EvoRubric: Self-Evolving Rubric-Driven RL for Open-Ended Generation
Pith reviewed 2026-06-29 07:51 UTC · model grok-4.3
The pith
A single policy co-evolves both responses and rubrics to align LLMs on open-ended tasks without static criteria or external generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
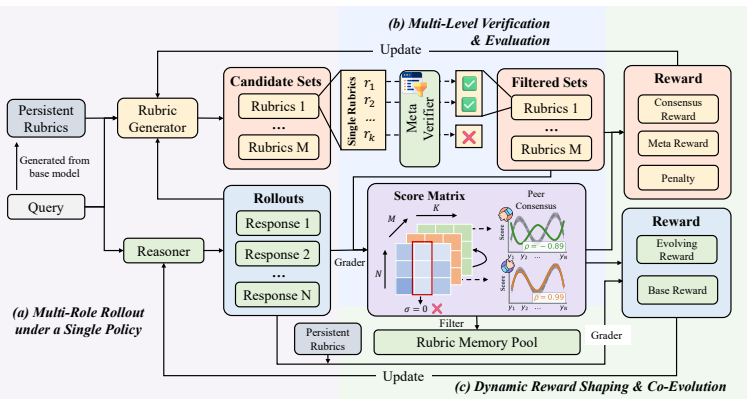
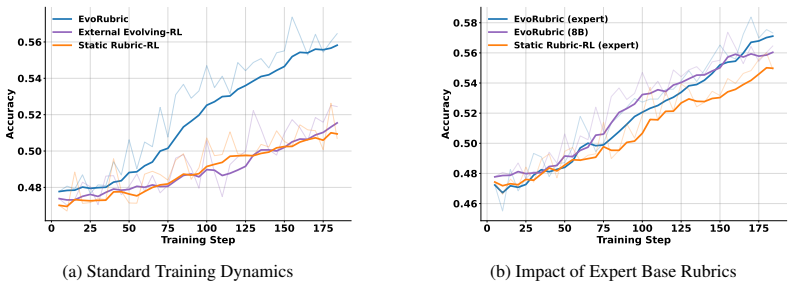
EvoRubric unifies response generation and rubric generation under one parameterized policy that alternates between Reasoner and Rubric Generator roles; a multi-level verification pipeline of meta-verifier, zero-variance pruning, and Leave-One-Out peer consensus filters reliable rubrics, which are archived in a memory pool to supply dense multi-objective rewards that continuously co-optimize both capabilities, yielding better results than static or external-LLM alignment methods and the ability to extend expert-annotated rubrics with novel dimensions.
What carries the argument
Single-policy co-evolution that alternates between Reasoner and Rubric Generator, backed by a multi-level verification pipeline and memory pool of validated rubrics to produce dense rewards.
If this is right
- The policy can keep adapting evaluation criteria without repeated human annotation.
- Expert rubrics can be used as a starting point that the system then extends with additional dimensions.
- Alignment no longer requires separate external models to create or update rubrics.
- The same framework applies across medical, writing, and science domains.
Where Pith is reading between the lines
- Self-generated rubrics could lower the cost of alignment by removing calls to proprietary models.
- If the verification holds, the approach may transfer to other subjective-reward settings beyond open-ended text.
- Over time the policy might learn to surface evaluation criteria that human annotators overlook.
Load-bearing premise
The verification pipeline reliably removes reward-hacking rubrics and supplies signals that genuinely improve the policy rather than just fitting the verification rules.
What would settle it
Remove the multi-level verification pipeline and check whether policy performance still exceeds static-rubric baselines or instead collapses due to exploited rubrics.
Figures

read the original abstract
Reinforcement Learning (RL) has significantly advanced Large Language Models (LLMs) in verifiable domains, but aligning models for open-ended generation remains profoundly challenging due to the lack of definitive rewards. Current rubric-based RL methods mitigate this by employing explicit criteria; however, they rely heavily on static, human-annotated rubrics that inevitably cause policy lag, or expensive external proprietary models for dynamic updates. In this paper, we propose EvoRubric, a novel single-policy co-evolutionary RL framework that eliminates the reliance on static criteria and on external rubric generators. By unifying response generation and rubric generation under a single parameterized policy, EvoRubric dynamically alternates between a Reasoner and a Rubric Generator. To prevent reward hacking and ensure the reliability of generated signals, we introduce a multi-level verification pipeline featuring a meta-verifier, zero-variance pruning, and a Leave-One-Out peer consensus mechanism. Validated criteria are dynamically archived into a memory pool, yielding dense, multi-objective rewards to continuously co-optimize both roles. Extensive experiments across Medical, Writing, and Science domains demonstrate that EvoRubric consistently outperforms traditional static and external-LLM-driven alignment methods. Notably, our framework is compatible with human-expert priors. When initialized with expert-annotated rubrics, EvoRubric can further uncover novel, discriminative dimensions, achieving better performance than relying solely on static expert annotations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvoRubric, a single-policy co-evolutionary RL framework for open-ended LLM generation. The policy alternates between a Reasoner role (response generation) and a Rubric Generator role; validated rubrics are produced via a multi-level verification pipeline (meta-verifier, zero-variance pruning, Leave-One-Out peer consensus), archived in a memory pool, and used to supply dense multi-objective rewards that co-optimize both roles. Experiments across Medical, Writing, and Science domains report consistent outperformance versus static human-annotated rubrics and external-LLM rubric generators; the framework is also shown to be compatible with expert priors and capable of discovering additional discriminative dimensions.
Significance. If the verification pipeline demonstrably blocks reward hacking while still supplying useful gradients in a single-policy setup, the approach would reduce dependence on static criteria and proprietary external models, offering a more scalable path for rubric-based alignment in open-ended domains. The memory-pool archiving and explicit compatibility with human-expert initialization are constructive features that could be adopted more broadly.
major comments (3)
- [Abstract] Abstract: the claim that the multi-level verification pipeline (meta-verifier + zero-variance pruning + Leave-One-Out consensus) reliably filters reward-hacking rubrics is load-bearing for the central performance claim, yet no implementation details, pseudocode, or interaction with the single parameterized policy are supplied; because both Reasoner and Rubric Generator share parameters, any learnable weakness in verification logic could be exploited.
- [Abstract] Abstract / Experiments: no ablation removing individual verification stages (e.g., zero-variance pruning or Leave-One-Out consensus) or diagnostic metrics (rubric-score variance before/after pruning, correlation between archived rubrics and human preference) are reported; without these, it is impossible to verify that the pipeline improves generation quality rather than merely increasing consistency with the verification rules themselves.
- [Abstract] Abstract: the reported gains over static and external-LLM baselines lack mention of statistical significance tests, controls for fitted verification thresholds, or checks that performance survives when self-generated data is replaced by held-out human rubrics; these controls are necessary to rule out circularity between the verification logic and the measured improvements.
minor comments (1)
- [Abstract] Abstract: the phrase 'dense, multi-objective rewards' is used without specifying how multiple archived rubrics are aggregated or weighted during policy optimization.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for greater transparency around the verification pipeline and experimental controls. We address each major comment below. Where details were insufficient in the submitted version, we will revise the manuscript to include them.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the multi-level verification pipeline (meta-verifier + zero-variance pruning + Leave-One-Out consensus) reliably filters reward-hacking rubrics is load-bearing for the central performance claim, yet no implementation details, pseudocode, or interaction with the single parameterized policy are supplied; because both Reasoner and Rubric Generator share parameters, any learnable weakness in verification logic could be exploited.
Authors: We agree that the abstract omits these specifics and that the shared-parameter setup makes verification robustness critical. The full manuscript (Section 3.2) describes the three-stage pipeline and its integration with the single policy, but we will add explicit pseudocode for the verification loop, a diagram of parameter sharing, and a short analysis of why the meta-verifier and consensus steps are not directly learnable by the policy. These additions will appear in the revised version. revision: yes
-
Referee: [Abstract] Abstract / Experiments: no ablation removing individual verification stages (e.g., zero-variance pruning or Leave-One-Out consensus) or diagnostic metrics (rubric-score variance before/after pruning, correlation between archived rubrics and human preference) are reported; without these, it is impossible to verify that the pipeline improves generation quality rather than merely increasing consistency with the verification rules themselves.
Authors: The current experiments do not contain the requested ablations or diagnostics. We will add (i) an ablation table removing each verification stage in turn, (ii) before/after variance statistics for archived rubrics, and (iii) correlation of rubric scores with held-out human preferences. These results will be reported in a new subsection of the experiments. revision: yes
-
Referee: [Abstract] Abstract: the reported gains over static and external-LLM baselines lack mention of statistical significance tests, controls for fitted verification thresholds, or checks that performance survives when self-generated data is replaced by held-out human rubrics; these controls are necessary to rule out circularity between the verification logic and the measured improvements.
Authors: We will include paired t-tests or Wilcoxon tests with p-values for all main comparisons, report sensitivity to verification thresholds, and add an experiment that substitutes the memory pool with held-out human rubrics while keeping the rest of the pipeline fixed. If the performance advantage persists, it will be shown; if not, we will discuss the limitation. revision: yes
Circularity Check
No circularity; framework described as empirical with external safeguards but no equations or self-citations reduce claims to inputs by construction.
full rationale
The abstract presents EvoRubric as a single-policy co-evolution with a multi-level verification pipeline (meta-verifier, zero-variance pruning, Leave-One-Out consensus) to prevent reward hacking, but supplies no equations, fitted parameters renamed as predictions, or self-citation chains. Performance is claimed via experiments across domains rather than derived by definition. Without methods-section equations showing e.g. reward = f(verification rules) by construction, the derivation chain remains independent of its own outputs. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature645(8081), 633–638 (Sep 2025)
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nat., 645(8081):633–638, 2025. doi: 10.1038/S41586-025-09422-Z. URL https://doi.org/ 10.1038/s41586-025-09422-z
-
[3]
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean M. Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains. InThe Four- teenth International Conference on Learning Representations, ICLR 2026. OpenReview.net, 2026. URL https://openreview.net/forum?id=c1bTcrDmt4
2026
-
[5]
Yu, and Sujian Li
Xiyu Wei, Qingwei Zong, Xiaoguang Li, Eugene J. Yu, and Sujian Li. Qurl: Rubrics as judge for open- ended question answering. InThe Fourteenth International Conference on Learning Representations, ICLR
-
[6]
URLhttps://openreview.net/forum?id=DrhWTuhtYq
OpenReview.net, 2026. URLhttps://openreview.net/forum?id=DrhWTuhtYq
2026
-
[9]
Yarn: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/ forum?id=wHBfxhZu1u
2024
-
[10]
How to train long-context language models (effectively)
Tianyu Gao, Alexander Wettig, Howard Yen, and Danqi Chen. How to train long-context language models (effectively). In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - Augu...
2025
-
[12]
Thomas McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Trans. Assoc. Comput. Linguistics, 10:539–554, 2022. doi: 10.1162/TACL\_A\_00475. URLhttps://doi.org/10.1162/tacl_a_00475. 10
work page internal anchor Pith review doi:10.1162/tacl 2022
-
[13]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=Ti67584b98
2024
-
[16]
Finesure: Fine-grained summarization evaluation using llms
Hwanjun Song, Hang Su, Igor Shalyminov, Jason Cai, and Saab Mansour. Finesure: Fine-grained summarization evaluation using llms. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 9...
-
[18]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[19]
Simpo: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS...
2024
-
[20]
Safe RLHF: safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: safe reinforcement learning from human feedback. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=TyFrPOKYXw
2024
-
[22]
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, and Bruno Castro da Silva. RLHF deciphered: A critical analysis of reinforcement learning from human feedback for llms.ACM Comput. Surv., 58(2):53:1–53:37, 2026. doi: 10.1145/3743127. URLhttps://doi.org/10.1145/3743127
-
[25]
Reinforcing chain-of-thought reasoning with self-evolving rubrics.CoRR, abs/2602.10885, 2026
Leheng Sheng, Wenchang Ma, Ruixin Hong, Xiang Wang, An Zhang, and Tat-Seng Chua. Reinforcing chain-of-thought reasoning with self-evolving rubrics.CoRR, abs/2602.10885, 2026. doi: 10.48550/ ARXIV .2602.10885. URLhttps://doi.org/10.48550/arXiv.2602.10885
-
[29]
Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar
Li S. Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar. Researchqa: Evaluating scholarly ques- tion answering at scale across 75 fields with survey-mined questions and rubrics.CoRR, abs/2509.00496,
-
[31]
Llmeval-med: A real-world clinical benchmark for medical llms with physician validation
Ming Zhang, Yujiong Shen, Zelin Li, Huayu Sha, Binze Hu, Yuhui Wang, Chenhao Huang, Shichun Liu, Jingqi Tong, Changhao Jiang, Mingxu Chai, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang, and Xuanjing Huang. Llmeval-med: A real-world clinical benchmark for medical llms with physician validation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, ...
2025
-
[32]
Eq-bench creative writing benchmark v3
Samuel J Paech. Eq-bench creative writing benchmark v3. https://github.com/EQ-bench/ creative-writing-bench, 2025
2025
-
[33]
Gemini-2.5-pro, 2025
Gemini Team. Gemini-2.5-pro, 2025. URL https://blog.google/innovation-and-ai/ models-and-research/google-deepmind/gemini-model-thinking-updates-march-2025/ #gemini-2-5-pro
2025
-
[34]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card.CoRR, abs/2508.10925, 2025. doi: 10.48550/ARXIV . 2508.10925. URLhttps://doi.org/10.48550/arXiv.2508.10925. A Differences from Previous Work To further clarify the novelty ofEvoRubric, we provide a detailed comparison between our framework and three representative lines of previous work in the realm of Rubric-...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[36]
Look for significant differences in quality, accuracy, style, or reasoning
Focus on Discriminative Features (The “Gap”) • Analyze the content of the responses deeply. Look for significant differences in quality, accuracy, style, or reasoning. • If two responses differ meaningfully (e.g., one is concise and accurate, the other is verbose and vague), but no Existing Rubric captures this difference, you must create a new rubric for...
-
[37]
•Avoid Duplication: Never duplicate an existing rubric in meaning or scope
Radical Non-Redundancy & Sparsity (CRITICAL) •Check Coverage First: Before creating a new rubric, rigorously verify if an Existing Rubric already covers the specific quality or error you noticed. •Avoid Duplication: Never duplicate an existing rubric in meaning or scope. Only target specific nuances or dimensions that are completely absent from the curren...
-
[38]
Includes a specific Python code example to illustrate the concept
Style Alignment & Formatting •Mimic the Style: Ensure your new criteria match the tone, length, and specificity level of the Existing Rubrics. •Condition-Based Scoring: All criteria must be written as conditions that,when met, trigger the point assignment. •Positive Rubrics (+ Points): Describe a specific excellence found in high-quality responses (e.g., ...
-
[39]
It should be a clear, unambiguous instruction for both human raters and future reward model training
Actionable & Objective • Each criterion must describe an observable, verifiable quality or error in the response text. It should be a clear, unambiguous instruction for both human raters and future reward model training. ### Analysis Workflow
-
[40]
• Mentally apply the existing rubrics to the responses
Mental Evaluation (The Coverage Check): • Read theResponsesand review theExisting Rubrics. • Mentally apply the existing rubrics to the responses. • Ask:Is there a significant strength in a good response or a fatal flaw in a bad response that completely slips through the current criteria?
-
[41]
Gap Identification: • Identify specific traits (reasoning steps, formatting, safety constraints, tone) that heavily distinguish the responses but are absent from the input rubrics
-
[42]
Direction & Formulation: • Frame the identified quality as a concrete condition to be met
-
[43]
criterion
Prioritization (Quality > Quantity): Continued on next page... 14 Table 5: Prompt template for the Rubric Generator (Continued) System Prompt • Generate 0 to 6 total rubrics. • 1 piercingly accurate, highly discriminative rubric is infinitely better than multiple mediocre ones. If no meaningful gap exists, output[]. ### Output Format Return ONLY a JSON li...
-
[44]
It contradicts standard medical guidelines or encourages hallucinations
Factual Conflict:The rubric rewards medically dangerous extrapolation, unverified diagnoses, or sycophancy (e.g., rewarding a response for agreeing with a user’s false premise). It contradicts standard medical guidelines or encourages hallucinations
-
[45]
test the pH of the prescribed ointment at home
Unmeasurable:The rubric demands actions that are impossible for a human rater to verify or clinically impractical for a patient (e.g., “test the pH of the prescribed ointment at home”)
-
[46]
Semantic Duplication:The rubric functionally overlaps with an existing base rubric, even if it uses different vocabulary or complex medical jargon to mask the duplication
-
[47]
consult a doctor
Trivial/Cliché:The rubric focuses on generic, superficial advice that applies to almost any medical query (e.g., “consult a doctor”) unless specifically critical to the prompt context
-
[48]
Length Hallucination:The rubric specifically rewards excessively long or verbose answers without adding clinical value
-
[49]
must use a markdown table
Style Hallucination:The rubric enforces a specific formatting style (e.g., “must use a markdown table”) that is irrelevant to the clinical accuracy of the response. Output your evaluation strictly in the following JSON format. Do not include any other text or markdown blocks outside the JSON: { "verdict": "VALID" // OR "INVALID: <Category Name>" // (e.g.,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.