OmniMatBench: A Human-Calibrated Multimodal Reasoning Benchmark Across 19 Materials Science Subfields
Pith reviewed 2026-06-29 07:00 UTC · model grok-4.3
The pith
A benchmark of 3,171 expert problems shows top multimodal models score only 0.372 on materials science reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
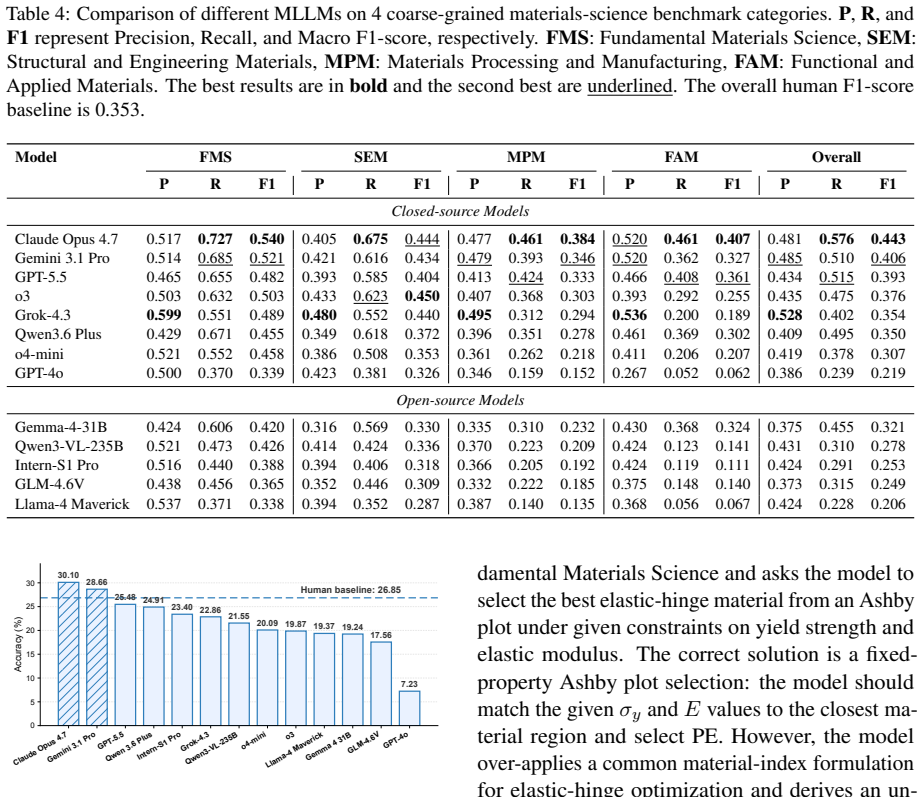
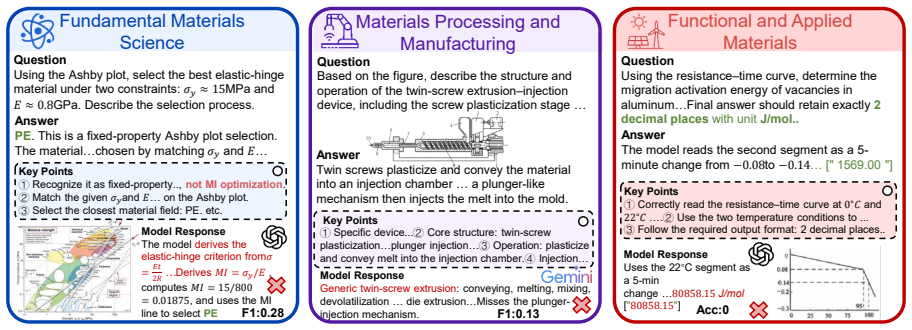
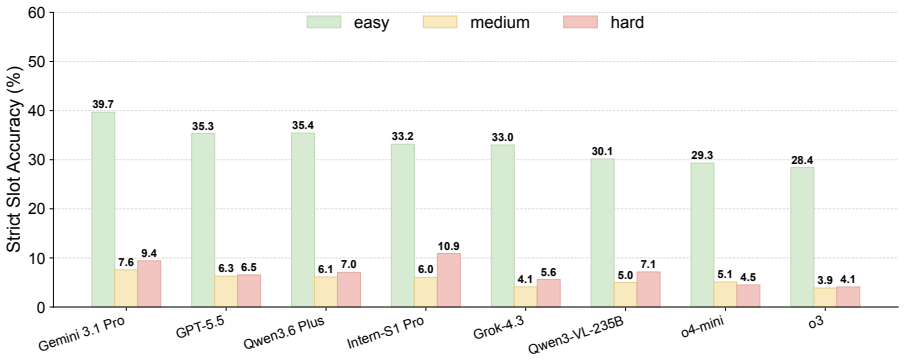
OmniMatBench supplies 3,171 QA and calculation problems distributed across fundamental materials knowledge, structural and engineering materials, processing and manufacturing, and functional and applied materials. Evaluation of 13 open- and closed-source MLLMs produces a maximum overall score of 0.372, accompanied by large performance spreads across the 19 subfields, reliance on fixed reasoning patterns, patchy command of materials facts, and weak results on high-level knowledge use even when formulas, retrieval, or code tools are supplied.
What carries the argument
OmniMatBench, the human-calibrated set of 3,171 multimodal QA and calculation problems spanning 19 materials-science subfields.
If this is right
- Model performance varies sharply across the 19 subfields rather than staying uniform.
- Models fall back on fixed reasoning heuristics instead of adapting to problem demands.
- Knowledge of materials facts is unevenly distributed inside the evaluated models.
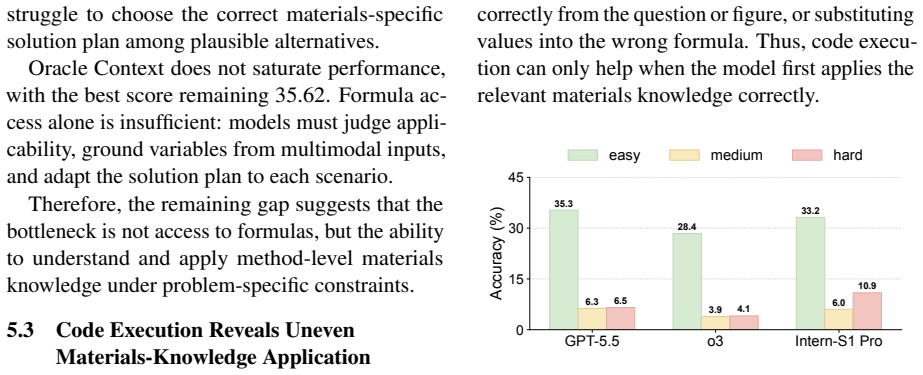
- Even with formula, retrieval, or code assistance, models struggle to apply high-level knowledge to new situations.
Where Pith is reading between the lines
- The benchmark could serve as a repeated yardstick to measure whether future models close the observed gap over successive releases.
- Training efforts might gain from targeted data on the subfields where current scores are lowest.
- Comparable human-calibrated reasoning suites could be built for adjacent fields such as chemistry or mechanical engineering to test transfer of the same limitations.
- Low scores imply that any near-term AI assistant for materials work would still need routine human review on complex tasks.
Load-bearing premise
The chosen problems faithfully represent the reasoning steps used in actual materials research and were scored correctly by the human experts who calibrated them.
What would settle it
A model that scores above 0.6 on the full set while independent materials researchers confirm the problems match typical research tasks and that the original human calibrations hold.
Figures







read the original abstract
As multimodal language models play an increasingly important role in scientific research, materials science offers a critical testbed due to its interdisciplinary, multimodal, and application-driven nature. However, existing materials benchmarks mainly focus on property prediction, knowledge QA, or characterization understanding, leaving the broader reasoning process from materials knowledge to application underexplored. To fill this gap, we present OmniMatBench, a human-calibrated multimodal reasoning benchmark for materials science. OmniMatBench contains 3,171 expert-curated QA and calculation problems across 19 materials-science subfields, spanning fundamental materials knowledge, structural and engineering materials, materials processing and manufacturing, and functional and applied materials. We evaluate 13 open-source and closed-source MLLMs and find that the best model achieves only a 0.372 overall score, revealing a substantial gap in current materials-science reasoning. Further analysis shows strong variation across subfields, fixed reasoning heuristics, uneven materials knowledge, and limited high-level knowledge application under formula-, retrieval-, and code-assisted settings. OmniMatBench provides crucial insights into the capabilities and limitations of current MLLMs and establishes a foundation for reliable AI assistants in materials-science research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents OmniMatBench, a benchmark with 3,171 expert-curated multimodal QA and calculation problems across 19 materials science subfields. Evaluation of 13 MLLMs shows the best model achieving an overall score of 0.372, with additional analysis of subfield variation, fixed reasoning heuristics, and limitations under formula-, retrieval-, and code-assisted conditions.
Significance. If the curation and calibration processes prove robust and the problems representative of end-to-end materials reasoning, the benchmark would offer a useful addition to existing materials-science testbeds by spanning fundamental knowledge through applied calculation tasks. The multi-subfield scope and inclusion of calculation problems are strengths relative to narrower property-prediction or QA benchmarks.
major comments (2)
- [Abstract] Abstract: the central claim that the 0.372 score reveals a 'substantial gap in current materials-science reasoning' rests on the unverified assumptions that the 3,171 problems are representative of full research reasoning chains and that human calibration ensures they test intended reasoning rather than surface patterns. No quantitative evidence (inter-annotator agreement, expert validation metrics, or coverage statistics) is supplied to support these assumptions.
- [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: the scoring methodology for multimodal and calculation problems is not described in sufficient detail to rule out measurement artifacts or post-hoc selection effects, which directly affects the reliability of the headline performance number and the subfield-variation analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional details and evidence as outlined.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 0.372 score reveals a 'substantial gap in current materials-science reasoning' rests on the unverified assumptions that the 3,171 problems are representative of full research reasoning chains and that human calibration ensures they test intended reasoning rather than surface patterns. No quantitative evidence (inter-annotator agreement, expert validation metrics, or coverage statistics) is supplied to support these assumptions.
Authors: We agree that quantitative validation metrics would strengthen the central claim. In the revised manuscript we will add inter-annotator agreement scores from the expert curation process, expert validation metrics for the human calibration procedure, and coverage statistics across the 19 subfields. These additions will directly support the representativeness of the problems and the interpretation of the performance gap. revision: yes
-
Referee: [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: the scoring methodology for multimodal and calculation problems is not described in sufficient detail to rule out measurement artifacts or post-hoc selection effects, which directly affects the reliability of the headline performance number and the subfield-variation analysis.
Authors: We acknowledge that the current description of the scoring methodology is insufficient. We will expand the benchmark construction and evaluation sections to include a detailed account of the scoring rules for multimodal and calculation problems, explicit procedures used to minimize measurement artifacts, and the evaluation protocol designed to avoid post-hoc selection effects. These clarifications will improve the reliability of the headline results and subfield analysis. revision: yes
Circularity Check
No significant circularity; empirical benchmark with no derivation chain
full rationale
The paper constructs and evaluates a multimodal benchmark (OmniMatBench) consisting of 3,171 expert-curated problems across 19 subfields, then reports model scores such as the best MLLM at 0.372. No equations, fitted parameters, predictions, or uniqueness theorems appear in the text. The work contains no self-citation load-bearing steps, no ansatz smuggling, and no renaming of known results as derivations. All claims rest on the external curation and evaluation process rather than any internal reduction of outputs to inputs by construction, making the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aaron Adcock, Aayushi Srivastava, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pande, Abhinav Pandey, Abhinav Sharma, Abhishek Kadian, Abhishek Kumawat, Adam Kelsey, and 1 others. 2026. The llama 4 herd: Architecture, training, evaluation, and deployment notes. arXiv preprint arXiv:2601.11659
-
[2]
Nawaf Alampara, Mara Schilling-Wilhelmi, Marti \ n o R \' os-Garc \' a, Indrajeet Mandal, Pranav Khetarpal, Hargun Singh Grover, NM Anoop Krishnan, and Kevin Maik Jablonka. 2025. Probing the limitations of multimodal language models for chemistry and materials research. Nature computational science, 5(10):952--961
2025
-
[3]
Anthropic . 2026. Introducing Claude Opus 4.7 . https://www.anthropic.com/news/claude-opus-4-7. Accessed: 2026-05-24
2026
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Lowik Chanussot, Abhishek Das, Siddharth Goyal, Thibaut Lavril, Muhammed Shuaibi, Morgane Riviere, Kevin Tran, Javier Heras-Domingo, Caleb Ho, Weihua Hu, and 1 others. 2021. Open catalyst 2020 (oc20) dataset and community challenges. Acs Catalysis, 11(10):6059--6072
2021
- [6]
-
[7]
Kamal Choudhary, Daniel Wines, Kangming Li, Kevin F Garrity, Vishu Gupta, Aldo H Romero, Jaron T Krogel, Kayahan Saritas, Addis Fuhr, Panchapakesan Ganesh, and 1 others. 2024. Jarvis-leaderboard: a large scale benchmark of materials design methods. npj Computational Materials, 10(1):93
2024
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Alexander Dunn, Qi Wang, Alex Ganose, Daniel Dopp, and Anubhav Jain. 2020. Benchmarking materials property prediction methods: the matbench test set and automatminer reference algorithm. npj Computational Materials, 6(1):138
2020
-
[11]
Google . 2026. Gemma 4 Model Card . https://ai.google.dev/gemma/docs/core/model_card_4. Accessed: 2026-05-24
2026
-
[12]
Google DeepMind . 2026. Gemini 3.1 Pro Model Card . https://deepmind.google/models/model-cards/gemini-3-1-pro/. Accessed: 2026-05-24
2026
-
[13]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, and 1 others. 2025. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Zhengzhao Lai, Youbin Zheng, Zhenyang Cai, Haonan Lyu, Jingpu Yang, Hong-Qing Liang, Yan Hu, and Benyou Wang. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.235 Can multimodal LLM s see materials clearly? a multimodal benchmark on materials characterization . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 4384--4404...
-
[16]
L \'a szl \'o Lendvai and Alessandro Pegoretti. 2024. The rise of interdisciplinarity: A new era in polymer research? Express Polymer Letters, 18(10):962--963
2024
-
[17]
Wanhao Liu, Weida Wang, Jiaqing Xie, Suorong Yang, Jue Wang, Benteng Chen, Guangtao Mei, Zonglin Yang, Shufei Zhang, Yuchun Mo, and 1 others. 2026. Polyreal: A benchmark for real-world polymer science workflows. arXiv preprint arXiv:2604.02934
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
-
[19]
Santiago Miret and NM Anoop Krishnan. 2025. Enabling large language models for real-world materials discovery. Nature Machine Intelligence, 7(7):991--998
2025
-
[20]
OpenAI . 2025. Introducing OpenAI o3 and o4-mini . https://openai.com/index/introducing-o3-and-o4-mini/. Published: April 16, 2025. Accessed: 2026-05-24
2025
-
[21]
OpenAI . 2026. GPT-5.5 Model . https://developers.openai.com/api/docs/models/gpt-5.5. Accessed: 2026-05-24
2026
-
[22]
Qwen Team . 2026. Qwen3.6-Plus: Towards Real World Agents . https://qwen.ai/blog?id=qwen3.6. Published: April 1, 2026. Accessed: 2026-05-24
2026
-
[23]
Janosh Riebesell, Rhys EA Goodall, Philipp Benner, Yuan Chiang, Bowen Deng, Gerbrand Ceder, Mark Asta, Alpha A Lee, Anubhav Jain, and Kristin A Persson. 2025. A framework to evaluate machine learning crystal stability predictions. nature machine intelligence, 7(6):836--847
2025
-
[24]
Yingheng Tang, Wenbin Xu, Jie Cao, Weilu Gao, Steven Farrell, Benjamin Erichson, Michael W Mahoney, Andy Nonaka, and Zhi Jackie Yao. 2026. A multimodal large language model for materials science. Nature Machine Intelligence, pages 1--14
2026
-
[25]
Richard Tran, Janice Lan, Muhammed Shuaibi, Brandon M Wood, Siddharth Goyal, Abhishek Das, Javier Heras-Domingo, Adeesh Kolluru, Ammar Rizvi, Nima Shoghi, and 1 others. 2023. The open catalyst 2022 (oc22) dataset and challenges for oxide electrocatalysts. Acs Catalysis, 13(5):3066--3084
2023
- [26]
- [27]
-
[28]
xAI . 2026. Grok 4.3 . https://docs.x.ai/developers/models/grok-4.3. Accessed: 2026-05-24
2026
-
[29]
Mohd Zaki, NM Anoop Krishnan, and 1 others. 2024. Mascqa: investigating materials science knowledge of large language models. Digital Discovery, 3(2):313--327
2024
-
[30]
Junkai Zhang, Jingru Gan, Xiaoxuan Wang, Zian Jia, Changquan Gu, Jianpeng Chen, Yanqiao Zhu, Mingyu Derek Ma, Dawei Zhou, Ling Li, and 1 others. 2025. Matscibench: Benchmarking the reasoning ability of large language models in materials science. arXiv preprint arXiv:2510.12171
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [31]
-
[32]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[33]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.