Fairness Beyond Demographics: Optimizing Performance Across Appearance-Based Hidden Cohorts in Medical Imaging
Pith reviewed 2026-06-29 08:03 UTC · model grok-4.3
The pith
Optimizing fairness across appearance-based image clusters cuts performance gaps on demographic attributes without using any demographic labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
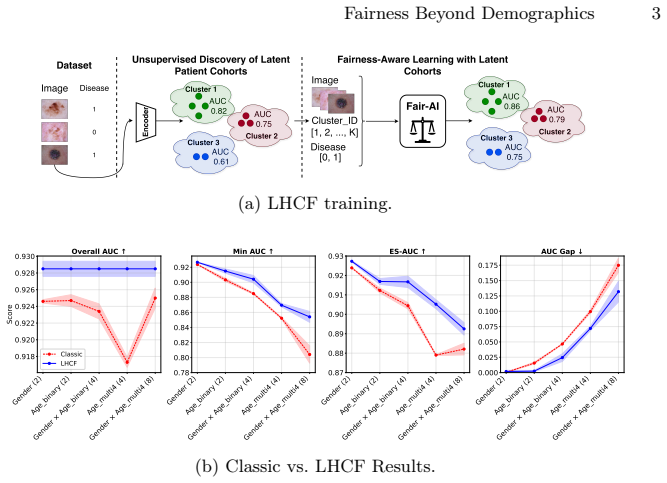
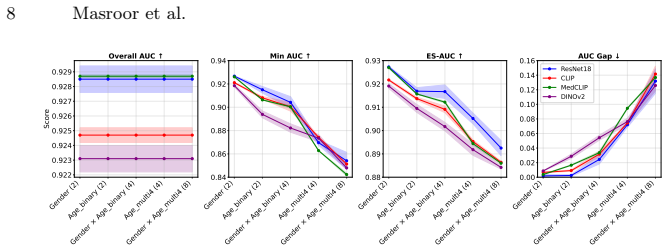
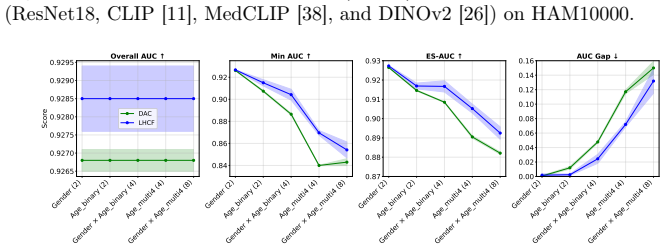
The label-free hidden-cohort fairness (LHCF) training paradigm clusters images into K appearance-based cohorts and optimizes fairness over these cohorts rather than over visible demographic attributes, yielding state-of-the-art reductions in performance disparities across single and multiple demographic attributes on HIDFairBench despite never using demographic labels.
What carries the argument
Label-free hidden-cohort fairness (LHCF) training paradigm, which discovers latent subpopulations through appearance-based clustering of images into K cohorts and then enforces fairness optimization across those cohorts.
If this is right
- Fairness optimization becomes feasible for combinations of multiple demographic attributes without suffering from sparse subgroup data.
- Models can be made more equitable across visible demographics even when those labels are unavailable at training time.
- Latent sources of model error beyond known demographics become accessible for optimization.
- The same training procedure applies uniformly to single-attribute and multi-attribute fairness settings.
Where Pith is reading between the lines
- The clustering step could be replaced by other unsupervised grouping methods to test whether appearance is the most effective signal for hidden cohorts.
- If the discovered cohorts align with clinical variables not used in training, the method might surface new patient stratifications worth studying.
- Deployment in hospitals would require checking whether the appearance clusters remain stable across different scanners and imaging protocols.
Load-bearing premise
Grouping images by visual appearance into a chosen number of cohorts will locate the main subpopulations that cause model errors and unfair performance rather than capturing imaging artifacts or other non-causal patterns.
What would settle it
Training a model with LHCF on a dataset and then observing that performance gaps on held-out demographic splits remain as large as or larger than those from standard training.
Figures
read the original abstract
Medical image analysis models can exhibit performance disparities across patient subgroups, threatening clinical safety and fairness. Existing methods typically address this issue by optimizing accuracy and fairness metrics for visible demographic attributes (e.g., sex or age) considered in isolation. This strategy not only overlooks potentially more informative latent stratifications, which may reveal deeper sources of model error and inequity, but also fails to scale when multiple demographic attributes are considered simultaneously due to the resulting sparsity of training data within each subgroup. We deal with these issues by introducing the label-free hidden-cohort fairness (LHCF) training paradigm that instead of maximizing fairness over visible demographic attributes, it optimizes fairness across latent subpopulations discovered from image appearance. By clustering images into K appearance-based cohorts and applying fairness optimization over them, LHCF uncovers underlying sources of model error and avoids the combinatorial sparsity of multi-demographic attributes, reducing disparities across both single and multiple demographic attributes. We demonstrate on our proposed fairness benchmark, HIDFairBench, that LHCF provides state-of-the-art fairness results on single and multiple demographic attributes, despite never using demographic labels for training. Our results position hidden-cohort fairness as a practical, scalable, and robust alternative to demographic-based fairness optimization for trustworthy medical image analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
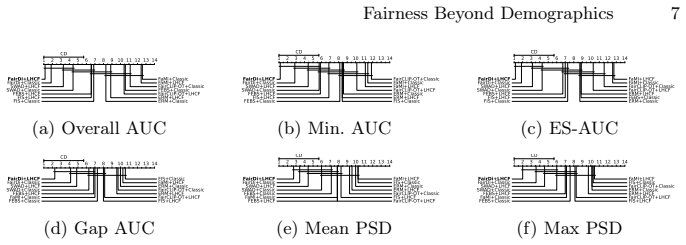
Summary. The manuscript introduces Label-free Hidden-Cohort Fairness (LHCF), which clusters medical images into K appearance-based cohorts via embeddings and applies group-fairness optimization (e.g., group DRO) over those cohorts rather than visible demographic labels. The central claim is that this yields state-of-the-art fairness on both single- and multi-attribute demographic disparities on the proposed HIDFairBench benchmark, without ever using demographic labels during training, while avoiding sparsity issues that arise when optimizing over multiple visible attributes simultaneously.
Significance. If the appearance-based cohorts reliably identify the subpopulations responsible for performance disparities, the approach would be significant: it offers a scalable, label-free alternative to demographic fairness methods and directly addresses the combinatorial sparsity problem for multiple attributes. The introduction of HIDFairBench as a dedicated fairness benchmark is also a positive contribution.
major comments (3)
- [Abstract] Abstract and method description: the SOTA fairness claim on demographic attributes (single and multi-attribute) without demographic labels during training rests on the unverified assumption that appearance-based clusters align with the actual sources of demographic disparity rather than scanner artifacts, acquisition parameters, or other non-causal visual factors. No section demonstrates that the discovered cohorts exhibit higher error variance tied to held-out demographic labels or remain stable under semantic-preserving perturbations.
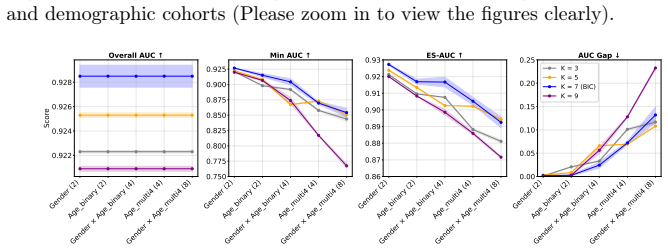
- [Method (clustering and optimization)] The paper lists K as the sole free parameter yet provides no analysis of sensitivity to K or justification that the fairness gains are not artifacts of the particular choice of K; this directly affects the claim that the method is a robust alternative to demographic-based optimization.
- [Experiments] No statistical significance tests, confidence intervals, or ablation on the clustering step are described that would confirm the reported fairness improvements are attributable to the hidden-cohort mechanism rather than the underlying model or optimization details.
minor comments (2)
- [Abstract] The abstract refers to 'our proposed fairness benchmark, HIDFairBench' but does not specify dataset composition, cohort sizes, or how the benchmark ensures that demographic labels are strictly held out from training.
- [Method] Notation for the fairness objective (e.g., the precise group DRO formulation over cohorts) is not introduced in the provided text, making it difficult to verify independence from demographic labels.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We respond to each major comment below and indicate where revisions will be made to address valid concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the SOTA fairness claim on demographic attributes (single and multi-attribute) without demographic labels during training rests on the unverified assumption that appearance-based clusters align with the actual sources of demographic disparity rather than scanner artifacts, acquisition parameters, or other non-causal visual factors. No section demonstrates that the discovered cohorts exhibit higher error variance tied to held-out demographic labels or remain stable under semantic-preserving perturbations.
Authors: We agree that the manuscript does not include explicit verification that the clusters align with demographic sources of disparity (as opposed to other visual factors) or demonstrate higher error variance tied to held-out labels and stability under perturbations. The current evidence consists of downstream improvements in demographic fairness metrics. In revision we will add analyses correlating cluster membership with held-out demographic attributes and evaluating cluster stability under semantic-preserving perturbations. revision: yes
-
Referee: [Method (clustering and optimization)] The paper lists K as the sole free parameter yet provides no analysis of sensitivity to K or justification that the fairness gains are not artifacts of the particular choice of K; this directly affects the claim that the method is a robust alternative to demographic-based optimization.
Authors: We concur that sensitivity analysis for K is required to substantiate robustness. The revised manuscript will include experiments across a range of K values showing that fairness gains remain consistent. revision: yes
-
Referee: [Experiments] No statistical significance tests, confidence intervals, or ablation on the clustering step are described that would confirm the reported fairness improvements are attributable to the hidden-cohort mechanism rather than the underlying model or optimization details.
Authors: The absence of statistical tests, confidence intervals, and clustering ablations is a valid observation. We will add these elements, including significance testing with intervals and an ablation isolating the contribution of the hidden-cohort optimization. revision: yes
Circularity Check
No circularity: method and claims are self-contained without reduction to inputs or self-citations
full rationale
The paper introduces LHCF by describing clustering of images into appearance-based cohorts followed by fairness optimization (e.g., group DRO) over those cohorts, explicitly without demographic labels. No equations, derivations, or self-citations appear in the provided text that would make any result equivalent to its inputs by construction. The benchmark HIDFairBench is proposed as an evaluation tool separate from the training procedure, and the SOTA claim rests on empirical demonstration rather than definitional equivalence. This satisfies the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Appearance-based image clustering will surface latent subpopulations that are more informative for fairness than visible demographic attributes.
invented entities (1)
-
hidden cohorts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In MICCAI (2025), 594–603
Bissoto, A.et al.Subgroup Performance Analysis in Hidden Stratifications. In MICCAI (2025), 594–603
2025
-
[2]
In ACM FAccT (2018), 77–91
Buolamwini, J.et al.Gender shades: Intersectional accuracy disparities in com- mercial gender classification. In ACM FAccT (2018), 77–91
2018
-
[3]
Scientific Data10,123 (2023)
Cai, H.et al.An online mammography database with biopsy confirmed types. Scientific Data10,123 (2023)
2023
-
[4]
NeurIPS34, 22405–22418 (2021)
Cha, J.et al.Swad: Domain generalization by seeking flat minima. NeurIPS34, 22405–22418 (2021)
2021
-
[5]
In CVPR (2024), 12017–12026
Chakraborty, R.et al.Exmap: Leveraging explainability heatmaps for unsuper- vised group robustness to spurious correlations. In CVPR (2024), 12017–12026
2024
-
[6]
Christodoulou,E.et al.Confidenceintervalsuncovered:Arewereadyforreal-world medical imaging AI? In MICCAI (2024), 124–132
2024
-
[7]
In NESY (2024), 403–418
Collevati, M.et al.Leveraging Neurosymbolic AI for Slice Discovery. In NESY (2024), 403–418
2024
-
[8]
DeGrave, A.et al.AI for radiographic COVID-19 detection selects shortcuts over signal. Nat. Mach. Intell. 3, 610–619. 2021
2021
-
[9]
P.et al.Maximum likelihood from incomplete data via the EM algorithm
Dempster, A. P.et al.Maximum likelihood from incomplete data via the EM algorithm. JRSSSB (methodological)39,1–22 (1977)
1977
-
[10]
Eyuboglu, S.et al.Domino: Discovering systematic errors with cross-modal em- beddings. arXiv preprint arXiv:2203.14960 (2022)
-
[11]
In CVPR (2023), 19358–19369
Fang, Y.et al.Eva: Exploring the limits of masked visual representation learning at scale. In CVPR (2023), 19358–19369
2023
-
[12]
G.et al.The clinician and dataset shift in artificial intelligence
Finlayson, S. G.et al.The clinician and dataset shift in artificial intelligence. New England Journal of Medicine385,283–286 (2021)
2021
-
[13]
The use of ranks to avoid the assumption of normality implicit in the analysis of variance
Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association32,675–701 (1937)
1937
-
[14]
In CVPR Workshop (2021), 1820– 1828
Groh, M.et al.Evaluating deep neural networks trained on clinical images in dermatology with the Fitzpatrick 17k dataset. In CVPR Workshop (2021), 1820– 1828
2021
-
[15]
In ICML (2018), 1929–1938
Hashimoto, T.et al.Fairness without demographics in repeated loss minimization. In ICML (2018), 1929–1938
2018
-
[16]
In CVPR (2016), 770– 778
He, K.et al.Deep residual learning for image recognition. In CVPR (2016), 770– 778
2016
-
[17]
IEEE TPAMI43,4037–4058 (2020)
Jing, L.et al.Self-supervised visual feature learning with deep neural networks: A survey. IEEE TPAMI43,4037–4058 (2020)
2020
-
[18]
M.et al.Distribution shift detection for the postmarket surveillance of medical AI algorithms: a retrospective simulation study
Koch, L. M.et al.Distribution shift detection for the postmarket surveillance of medical AI algorithms: a retrospective simulation study. NPJ Digital Medicine7, 120 (2024)
2024
-
[19]
In CVPR (2024), 12289–12301
Luo, Y.et al.FairCLIP: Harnessing fairness in vision-language learning. In CVPR (2024), 12289–12301
2024
- [20]
-
[21]
C.et al.Systematic outperformance of 112 dermatologists in multi- class skin cancer image classification by convolutional neural networks
Maron, R. C.et al.Systematic outperformance of 112 dermatologists in multi- class skin cancer image classification by convolutional neural networks. European Journal of Cancer119,57–65 (2019). 10 Masroor et al
2019
-
[22]
arXiv preprint arXiv:2411.11939 (2024)
Masroor, M.et al.Fair Distillation: Teaching Fairness from Biased Teachers in Medical Imaging. arXiv preprint arXiv:2411.11939 (2024)
-
[23]
Nemenyi,P.B.Distribution-freemultiplecomparisons.(PrincetonUniversity,1963)
1963
-
[24]
In CHIL (2020), 151–159
Oakden-Rayner, L.et al.Hidden stratification causes clinically meaningful failures in machine learning for medical imaging. In CHIL (2020), 151–159
2020
-
[25]
In FAIMI Workshop, MICCAI (2024)
Olesen, V.et al.Slicing through bias: Explaining performance gaps in medical im- age analysis using slice discovery methods. In FAIMI Workshop, MICCAI (2024)
2024
-
[26]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M.et al.Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
arXiv preprint arXiv:2207.04104 (2022)
Plumb, G.et al.Towards a more rigorous science of blindspot discovery in image classification models. arXiv preprint arXiv:2207.04104 (2022)
-
[28]
PLoS medicine 15,e1002686 (2018)
Rajpurkar, P.et al.Deep learning for chest radiograph diagnosis: A retrospective comparison of the CheXNeXt algorithm to practicing radiologists. PLoS medicine 15,e1002686 (2018)
2018
-
[29]
In ICLR (2020)
Sagawa, S.et al.Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. In ICLR (2020)
2020
-
[30]
Estimating the dimension of a model
Schwarz, G. Estimating the dimension of a model. The annals of statistics, 461–464 (1978)
1978
-
[31]
In CVPR (2022), 16742–16751
Seo, S.et al.Unsupervised learning of debiased representations with pseudo- attributes. In CVPR (2022), 16742–16751
2022
-
[32]
Nature medicine 27,2176–2182 (2021)
Seyyed-Kalantari, L.et al.Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations. Nature medicine 27,2176–2182 (2021)
2021
-
[33]
NeurIPS33,19339–19352 (2020)
Sohoni, N.et al.No subclass left behind: Fine-grained robustness in coarse-grained classification problems. NeurIPS33,19339–19352 (2020)
2020
-
[34]
In ECCV (2024)
Tian, Y.et al.FairDomain: Achieving Fairness in Cross-Domain Medical Image Segmentation and Classification. In ECCV (2024)
2024
-
[35]
In ICLR (2024)
Tian, Y.et al.FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling. In ICLR (2024)
2024
-
[36]
Scientific data5,1–9 (2018)
Tschandl, P.et al.The HAM10000 dataset, a large collection of multi-source der- matoscopic images of common pigmented skin lesions. Scientific data5,1–9 (2018)
2018
-
[37]
Vapnik, V. N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 10,988–999 (1999)
1999
-
[38]
In EMNLP (2022), 3876–3887
Wang, Z.et al.Medclip: Contrastive learning from unpaired medical images and text. In EMNLP (2022), 3876–3887
2022
-
[39]
BMJ369(2020)
Wynants, L.et al.Prediction models for diagnosis and prognosis of covid-19: sys- tematic review and critical appraisal. BMJ369(2020)
2020
-
[40]
R.et al.Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: a cross-sectional study
Zech, J. R.et al.Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: a cross-sectional study. PLoS medicine15, e1002683 (2018)
2018
-
[41]
In ICLR (2023)
Zong, Y.et al.MEDFAIR: Benchmarking fairness for medical imaging. In ICLR (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.