Label Over Logic? How Source Cues Bias Human Fallacy Judgments More Than LLMs
Pith reviewed 2026-06-29 05:34 UTC · model grok-4.3
The pith
Humans judge logical fallacies more leniently when labeled as human-written than LLMs do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
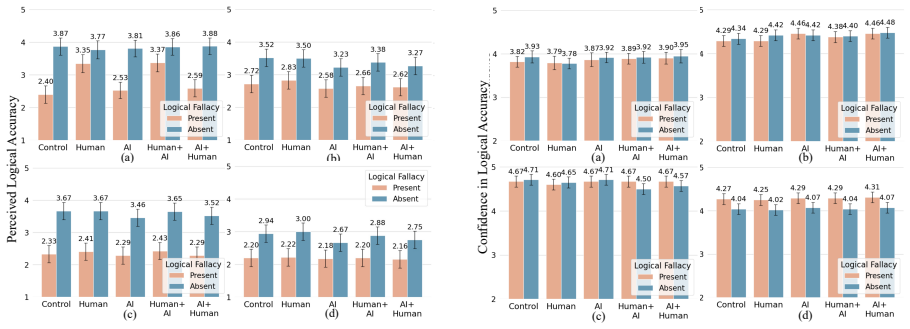
Human evaluators assigned higher trust and evaluation ratings to logically fallacious comments when labeled as written by a human or a human with AI assistance, while LLM evaluations remained stable across source labels including human, AI, human with AI assistance, AI with human assistance, and no disclosure.
What carries the argument
The source label attached to fallacious comments, manipulated across five conditions to isolate its effect on judgment accuracy for humans versus LLMs.
If this is right
- LLM evaluations of reasoning quality remain consistent when source information is present.
- Human evaluators require safeguards when source labels indicate human origin.
- Human-LLM collaboration can offset source bias in fallacy judgment tasks.
- Stability of evaluations differs across specific LLMs.
Where Pith is reading between the lines
- LLMs could serve as initial filters before human review in content moderation pipelines.
- Interventions that hide source labels might bring human detection rates closer to LLM levels.
- Moderation platforms may gain reliability by routing source-labeled items first through LLMs.
Load-bearing premise
The logical fallacies are equivalent in strength and type across all source label conditions.
What would settle it
A replication study using the same comments where humans show equal fallacy detection rates across all source labels.
Figures




read the original abstract
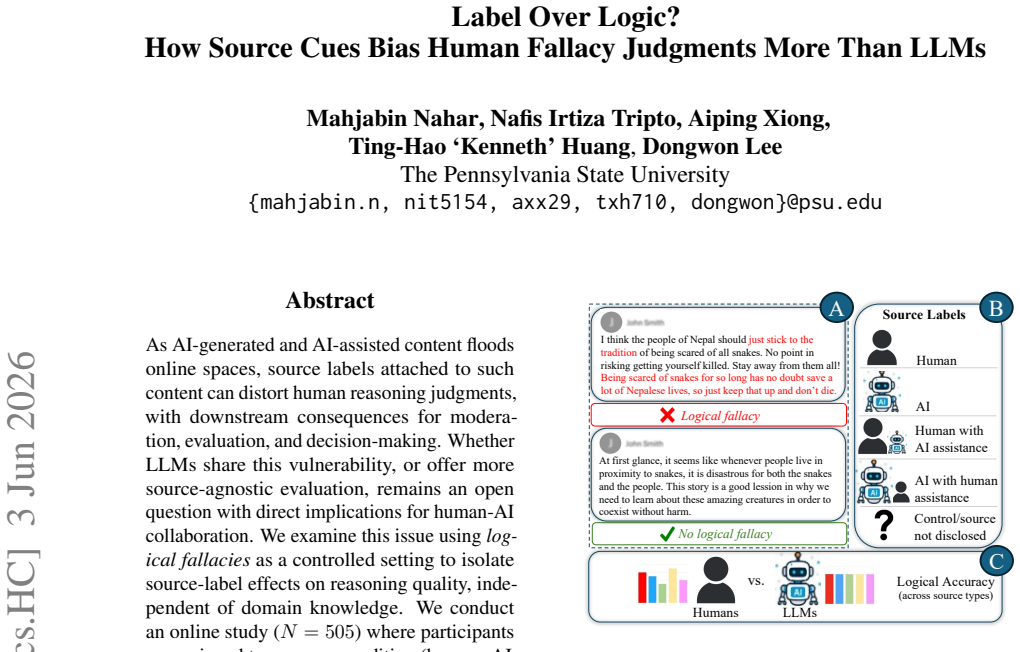
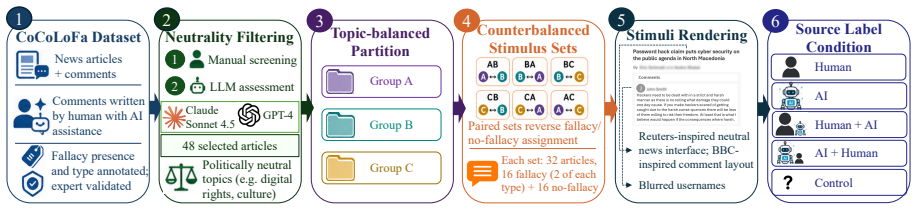
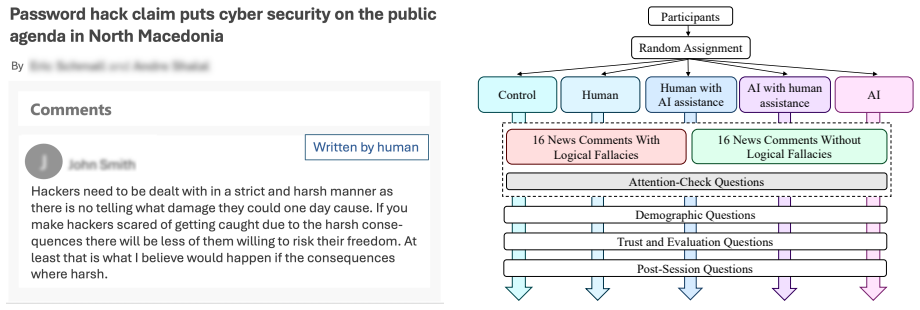
As AI-generated and AI-assisted content floods online spaces, source labels attached to such content can distort human reasoning judgments, with downstream consequences for moderation, evaluation, and decision-making. Whether LLMs share this vulnerability, or offer more source-agnostic evaluation, remains an open question with direct implications for human-AI collaboration. We examine this issue using logical fallacies as a controlled setting to isolate source-label effects on reasoning quality, independent of domain knowledge. We conduct an online study (N=505) where participants are assigned to a source condition (human, AI, human with AI assistance, AI with human assistance, or no disclosure) and evaluate comments containing logical fallacies, comparing their judgments with those of LLMs (GPT-5.2, Gemini 2.5 Flash, Claude Sonnet 4.5), who were evaluated across the same source conditions. Human evaluators were significantly more susceptible to fallacies labeled as written by human or human with AI assistance and assigned higher trust and evaluation ratings in these conditions. LLM evaluations remained comparatively stable across source labels, though performance varied across models. Confidence levels were similarly high across conditions for both humans and LLMs, regardless of fallacy presence. Our findings indicate that source-label bias in reasoning evaluation is primarily a human vulnerability and highlight the potential of human-LLM collaboration in increasingly AI-mediated environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from an online study (N=505) in which participants evaluated comments containing logical fallacies under five source-label conditions (human, AI, human with AI assistance, AI with human assistance, no disclosure). Human evaluators showed greater susceptibility to fallacies and assigned higher trust/evaluation ratings when comments were labeled as human-authored or human+AI, while LLM evaluators (GPT-5.2, Gemini 2.5 Flash, Claude Sonnet 4.5) produced more stable judgments across labels. The design uses logical fallacies to isolate source-label effects independent of domain knowledge, with the central claim that source bias is primarily a human vulnerability.
Significance. If the stimulus-equivalence assumption holds and the statistical results are robust, the work provides evidence that LLMs can offer more source-agnostic evaluation than humans in fallacy detection, with implications for moderation pipelines and human-AI collaboration. The empirical comparison across multiple models and the large human sample are strengths.
major comments (2)
- [Methods] Methods section: the claim that the design isolates source-label effects 'independent of domain knowledge' rests on the unverified assumption that fallacious comments are equivalent in subtlety, length, and difficulty across the five label conditions. No pre-test equivalence ratings, stimulus counterbalancing procedure, or post-hoc checks for confounds are described; if distinct comments were generated or selected per condition, the reported human bias difference is confounded.
- [Results] Results section: the abstract states that humans were 'significantly more susceptible' and assigned 'higher trust and evaluation ratings' but supplies no statistical tests, effect sizes, exclusion criteria, or control variables. Without these details the support for the central human-vs-LLM contrast cannot be evaluated.
minor comments (2)
- [Abstract] Abstract and Methods: model version numbers (GPT-5.2, Claude Sonnet 4.5) should be clarified or footnoted if they refer to hypothetical or internal versions rather than publicly released models.
- [Results] Figure or table reporting LLM vs. human ratings: axis labels and error bars should be added for direct visual comparison of stability across conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our methods and results. We address each point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods] Methods section: the claim that the design isolates source-label effects 'independent of domain knowledge' rests on the unverified assumption that fallacious comments are equivalent in subtlety, length, and difficulty across the five label conditions. No pre-test equivalence ratings, stimulus counterbalancing procedure, or post-hoc checks for confounds are described; if distinct comments were generated or selected per condition, the reported human bias difference is confounded.
Authors: We agree that the manuscript should provide more explicit documentation on stimulus construction. All fallacious comments were generated from a common template set with matched length and fallacy type, then randomly assigned to label conditions. No pre-test equivalence ratings were collected. We will expand the Methods section with a full description of the generation procedure, randomization process, and any available post-hoc length/complexity checks. revision: yes
-
Referee: [Results] Results section: the abstract states that humans were 'significantly more susceptible' and assigned 'higher trust and evaluation ratings' but supplies no statistical tests, effect sizes, exclusion criteria, or control variables. Without these details the support for the central human-vs-LLM contrast cannot be evaluated.
Authors: The full Results section reports the relevant statistical tests (including ANOVA and follow-up contrasts), effect sizes, exclusion criteria based on attention checks, and control variables. We acknowledge that the abstract omits these details. We will revise the abstract to include the key statistical results supporting the human-LLM comparison. revision: yes
Circularity Check
No circularity: purely empirical study with no derivation chain
full rationale
The paper reports results from an online experiment (N=505) comparing human and LLM fallacy judgments under source-label conditions. No equations, fitted parameters, predictions, or first-principles derivations are present. Claims rest on direct statistical comparisons of ratings across conditions rather than any internal reduction or self-referential construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results occur. The design choice to use logical fallacies as stimuli is a methodological control, not a circular input-output equivalence. This is the expected outcome for an empirical HCI study without theoretical modeling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Ad Fontes Media . 2026. Reuters bias and reliability. https://adfontesmedia.com/reuters-bias-and-reliability/. [Online; last accessed 05/22/2026]
2026
-
[4]
AllSides . 2021. Reuters fact check. https://www.allsides.com/news-source/reuters-fact-check-media-bias. [Online; last accessed 05/22/2026]
2021
-
[5]
Anthropic. 2025. Introducing claude sonnet 4.5. https://www.anthropic.com/news/claude-sonnet-4-5. Accessed: 2026-04-08
2025
-
[6]
Cheng Chen and S Shyam Sundar. 2023. Is this ai trained on credible data? the effects of labeling quality and performance bias on user trust. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1--11
2023
-
[7]
Serena Chen and Shelly Chaiken. 1999. The heuristic-systematic. Dual-process theories in social psychology, 73
1999
-
[8]
Yanran Chen, Lynn Greschner, Roman Klinger, Michael Klenk, and Steffen Eger. 2026. Emotionally charged, logically blurred: Ai-driven emotional framing impairs human fallacy detection. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6709--6732
2026
-
[9]
Inyoung Cheong, Alicia Guo, Mina Lee, Zhehui Liao, Kowe Kadoma, Dongyoung Go, Joseph Chee Chang, Peter Henderson, Mor Naaman, and Amy X Zhang. 2025. Penalizing transparency? how ai disclosure and author demographics shape human and ai judgments about writing. arXiv preprint arXiv:2507.01418
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Amy JC Cuddy, Susan T Fiske, and Peter Glick. 2008. Warmth and competence as universal dimensions of social perception: The stereotype content model and the bias map. Advances in experimental social psychology, 40:61--149
2008
-
[12]
Yue Dai, Jiyoung Lee, and Ji Won Kim. 2024. Ai vs. human voices: How delivery source and narrative format influence the effectiveness of persuasion messages. International Journal of Human--Computer Interaction, 40(24):8735--8749
2024
-
[13]
Benjamin D Douglas, Patrick J Ewell, and Markus Brauer. 2023. Data quality in online human-subjects research: Comparisons between mturk, prolific, cloudresearch, qualtrics, and sona. Plos one, 18(3):e0279720
2023
-
[14]
Itiel E Dror. 2020. Cognitive and human factors in expert decision making: six fallacies and the eight sources of bias. Analytical chemistry, 92(12):7998--8004
2020
-
[15]
Franz Faul, Edgar Erdfelder, Axel Buchner, and Albert-Georg Lang. 2009. Statistical power analyses using g* power 3.1: Tests for correlation and regression analyses. Behavior research methods, 41(4):1149--1160
2009
-
[16]
Susan T Fiske, Amy JC Cuddy, Peter Glick, and Jun Xu. 2018. A model of (often mixed) stereotype content: Competence and warmth respectively follow from perceived status and competition. In Social cognition, pages 162--214. Routledge
2018
-
[17]
Isabel O Gallegos, Chen Shani, Weiyan Shi, Federico Bianchi, Izzy Gainsburg, Dan Jurafsky, and Robb Willer. 2026. Labeling messages as ai-generated does not reduce their persuasive effects. PNAS nexus, 5(2):pgag008
2026
-
[18]
Graham R Gibbs. 2007. Thematic coding and categorizing. Analyzing qualitative data, 703(38-56)
2007
-
[19]
Josh A Goldstein, Jason Chao, Shelby Grossman, Alex Stamos, and Michael Tomz. 2024. How persuasive is ai-generated propaganda? PNAS nexus, 3(2):pgae034
2024
-
[20]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, and 1 others. 2024. A survey on llm-as-a-judge. The Innovation
2024
-
[21]
Chadi Helwe, Tom Calamai, Pierre-Henri Paris, Chlo \'e Clavel, and Fabian Suchanek. 2024. Mafalda: A benchmark and comprehensive study of fallacy detection and classification. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4810--4845
2024
-
[22]
David M Howcroft and Verena Rieser. 2021. What happens if you treat ordinal ratings as interval data? human evaluations in nlp are even more under-powered than you think. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 8932--8939
2021
-
[23]
Timon MJ Hruschka and Markus Appel. 2023. Learning about informal fallacies and the detection of fake news: An experimental intervention. PLoS One, 18(3):e0283238
2023
-
[24]
Gagan Jain, Samridhi Pareek, and Per Carlbring. 2024. Revealing the source: How awareness alters perceptions of ai and human-generated mental health responses. Internet Interventions, 36:100745
2024
-
[25]
Jiwon Jeong, Hyeju Jang, and Hogun Park. 2025. Large language models are better logical fallacy reasoners with counterargument, explanation, and goal-aware prompt formulation. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 6918--6937
2025
-
[26]
Haiyan Jia, Alyssa Appelman, Mu Wu, and Steve Bien-Aime. 2024. News bylines and perceived ai authorship: Effects on source and message credibility. Computers in Human Behavior: Artificial Humans, 2(2):100093
2024
-
[27]
Zhijing Jin, Abhinav Lalwani, Tejas Vaidhya, Xiaoyu Shen, Yiwen Ding, Zhiheng Lyu, Mrinmaya Sachan, Rada Mihalcea, and Bernhard Schoelkopf. 2022. Logical fallacy detection. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 7180--7198
2022
-
[28]
Devon Johnson and Kent Grayson. 2005. Cognitive and affective trust in service relationships. Journal of Business research, 58(4):500--507
2005
-
[29]
Artur Klingbeil, Cassandra Gr \"u tzner, and Philipp Schreck. 2024. Trust and reliance on ai—an experimental study on the extent and costs of overreliance on ai. Computers in Human Behavior, 160:108352
2024
-
[30]
Deepak Kumar, Yousef Anees AbuHashem, and Zakir Durumeric. 2024. Watch your language: Investigating content moderation with large language models. In Proceedings of the International AAAI Conference on Web and Social Media, volume 18, pages 865--878
2024
-
[31]
Alexandra Kuznetsova, Per B Brockhoff, and Rune HB Christensen. 2017. lmertest package: tests in linear mixed effects models. Journal of statistical software, 82:1--26
2017
-
[32]
Dani \"e l Lakens. 2013. Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and anovas. Frontiers in psychology, 4:62627
2013
-
[33]
Fan Li, Ya Yang, and Guoming Yu. 2025. Nudging perceived credibility: The impact of aigc labeling on user distinction of ai-generated content. Emerging Media, 3(2):275--304
2025
-
[34]
Zhuoyan Li, Chen Liang, Jing Peng, and Ming Yin. 2024. How does the disclosure of ai assistance affect the perceptions of writing? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4849--4868
2024
-
[35]
Sue Lim and Ralf Schm \"a lzle. 2024. The effect of source disclosure on evaluation of ai-generated messages. Computers in Human Behavior: Artificial Humans, 2(1):100058
2024
-
[36]
Teng Lin and Yiqing Zhang. 2026. Visible sources and invisible risks: exploring the impact of ai disclosure on perceived credibility of ai-generated content. Journal of Science Communication, 25(1):A09
2026
-
[37]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: Nlg evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 2511--2522
2023
-
[38]
Jennifer M Logg, Julia A Minson, and Don A Moore. 2019. Algorithm appreciation: People prefer algorithmic to human judgment. Organizational behavior and human decision processes, 151:90--103
2019
-
[39]
Marketing Tech News . 2025. Instagram tests ai-generated comments to boost engagement. https://www.marketingtechnews.net/news/instagram-tests-ai-generated-comments-to-boost-engagement/. [Author: Muhammad Zulhusni; Online; last accessed 04/08/2026]
2025
-
[40]
Mahjabin Nahar, Eun-Ju Lee, Jin Won Park, and Dongwon Lee. 2025. Catch me if you search: When contextual web search results affect the detection of hallucinations. Computers in Human Behavior, page 108763
2025
-
[41]
Mahjabin Nahar, Haeseung Seo, Eun-Ju Lee, Aiping Xiong, and Dongwon Lee. 2024. Fakes of varying shades: How warning affects human perception and engagement regarding llm hallucinations. First Conference on Language Modeling (COLM)
2024
-
[42]
Daniel J O'Keefe. 2008. Elaboration likelihood model. The International Encyclopedia of Communication
2008
-
[43]
Qian Pan, Zahra Ashktorab, Michael Desmond, Martin Santillan Cooper, James Johnson, Rahul Nair, Elizabeth Daly, and Werner Geyer. 2024. Human-centered design recommendations for llm-as-a-judge. In Proceedings of the 1st Human-Centered Large Language Modeling Workshop, pages 16--29
2024
-
[44]
Junyeong Park, Seogyeong Jeong, Seyoung Song, Yohan Lee, and Alice Oh. 2025. Llm-c3mod: A human-llm collaborative system for cross-cultural hate speech moderation. In Proceedings of the 3rd Workshop on Cross-Cultural Considerations in NLP (C3NLP 2025), pages 71--88
2025
-
[45]
Amirreza Payandeh, Dan Pluth, Jordan Hosier, Xuesu Xiao, and Vijay K Gurbani. 2024. How susceptible are llms to logical fallacies? In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 8276--8286
2024
-
[46]
Gordon Pennycook, Jonathon McPhetres, Yunhao Zhang, Jackson G Lu, and David G Rand. 2020. Fighting covid-19 misinformation on social media: Experimental evidence for a scalable accuracy-nudge intervention. Psychological science, 31(7):770--780
2020
-
[47]
Gordon Pennycook and David G Rand. 2021. The psychology of fake news. Trends in cognitive sciences, 25(5):388--402
2021
-
[48]
Irene Rae. 2024. The effects of perceived ai use on content perceptions. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1--14
2024
-
[49]
Saumya Sahai, Oana Balalau, and Roxana Horincar. 2021. Breaking down the invisible wall of informal fallacies in online discussions. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 644--657
2021
-
[50]
Sha Sajadieh, Loredana Fattorini, Raymond Perrault, Yolanda Gil, Vanessa Parli, Lapo Santarlasci, Juan Pava, Nestor Maslej, Russ Altman, Erik Brynjolfsson, Carla Brodley, Jack Clark, Virginia Dignum, Vipin Kumar, James Landay, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, and 4 others. 2026. https://aiindex.stanford.edu/report/ The AI Inde...
2026
-
[51]
Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti, and Robert West. 2025. On the conversational persuasiveness of gpt-4. Nature Human Behaviour, 9(8):1645--1653
2025
-
[52]
Barry R Schlenker, Bob Helm, and James T Tedeschi. 1973. The effects of personality and situational variables on behavioral trust. Journal of personality and social psychology, 25(3):419
1973
-
[53]
Hendrik Schuff, Hsiu-Yu Yang, Heike Adel, and Ngoc Thang Vu. 2021. Does external knowledge help explainable natural language inference? automatic evaluation vs. human ratings. In Proceedings of the fourth BlackboxNLP workshop on analyzing and interpreting neural networks for NLP, pages 26--41
2021
-
[54]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 others. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Zhivar Sourati, Vishnu Priya Prasanna Venkatesh, Darshan Deshpande, Himanshu Rawlani, Filip Ilievski, H \^o ng- \^A n Sandlin, and Alain Mermoud. 2023. Robust and explainable identification of logical fallacies in natural language arguments. Knowledge-Based Systems, 266:110418
2023
-
[56]
Giovanni Spitale, Nikola Biller-Andorno, and Federico Germani. 2023. Ai model gpt-3 (dis) informs us better than humans. Science Advances, 9(26):eadh1850
2023
-
[57]
Stanford Encyclopedia of Philosophy . 2024. Fallacies. https://plato.stanford.edu/entries/fallacies/. [Online; last accessed 05/22/2026]
2024
- [58]
-
[59]
Xin Sun, Di Wu, Sijing Qin, Isao Echizen, Abdallah El Ali, and Saku Sugawara. 2026. Label effects: Shared heuristic reliance in trust assessment by humans and llm-as-a-judge. arXiv preprint arXiv:2604.05593
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Zhen Sun, Zongmin Zhang, Xinyue Shen, Ziyi Zhang, Yule Liu, Michael Backes, Yang Zhang, and Xinlei He. 2025 b . Are we in the ai-generated text world already? quantifying and monitoring aigt on social media. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22975--23005
2025
-
[61]
The Verge . 2025. Reddit bans researchers who used ai bots to manipulate commenters. https://www.theverge.com/ai-artificial-intelligence/657978/reddit-ai-experiment-banned. [Author: Marina Galperina; Online; last accessed 04/08/2026]
2025
-
[62]
Alexander Todorov, Shelly Chaiken, and Marlone D Henderson. 2002. The heuristic-systematic model of social information processing. The persuasion handbook: Developments in theory and practice, 23:195--211
2002
-
[63]
Douglas N. Walton. 1987. https://doi.org/10.1075/pbcs.4 Informal fallacies . Pragmatics & Beyond Companion Series
-
[64]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
- [65]
-
[66]
Min-Hsuan Yeh, Ruyuan Wan, and Ting-Hao Huang. 2024. Cocolofa: A dataset of news comments with common logical fallacies written by llm-assisted crowds. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 660--677
2024
-
[67]
Guanglu Zhang, Leah Chong, Kenneth Kotovsky, and Jonathan Cagan. 2023. Trust in an ai versus a human teammate: The effects of teammate identity and performance on human-ai cooperation. Computers in Human Behavior, 139:107536
2023
-
[68]
Yunhao Zhang and Ren \'e e Gosline. 2023. Human favoritism, not ai aversion: People’s perceptions (and bias) toward generative ai, human experts, and human--gai collaboration in persuasive content generation. Judgment and Decision Making, 18:e41
2023
-
[69]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595--46623
2023
-
[70]
Yingfan Zhou, Ester Chen, Manasa Pisipati, Aiping Xiong, and Sarah Rajtmajer. 2025. Effect of ai performance, risk perception, and trust on human dependence in deepfake detection ai system. Proceedings of the ACM on Human-Computer Interaction, 9(7):1--24
2025
-
[71]
Tiffany Zhu, Iain Weissburg, Kexun Zhang, and William Yang Wang. 2025. Human bias in the face of ai: Examining human judgment against text labeled as ai generated. In Findings of the Association for Computational Linguistics: ACL 2025, pages 25907--25914
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.