Adaptive Targeted Dynamic Chunking for Tokenization-Free Hierarchical Model
Pith reviewed 2026-06-29 08:01 UTC · model grok-4.3
The pith
Adaptive Targeted Dynamic Chunking uses curriculum learning to progressively increase compression ratios for more stable training in byte-level hierarchical models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
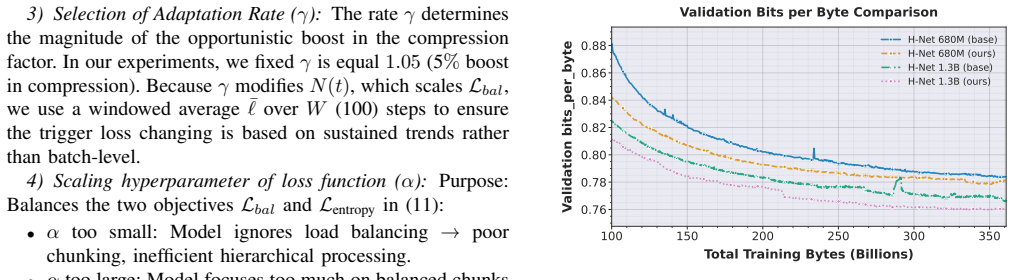
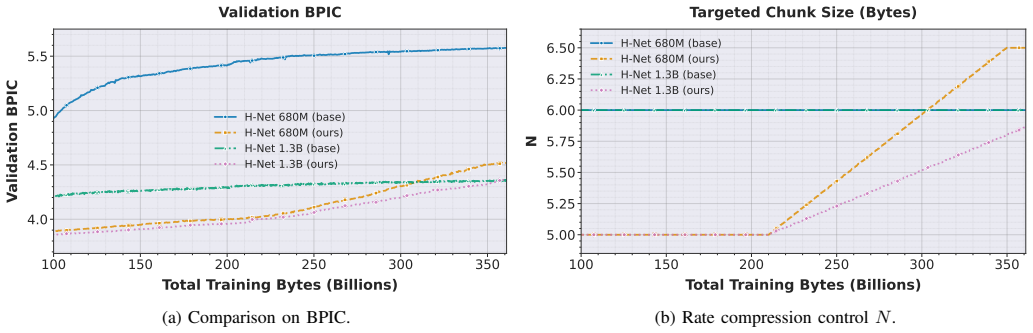
The authors establish that ATDC, through progressive adjustment of the target compression ratio, produces hierarchical models with competitive Bits-Per-Byte scores, more stable dynamics during training, and better final performance on diverse tasks than models that hold the compression ratio fixed throughout.
What carries the argument
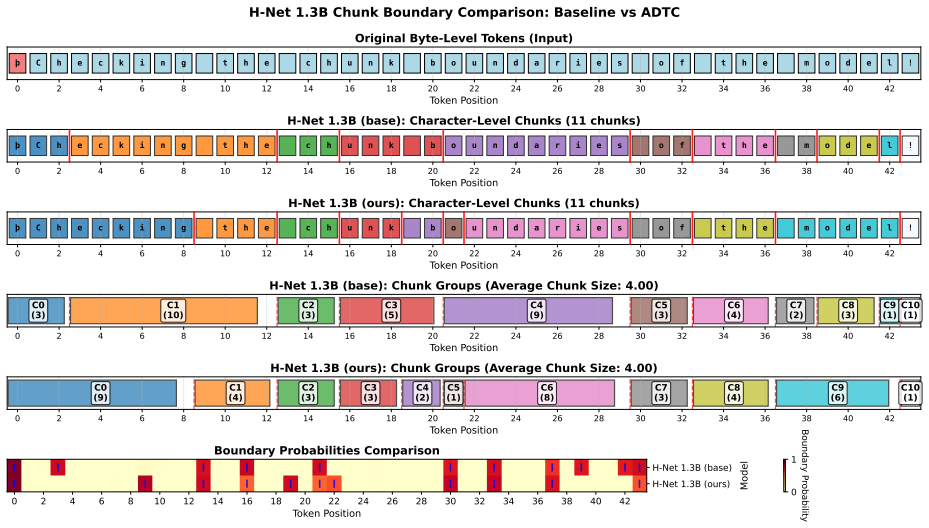
Adaptive Targeted Dynamic Chunking (ATDC), which employs curriculum learning to transition the compression ratio and uses the Bytes-Per-Innermost-Chunk metric to monitor chunk size changes.
Load-bearing premise
That progressively raising the target compression ratio via curriculum learning will reliably stabilize training and produce superior final performance without introducing new instabilities or requiring extensive hyperparameter retuning for each dataset.
What would settle it
Training a hierarchical model with the proposed curriculum on compression ratio and finding that it diverges or ends with higher bits-per-byte than a fixed-ratio control on the FineWeb-Edu dataset.
Figures
read the original abstract
Tokenization-free hierarchical models are emerging as a promising alternative to traditional Large Language Models (LLMs), addressing inherent preprocessing issues such as vocabulary design complexity, out-of-vocabulary (OOV) errors, and language-specific constraints. However, a significant challenge in these byte-level methods is the optimization of the compression ratio, a critical factor that dictates model performance for processing bytes data via chunks. In this paper, we propose Adaptive Targeted Dynamic Chunking (ATDC), a novel byte-compression control mechanism designed to enhance the effectiveness of dynamic chunking within hierarchical architectures. Our approach utilizes curriculum learning to progressively adjust the compression ratio during training, transitioning from low to high compression to stabilize the learning process. We provide an analysis establishing the relationship between the target compression ratio and Bytes-Per-Innermost-Chunk (BPIC), allowing for tracking of chunk-size evolution throughout the training phase. Evaluations conducted on the FineWeb-Edu 100B dataset demonstrate that hierarchical models equipped with ATDC achieve competitive Bits-Per-Byte (BPB) performance compared to conventional baselines operating at both byte and token levels. Furthermore, the proposed method exhibits more stable training dynamics and superior final performance across diverse downstream tasks compared to models using fixed compression ratios, while maintaining the inherent robustness and flexibility of byte-level processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Targeted Dynamic Chunking (ATDC), a curriculum-learning mechanism that progressively raises the target compression ratio during training of tokenization-free hierarchical byte-level models. It includes an analysis relating target compression ratio to Bytes-Per-Innermost-Chunk (BPIC) for tracking chunk-size evolution. On the FineWeb-Edu 100B dataset, the authors claim that ATDC-equipped models achieve competitive Bits-Per-Byte (BPB) relative to byte- and token-level baselines while exhibiting more stable training dynamics and better downstream performance than fixed-ratio controls.
Significance. If the empirical results are robust, ATDC would offer a practical route to stable training of hierarchical byte-level models, preserving their robustness and flexibility advantages over tokenization while addressing compression-ratio optimization. The BPIC analysis provides a useful diagnostic tool for monitoring dynamic chunking behavior.
major comments (2)
- [Abstract] Abstract: the central empirical claims of competitive BPB, more stable training dynamics, and superior downstream performance are stated without any quantitative values, error bars, ablation details, dataset splits, or compute-matched controls. This directly affects verifiability of the main result.
- [§3 (Method) and §4 (Experiments)] The curriculum-learning claim (progressively raising compression ratio stabilizes training and outperforms fixed ratios) is load-bearing for the contribution, yet the manuscript supplies no schedule design details, ablation against fixed high-compression baselines, or hyperparameter-sensitivity analysis. Without these, it remains possible that observed gains reflect unequal optimization effort rather than the adaptive mechanism.
minor comments (2)
- [§3.1] The relationship between target compression ratio and BPIC is described as an analysis tool; formalizing it as an equation or derivation would improve clarity and reproducibility.
- [Figures 2-4] Figure captions and axis labels for training curves should explicitly state the compression-ratio schedule and baseline configurations for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on improving the clarity and verifiability of our results. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims of competitive BPB, more stable training dynamics, and superior downstream performance are stated without any quantitative values, error bars, ablation details, dataset splits, or compute-matched controls. This directly affects verifiability of the main result.
Authors: We agree that the abstract would benefit from greater specificity to aid verifiability. The current abstract summarizes qualitative outcomes, but the body of the manuscript contains the supporting quantitative results on FineWeb-Edu 100B. In revision we will update the abstract to report key BPB numbers relative to byte- and token-level baselines, note the use of curriculum progression for stability, reference downstream task improvements, and explicitly mention the dataset and fixed-ratio controls. Where multiple runs exist we will add error bars or stability indicators; otherwise we will qualify single-run results. revision: yes
-
Referee: [§3 (Method) and §4 (Experiments)] The curriculum-learning claim (progressively raising compression ratio stabilizes training and outperforms fixed ratios) is load-bearing for the contribution, yet the manuscript supplies no schedule design details, ablation against fixed high-compression baselines, or hyperparameter-sensitivity analysis. Without these, it remains possible that observed gains reflect unequal optimization effort rather than the adaptive mechanism.
Authors: This point is well taken; additional methodological transparency is required. While §3 describes the progressive adjustment of the target compression ratio via curriculum learning, we will expand it to include the exact schedule (e.g., the functional form and step-wise increments of the target ratio), the BPIC tracking equations, and all relevant hyperparameters. In §4 we will add explicit ablations that compare ATDC against fixed high-compression-ratio baselines under matched compute budgets, and we will report any hyperparameter sensitivity results already obtained or note their absence. These changes will directly address the possibility of unequal optimization effort. revision: yes
Circularity Check
No circularity; empirical claims rest on external dataset evaluations
full rationale
The paper reports experimental results on FineWeb-Edu 100B comparing ATDC-equipped hierarchical models against byte- and token-level baselines, claiming competitive BPB, more stable dynamics, and superior downstream performance. No equations, derivations, or self-citations are presented that reduce these outcomes to fitted inputs or definitional loops by construction. The mentioned analysis of target compression ratio versus BPIC is framed as a tracking tool rather than a load-bearing premise that forces the results. The curriculum-learning schedule and performance claims are therefore self-contained against the reported benchmarks and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Regularizing data for improving execution time of nlp model,
T. Dang, Y . Sakai, T. Tabaru, and A. Kasagi, “Regularizing data for improving execution time of nlp model,” inThe International FLAIRS Conference Proceedings, vol. 35, 2022
2022
-
[2]
Efficient and large scale pre-training techniques for japanese natural language processing,
A. Kasagi, M. Asaoka, A. Tabuchi, Y . Oyama, T. Honda, Y . Sakai, T. Dang, and T. Tabaru, “Efficient and large scale pre-training techniques for japanese natural language processing,” in2021 Ninth International Symposium on Computing and Networking (CANDAR). IEEE, 2021, pp. 108–113
2021
-
[3]
Sentencepiece: A simple and language inde- pendent subword tokenizer and detokenizer for neural text processing,
T. Kudo and J. Richardson, “Sentencepiece: A simple and language inde- pendent subword tokenizer and detokenizer for neural text processing,” inProceedings of the 2018 Conference on EMNLP, 2018, pp. 66–71
2018
-
[4]
Boundless byte pair encoding: Breaking the pre-tokenization barrier,
C. W. Schmidt, V . Reddy, C. Tanner, and Y . Pinter, “Boundless byte pair encoding: Breaking the pre-tokenization barrier,” inSecond CLM, 2025
2025
-
[5]
Fast wordpiece tokenization,
X. Song, A. Salcianu, Y . Song, D. Dopson, and D. Zhou, “Fast wordpiece tokenization,” inProceedings of the 2021 conference on empirical methods in natural language processing, 2021, pp. 2089–2103
2021
-
[6]
Hierarchical autoregressive transformers: Combining byte- and word-level processing for robust, adaptable language models,
P. Neitemeier, B. Deiseroth, C. Eichenberg, and L. Balles, “Hierarchical autoregressive transformers: Combining byte- and word-level processing for robust, adaptable language models,” inThe 13th ICLR, 2025
2025
-
[7]
Do all languages cost the same? tokenization in the era of commercial language models,
O. Ahia, S. Kumar, H. Gonen, J. Kasai, D. R. Mortensen, N. A. Smith, and Y . Tsvetkov, “Do all languages cost the same? tokenization in the era of commercial language models,” inThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[8]
Language model tokenizers introduce unfairness between languages,
A. Petrov, E. La Malfa, P. Torr, and A. Bibi, “Language model tokenizers introduce unfairness between languages,”Advances in NeurIPS, vol. 36, pp. 36 963–36 990, 2023
2023
-
[9]
Byte latent transformer: Patches scale better than tokens,
A. Pagnoni, R. Pasunuru, P. Rodriguez, J. Nguyen, B. Muller, M. Li, C. Zhou, L. Yu, J. E. Weston, L. Zettlemoyeret al., “Byte latent transformer: Patches scale better than tokens,” inProceedings of the 63rd the ALC (V olume 1: Long Papers), 2025, pp. 9238–9258
2025
-
[10]
Hierarchical transformers are more efficient language models,
P. Nawrot, S. Tworkowski, M. Tyrolski, Ł. Kaiser, Y . Wu, C. Szegedy, and H. Michalewski, “Hierarchical transformers are more efficient language models,” inFindings of the ACL: NAACL 2022, 2022, pp. 1559–1571
2022
-
[11]
Dynamic chunking for end-to-end hierarchical sequence modeling,
S. Hwang, B. Wang, and A. Gu, “Dynamic chunking for end-to-end hierarchical sequence modeling,” inThe 14th ICLR, 2026
2026
-
[12]
The fineweb datasets: Decanting the web for the finest text data at scale,
G. Penedo, H. Kydl ´ıˇcek, A. Lozhkov, M. Mitchell, C. A. Raffel, L. V on Werra, T. Wolfet al., “The fineweb datasets: Decanting the web for the finest text data at scale,”Advances in NeurIPS, vol. 37, pp. 30 811–30 849, 2024
2024
-
[13]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Byt5: Towards a token-free future with pre-trained byte-to-byte models,
L. Xue, A. Barua, N. Constant, R. Al-Rfou, S. Narang, M. Kale, A. Roberts, and C. Raffel, “Byt5: Towards a token-free future with pre-trained byte-to-byte models,”Transactions of the ACL, vol. 10, pp. 291–306, 2022
2022
-
[15]
MEGABYTE: Predicting million-byte sequences with mul- tiscale transformers,
L. YU, D. Simig, C. Flaherty, A. Aghajanyan, L. Zettlemoyer, and M. Lewis, “MEGABYTE: Predicting million-byte sequences with mul- tiscale transformers,” inThirty-seventh Conference on NeurIPS, 2023
2023
-
[16]
Mambabyte: Token-free selective state space model,
J. Wang, T. Gangavarapu, J. N. Yan, and A. M. Rush, “Mambabyte: Token-free selective state space model,” inFirst Conference on Lan- guage Modeling, 2024
2024
-
[17]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. Re, “Efficiently modeling long sequences with structured state spaces,” inInternational Conference on Learning Representations, 2022
2022
-
[18]
M. Zakershahrak and S. Ghodratnama, “H-net++: Hierarchical dynamic chunking for tokenizer-free language modelling in morphologically-rich languages,”arXiv preprint arXiv:2508.05628, 2025
-
[19]
Transformers are SSMs: Generalized models and ef- ficient algorithms through structured state space duality,
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and ef- ficient algorithms through structured state space duality,” inProceedings of the 41st ICML, vol. 235, 2024, pp. 10 041–10 071
2024
-
[20]
GLU Variants Improve Transformer
N. Shazeer, “Glu variants improve transformer,”arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[21]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Exponential moving average of weights in deep learning: Dynamics and benefits,
D. Morales-Brotons, T. V ogels, and H. Hendrikx, “Exponential moving average of weights in deep learning: Dynamics and benefits,”Transac- tions on Machine Learning Research, 2024
2024
-
[23]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
S. Hu, Y . Tu, X. Han, C. He, G. Cui, X. Long, Z. Zheng, Y . Fang, Y . Huang, W. Zhaoet al., “Minicpm: Unveiling the potential of small language models with scalable training strategies,”arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Simple and scalable strategies to continually pre-train large language models,
A. Ibrahim, B. Th ´erien, K. Gupta, M. L. Richter, Q. G. Anthony, E. Belilovsky, T. Lesort, and I. Rish, “Simple and scalable strategies to continually pre-train large language models,”TMLR, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.