi-variate Gaussian distribution. Then, we introduce an uncertainty score to search the ID-OOD separating boundary. After that, we refine the ID-OOD boundary by pulling together ID query features. Besides, video-query matching and frame-query matching are designed for coarse-grained and fine-grained cross-modal interaction, respectively. Finally, a positive-unlabeled learning module is introduced for moment retrieval. Experimental results on three VMR datasets show the effectiveness of our OpenVMR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Open-Set Video Moment Retrieval (OS-VMR) task, extending standard VMR to require both accurate moment retrieval for in-distribution (ID) queries and explicit rejection of out-of-distribution (OOD) queries. It proposes the OpenVMR model, which first fits a normalizing flow to ID query features under an explicit multivariate Gaussian assumption, derives an uncertainty score to locate an ID-OOD decision boundary (subsequently refined by pulling ID features together), performs coarse- and fine-grained cross-modal matching, and applies positive-unlabeled learning for retrieval. The authors position this as the first work on OS-VMR and state that experiments on three VMR datasets demonstrate its effectiveness.
Significance. If the normalizing-flow separation and subsequent retrieval pipeline prove reliable, the work would address a practically important limitation of existing closed-set VMR systems in safety-critical domains. The task definition itself is a clear contribution; however, the significance is currently limited by the absence of any reported quantitative evidence that the Gaussian assumption and uncertainty boundary yield stable OOD rejection.
major comments (2)
- [Abstract] Abstract: the central OS-VMR claim rests on the statement that 'the ID query distribution obeys the multi-variate Gaussian distribution' together with an uncertainty score that 'search[es] the ID-OOD separating boundary.' No derivation, comparison to alternative base distributions, or empirical validation of this modeling choice is supplied, yet the entire ID/OOD distinction (and therefore the safety guarantee) depends on it.
- [Abstract] Abstract: the manuscript asserts that 'Experimental results on three VMR datasets show the effectiveness of our OpenVMR' but supplies neither metrics, baselines, ablations, nor error analysis. Without these data it is impossible to determine whether the normalizing-flow component actually improves OOD rejection or whether the positive-unlabeled retrieval module preserves performance on ID queries.
minor comments (1)
- [Abstract] The footnote equating 'video-relevant query' with ID and 'video-irrelevant query' with OOD is helpful; repeating the ID/OOD terminology consistently in the main text would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work introducing the Open-Set Video Moment Retrieval task and the OpenVMR model. We address each major comment below and commit to revisions that strengthen the justification of modeling choices and the clarity of experimental evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central OS-VMR claim rests on the statement that 'the ID query distribution obeys the multi-variate Gaussian distribution' together with an uncertainty score that 'search[es] the ID-OOD separating boundary.' No derivation, comparison to alternative base distributions, or empirical validation of this modeling choice is supplied, yet the entire ID/OOD distinction (and therefore the safety guarantee) depends on it.
Authors: We agree that the manuscript would be strengthened by explicit justification for the multivariate Gaussian base distribution. Normalizing flows standardly employ a Gaussian base for tractability and to enable exact likelihood computation; our uncertainty score is derived from the resulting density under this assumption. We will add a dedicated paragraph in the method section providing the rationale, include an ablation comparing Gaussian to alternatives such as a Laplace base distribution, and report empirical validation (e.g., Q-Q plots or Kolmogorov-Smirnov tests on ID query features) to demonstrate the modeling choice's suitability. revision: yes
-
Referee: [Abstract] Abstract: the manuscript asserts that 'Experimental results on three VMR datasets show the effectiveness of our OpenVMR' but supplies neither metrics, baselines, ablations, nor error analysis. Without these data it is impossible to determine whether the normalizing-flow component actually improves OOD rejection or whether the positive-unlabeled retrieval module preserves performance on ID queries.
Authors: The full manuscript contains an Experiments section reporting results across three VMR datasets with baseline comparisons and ablations. However, we acknowledge the referee's point that the abstract and the specific analysis of the normalizing-flow component's contribution to OOD rejection could be more explicit. We will revise the abstract to include key quantitative metrics (e.g., OOD rejection AUC and ID mIoU) and add a new subsection with targeted ablations isolating the flow-based detector and the positive-unlabeled module to directly address concerns about their individual contributions. revision: yes
Circularity Check
No circularity: standard normalizing flow and PU learning applied to new task
full rationale
The derivation applies established normalizing flow density estimation (with explicit multivariate Gaussian base distribution) to model ID queries, derives an uncertainty score for boundary search, refines via feature pulling, and uses positive-unlabeled learning for retrieval. None of these steps reduce by construction to the paper's own fitted parameters or self-citations; the components are independent external techniques applied to the OS-VMR setting. The approach is self-contained with no load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- uncertainty score boundary
axioms (1)
- domain assumption ID query distribution obeys the multi-variate Gaussian distribution
Reference graph
Works this paper leans on
-
[1]
Jessa Bekker and Jesse Davis. 2020. Learning from positive and unlabeled data: A survey.Machine Learning109, 4 (2020), 719–760
2020
-
[2]
Fuyao Cai, Daizong Liu, Xiang Fang, Jixiang Yu, Keke Tang, and Pan Zhou. 2025. Imperceptible Beam-Sensitive Adversarial Attacks for LiDAR-based Object Detection in Autonomous Driving. In2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
2025
-
[3]
Xiaowen Cai, Daizong Liu, Xiaoye Qu, Xiang Fang, Jianfeng Dong, Keke Tang, Pan Zhou, Lichao Sun, and Wei Hu. 2026. Towards building model/prompt- transferable attackers against large vision-language models.Advances in Neural Information Processing Systems38 (2026), 174022–174058
2026
-
[4]
Joao Carreira and Andrew Zisserman. 2017. Quo vadis, action recognition? a new model and the kinetics dataset. InCVPR
2017
-
[5]
Jingyuan Chen, Xinpeng Chen, Lin Ma, Zequn Jie, and Tat-Seng Chua. 2018. Temporally grounding natural sentence in video. InEMNLP
2018
-
[6]
Jiaming Chen, Weixin Luo, Wei Zhang, and Lin Ma. 2022. Explore Inter-contrast between Videos via Composition for Weakly Supervised Temporal Sentence Grounding. InAAAI
2022
-
[7]
Long Chen, Chujie Lu, Siliang Tang, Jun Xiao, Dong Zhang, Chilie Tan, and Xiaolin Li. 2020. Rethinking the Bottom-Up Framework for Query-based Video Localization. InAAAI
2020
-
[8]
Zhenfang Chen, Lin Ma, Wenhan Luo, Peng Tang, and Kwan-Yee K Wong
- [9]
-
[10]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. InNeurIPS
2014
-
[11]
Ran Cui, Tianwen Qian, Pai Peng, Elena Daskalaki, Jingjing Chen, Xiaowei Guo, Huyang Sun, and Yu-Gang Jiang. 2022. Video Moment Retrieval from Text Queries via Single Frame Annotation. InSIGIR
2022
-
[12]
Laurent Dinh, David Krueger, and Yoshua Bengio. 2015. NICE: Non-linear independent components estimation.ICLR(2015)
2015
-
[13]
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. 2017. Density estimation using Real NVP.International Conference on Learning Representations(2017)
2017
-
[14]
Wanlong Fang, Tianle Zhang, and Alvin Chan. 2026. To align or not to align: Strategic multimodal representation alignment for optimal performance. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 21056– 21064
2026
-
[15]
Wanlong Fang, Tianle Zhang, Wen Tao, and Alvin Chan. 2026. Towards Un- derstanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition. InInternational Conference on Machine Learning
2026
-
[16]
Xiang Fang. 2026. Advancing Out-of-Distribution Detection Across Diverse Scenarios. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 41042–41043
2026
-
[17]
Xiang Fang, Arvind Easwaran, and Blaise Genest. 2025. Adaptive Multi-prompt Contrastive Network for Few-shot Out-of-distribution Detection. InInterna- tional Conference on Machine Learning
2025
-
[18]
Xiang Fang, Arvind Easwaran, Blaise Genest, and Ponnuthurai Nagaratnam Suganthan. 2025. Adaptive Hierarchical Graph Cut for Multi-granularity Out- of-distribution Detection.IEEE Transactions on Artificial Intelligence(2025)
2025
-
[19]
Xiang Fang, Arvind Easwaran, Blaise Genest, and Ponnuthurai Nagaratnam Sug- anthan. 2025. Your data is not perfect: Towards cross-domain out-of-distribution detection in class-imbalanced data.Expert Systems with Applications(2025)
2025
-
[20]
Xiang Fang and Wanlong Fang. 2026. Disentangling Adversarial Prompts: A Semantic-Graph Defense for Robust LLM Security. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[21]
Xiang Fang and Wanlong Fang. 2026. SLAP: The Semantic Least Action Princi- ple for Variational Video-Language Modeling. InInternational Conference on Machine Learning
2026
-
[22]
Xiang Fang, Wanlong Fang, and Wei Ji. 2026. Immuno-VLM: Immunizing Large Vision-Language Models via Generative Semantic Antibodies for Open-World Trustworthiness. InInternational Conference on Machine Learning
2026
-
[23]
Xiang Fang, Wanlong Fang, Wei Ji, and Tat-Seng Chua. 2025. Turing Patterns for Multimedia: Reaction-Diffusion Multi-Modal Fusion for Language-Guided Video Moment Retrieval. InACM International Conference on Multimedia
2025
-
[24]
Xiang Fang, Wanlong Fang, and Changshuo Wang. 2025. Hierarchical Semantic- Augmented Navigation: Optimal Transport and Graph-Driven Reasoning for Vision-Language Navigation. InAdvances in Neural Information Processing Sys- tems
2025
-
[25]
Xiang Fang, Wanlong Fang, and Changshuo Wang. 2026. CogniVerse: Revolu- tionizing Multi-modal Retrieval-Augmented Generation with Cognitive Reflec- tion and Geometric Reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2026
-
[26]
Xiang Fang, Wanlong Fang, and Changshuo Wang. 2026. Unveiling the Fragility of Vision-Language Models: Multi-Modal Adversarial Synergy via Texture- Constrained Perturbations and Cross-Modal Optimization. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[27]
Xiang Fang, Wanlong Fang, Changshuo Wang, Daizong Liu, Keke Tang, Jianfeng Dong, Pan Zhou, and Beibei Li. 2025. Multi-pair temporal sentence grounding via multi-thread knowledge transfer network. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 2915–2923
2025
-
[28]
Xiang Fang, Wanlong Fang, Changshuo Wang, Daizong Liu, Keke Tang, Jianfeng Dong, Pan Zhou, and Beibei Li. 2025. Multi-Pair Temporal Sentence Grounding via Multi-Thread Knowledge Transfer Network. InProceedings of the AAAI Conference on Artificial Intelligence
2025
-
[29]
Xiang Fang, Wanlong Fang, Changshuo Wang, Xiaoye Qu, and Daizong Liu
-
[30]
InProceedings of the AAAI Conference on Artificial Intelligence
Rethinking Video-language Model From the Language Input Perspective. InProceedings of the AAAI Conference on Artificial Intelligence
-
[31]
Xiang Fang, Wanlong Fang, Changshuo Wang, Keke Tang, Daizong Liu, Siyi Wang, and Wei Ji. 2026. Towards Unified Vision-Language Models With Incom- plete Multi-Modal Inputs. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[32]
Xiang Fang and Yuchong Hu. 2020. Double self-weighted multi-view clustering via adaptive view fusion.arXiv preprint arXiv:2011.10396(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[33]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Wu. 2021. Animc: A soft approach for autoweighted noisy and incomplete multiview clustering.IEEE Transactions on Artificial Intelligence3, 2 (2021), 192–206
2021
-
[34]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Oliver Wu. 2020. V3H: View variation and view heredity for incomplete multiview clustering.IEEE Transac- tions on Artificial Intelligence1, 3 (2020), 233–247
2020
-
[35]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Oliver Wu. 2021. Unbal- anced incomplete multi-view clustering via the scheme of view evolution: Weak views are meat; strong views do eat.IEEE Transactions on Emerging Topics in Computational Intelligence6, 4 (2021), 913–927
2021
-
[36]
Xiang Fang, Daizong Liu, Wanlong Fang, Pan Zhou, Yu Cheng, Keke Tang, and Kai Zou. 2023. Annotations Are Not All You Need: A Cross-modal Knowledge Transfer Network for Unsupervised Temporal Sentence Grounding. InFindings of the Association for Computational Linguistics: EMNLP 2023. 8721–8733
2023
-
[37]
Xiang Fang, Daizong Liu, Wanlong Fang, Pan Zhou, Zichuan Xu, Wenzheng Xu, Junyang Chen, and Renfu Li. 2024. Fewer Steps, Better Performance: Efficient Cross-Modal Clip Trimming for Video Moment Retrieval Using Language. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 1735–1743
2024
-
[38]
Xiang Fang, Daizong Liu, Pan Zhou, and Yuchong Hu. 2022. Multi-modal cross- domain alignment network for video moment retrieval.IEEE Transactions on Multimedia25 (2022), 7517–7532
2022
-
[39]
Xiang Fang, Daizong Liu, Pan Zhou, and Guoshun Nan. 2023. You can ground earlier than see: An effective and efficient pipeline for temporal sentence ground- ing in compressed videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2448–2460
2023
-
[40]
Xiang Fang, Daizong Liu, Pan Zhou, Zichuan Xu, and Ruixuan Li. 2023. Hi- erarchical local-global transformer for temporal sentence grounding.IEEE Transactions on Multimedia(2023)
2023
-
[41]
Xiang Fang, Zeyu Xiong, Wanlong Fang, Xiaoye Qu, Chen Chen, Jianfeng Dong, Keke Tang, Pan Zhou, Yu Cheng, and Daizong Liu. 2024. Rethinking Weakly- supervised Video Temporal Grounding From a Game Perspective. InEuropean Conference on Computer Vision. Springer
2024
-
[42]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017. Tall: Temporal activity localization via language query. InICCV
2017
-
[43]
Jialin Gao, Xin Sun, Mengmeng Xu, Xi Zhou, and Bernard Ghanem. 2021. Relation-aware Video Reading Comprehension for Temporal Language Ground- ing. InEMNLP. 3978–3988
2021
-
[44]
Junyu Gao and Changsheng Xu. 2021. Fast video moment retrieval. InICCV
2021
-
[45]
Runzhou Ge, Jiyang Gao, Kan Chen, and Ram Nevatia. 2019. Mac: Mining activity concepts for language-based temporal localization. InW ACV
2019
-
[46]
Denis Gudovskiy, Shun Ishizaka, and Kazuki Kozuka. 2022. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows.IEEE Winter Conference on Application of Computer Vision(2022)
2022
-
[47]
Dan Guo, Kun Li, Bin Hu, Yan Zhang, and Meng Wang. 2024. Benchmarking Micro-action Recognition: Dataset, Method, and Application.IEEE Transactions on Circuits and Systems for Video Technology34, 7 (2024), 6238–6252
2024
-
[48]
Dan Hendrycks and Kevin Gimpel. [n. d.]. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. InICLR. MM ’24, October 28-November 1, 2024, Melbourne, VIC, Australia Xiang Fang et al
2024
-
[49]
Yen-Chang Hsu, Yilin Shen, Hongxia Jin, and Zsolt Kira. 2020. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data. InCVPR
2020
-
[50]
Jaedong Hwang, Seoung Wug Oh, Joon-Young Lee, and Bohyung Han. 2021. Exemplar-Based Open-Set Panoptic Segmentation Network. InCVPR
2021
-
[51]
Wei Ji, Renjie Liang, Lizi Liao, Hao Fei, and Fuli Feng. 2023. Partial annotation- based video moment retrieval via iterative learning. InMM
2023
-
[52]
Wei Ji, Renjie Liang, Zhedong Zheng, Wenqiao Zhang, Shengyu Zhang, Juncheng Li, Mengze Li, and Tat-seng Chua. 2023. Are binary annotations sufficient? video moment retrieval via hierarchical uncertainty-based active learning. In CVPR
2023
-
[53]
Wei Ji, You Qin, Long Chen, Yinwei Wei, Yiming Wu, and Roger Zimmermann
-
[54]
InICASSP
Mrtnet: Multi-resolution temporal network for video sentence grounding. InICASSP
-
[55]
KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian
-
[56]
Towards open world object detection. InCVPR
- [57]
-
[58]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[59]
Polina Kirichenko, Pavel Izmailov, and Andrew G Wilson. 2020. Why normaliz- ing flows fail to detect out-of-distribution data.NeurIPS33 (2020), 20578–20589
2020
-
[60]
Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Skip-thought vectors.Advances in Neural Information Processing Systems (NIPS)28 (2015)
2015
-
[61]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles
-
[62]
Dense-captioning events in videos. InICCV
-
[63]
Mingjin Kuai, You Qin, Xiang Fang, Wei Ji, and Roger Zimmermann. 2026. Dynamic Graph-enhanced Event Refinement for Temporal Sentence Grounding of Micro-moments.IEEE Transactions on Multimedia(2026)
2026
-
[64]
Nishant Kumar, Siniša Šegvić, Abouzar Eslami, and Stefan Gumhold. 2023. Normalizing Flow based Feature Synthesis for Outlier-Aware Object Detection. InCVPR
2023
-
[65]
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. NeurIPS31 (2018)
2018
-
[66]
Huashuo Lei, Xiaowen Cai, Daizong Liu, Xiang Fang, Xiaoye Qu, Jianfeng Dong, Jixiang Yu, and Keyan Jin. 2025. Exploring Disentangled Appearance- Motion Contexts for Temporal Activity Localization. In2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2025
-
[67]
Hongxiang Li, Meng Cao, Xuxin Cheng, Yaowei Li, Zhihong Zhu, and Yuexian Zou. 2023. G2l: Semantically aligned and uniform video grounding via geodesic and game theory. InICCV
2023
-
[68]
Pandeng Li, Chen-Wei Xie, Hongtao Xie, Liming Zhao, Lei Zhang, Yun Zheng, Deli Zhao, and Yongdong Zhang. 2023. MomentDiff: Generative Video Moment Retrieval from Random to Real. InNeurIPS
2023
-
[69]
Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, Xinwang Liu, Fuchun Sun, and Kunlun He. 2024. A survey of knowledge graph reasoning on graph types: Static, dynamic, and multi-modal.TPAMI (2024)
2024
-
[70]
Ke Liang, Lingyuan Meng, Sihang Zhou, Wenxuan Tu, Siwei Wang, Yue Liu, Meng Liu, Long Zhao, Xiangjun Dong, and Xinwang Liu. 2024. MINES: Message Intercommunication for Inductive Relation Reasoning over Neighbor-Enhanced Subgraphs. InAAAI
2024
-
[71]
Ke Liang, Sihang Zhou, Meng Liu, Yue Liu, Wenxuan Tu, Yi Zhang, Liming Fang, Zhe Liu, and Xinwang Liu. 2024. Hawkes-enhanced spatial-temporal hypergraph contrastive learning based on criminal correlations. InAAAI
2024
-
[72]
Ke Liang, Sihang Zhou, Yue Liu, Lingyuan Meng, Meng Liu, and Xinwang Liu
-
[73]
Structure guided multi-modal pre-trained transformer for knowledge graph reasoning.arXiv(2023)
2023
-
[74]
Shiyu Liang, Yixuan Li, and R Srikant. 2018. Enhancing the reliability of out-of- distribution image detection in neural networks. InICLR
2018
-
[75]
Zhijie Lin, Zhou Zhao, Zhu Zhang, Qi Wang, and Huasheng Liu. 2020. Weakly- supervised video moment retrieval via semantic completion network. InAAAI
2020
-
[76]
Chengliang Liu, Jie Wen, Xiaoling Luo, Chao Huang, Zhihao Wu, and Yong Xu
-
[77]
DICNet: Deep Instance-Level Contrastive Network for Double Incomplete Multi-View Multi-Label Classification. InAAAI
-
[78]
Chengliang Liu, Jie Wen, Xiaoling Luo, and Yong Xu. 2023. Incomplete Multi- View Multi-Label Learning via Label-Guided Masked View- and Category-Aware Transformers. InAAAI
2023
-
[79]
Chengliang Liu, Jie Wen, Zhihao Wu, Xiaoling Luo, Chao Huang, and Yong Xu. 2023. Information Recovery-Driven Deep Incomplete Multiview Clustering Network.IEEE TNNLS(2023)
2023
-
[80]
Daizong Liu, Xiaowen Cai, Junhao Dong, Zhongliang Guo, Xiaoye Qu, Runwei Guan, Xiang Fang, and Dengpan Ye. 2026. Attacking Gray-Box Large Vision- Language Models with Adaptive SVD-Structured Adversarial Alignment. In International Conference on Machine Learning
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.