Feedback-to-Rubrics: Can We Learn Expert Criteria from Inline Comments?
Pith reviewed 2026-06-29 09:09 UTC · model grok-4.3
The pith
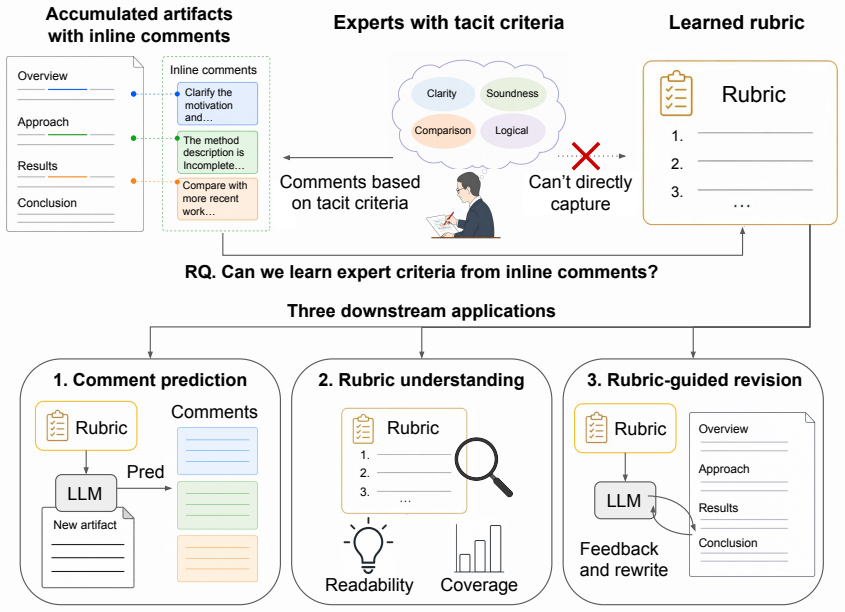
Inline comments on artifacts can be distilled into reusable natural-language rubrics that guide comment prediction and artifact revision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Inline comments can be distilled into reusable rubrics that support comment prediction, rubric understanding, and automatic artifact revision.
What carries the argument
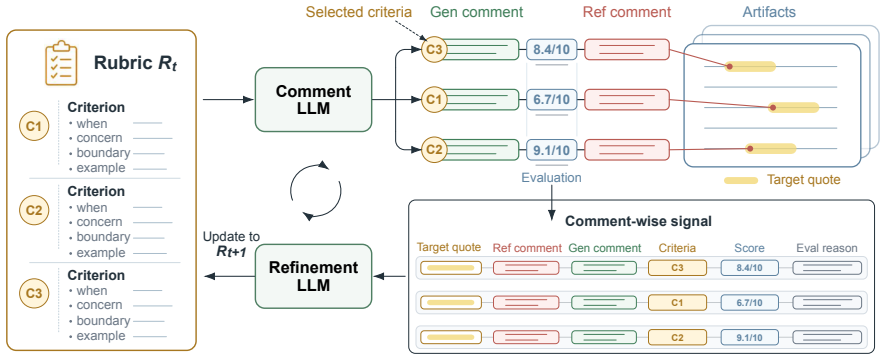
Iterative rubric refinement driven by mismatches between rubric-conditioned LLM predictions and reference comments.
If this is right
- Learned rubrics can be applied to new artifacts to predict the comments an expert would leave.
- The same rubrics can be used to revise artifacts so they better satisfy the captured criteria.
- The rubrics become explicit, reusable statements of tacit preferences that were previously only implicit in comments.
- The refinement loop operates without requiring new human-labeled examples beyond the original comments.
Where Pith is reading between the lines
- Organizations could maintain living rubrics that evolve from ongoing review streams rather than static documents.
- The approach might extend to domains with different feedback forms, such as code review comments or design critiques.
- A natural test would be to compare rubric quality when the underlying LLM is swapped for a weaker or stronger model.
Load-bearing premise
Mismatches between rubric-conditioned LLM predictions and reference comments supply a reliable signal for refinement without extra labeled data or human oversight.
What would settle it
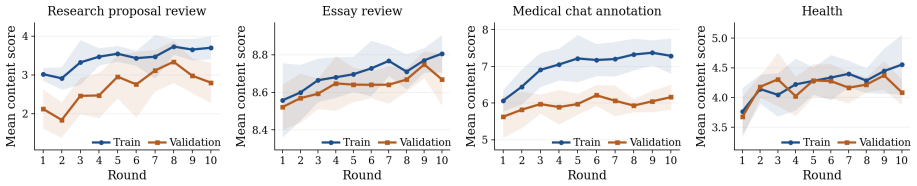
Measure whether rubrics refined on one set of comments produce comment predictions on held-out drafts that human experts rate as matching their own feedback more closely than rubrics created by direct prompting or baselines.
Figures


read the original abstract
Large language models (LLMs) are increasingly used for writing and review support, but their usefulness depends on context-dependent criteria, such as expert preferences or organization-specific conventions, that are often tacit, undocumented, and difficult to elicit directly. We propose a problem setting for learning reusable natural-language rubrics from accumulated inline comments on artifacts such as human-written or LLM-generated drafts. Our method infers rubrics from these comments and iteratively refines them by observing comment-wise mismatches between rubric-conditioned predictions and reference comments. We evaluate the proposed method in real-world review settings and in controlled settings with reference rubrics. These results show that inline comments can be distilled into reusable rubrics that support comment prediction, rubric understanding, and automatic artifact revision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Feedback-to-Rubrics, a method to distill reusable natural-language rubrics from accumulated inline comments on artifacts (human or LLM-generated drafts). Rubrics are inferred from comments and iteratively refined by observing mismatches between rubric-conditioned LLM predictions and reference comments. The approach is evaluated in real-world review settings and controlled settings with reference rubrics. The central claim is that the resulting rubrics support three capabilities: comment prediction, rubric understanding, and automatic artifact revision.
Significance. If the results hold, the work would be significant for LLM-assisted writing and review systems. It addresses the challenge of capturing tacit, context-dependent criteria (expert preferences or organizational conventions) without direct elicitation, using existing feedback as a signal. The mismatch-based refinement loop is a potentially efficient way to improve rubric quality without new labeled data. Success would enable more adaptable, reusable rubrics that improve LLM performance on downstream tasks like prediction and revision.
major comments (2)
- [Abstract] Abstract: the central claim that inline comments can be distilled into reusable rubrics supporting comment prediction, rubric understanding, and automatic artifact revision is stated without any quantitative results, baselines, or error analysis. This makes it impossible to assess whether the mismatch signal actually produces improvements or whether the three capabilities are demonstrated at a level beyond the reference comments themselves.
- [Method] Method (inferred from abstract description): the iterative refinement step treats mismatches between rubric-conditioned LLM predictions and reference comments as a sufficient, reliable signal for rubric improvement without additional labeled data or human oversight. No details are provided on rubric representation, mismatch quantification, or controls against degenerate solutions (e.g., overly vague or circular rubrics), which is load-bearing for the claim that expert criteria can be learned this way.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address each major comment below, clarifying the manuscript content and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that inline comments can be distilled into reusable rubrics supporting comment prediction, rubric understanding, and automatic artifact revision is stated without any quantitative results, baselines, or error analysis. This makes it impossible to assess whether the mismatch signal actually produces improvements or whether the three capabilities are demonstrated at a level beyond the reference comments themselves.
Authors: The abstract is intentionally high-level to summarize the problem setting and approach. Quantitative results, including performance metrics on comment prediction (e.g., F1 improvements over baselines), rubric understanding tasks, and revision quality (with human and automatic evaluations), along with error analyses and comparisons to reference comments, are reported in Sections 4 (real-world settings) and 5 (controlled settings). We will revise the abstract to include one or two key quantitative highlights and a brief mention of baselines to better ground the central claims. revision: partial
-
Referee: [Method] Method (inferred from abstract description): the iterative refinement step treats mismatches between rubric-conditioned LLM predictions and reference comments as a sufficient, reliable signal for rubric improvement without additional labeled data or human oversight. No details are provided on rubric representation, mismatch quantification, or controls against degenerate solutions (e.g., overly vague or circular rubrics), which is load-bearing for the claim that expert criteria can be learned this way.
Authors: The method section (Section 3) specifies rubric representation as structured natural-language lists of criteria, mismatch quantification via a combination of exact-match accuracy and embedding-based semantic similarity between LLM-predicted comments and reference comments, and controls including prompt-based specificity constraints during refinement plus validation on held-out comment sets to mitigate vagueness or circularity. We agree these elements merit more explicit exposition and pseudocode. We will expand Section 3 with these details, including a description of the mismatch signal and degeneracy safeguards. revision: yes
Circularity Check
No significant circularity; derivation relies on external reference comments as ground truth
full rationale
The abstract and reader's summary describe a method that infers rubrics from inline comments and refines them using mismatches against independent reference comments. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations are present in the supplied text. The process treats reference comments as external ground truth rather than deriving outputs from the same fitted quantities by construction. This matches the default expectation of a self-contained approach against external benchmarks, warranting a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chin-Yew Lin
Curran Associates, Inc. Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81. Ying-Chun Lin, Jennifer Neville, Jack Stokes, Longqi Yang, Tara Safavi, Mengting Wan, Scott Counts, Sid- dharth Suri, Reid Andersen, Xiaofeng Xu, Deepak Gupta, Sujay Kumar Jauhar, Xia Song, Georg Buscher, Saur...
2004
-
[2]
InProceedings of the 14th International Conference on Natural Language Gen- eration, pages 320–324
Shared task on feedback comment generation for language learners. InProceedings of the 14th International Conference on Natural Language Gen- eration, pages 320–324. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. InProceedings of the 40th annual meeting of the Associati...
2002
-
[3]
Learning to retrieve prompts for in-context learning. InProceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technolo- gies, pages 2655–2671. Abdelrahman Sadallah, Tim Baumgärtner, Iryna Gurevych, and Ted Briscoe. 2025. The good, the bad and the constructive: Automatically measur...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
[retrieved comment 1]
retrieved comment: "[retrieved comment 1]", target_quote: "[retrieved target quote 1]", similarity=[score 1]
-
[5]
[retrieved comment 2]
retrieved comment: "[retrieved comment 2]", target_quote: "[retrieved target quote 2]", similarity=[score 2]
-
[6]
[retrieved comment 3]
retrieved comment: "[retrieved comment 3]", target_quote: "[retrieved target quote 3]", similarity=[score 3] The Top-3 RAG with LLM baseline uses the same fixed-position prompting setup as the main generation method described in Appendix D, with two modifications. First, the system instruction states that the prompt includes comments retrieved by similari...
2019
-
[7]
Comment:
Fostering Creativity and Innovation: How can holographic AI assistants foster creativity and innovation by enabling professionals to visualize and int" Comment: "This sub research question alone could be broad enough for a bachelors thesis. As said before, try and limit your scope significantly" Criterion 4: theoretical-framework, explanation (points = -1...
2024
-
[8]
Comment:
Fostering Creativity and Innovation: How can holographic AI assistants foster creativity and innovation by enabling professionals to visualize and int" Comment: "This sub research question alone could be broad enough for a bachelors thesis. As said before, try and limit your scope significantly" Example pair 2: Target: "n and healthcare? − What role does ...
-
[9]
3D Holographic and Interactive Artificial Intelligence System
and "3D Holographic and Interactive Artificial Intelligence System"[4] concerns the combinative application of both AI and holography to create dynamic, three−dimensional user interfaces. Works such as "Holographic AI Assistance" [3] further investigate integrating these" Comment: "In a SOTA section, you want to combine these different pieces of literatur...
-
[10]
Comment-trigger patterns (when a comment is made)
-
[11]
--- ## CORE PRINCIPLE Each rubric = a **specific, local issue pattern** that directly triggers a comment AND encodes why that issue is prioritized in the reference comments
Comment-selection behavior (why that specific comment is chosen over alternatives) The rubrics must be precise enough so that, when applied, the LLM selects the same type of comment as the reference comments. --- ## CORE PRINCIPLE Each rubric = a **specific, local issue pattern** that directly triggers a comment AND encodes why that issue is prioritized i...
-
[12]
What kinds of local statements, omissions, or structures tend to trigger comments
-
[13]
What EXACTLY is missing, unsupported, misleading, weakly scoped, or otherwise comment-worthy in those cases
-
[14]
What OTHER critiques could have been made in the same location
-
[15]
The artifact lacks specificity
Why the reference comments selected THIS critique instead of alternatives Your output should reflect actual reference-comment behavior, not ideal review standards. --- ## CRITICAL BEHAVIORAL RULES ### 1. Stay LOCAL (most important) Criteria must describe issues at the level of: - a sentence - a claim - a recommendation - a comparison - a specific mention,...
-
[16]
[[points]] [criterion text]
-
[17]
## Positions Requiring Comments ([M] positions):
[[points]] [criterion text] ... ## Positions Requiring Comments ([M] positions):
-
[18]
[target quote]
target_quote: "[target quote]"[, start=[start]][, end=[end]]
-
[19]
[target quote]
target_quote: "[target quote]"[, start=[start]][, end=[end]] ... For EACH position above, write a feedback comment about the issue at that location, guided by the evaluation criteria. Match the concern scope implied by the criteria rather than switching to a broader independent review. You MUST return exactly [M] comments, one per position. D.3 Comment Ev...
-
[20]
**Keep as-is**: A criterion repeatedly supports the right slot-level concern and leads to high content scores
-
[21]
Add stronger exclusion boundaries
**Narrow selection**: A criterion is cited for slots where the original comment clearly reflects a different concern. Add stronger exclusion boundaries
-
[22]
**Strengthen preferred selectors**: When the correct concern is present in the original slot comment but the generated comment drifts, make the intended selector more concrete and easier to choose
-
[23]
**Repair before adding**: First sharpen the boundaries among existing criteria before inventing a new one
-
[24]
**Add when needed for coverage**: If a recurring slot-level concern cannot be represented by repairing existing criteria, add it even if this increases rubric count
-
[25]
Do NOT remove a criterion solely for compactness if it covers a distinct observed concern
**Remove/merge carefully**: Remove or merge only when criteria are true duplicates or repeatedly add no distinct signal. Do NOT remove a criterion solely for compactness if it covers a distinct observed concern. IMPORTANT RULES: 1.`criterion`should describe a specific OBSERVABLE and LOCAL issue pattern in an artifact
-
[26]
Write them as descriptions of what IS in the artifact
DO NOT write criteria as "should" statements. Write them as descriptions of what IS in the artifact. 3.`criterion`must be SELF-CONTAINED. Encode the trigger, scope, exact concern, and important applicability or exclusion boundary directly inside `criterion`
-
[27]
When useful, encode why this criterion should win over a nearby broader criterion, or when it should NOT be selected for a slot
-
[28]
Leave`reasoning`as an empty string
Put all substantive rubric meaning in `criterion`. Leave`reasoning`as an empty string
-
[29]
7.`criterion`may be long and detailed
Put all important detail directly into `criterion`, not a separate explanation field. 7.`criterion`may be long and detailed. Around 100 words is acceptable when needed to make the trigger, issue type, and selector boundary explicit
-
[30]
select this when
Each criterion should explicitly encode a selector: - "select this when ..." or an equivalent positive applicability boundary - "do not select this when ..." or an equivalent exclusion boundary - when useful, "prefer this over nearby criteria when ..." - include a typical local pattern, statement shape, or recurring concrete situation where the criterion ...
-
[31]
If one rubric wrongly wins over another, repair both sides of the boundary: - narrow the wrongly selected rubric - strengthen the rubric that should have been selected
-
[32]
Prefer repairing selector boundaries of existing criteria over adding new criteria
-
[33]
If two criteria differ only by wording, local examples, or minor framing, merge them into one sharper criterion; if they represent distinct observed concerns, keep them separate
Cover the observed comment space. If two criteria differ only by wording, local examples, or minor framing, merge them into one sharper criterion; if they represent distinct observed concerns, keep them separate
-
[34]
Do not output any criterion that lacks at least one embedded concrete example pair
-
[35]
needs more detail
Stay close to the original concern and granularity; do NOT broaden into vague categories like "needs more detail" unless the concrete issue type is explicit. 14.`points`MUST be an integer from -10 to 10, excluding 0. 15.`tags`should categorize the criterion. SCORING LOGIC: 23 - When the criterion IS SATISFIED (the condition is present), the points are awa...
-
[36]
Select GLOBAL items whose concern/trigger could plausibly apply to any reasonable response to this prompt
-
[37]
For each selected global item, produce ONE OR MORE prompt-specific local entries. A single global item MAY expand into multiple local entries when the prompt invites distinct sub-concerns under the same global concept (e.g., different safety dimensions, different topics the response should cover, different expected actions); emit a separate entry per sub-...
-
[38]
items": [ {
Always record`source_index`as the 0-based index of the source item in the global rubric, for traceability. Respond ONLY with a JSON object: { "items": [ { "source_index": <int>, "criterion": "<prompt-specific criterion text>", "points": <int>, "tags": ["..."], "reasoning": "<why this applies and how it was specialized>" }, ... ], "reasoning": "<overall ra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.