RAISE: RAG Design as an Architecture Search Problem
Pith reviewed 2026-06-29 07:12 UTC · model grok-4.3
The pith
RAG design choices form an architecture search problem whose optimal methods vary sharply by task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
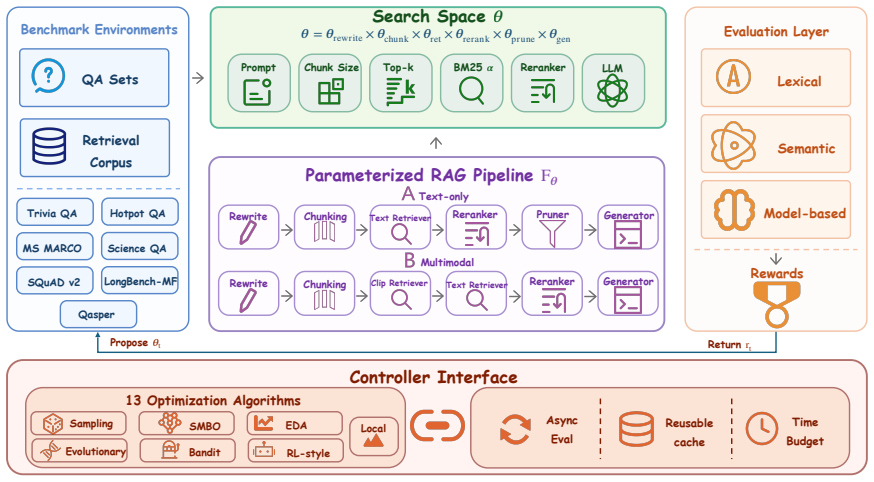
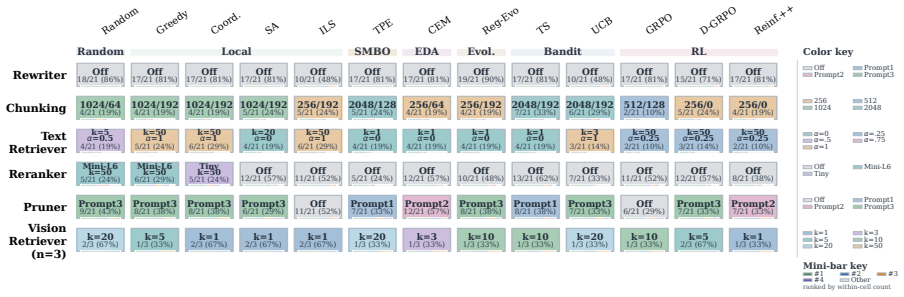
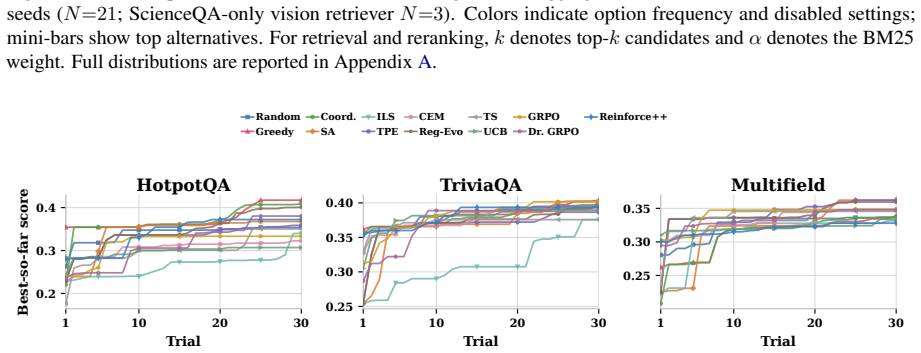
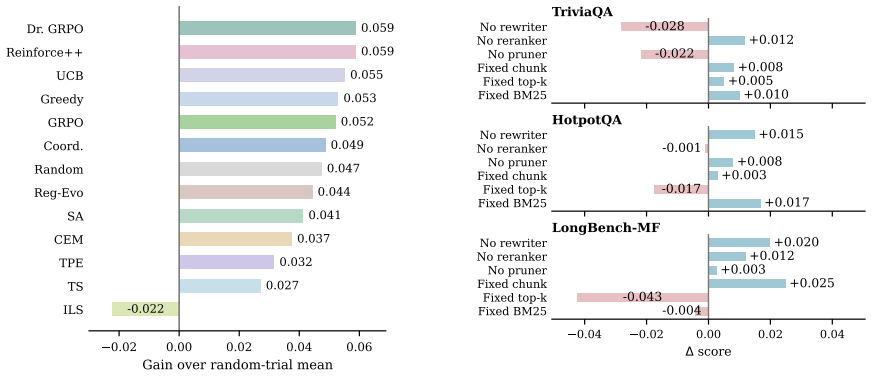
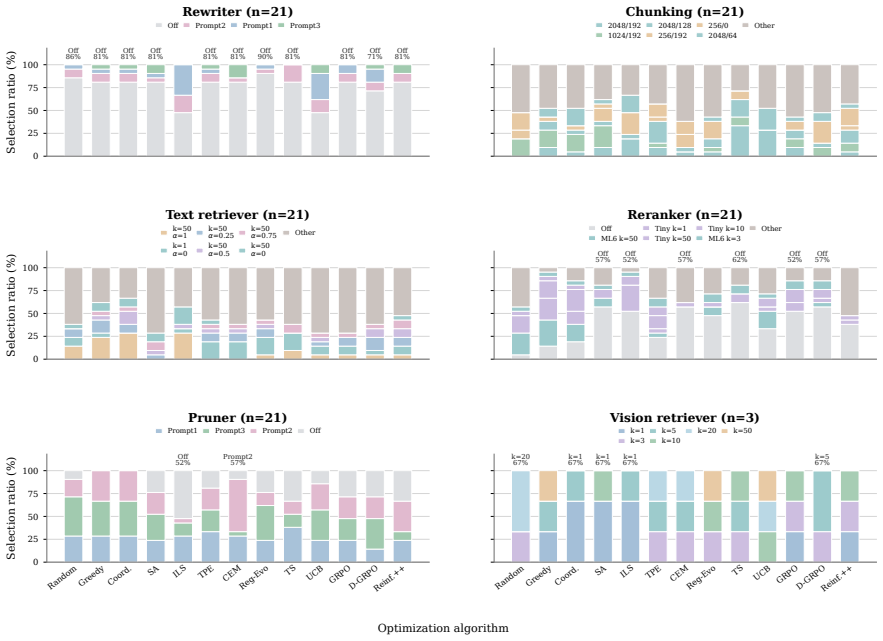
RAISE treats RAG pipeline construction as hyperparameter optimization over a fixed search space covering query rewriting, chunking, retrieval depth, reranking, and context compression. Thirteen search algorithms are run on seven text and multimodal datasets under identical budgets and three random seeds. The resulting performance profiles show that optimization success is highly task-dependent, with methods that rank high on one dataset failing to generalize consistently to others.
What carries the argument
The RAISE benchmark, which standardizes search spaces, budgets, and evaluation protocols so that different RAG architecture search algorithms can be compared fairly across datasets.
Load-bearing premise
The chosen search spaces, fixed budgets, and seven public datasets are representative enough of real RAG design problems that the observed task-dependency will hold in other settings.
What would settle it
A single search algorithm that ranks first or near-first on every one of the seven datasets under the same budgets and seeds would falsify the claim of strong task dependence.
Figures
read the original abstract
Retrieval-augmented generation (RAG) systems expose numerous design choices spanning query rewriting, chunking, retrieval depth, reranking, and context compression. In practice, these choices are often configured through heuristics, hindering systematic evaluation and reproducibility across settings. We argue that this challenge is best formulated as RAG architecture search. To support controlled and reproducible study of this problem, we introduce the RAG Intelligence Search Engine (RAISE), a comprehensive framework and benchmark for RAG hyperparameter optimization, which evaluates optimization methods for RAG pipelines under standardized search spaces and budgets. RAISE implements 13 search algorithms and evaluates them across seven public text and multimodal datasets using three random seeds. Our experiments show that optimization performance is highly task-dependent: methods that perform strongly on one dataset may not generalize consistently across others, cautioning against interpreting aggregate rankings as evidence of universally superior strategies. RAISE provides a common experimental substrate for fair, reproducible, and systematic research on RAG hyperparameter optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames RAG pipeline design (query rewriting, chunking, retrieval depth, reranking, compression) as an architecture search problem and introduces the RAISE benchmark to support controlled evaluation of hyperparameter optimization methods. It implements 13 search algorithms, evaluates them on seven public text and multimodal datasets under standardized search spaces and budgets using three random seeds, and reports that optimization performance is highly task-dependent, with strong methods on one dataset failing to generalize consistently.
Significance. If the experimental findings hold under the stated conditions, RAISE supplies a reproducible public substrate for RAG optimization research and supplies concrete evidence against treating aggregate rankings as universal. The use of multiple public datasets and fixed seeds is a positive contribution to reproducibility in the area.
major comments (2)
- [§4 Experiments] §4 (Experiments) and the abstract: the claim that 'optimization performance is highly task-dependent' and does not generalize is load-bearing for the paper's main conclusion, yet the manuscript provides no analysis or table quantifying dataset diversity (domains, query types, corpus sizes, modalities) or justifying why the seven chosen datasets suffice to distinguish genuine task-dependency from benchmark-specific artifacts.
- [§3 RAISE framework] §3 (RAISE framework) and §4.1: the standardized search spaces and budgets are central to the reproducibility claim, but the text does not supply the precise parameterization (e.g., ranges for chunk size, retrieval depth, reranker choice) per dataset or modality, preventing independent verification that the observed non-generalization is not an artifact of the chosen spaces.
minor comments (2)
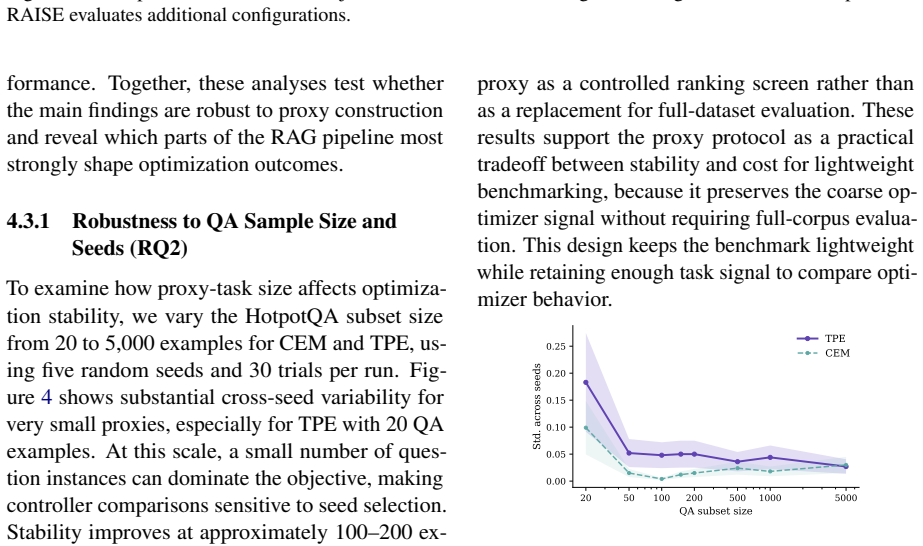
- [Results tables] Table 2 or equivalent results table: report per-dataset variance across the three seeds and any statistical test used to declare one method 'strong' on a given dataset.
- [§5 Discussion] §5 (Discussion): add a short paragraph on limitations of the current search spaces (e.g., static corpora, fixed modalities) to contextualize the task-dependency finding.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to strengthen the justification and reproducibility of our experimental claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4 Experiments] §4 (Experiments) and the abstract: the claim that 'optimization performance is highly task-dependent' and does not generalize is load-bearing for the paper's main conclusion, yet the manuscript provides no analysis or table quantifying dataset diversity (domains, query types, corpus sizes, modalities) or justifying why the seven chosen datasets suffice to distinguish genuine task-dependency from benchmark-specific artifacts.
Authors: We agree that an explicit quantification of dataset diversity would better substantiate the task-dependency conclusion. In the revision we will add a table (or subsection) in §4 that reports, for each of the seven datasets, the domain, query type, corpus size, modality, and a concise justification for selection. This addition will clarify the coverage of text and multimodal settings and help distinguish genuine task effects from benchmark artifacts. revision: yes
-
Referee: [§3 RAISE framework] §3 (RAISE framework) and §4.1: the standardized search spaces and budgets are central to the reproducibility claim, but the text does not supply the precise parameterization (e.g., ranges for chunk size, retrieval depth, reranker choice) per dataset or modality, preventing independent verification that the observed non-generalization is not an artifact of the chosen spaces.
Authors: We acknowledge that the current text does not enumerate the exact hyperparameter ranges per dataset or modality. We will expand §3 (and/or add an appendix) with precise tables listing the search-space bounds for chunk size, retrieval depth, reranker choice, compression ratio, and other parameters, differentiated by dataset and modality where applicable. This will enable independent verification of the experimental conditions. revision: yes
Circularity Check
No circularity: empirical benchmark paper with no derivations or self-referential claims
full rationale
The paper introduces RAISE as an empirical benchmark and framework for evaluating RAG hyperparameter optimization methods. It reports experimental results from running 13 search algorithms on seven public datasets under fixed search spaces and budgets, concluding that performance is task-dependent. No equations, first-principles derivations, predictions, or ansatzes are present. The central observation follows directly from the reported runs on the chosen public data; it does not reduce by construction to any fitted parameter, self-citation chain, or definitional equivalence. Self-citations, if any, are not load-bearing for the empirical findings. This is a standard empirical benchmark contribution whose claims are externally falsifiable via replication on the same public datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Finite-time analysis of the multiarmed ban- dit problem.Mach. Learn., 47(2–3):235–256. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhi- fang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025. Qwen3-v...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A
Benchmarking large language models in retrieval-augmented generation.Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):17754–17762. Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. 2021. A dataset of information-seeking questions and answers an- chored in research papers. InProceedings of the 2021 Conf...
2021
-
[3]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert
Hpobench: A collection of reproducible multi-fidelity benchmark problems for hpo.Preprint, arXiv:2109.06716. Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. RAGAs: Automated evalu- ation of retrieval augmented generation. InProceed- ings of the 18th Conference of the European Chap- ter of the Association for Computational Linguis...
-
[4]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization. Preprint, arXiv:2501.03262. 9 Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park. 2024. Adaptive-rag: Learn- ing to adapt retrieval-augmented large language mod- els through question complexity. InProceedings of the 2024 Conference of the Nor...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Understanding r1-zero-like training: A critical perspective.Preprint, arXiv:2503.20783. H. R. Lourenco, O. C. Martin, and T. Stutzle. 2001. Iterated local search.Preprint, arXiv:math/0102188. Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai- Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal rea...
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
Practical bayesian optimization of machine learning algorithms. InAdvances in Neural Informa- tion Processing Systems 25, pages 2951–2959. William R Thompson. 1933. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika, 25(3/4):285– 294. Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Mi...
work page internal anchor Pith review Pith/arXiv arXiv 1933
-
[7]
is defined as METEOR= 10PmRm Rm + 9Pm (1−Pen)(16) B.2.2 Semantic and Model-Based Metrics BERTScore-F1.BERTScore (Zhang et al., 2020) computes semantic overlap using contextualized embeddings. Its recall term is RBERT = 1 |Y ∗| X y∗∈Y ∗ max y∈Y y⊤y∗ (17) 13 LLM-as-a-Judge (LLM-aaJ).For complex rea- soning tasks, RAISE supports an LLM-based judge model M wh...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.