Plan, Don't Pose: Long Composite Motion Generation with Text-Aligned BFM
Pith reviewed 2026-06-29 08:48 UTC · model grok-4.3
The pith
Text2BFM aligns language with frozen behavioral foundation models in a compressed latent manifold to generate long composite motions without direct pose synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
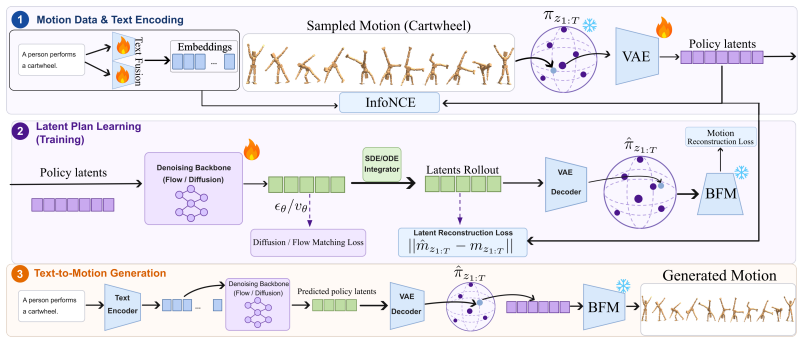
Text2BFM is the first framework that aligns natural language with pretrained Behavioral Foundation Models for T2M generation without relying on heavy end-to-end motion generators. It operates in the latent policy space of a frozen BFM, using a text-aligned variational behavioral bottleneck to compress policy-latent sequences into compact motion representations that remain compatible with language and preserve long-horizon behavioral structure. Generation occurs in this compact behavioral manifold with a lightweight conditional generator, after which the resulting latent encoded behaviors are decoded into policy latents that drive the pretrained frozen BFM.
What carries the argument
The text-aligned variational behavioral bottleneck, which compresses BFM policy-latent sequences into compact, language-compatible motion representations while preserving long-horizon behavioral structure.
If this is right
- Text2BFM achieves efficient and robust T2M generation by keeping the foundation model frozen.
- The method delivers strong performance on long, compositional textual descriptions.
- Semantic planning is decoupled from low-level motion execution.
- The frozen BFM serves as an executable motion prior without retraining.
Where Pith is reading between the lines
- Behavioral foundation models could be reused across multiple language-conditioned tasks by swapping only the bottleneck and generator.
- The same compression approach might extend to other sequential control domains where long-horizon structure must align with external instructions.
- Treating motion planning as a separate semantic compression step could reduce the need for ever-larger end-to-end models in animation and robotics.
Load-bearing premise
A variational bottleneck can compress BFM policy-latent sequences into compact representations that stay compatible with language while preserving the essential long-horizon behavioral structure.
What would settle it
Showing that motions produced for long compositional prompts either fail to follow the described action sequence or perform no better in coherence and efficiency than direct end-to-end pose generators.
Figures


read the original abstract
Text-to-motion (T2M) generation has broad applications in character animation, virtual avatars, and human-robot interaction. Existing methods typically generate pose trajectories or motion tokens directly from language, forcing a single model to handle semantic interpretation, long-horizon structure, and low-level physical realization. This coupling makes them costly and often unreliable for long, compositional, or semantically dense prompts. We propose Text2BFM, the first framework that aligns natural language with pretrained Behavioral Foundation Models (BFMs) for T2M generation without relying on heavy end-to-end motion generators. Text2BFM operates in the latent policy space of a frozen BFM, using it as an executable motion prior. A text-aligned variational behavioral bottleneck compresses BFM policy-latent sequences into compact motion representations that are compatible with language and preserve long-horizon behavioral structure. Generation is performed in this compact behavioral manifold with a lightweight conditional generator, and the resulting latent encoded behaviors are decoded into policy latents that drive the pretrained frozen BFM. By decoupling semantic planning from motion execution, Text2BFM achieves efficient, robust T2M generation and strong performance on long, compositional textual descriptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Text2BFM, the first framework to align natural language with pretrained Behavioral Foundation Models (BFMs) for text-to-motion (T2M) generation. It operates in the latent policy space of a frozen BFM as an executable prior, employing a text-aligned variational behavioral bottleneck to compress policy-latent sequences into compact, language-compatible motion representations that preserve long-horizon structure. A lightweight conditional generator performs planning in this manifold, with latents decoded to drive the BFM, thereby decoupling semantic planning from low-level motion execution for improved efficiency and robustness on long, compositional prompts.
Significance. If the text-aligned variational behavioral bottleneck demonstrably preserves long-horizon behavioral structure while maintaining language compatibility, the approach could offer a meaningful contribution to T2M by reducing reliance on end-to-end generators and leveraging frozen BFMs for scalable, robust generation of complex motions. The latent-planning pattern is standard but its application here to BFMs could enable more efficient handling of compositional text if empirically validated.
major comments (1)
- Abstract (paragraph describing the framework): The central claim that the text-aligned variational behavioral bottleneck 'compresses BFM policy-latent sequences into compact motion representations that are compatible with language and preserve long-horizon behavioral structure' is load-bearing yet unsupported by any equations, implementation details, metrics, ablations, or quantitative results in the manuscript, preventing evaluation of whether the compression actually achieves the stated preservation.
minor comments (1)
- Abstract: The term 'Behavioral Foundation Models (BFMs)' is introduced without a reference or prior definition, which may confuse readers unfamiliar with the specific pretrained models used.
Simulated Author's Rebuttal
We thank the referee for their review and the identification of a clarity issue in the abstract. We address the major comment below.
read point-by-point responses
-
Referee: Abstract (paragraph describing the framework): The central claim that the text-aligned variational behavioral bottleneck 'compresses BFM policy-latent sequences into compact motion representations that are compatible with language and preserve long-horizon behavioral structure' is load-bearing yet unsupported by any equations, implementation details, metrics, ablations, or quantitative results in the manuscript, preventing evaluation of whether the compression actually achieves the stated preservation.
Authors: The full manuscript contains the supporting material in Section 3 (Method), which derives the text-aligned variational behavioral bottleneck via an evidence lower bound that jointly enforces compression of policy-latent sequences and alignment to language embeddings, along with the decoding step that recovers executable behaviors from the frozen BFM. Section 4 reports quantitative ablations on bottleneck capacity, language-alignment metrics, and long-horizon coherence scores that directly evaluate preservation of behavioral structure. To make this support immediately visible from the abstract, we will insert a concise parenthetical reference to these sections and the key variational objective in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and framework description introduce Text2BFM as an architectural decoupling of semantic planning from motion execution via a text-aligned variational behavioral bottleneck operating on frozen BFM latents. No equations, fitted parameters, or predictions are presented that reduce by construction to inputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claim is a design pattern (latent-space planning) with no internal reduction to self-defined quantities or self-referential citations. This is self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained Behavioral Foundation Models exist and can serve as frozen executable motion priors.
invented entities (1)
-
Text-aligned variational behavioral bottleneck
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proto successor measure: Representing the behavior space of an RL agent
Siddhant Agarwal, Harshit Sikchi, Peter Stone, and Amy Zhang. Proto successor measure: Representing the behavior space of an RL agent. InF orty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=mUDnPzopZF
2025
-
[2]
Language2pose: Natural language grounded pose forecasting
Chaitanya Ahuja and Louis-Philippe Morency. Language2pose: Natural language grounded pose forecasting. In2019 International conference on 3D vision (3DV), pages 719–728. IEEE, 2019
2019
-
[3]
Albergo, Nicholas M
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInternational Conference on Learning Representations, 2023
2023
-
[4]
Hunt, Tom Schaul, Hado van Hasselt, and David Silver
André Barreto, Will Dabney, Rémi Munos, Jonathan J. Hunt, Tom Schaul, Hado van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[5]
Léonard Blier, Corentin Tallec, and Yann Ollivier. Learning successor states and goal-dependent values: A mathematical viewpoint.arXiv preprint arXiv:2101.07123, 2021
-
[6]
Maksim Bobrin, Ilya Zisman, Alexander Nikulin, Vladislav Kurenkov, and Dmitry V . Dylov. Zero-shot adaptation of behavioral foundation models to unseen dynamics. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=dBDBg4WF4F
2026
-
[7]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18000–18010, 2023
2023
-
[8]
Improving generalization for temporal difference learning: The successor repre- sentation.Neural Computation, 5(4):613–624, 1993
Peter Dayan. Improving generalization for temporal difference learning: The successor repre- sentation.Neural Computation, 5(4):613–624, 1993
1993
-
[9]
Go to zero: Towards zero-shot motion generation with million-scale data
Ke Fan, Shunlin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, and Jingbo Wang. Go to zero: Towards zero-shot motion generation with million-scale data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13336–13348, 2025
2025
-
[10]
Syn- thesis of compositional animations from textual descriptions
Anindita Ghosh, Noshaba Cheema, Cennet Oguz, Christian Theobalt, and Philipp Slusallek. Syn- thesis of compositional animations from textual descriptions. InProceedings of the IEEE/CVF international conference on computer vision, pages 1396–1406, 2021
2021
-
[11]
Hu- manML3D: A large and diverse 3d human motion-language dataset
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Hu- manML3D: A large and diverse 3d human motion-language dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5151–5160, 2022
2022
-
[12]
Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts. InEuropean Conference on Computer Vision, pages 580–597. Springer, 2022
2022
-
[13]
Momask: Generative masked modeling of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked modeling of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024
1900
-
[14]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations, 2014
2014
-
[15]
BFM-zero: A promptable behavioral foundation model for humanoid control using unsupervised reinforcement learning
Yitang Li, Zhengyi Luo, Tonghe Zhang, Cunxi Dai, Anssi Kanervisto, Andrea Tirinzoni, Haoyang Weng, Kris Kitani, Mateusz Guzek, Ahmed Touati, Alessandro Lazaric, Matteo Pirotta, and Guanya Shi. BFM-zero: A promptable behavioral foundation model for humanoid control using unsupervised reinforcement learning. InThe F ourteenth International Conference on Lea...
2026
-
[16]
Zeyu Ling, Shunlin Lu, Yuhong Zhang, et al. Motionllama: A unified framework for motion synthesis and comprehension.arXiv preprint arXiv:2411.17335, 2024. 11
-
[17]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
2023
-
[19]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Kris Kitani, Weipeng Xu, et al. Perpetual humanoid control for real-time simulated avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10895–10904, 2023
2023
-
[20]
Hierarchical motion generation with diffusion transformers
Ziyi Luo, Hongwen Yang, Xiaogang Wang, and Ziwei Liu. Hierarchical motion generation with diffusion transformers. InAdvances in Neural Information Processing Systems, 2024
2024
-
[21]
Troje, Gerard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. InInternational Conference on Computer Vision, pages 5442–5451, 2019
2019
-
[22]
MoMask: Hierarchi- cal masked 3d human motion generation.arXiv preprint arXiv:2312.04561, 2023
Shenghao Mo, Junting Zhang, Yuxiao Guo, Jingbo Wang, and Qifeng Liu. MoMask: Hierarchi- cal masked 3d human motion generation.arXiv preprint arXiv:2312.04561, 2023
-
[23]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
2023
-
[24]
AMP: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics, 40 (4):144:1–144:20, 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. AMP: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics, 40 (4):144:1–144:20, 2021
2021
-
[25]
ASE: Large-scale reusable adversarial skill embeddings for physically simulated characters.ACM Transactions on Graphics, 41(4):94:1–94:17, 2022
Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, and Sanja Fidler. ASE: Large-scale reusable adversarial skill embeddings for physically simulated characters.ACM Transactions on Graphics, 41(4):94:1–94:17, 2022
2022
-
[26]
Black, and Gül Varol
Mathis Petrovich, Michael J. Black, and Gül Varol. TEMOS: Generating diverse human motions from textual descriptions. InEuropean Conference on Computer Vision, pages 480–
-
[27]
Black, and Gül Varol
Mathis Petrovich, Michael J. Black, and Gül Varol. TMR: Text-to-motion retrieval using con- trastive 3d human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9488–9497, 2023
2023
-
[28]
The KIT motion-language dataset
Matthias Plappert, Christian Mandery, and Tamim Asfour. The KIT motion-language dataset. Big Data, 4(4):236–252, 2016. doi: 10.1089/big.2016.0028
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning, pages 8748–8763. PMLR, 2021
2021
-
[30]
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas J. Guibas. HuMoR: 3d human motion model for robust pose estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11488–11499, 2021
2021
-
[31]
InProceedings of the AAAI conference on artificial intelligence, Vol
Davis Rempe, Mathis Petrovich, Ye Yuan, Haotian Zhang, Xue Bin Peng, Yifeng Jiang, Tingwu Wang, Umar Iqbal, David Minor, Michael de Ruyter, Jiefeng Li, Chen Tessler, Edy Lim, Eugene Jeong, Sam Wu, Ehsan Hassani, Michael Huang, Jin-Bey Yu, Chaeyeon Chung, Lina Song, Olivier Dionne, Jan Kautz, Simon Yuen, and Sanja Fidler. Kimodo: Scaling controllable human...
-
[32]
Stochastic backpropagation and approximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. InInternational Conference on Machine Learning, pages 1278–1286, 2014. 12
2014
-
[33]
RL zero: Zero-shot language to behaviors without any supervision
Harshit Sikchi, Siddhant Agarwal, Pranaya Jajoo, Samyak Parajuli, Caleb Chuck, Max Rudolph, Peter Stone, Amy Zhang, and Scott Niekum. RL zero: Zero-shot language to behaviors without any supervision. In7th Robot Learning Workshop: Towards Robots with Human-Level Abilities,
-
[34]
URLhttps://openreview.net/forum?id=wNvuk13MnP
-
[35]
CALM: Conditional adversarial latent models for directable virtual characters
Chen Tessler, Yoni Kasten, Yunrong Guo, Shie Mannor, Gal Chechik, and Xue Bin Peng. CALM: Conditional adversarial latent models for directable virtual characters. InACM SIGGRAPH Conference Proceedings, 2023
2023
-
[36]
Bermano, and Daniel Cohen-Or
Guy Tevet, Brian Gordon, Amir Hertz, Amit H. Bermano, and Daniel Cohen-Or. MotionCLIP: Exposing human motion generation to CLIP space. InEuropean Conference on Computer Vision, pages 358–374. Springer, 2022
2022
-
[37]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H. Bermano. Human motion diffusion model. InInternational Conference on Learning Representations, 2023
2023
-
[38]
Zero-shot whole-body humanoid control via behavioral foundation models
Andrea Tirinzoni, Ahmed Touati, Jesse Farebrother, Mateusz Guzek, Anssi Kanervisto, Yingchen Xu, Alessandro Lazaric, and Matteo Pirotta. Zero-shot whole-body humanoid control via behavioral foundation models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=9sOR0nYLtz
2025
-
[39]
Learning one representation to optimize all rewards
Ahmed Touati and Yann Ollivier. Learning one representation to optimize all rewards. In Advances in Neural Information Processing Systems, volume 34, pages 13–24, 2021
2021
-
[40]
Does zero-shot reinforcement learning exist? InThe Eleventh International Conference on Learning Representations, 2023
Ahmed Touati, Jérémy Rapin, and Yann Ollivier. Does zero-shot reinforcement learning exist? InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=MYEap_OcQI
2023
-
[41]
Yuxin Wen, Qing Shuai, Di Kang, Jing Li, Cheng Wen, Yue Qian, Ningxin Jiao, Changhai Chen, Weijie Chen, Yiran Wang, et al. Hy-motion 1.0: Scaling flow matching models for text-to-motion generation.arXiv preprint arXiv:2512.23464, 2025
-
[42]
PhysDiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. PhysDiff: Physics-guided human motion diffusion model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16010–16021, 2023
2023
-
[43]
Generating human motion from textual descriptions with discrete representations
Jianrong Zhang, Yang Zhang, Xiaodong Cun, Yong Zhang, Hongwei Zhao, Hongtao Lu, Xi Shen, and Ying Shan. Generating human motion from textual descriptions with discrete representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14730–14740, 2023
2023
-
[44]
MotionDiffuse: Text-driven human motion generation with diffusion model
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xiaoyu Guo, Lei Yang, and Ziwei Liu. MotionDiffuse: Text-driven human motion generation with diffusion model. In Advances in Neural Information Processing Systems, volume 35, pages 12987–12999, 2022
2022
-
[45]
Remodiffuse: Retrieval-augmented motion diffusion model
Mingyuan Zhang, Xinying Guo, Liang Pan, Zhongang Cai, Fangzhou Hong, Huirong Li, Lei Yang, and Ziwei Liu. Remodiffuse: Retrieval-augmented motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 364–373, 2023. 13 A Technical Details and Hyperparameters Our method is trained in two stages: 1) semantic laten...
2023
-
[46]
Stage 2: Text-to-latent generator .A pretrained FB backbone is adapted to predict latent mo- tion sequences conditioned on text
The latent sequence m has stochastic posterior parameterization (µ,logσ 2) and reparameterized sampling. Stage 2: Text-to-latent generator .A pretrained FB backbone is adapted to predict latent mo- tion sequences conditioned on text. Optimization uses composite generation/reconstruction losses (including consistency in bothmandzspaces). Compute resources....
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.