Cookie-Bench: Continuous On-screen Key Interaction Evaluation for Web Generation
Pith reviewed 2026-06-29 07:21 UTC · model grok-4.3
The pith
Cookie-Frame matches expert human ratings on interactive web generation without references or test suites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
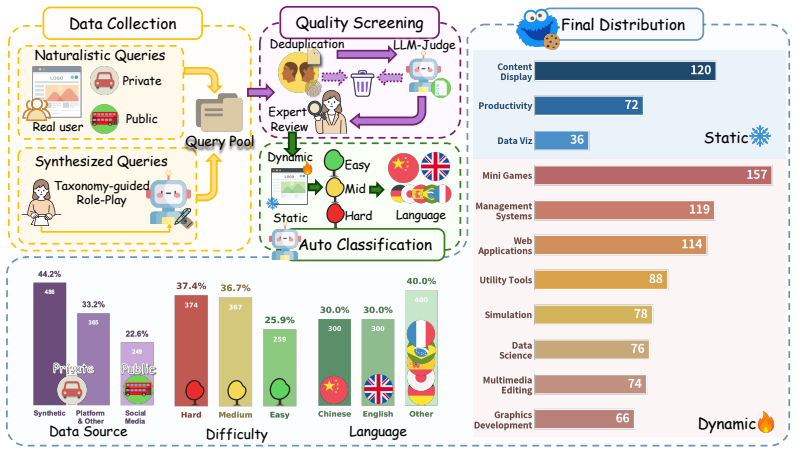
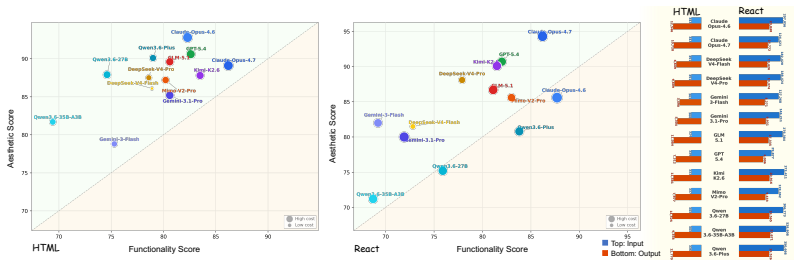
Cookie-Bench supplies an 11-domain, 54-leaf, 1000-query WebDev benchmark balanced across static-presentation and interactive-application tasks; Cookie-Frame implements a metacognition-inspired regime that separates evidence accumulation (static perception plus agent-driven continuous screen interaction) from holistic judgment (dynamic scoring), achieving close alignment with expert human ratings while exposing headroom across frontier LLMs on interactive web generation.
What carries the argument
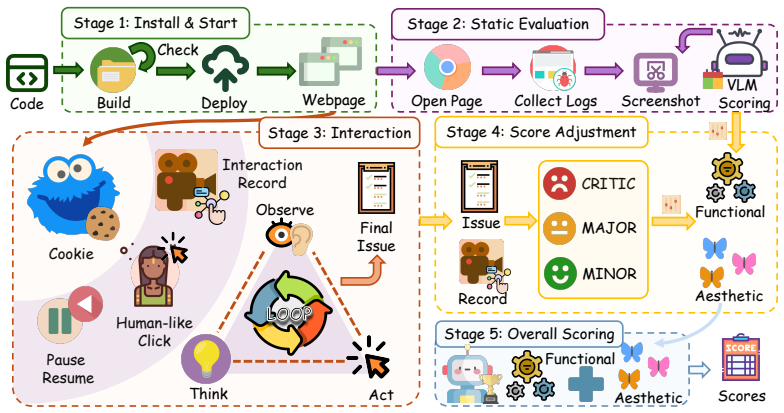
Cookie-Frame, the three-stage process of static perception, agent-driven interaction with continuous screen-video capture, and post-evidence dynamic scoring with structured failure attribution.
If this is right
- Evaluation of LLM-generated interactive web applications can proceed at scale without human judges or reference code at each iteration.
- Current frontier models exhibit measurable shortfalls on both functionality and aesthetics when judged under continuous-interaction conditions.
- The same reference-free regime applies equally to static presentation tasks and to dynamic application tasks.
- Structured failure attribution produced after full evidence collection supplies actionable diagnostic signals for model improvement.
Where Pith is reading between the lines
- The continuous screen-capture record could serve as training data for reward models that learn to predict human preference directly from interaction traces.
- The separation of evidence accumulation from judgment may generalize to other GUI domains such as mobile or desktop application generation.
- Because the benchmark resists recall of circulated prompts, repeated use of the same queries is less likely to inflate reported performance over time.
Load-bearing premise
An autonomous agent performing continuous screen interaction and later holistic scoring can replicate the reasoned synthesis a human reviewer performs over a live session without any reference implementation or test suite.
What would settle it
A side-by-side study in which multiple expert human raters independently score the same set of generated web applications and the resulting scores diverge substantially from Cookie-Frame verdicts on a non-negligible fraction of cases.
Figures


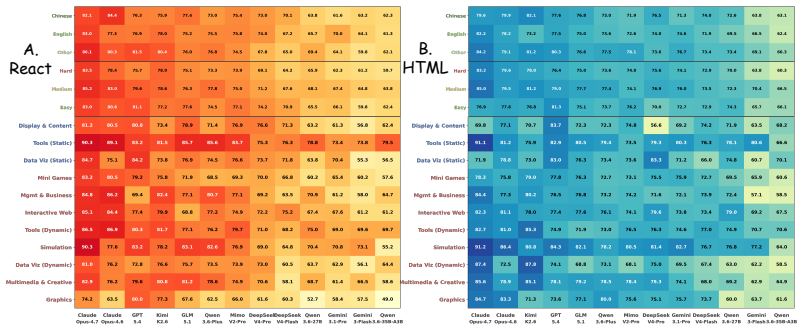
read the original abstract
Front-end web code has become a core product surface for every frontier LLM release, yet evaluating these interactive applications at development speed remains costly because human-judged leaderboards like Arena do not scale. Existing automated proxies typically lean on reference implementations, test suites, or rigid checklists, and tend to miss the reasoned synthesis a human reviewer performs over a live session. We articulate a new evaluation regime that is simultaneously reference-free, autonomously driven, and holistically reasoned, and instantiate it through two artifacts. \textbf{\dataname} is an 11-domain, 54-leaf, 1,000-query WebDev benchmark spanning both static-presentation and interactive-application tasks, balanced across three difficulty tiers and three target-language groups, with briefs rewritten to resist recall from circulated prompts. \textbf{\framename}, grounded in Flavell's metacognitive monitoring, separates evidence accumulation from judgment across three stages: Static Perception forms a first impression from passive observation; Agent-Driven Interaction explores the application autonomously while capturing continuous screen video, audio, and per-step screenshots; Dynamic Scoring issues holistic functionality and aesthetics verdicts with structured failure attribution only after the evidence chain is complete. On \dataname, \framename aligns closely with expert human ratings while surfacing substantial headroom across 13 frontier LLMs on interactive web generation. \noindenthttps://anonymous.4open.science/r/Cookie-3CE/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Cookie-Bench, an 11-domain, 54-leaf, 1,000-query benchmark for LLM-generated web applications spanning static and interactive tasks across difficulty tiers and languages, with prompts rewritten to avoid recall. It also presents Cookie-Frame, a reference-free three-stage framework (Static Perception, Agent-Driven Interaction via continuous screen capture, and Dynamic Scoring) grounded in Flavell's metacognitive monitoring, claiming close alignment with expert human ratings and substantial headroom across 13 frontier LLMs on interactive web generation.
Significance. If the alignment claim holds with quantitative support, the work could supply a scalable, autonomous alternative to human-judged leaderboards for evaluating complex interactive front-end code, addressing the scalability limits of existing reference- or test-suite-based proxies while enabling holistic, reasoned verdicts.
major comments (2)
- [Abstract] Abstract: the central claim that Cookie-Frame 'aligns closely with expert human ratings' is asserted without any reported metrics (e.g., correlation coefficients, agreement statistics, sample sizes, or inter-rater reliability). This is load-bearing for the primary contribution, as the evaluation regime's three-stage separation and mapping from captured evidence to structured verdicts remains unvalidated against human live-session synthesis.
- [Abstract] Abstract and evaluation regime description: the assertion of 'substantial headroom across 13 frontier LLMs' inherits the same validation gap; without ablation results comparing staged scoring to direct LLM scoring or details on how the autonomous agent replicates reasoned human judgment, the headroom result cannot be assessed for robustness.
minor comments (2)
- The benchmark construction mentions 'briefs rewritten to resist recall from circulated prompts,' but provides no concrete details on the rewriting process or verification method.
- Notation for the two artifacts uses placeholder macros (\dataname, \framename) in the abstract; consistent naming (Cookie-Bench, Cookie-Frame) should be used throughout.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to make quantitative support for the alignment and headroom claims explicit in the abstract. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Cookie-Frame 'aligns closely with expert human ratings' is asserted without any reported metrics (e.g., correlation coefficients, agreement statistics, sample sizes, or inter-rater reliability). This is load-bearing for the primary contribution, as the evaluation regime's three-stage separation and mapping from captured evidence to structured verdicts remains unvalidated against human live-session synthesis.
Authors: We agree that the abstract should report the supporting metrics rather than asserting alignment without them. The full manuscript contains a human study with Pearson correlation, sample size, and inter-rater reliability figures validating the three-stage regime against expert ratings on live sessions. We will revise the abstract to include these quantitative results so that the validation of the staged evidence-to-verdict mapping is visible at the abstract level. revision: yes
-
Referee: [Abstract] Abstract and evaluation regime description: the assertion of 'substantial headroom across 13 frontier LLMs' inherits the same validation gap; without ablation results comparing staged scoring to direct LLM scoring or details on how the autonomous agent replicates reasoned human judgment, the headroom result cannot be assessed for robustness.
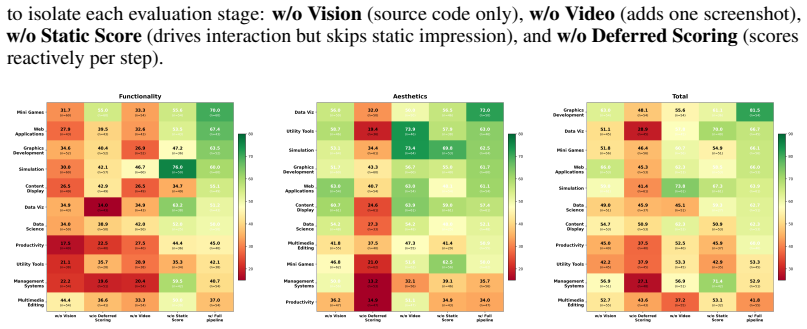
Authors: The headroom result is obtained by running the complete Cookie-Frame pipeline (including agent-driven continuous interaction and post-evidence dynamic scoring) on the 13 models; the primary validation remains the correlation with human ratings rather than an internal ablation against direct LLM scoring. We will add a concise clarification in the abstract and evaluation section describing how the metacognition-inspired separation of perception, interaction, and scoring is intended to approximate human live-session synthesis. An explicit ablation against direct LLM scoring is not present in the current manuscript and would require additional experiments; we therefore treat this as a partial revision focused on textual clarification. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The paper presents Cookie-Bench as a new reference-free benchmark and Cookie-Frame as a three-stage evaluation process grounded explicitly in Flavell's external metacognitive monitoring concept. No equations, fitted parameters, self-citations, or ansatzes appear in the abstract or described framework. The alignment claim with human ratings is positioned as an empirical outcome rather than a quantity derived by construction from the inputs. The derivation chain introduces new artifacts without reducing any prediction or uniqueness result to its own definitions or prior self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-stage process (Static Perception, Agent-Driven Interaction, Dynamic Scoring) grounded in Flavell's metacognitive monitoring accurately captures human reasoned synthesis over live sessions.
Reference graph
Works this paper leans on
-
[1]
Claude builds visuals
Anthropic. Claude builds visuals. https://claude.com/blog/claude-builds-visuals, 2026. Ac- cessed: 2026-04-23
2026
-
[2]
Claude opus 4.6
Anthropic. Claude opus 4.6. https://www.anthropic.com/news/claude-opus-4-6 , 2026. Ac- cessed: 2026-05-01
2026
-
[3]
Claude opus 4.7
Anthropic. Claude opus 4.7. https://www.anthropic.com/news/claude-opus-4-7 , 2026. Ac- cessed: 2026-05-01
2026
- [4]
-
[5]
DeepSeek-V4
DeepSeek AI. DeepSeek-V4. https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/ main/DeepSeek_V4.pdf, 2026. Accessed: 2026-05-01
2026
-
[6]
J. H. Flavell. Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry. American psychologist, 34(10):906, 1979
1979
-
[7]
Gemini 3
Google. Gemini 3. https://aistudio.google.com/models/gemini-3, 2026. Accessed: 2026-04- 23. 10
2026
-
[8]
Gemini 3.1 Pro
Google DeepMind. Gemini 3.1 Pro. https://deepmind.google/technologies/gemini/, 2026. Accessed: 2026-05-01
2026
-
[9]
Y . Gui, Z. Li, Y . Wan, Y . Shi, H. Zhang, Y . Su, S. Dong, X. Zhou, and W. Jiang. Vision2ui: A real-world dataset with layout for code generation from ui designs.CoRR, 2024
2024
-
[10]
Y . Gui, Z. Li, Y . Wan, Y . Shi, H. Zhang, B. Chen, Y . Su, D. Chen, S. Wu, X. Zhou, et al. Webcode2m: A real-world dataset for code generation from webpage designs. InProceedings of the ACM on Web Conference (WWW 2025), pages 1834–1845, 2025
2025
-
[11]
H. Guo, W. Zhang, J. Chen, Y . Gu, J. Yang, J. Du, S. Cao, B. Hui, T. Liu, J. Ma, et al. Iw-bench: Evaluating large multimodal models for converting image-to-web. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6449–6466, 2025
2025
- [12]
- [13]
- [14]
- [15]
-
[16]
H. Laurençon, L. Tronchon, and V . Sanh. Unlocking the conversion of web screenshots into html code with the websight dataset.arXiv preprint arXiv:2403.09029, 2024
-
[17]
X. Lei, X. Che, J. Xiong, C. Zhang, Y . Huang, C. Zhou, H. Huang, M. Liu, L. Zhu, H. Ye, J. Hao, K. Deng, Z. Zhan, H. Li, D. Li, Y . Yao, M. Sun, Z. Zhang, and J. Liu. Webcompass: Towards multimodal web coding evaluation for code language models, 2026. URLhttps://arxiv.org/abs/2604.18224
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
- [19]
- [20]
- [21]
-
[22]
Kimi K2.6.https://www.kimi.com/blog/kimi-k2-6, 2026
Moonshot AI. Kimi K2.6.https://www.kimi.com/blog/kimi-k2-6, 2026. Accessed: 2026-05-01
2026
-
[23]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , 2026. Ac- cessed: 2026-05-01
2026
-
[24]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/zh-Hans-CN/index/ introducing-gpt-5-4/, 2026. Accessed: 2026-04-23
2026
-
[25]
Z. Peng, W. Tao, X. Yin, C. Ying, Y . Luo, and Y . Guo. Playcoder: Making llm-generated gui code playable,
-
[26]
URLhttps://arxiv.org/abs/2604.19742
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Robertson
S. Robertson. Understanding inverse document frequency: on theoretical arguments for idf.Journal of documentation, 60(5):503–520, 2004
2004
-
[28]
Sadowski and G
C. Sadowski and G. Levin. Simhash: Hash-based similarity detection. Technical report, Technical report, Google, 2007
2007
-
[29]
C. Si, Y . Zhang, R. Li, Z. Yang, R. Liu, and D. Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), pages 3956–3974, Albuquerque, New Mexico, Apr. 20...
2025
- [30]
- [31]
-
[32]
Wu, Y .-H
J. Wu, Y .-H. Peng, X. Y . A. Li, A. Swearngin, J. P. Bigham, and J. Nichols. Uiclip: a data-driven model for assessing user interface design. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, pages 1–16, 2024
2024
- [33]
-
[34]
J. Xiao, Y . Wan, Y . Huo, Z. Wang, X. Xu, W. Wang, Z. Xu, Y . Wang, and M. R. Lyu. Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 241–253. IEEE, 2025
2025
- [35]
-
[36]
Mimo V2 Pro.https://mimo.xiaomi.com/mimo-v2-pro, 2026
Xiaomi. Mimo V2 Pro.https://mimo.xiaomi.com/mimo-v2-pro, 2026. Accessed: 2026-05-01
2026
- [37]
- [38]
-
[39]
S. Yun, H. Lin, R. Thushara, M. Q. Bhat, Y . Wang, Z. Jiang, M. Deng, J. Wang, T. Tao, J. Li, H. Li, P. Nakov, T. Baldwin, Z. Liu, E. P. Xing, X. Liang, and Z. Shen. Web2code: A large-scale webpage-to-code dataset and evaluation framework for multimodal llms. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 112134–112157. Cu...
2024
- [40]
-
[41]
MiniAppBench: Evaluating the Shift from Text to Interactive HTML Responses in LLM-Powered Assistants
Z. Zhang, C. Yu, Y . Li, C. Zhuang, L. Mo, and S. Li. Miniappbench: Evaluating the shift from text to interactive html responses in llm-powered assistants.arXiv preprint arXiv:2603.09652, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
GLM-5.1.https://z.ai/blog/glm-5.1, 2026
Zhipu AI. GLM-5.1.https://z.ai/blog/glm-5.1, 2026. Accessed: 2026-05-01
2026
-
[43]
H. Zhu, Y . Zhang, B. Zhao, J. Ding, S. Liu, T. Liu, D. Wang, Y . Liu, and Z. Li. Frontendbench: A benchmark for evaluating llms on front-end development via automatic evaluation.arXiv preprint arXiv:2506.13832, 2025. 12 Appendix Contents A. Cookie-Bench Benchmark Data: Supplementary Details. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[44]
Environment freeze.During the agent’s deliberation phase (between observation and action selection), the application state is paused to prevent temporal drift. This ensures that the page state the agent reasons about remains consistent with the state it subsequently acts upon, avoiding evaluation artifacts caused by animations, timers, or asynchronous upd...
-
[45]
Multi-modal evidence capture.A continuous capture pipeline records screen video and audio streams alongside per-step screenshots throughout the interaction session. Unlike discrete snapshot- based approaches, this preserves the full temporal evolution of application behavior, including animation timing, transition smoothness, loading-state flicker, and au...
-
[46]
Human-like input simulation.Rather than issuing instantaneous programmatic inputs, the agent introduces realistic interaction rhythms: gradual mouse movements, natural typing cadence, and appropriate pauses between actions. This prevents evaluation artifacts that arise when applications behave differently under programmatic versus human-speed input (e.g.,...
-
[47]
If no visible change occurred, say so explicitly
Primacy of Evidence: Document every action and its directly observed result. If no visible change occurred, say so explicitly
-
[48]
no change observed
Anti-Stagnation: If the page state is identical for 3 consecutive observation cycles while waiting for something (e.g., a response, animation, or load), note this as "no change observed" and move on
-
[49]
Anti-Loop: If you find yourself repeating the same action or sequence without a new outcome, break the loop immediately and document it
-
[50]
If still broken, exit immediately and report it in your overall_observation -- do not attempt workarounds
Garbled Page Handling: If the page appears garbled or unreadable (encoding issues), refresh up to 2 times. If still broken, exit immediately and report it in your overall_observation -- do not attempt workarounds
-
[51]
Do NOT document or comment on any programming language mismatch -- just test what is in front of you
Programming Language: The output project is expected to be a web application (HTML, React, etc.), regardless of what the query specifies. Do NOT document or comment on any programming language mismatch -- just test what is in front of you
-
[52]
Page Language: Note in your overall_observation if the page language does not match the language requirement in the user query
-
[53]
No Scoring Required: You are NOT evaluating quality -- just testing functionality and documenting observations. II. WEB APPLICATION TESTING PROTOCOL Step 1: Test Core Functionality Test the CORE LOGIC first. Interact with the main workflow users will use the website, and experience its primary purpose. Step 2: Test Interactive Elements Systematically test:
-
[54]
Navigation: All menu items, links, breadcrumbs
-
[55]
Buttons: All primary and secondary buttons
-
[56]
Forms: Input fields, dropdowns, checkboxes, validation
-
[57]
Dynamic Content: Tabs, accordions, modals, tooltips
-
[58]
Media: Images, videos, carousels load status
-
[59]
Tested 3/20 product cards, all functional
Search/Filter: Any search or filtering functionality III. GAME TESTING PROTOCOL If the application appears to be a game, apply the following protocol instead of (or in addition to) the Web Application Testing Protocol above. Non-Real-Time Interactive Games (card games, turn-based games, strategy games, puzzle games, etc.): - Try to test the complete game ...
-
[60]
Actively plan your steps, prioritize core functionality, and stop testing in time to prepare output before reaching the limit
Step Limit: You MUST conclude and produce your final JSON output within {max_steps} steps. Actively plan your steps, prioritize core functionality, and stop testing in time to prepare output before reaching the limit
-
[61]
Environment Limitations (DO NOT Test -- Assume Working): - Backend/Database: Login systems, user authentication, data persistence - Third-Party APIs: LLM APIs, payment gateways, social media APIs, map services - File Operations: File upload/download functionality - Email/SMS: Email sending, SMS verification
-
[62]
Console Errors -- Only Report Critical Errors: Record only JavaScript errors that cause observable malfunction in the page or directly break functionality. Do NOT report: - Console warnings of any kind - Font loading failures (fonts.googleapis.com, fonts.gstatic.com) - Favicon 404 errors - CDN resource failures that do not visibly break the page
-
[63]
Focus on Frontend Interactions: Test what's visibly interactive in the browser
-
[64]
Prioritize Critical Path: Test main workflow first, then secondary elements
-
[65]
actions_performed
No Edge Cases: Do NOT test extreme or edge case inputs. VII. FINAL OUTPUT FORMAT Provide a comprehensive interaction summary as a JSON object. This summary will be used by a VLM evaluator to assess the application quality. Important: You MUST provide this JSON output before reaching the {max_steps}-step limit. { "actions_performed": [ "Navigated to {url}"...
-
[66]
Webpage Screenshot: For visual and layout audit
-
[67]
Source Code: To review logic, event handlers, and implementation quality
-
[68]
Original User Query: To verify if requirements and language match
-
[69]
Browser Console Logs & Dev Server Output: To detect hidden functional crashes or warnings. II. SCORING SYSTEM (0.0 - 8.0 SCALE) Programming language specification: The output project MUST be in html/react WHATEVER the query specified. DO NOT DEDUCT points for the difference from user query. Page language check: The web page's displayed language (in contra...
-
[70]
start->interact->win/lose->restart/next
FUNCTIONAL SCORING (REQUIREMENT-DRIVEN AUDIT) Step 1: Assess Implementation Completeness - 8.0 points: ALL user requirements fully implemented with correct logic - 7.0 points: ALL user requirements implemented, only minor features missing or error (e.g. form validation is incomplete) - 5.0 points: Core requirements implemented, some key features missing o...
-
[71]
ready to build
AESTHETIC SCORING (DEFECT-BASED ELITE STANDARDS) STEP 1: BASELINE - 5.0 points: High-quality, clean, and modern. Standard professional work. - 3.0 points: Functional but unpolished. With issues. - 1.0 points: Raw HTML elements with no styling or only very basic CSS. - 0.0 points: App fails to render, is blank, shows raw code or placeholder page (e.g. "rea...
-
[72]
Detailed step-by-step explanation
-
[73]
functional_reason
Clear deduction breakdown with math { "functional_reason": "Step 1: [Base score, reason]. Step 2: [Instruction following audit - query alignment, elaboration, hallucination, template check, language]. Step 3: [Source code interactive elements verification]. Step 4: [Data display check]. Step 5: [Console error audit]. Calculation: [show math]. Final: X.X",...
-
[74]
Confirm problems found in video - these are DEFINITE issues
-
[75]
Do NOT dismiss code-level problems from static evaluation - unless the video explicitly proves they don't exist
-
[76]
Identify:
If static evaluation identified a problem in the code, assume it exists UNLESS: - The video explicitly demonstrates the feature working correctly - The video shows the problematic code path executing without issues Your Task Carefully review the initial screenshot, the source code context, and the interaction video /frames. Identify:
-
[77]
NEW problems discovered in video - issues that became apparent during interaction
-
[78]
could be better
CONFIRMED code problems - issues mentioned in static evaluation that are NOT disproven by the video Focus Areas 27 Functional Problems CRITICAL Severity (suggest -2.0 or more each): - Core logic complete failure: Application crashes, infinite loop, or becomes completely unusable (blocks ALL usage) - Language mismatch: Page language doesn't match user quer...
-
[79]
Match severity to EXACT deduction amounts: Don't guess - use the mappings above
-
[80]
Report NEW problems from video: Issues that became visible during interaction
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.