CLUBench: A Clustering Benchmark
Pith reviewed 2026-06-29 08:33 UTC · model grok-4.3
The pith
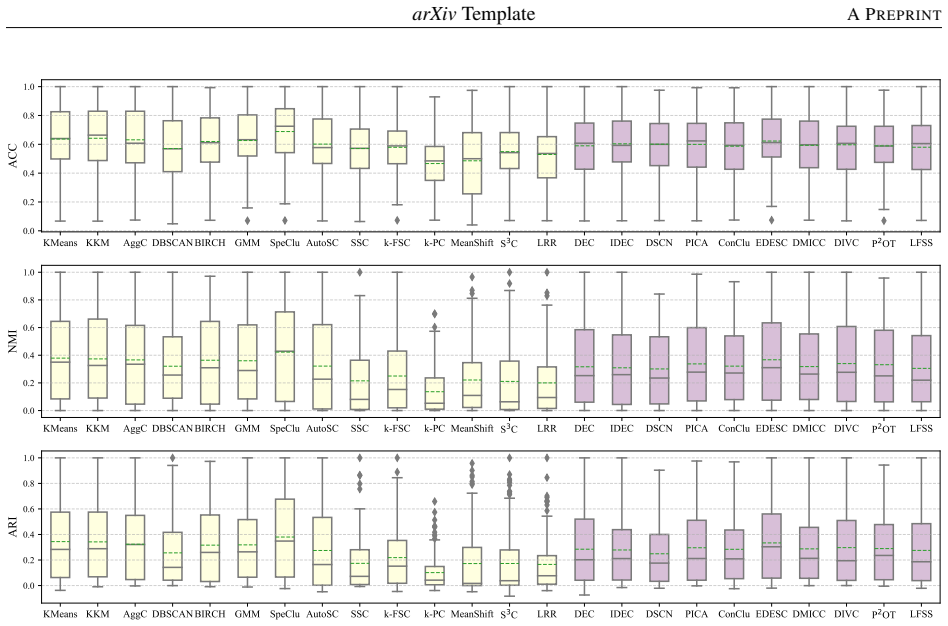
Deep clustering methods show no significant average advantage over top conventional algorithms like KMeans across 131 datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
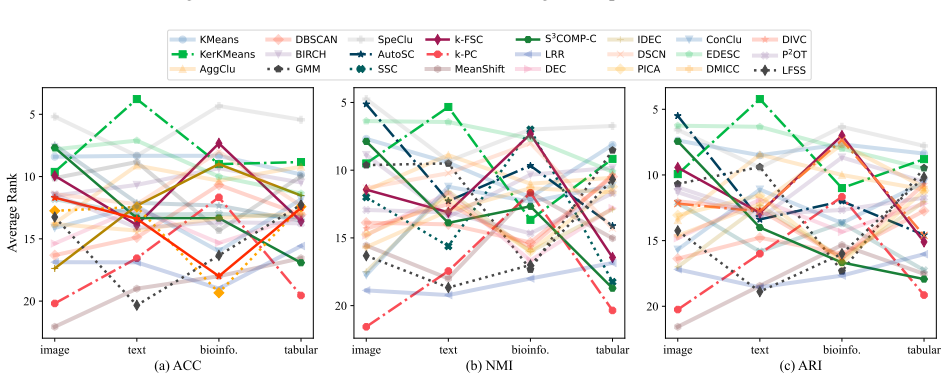
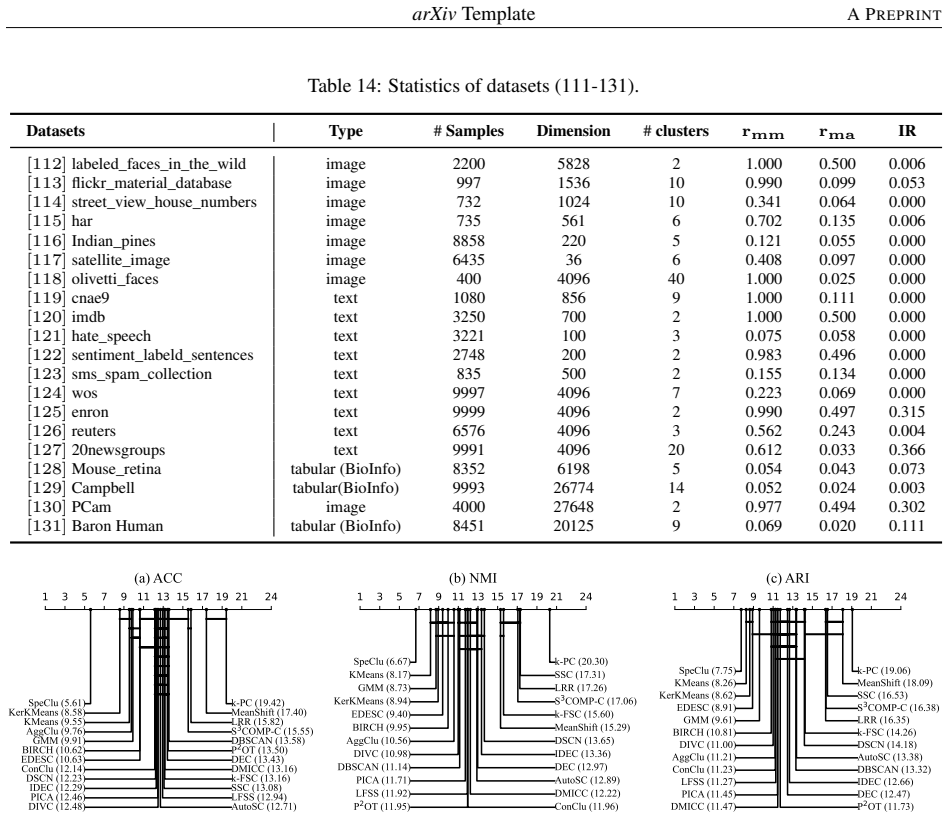
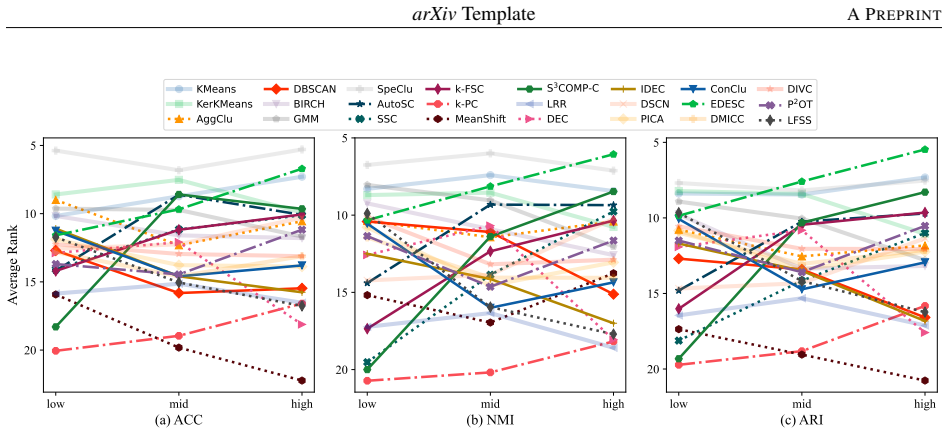
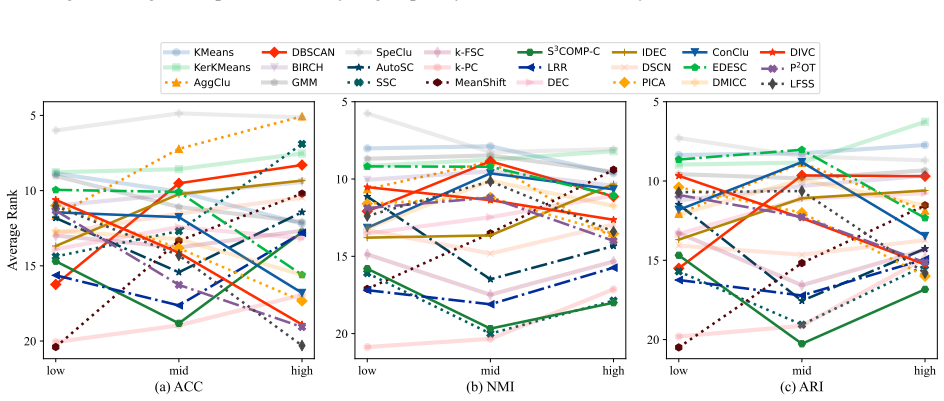
CLUBench evaluates 24 algorithms of varied principles on 131 datasets via 178,815 experiments and finds that deep clustering methods lack a significant performance advantage over top conventional algorithms such as KMeans and SpeClu on average, that pretrained embeddings combined with conventional methods work effectively for image and text clustering, and that low-rank structures in cross-model performance matrices support efficient approximation of overall performance and model selection across hyperparameter configurations.
What carries the argument
The CLUBench benchmark, which runs comprehensive comparisons of conventional, deep, and foundation-model clustering methods on diverse datasets while examining hyperparameter tuning, data type impacts, pretrained embeddings, and low-rank performance matrix structures.
If this is right
- Conventional algorithms such as KMeans and SpeClu remain competitive baselines for general clustering tasks.
- Pretrained embeddings paired with conventional methods offer an effective route for image and text clustering without needing specialized deep clustering networks.
- Low-rank structure in performance matrices can reduce the computational cost of full cross-algorithm evaluations.
- Clustering performance matrices across hyperparameter settings enable practical model selection without exhaustive testing on every new dataset.
Where Pith is reading between the lines
- Future work could test whether the observed performance patterns hold when datasets are drawn from domains underrepresented in the current collection, such as time-series or graph data.
- The similarity analysis among algorithms might support the development of automated algorithm recommendation systems based on data characteristics alone.
- If low-rank approximations prove reliable, practitioners could evaluate only a small subset of configurations and still estimate full benchmark rankings accurately.
Load-bearing premise
The 131 datasets, chosen metrics, and hyperparameter tuning procedures fairly represent the space of practical clustering problems and allow equitable comparison across algorithm families.
What would settle it
A new collection of datasets or metrics where deep clustering methods show a consistent and sizable average performance gain over the best conventional algorithms would falsify the central performance claim.
Figures
read the original abstract
Clustering is a fundamental problem in data science with a long-standing research history, yielding numerous insightful algorithms. Despite this progress, a systematic and large-scale empirical evaluation that jointly considers conventional algorithms, deep learning-based methods, and recent foundation model-based clustering remains largely absent, leading to limited guidance on algorithm selection and deployment. To address this gap, we introduce CLUBench, a comprehensive clustering benchmark comprising 24 algorithms of diverse principles evaluated on 131 datasets across tabular, text, and image data, involving 178,815 experiments. Importantly, our analyses of (i) the impact of hyperparameter tuning,(ii) the impact of data types and characteristics,(iii) the impact of pretrained embeddings,(iv) large language model-based clustering,(v) the similarity of algorithms, and (vi) the low-rank structures of performance matrices, yield meaningful insights and promising pathways for clustering research. For instance, our study reveals that: 1) All evaluated deep clustering methods do not exhibit a significant advantage compared with the top-performing conventional clustering algorithms (e.g., KMeans, SpeClu) in terms of average performance; 2) For image and text clustering tasks, combining pretrained embeddings with conventional clustering algorithms (e.g., KMeans, SpeClu) offers effective and efficient clustering; 3) Clustering remains a challenging and nontrivial problem, even in the era of increasingly dominant foundation models. Moreover, we propose to use the low-rank structure in cross-model performance matrices to efficiently approximate the overall performance evaluation in practical applications. We further demonstrate the feasibility of model selection based on the performance matrices across all hyperparameter configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLUBench, a benchmark evaluating 24 clustering algorithms (conventional, deep learning-based, and foundation model-based) across 131 datasets spanning tabular, text, and image modalities via 178,815 experiments. It analyzes the effects of hyperparameter tuning, data characteristics, pretrained embeddings, LLM-based clustering, algorithm similarities, and low-rank structures in performance matrices. Central claims include that deep clustering methods show no significant average-performance advantage over top conventional methods (e.g., KMeans, spectral clustering), that pretrained embeddings paired with conventional algorithms are effective for image/text tasks, and that clustering remains challenging even with foundation models; the work also proposes low-rank approximations for efficient performance estimation.
Significance. If the fairness of comparisons holds, this large-scale empirical study supplies practical guidance on algorithm selection and challenges the presumed superiority of deep methods, while the low-rank structure proposal offers a methodological tool for scalable benchmarking. The experiment volume and multi-modal coverage constitute a clear strength for the field.
major comments (2)
- [Analysis (i)] Analysis (i) on the impact of hyperparameter tuning: the manuscript provides no quantitative details on trial counts per algorithm family, search strategy (grid/random/Bayesian), or normalization of tuning budgets between deep methods (with large spaces for learning rates, architectures, regularization) and conventional methods (e.g., KMeans). This is load-bearing for the headline claim that deep methods exhibit no significant advantage, because unequal optimization effort could artifactually favor simpler conventional algorithms.
- [Benchmark construction] Benchmark construction and dataset curation: exact selection criteria for the 131 datasets, inclusion of statistical testing for performance differences, and confirmation that hyperparameter search spaces were matched are absent from the provided description. These omissions directly affect verifiability of the cross-family average-performance comparisons that underpin the main conclusions.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly noting whether performance differences were assessed with statistical tests and the precise hyperparameter budget protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of reproducibility and fairness in our empirical comparisons. We address each major comment below and will incorporate the requested details into a revised manuscript.
read point-by-point responses
-
Referee: [Analysis (i)] Analysis (i) on the impact of hyperparameter tuning: the manuscript provides no quantitative details on trial counts per algorithm family, search strategy (grid/random/Bayesian), or normalization of tuning budgets between deep methods (with large spaces for learning rates, architectures, regularization) and conventional methods (e.g., KMeans). This is load-bearing for the headline claim that deep methods exhibit no significant advantage, because unequal optimization effort could artifactually favor simpler conventional algorithms.
Authors: We agree that quantitative details on the hyperparameter tuning process are necessary to support the fairness of our comparisons. The original manuscript described the overall experimental setup but omitted explicit trial counts, search strategies, and budget normalization. In the revision we will add a new subsection (and accompanying table) that reports: (i) the number of trials allocated to each algorithm family, (ii) the search strategy used (random search with fixed evaluation budgets), and (iii) how total computational budgets were equalized across deep and conventional methods by limiting the number of model evaluations rather than wall-clock time. This addition will directly address the concern that unequal optimization effort may have biased results toward simpler algorithms. revision: yes
-
Referee: [Benchmark construction] Benchmark construction and dataset curation: exact selection criteria for the 131 datasets, inclusion of statistical testing for performance differences, and confirmation that hyperparameter search spaces were matched are absent from the provided description. These omissions directly affect verifiability of the cross-family average-performance comparisons that underpin the main conclusions.
Authors: We acknowledge that the manuscript description of dataset curation and statistical analysis is incomplete. In the revision we will expand the 'Datasets' and 'Experimental Setup' sections to provide: (i) the precise inclusion criteria and sources used to select the 131 datasets, (ii) results of statistical significance tests (paired Wilcoxon signed-rank tests with Bonferroni correction) comparing average performance across algorithm families, and (iii) an explicit statement that hyperparameter search spaces were constructed to be comparable in terms of the number of configurations evaluated per method. These additions will improve verifiability of the cross-family comparisons. revision: yes
Circularity Check
Purely empirical benchmark; no derivations or self-referential predictions
full rationale
This is a large-scale empirical benchmark paper that reports performance numbers from 178k experiments across 131 datasets and 24 algorithms. It contains no mathematical derivations, uniqueness theorems, ansatzes, or predictions that reduce to quantities fitted inside the paper. All claims (e.g., deep methods showing no significant average advantage) are direct empirical observations from the collected results rather than constructed equivalences. Self-citations, if present, are not load-bearing for any central result. The paper is therefore self-contained against external benchmarks with score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard external clustering metrics (NMI, ARI, etc.) provide a fair basis for cross-algorithm comparison.
- domain assumption The 131 datasets collectively represent the range of tabular, text, and image clustering tasks encountered in practice.
Reference graph
Works this paper leans on
-
[1]
URLhttps://ojs.aaai.org/index.php/AAAI/article/view/5867
doi:10.1609/aaai.v34i04.5867. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/5867. Uno Fang, Man Li, Jianxin Li, Longxiang Gao, Tao Jia, and Yanchun Zhang. A comprehensive survey on multi-view clustering.IEEE Transactions on Knowledge and Data Engineering, 35(12):12350–12368, 2023. doi:10.1109/TKDE.2023.3270311. Jie Chen, Hua Mao, Wai Lok Woo, and Xi...
-
[2]
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders
doi:10.1038/s41586-024-08328-6. URLhttps://www.nature.com/articles/s41586-024-08328-6. Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008. Emmanuel Candes and Benjamin Recht. Exact matrix completion via convex optimization.Communications of the ACM, 55(6):111–119, 2012. Yu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-024-08328-6 2008
-
[3]
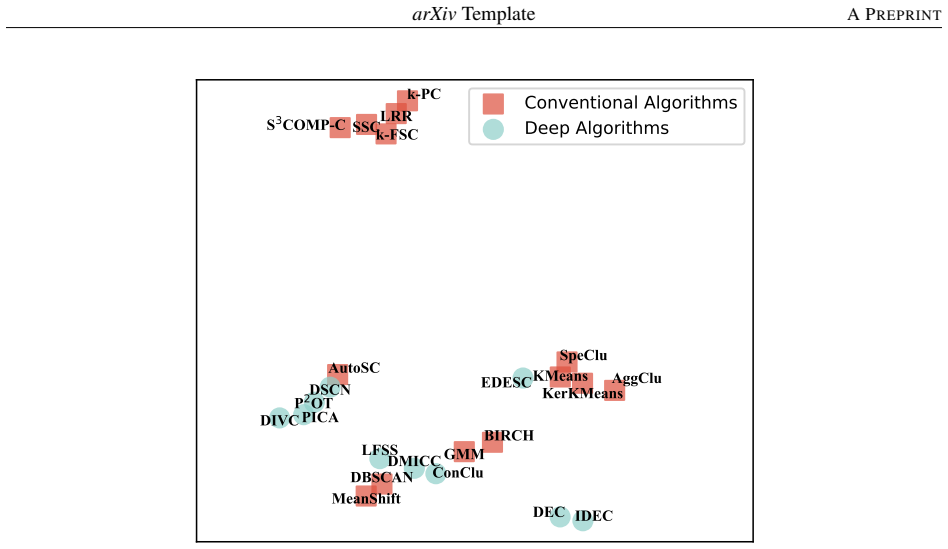
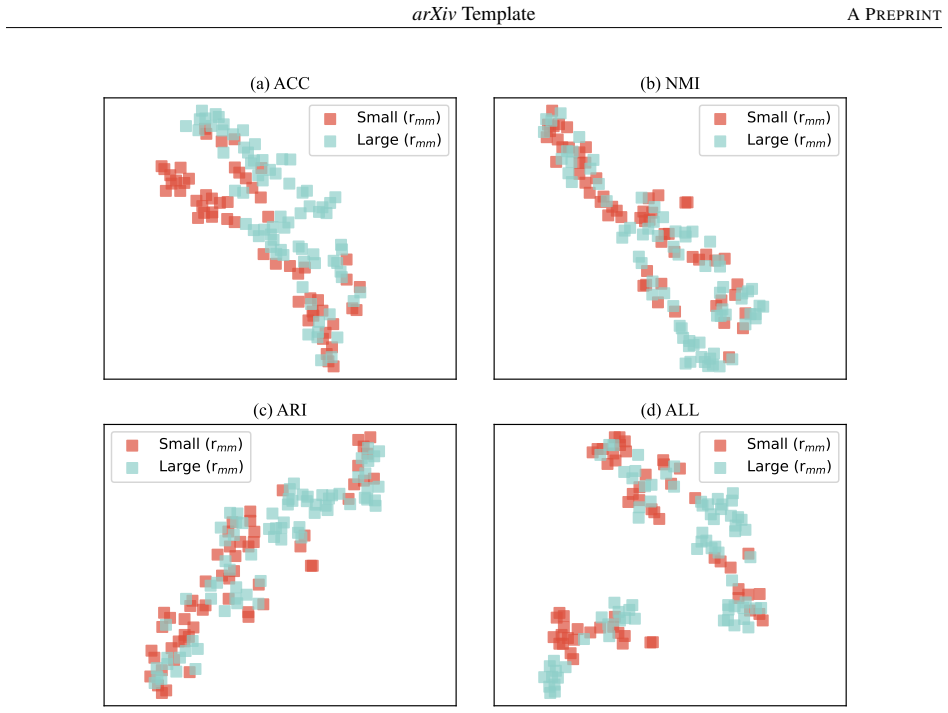
In addition to the aggregated representation, we further apply t-SNE separately to Pacc, Pnmi, and Pari, with the corresponding visualizations shown in Figure 5 (a)-(c)
to these dataset-level performance vectors yields a two-dimensional visualization in Figure 5 (d) that captures similarities among datasets in terms of their clustering behavior. In addition to the aggregated representation, we further apply t-SNE separately to Pacc, Pnmi, and Pari, with the corresponding visualizations shown in Figure 5 (a)-(c). In Figur...
2012
-
[4]
N", "K",
Output ONLY a JSON object with keys: "N", "K", "labels"
-
[5]
N" must equal {N}
"N" must equal {N}. "K" must equal {K}
-
[6]
"labels" must be a list of length N={N}
-
[7]
[0, {K-1}]
Each label must be an integer in {{0,1,...,K-1}} i.e. [0, {K-1}]
-
[8]
Every label in {{0,...,K-1}} must appear at least once (use exactly K clusters)
-
[9]
No extra keys, no explanation, no markdown, no code
-
[10]
b) set(labels)=={0,1,...,K-1}
Before you output the final JSON, internally verify: a) len(labels)=={N}. b) set(labels)=={0,1,...,K-1}. c) all labels are ints
-
[11]
N": 5, "K
If any check fails, fix labels and re-check until all pass. EXAMPLE JSON OUTPUT: {{"N": 5, "K": 2, "labels": [0, 1, 1, 0, 1]}} User: Return the results as JSON. N={N}, D={D}, K={K} X (row0 first): {Textualized Matrix Rows} /uni00000014/uni00000015/uni00000013/uni00000017/uni00000013/uni00000019/uni00000013/uni0000001b/uni00000013/uni00000014/uni00000013/u...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.