Selective QA over Conflicting Multi-Source Personal Memory: A Diagnostic Testbed and Method Comparison
Pith reviewed 2026-06-29 07:49 UTC · model grok-4.3
The pith
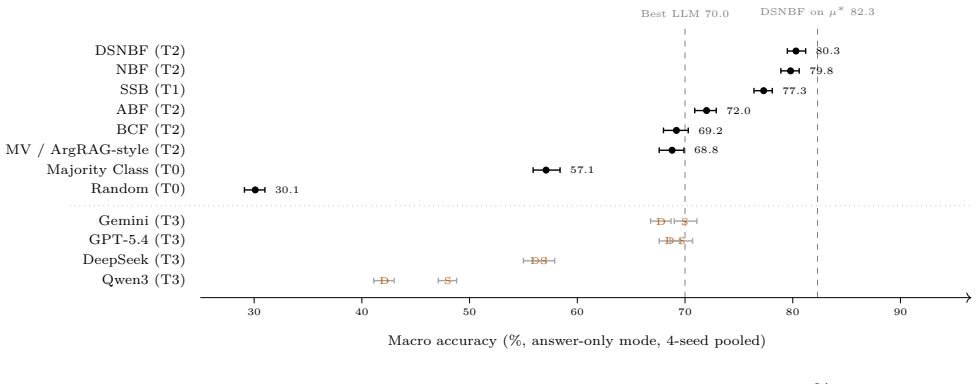
Trained fusion resolvers achieve 80.3 percent accuracy on selective QA over conflicting multi-source personal memories, outperforming prompt-only LLMs at 70 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
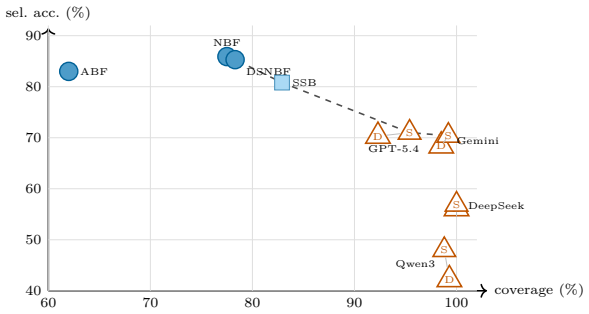
The central claim is that the introduced diagnostic testbed reveals trained fusion methods as superior to prompt-only large language models for handling conflicting evidence in multi-source personal memory scenarios, with the best fusion resolver achieving 80.3 percent accuracy versus 70.0 percent for LLMs, and improved selective accuracy when abstention is permitted.
What carries the argument
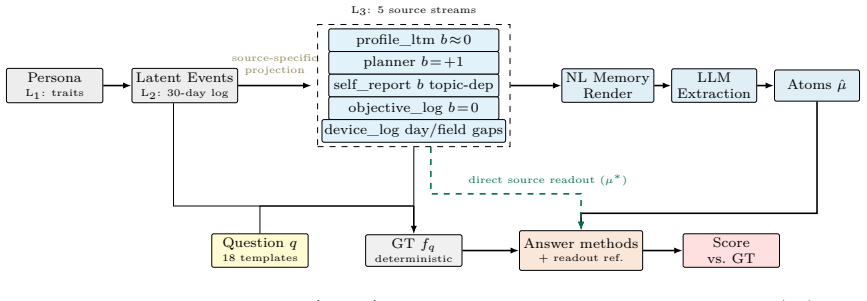
The diagnostic testbed of 18 question templates across 8 reasoning types with controlled source distortions and deterministic ground truth, which isolates the performance of the conflict-resolution step in selective QA.
If this is right
- Error sources in QA systems can be attributed more precisely to evidence issues versus resolution logic.
- Trained fusion approaches are more effective than direct LLM prompting for persistent memory applications.
- Abstention mechanisms improve accuracy at the cost of lower answer coverage.
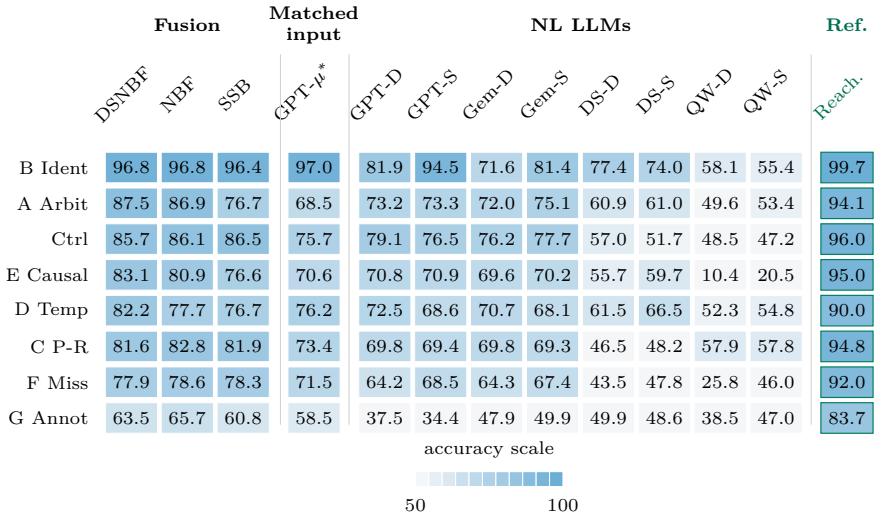
- Performance varies by reasoning type, indicating the need for method selection based on query characteristics.
Where Pith is reading between the lines
- Personal AI agents could benefit from incorporating similar fusion resolvers to manage real user memory conflicts.
- The released dataset and code enable further development of specialized conflict resolution techniques.
- Extending the benchmark to include more dynamic or user-specific distortions could test robustness in practice.
- The varying model strengths suggest potential for ensemble methods combining different approaches.
Load-bearing premise
The benchmark's 18 question templates across 8 reasoning types with controlled source distortions and deterministic ground truth sufficiently capture the complexities of real-world conflicting multi-source personal memory scenarios.
What would settle it
If evaluations on actual deployed personal AI agents with real user memories show that LLM baselines close the performance gap or reverse the ranking observed on the benchmark.
Figures

read the original abstract
Emerging personal AI agents are moving toward persistent, multi-source memory. This creates an evaluation problem: systems must decide how to use conflicting or incomplete evidence; they cannot just retrieve facts from one clean history. Existing benchmarks rarely show whether an error came from the evidence given to a method or from the method's conflict-resolution step. We study this as selective QA over conflicting multi-source personal memory: systems answer based on conflicting, sometimes incomplete sources, or abstain when evidence is insufficient. We develop a benchmark containing 18 question templates across 8 reasoning types, 480 personas, 4 random seeds, and 34,560 instances, with controlled source distortions and deterministic ground truth. We evaluate the performance of baselines without access to any source, access to a single source, structured fusion methods, and frontier LLMs. The best trained fusion resolver reaches 80.3% accuracy, while the strongest prompt-only LLM baseline reaches 70.0%. With abstention, the same resolver reaches 85.3% selective accuracy at 78.3% coverage and the best LLM reaches 71.0% selective accuracy at 95.4% coverage. Different models have different strengths across reasoning types. We release the data, code, cached model outputs, and data-generating process for reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a diagnostic benchmark for selective question answering in the presence of conflicting multi-source personal memory. The benchmark includes 18 question templates spanning 8 reasoning types, generated from 480 personas across 4 random seeds for a total of 34,560 instances, with controlled source distortions and deterministic ground truth. The authors evaluate no-source baselines, single-source access, structured fusion methods, and frontier LLMs, reporting that the best trained fusion resolver achieves 80.3% accuracy (compared to 70.0% for the strongest prompt-only LLM baseline). With an abstention option, the resolver reaches 85.3% selective accuracy at 78.3% coverage, while the best LLM reaches 71.0% selective accuracy at 95.4% coverage. Different models exhibit different strengths across reasoning types. All data, code, cached model outputs, and the data-generating process are released for reuse.
Significance. If the reported results hold, this paper makes a useful contribution by providing a controlled testbed that isolates the conflict-resolution step in multi-source memory scenarios, which is a growing challenge for personal AI agents. The distinction between trained fusion resolvers and prompt-only LLMs is clearly drawn, and the per-reasoning-type analysis highlights model-specific capabilities. The release of the full data-generating process and artifacts is a notable strength that enables reproducibility and extension by the community. The synthetic but deterministic design allows for precise error attribution, addressing a gap in existing benchmarks. The stress-test concern regarding real-world coverage does not undermine the central claims, as the work positions the benchmark explicitly as a diagnostic tool rather than a comprehensive real-world proxy.
minor comments (3)
- [§3.2] §3.2: The 8 reasoning types are listed but lack a short illustrative example for each to show how the controlled distortions are applied in the templates.
- [Table 4] Table 4 (or equivalent results table): The selective accuracy results with abstention report coverage only for the top methods; including coverage for all evaluated approaches would strengthen the comparison.
- [§6] §6: The limitations section could more explicitly note that the 18 templates are designed for controlled isolation of conflict resolution rather than exhaustive coverage of all possible real-world memory conflicts.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the benchmark's diagnostic value, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
Empirical benchmark paper with no derivations or self-referential steps
full rationale
This is a benchmark creation and evaluation paper that constructs a synthetic dataset with 18 templates across 8 reasoning types, 480 personas, controlled distortions, and deterministic ground truth, then reports accuracy numbers for fusion resolvers versus LLM baselines (with and without abstention). No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the derivation chain. The data-generating process is explicitly released for reuse, rendering all performance claims externally falsifiable on the provided instances rather than internally forced by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ground truth is deterministic given the sources and distortions
Reference graph
Works this paper leans on
-
[1]
Apple intelligence, 2024
Apple. Apple intelligence, 2024. URLhttps://developer.apple.com/apple-intelligence/
2024
-
[2]
Brenner and John DeLamater
Philip S. Brenner and John DeLamater. Social desirability bias in self-reports of physical activity: Is an exercise identity the culprit?Social Indicators Research, 117(2):489–504, 2014.https://doi.org/10. 1007/s11205-013-0359-y
2014
-
[3]
Roger Buehler, Dale Griffin, and Michael Ross. Exploring the “planning fallacy”: Why people underesti- mate their task completion times.Journal of Personality and Social Psychology, 67(3):366–381, 1994. https://doi.org/10.1037/0022-3514.67.3.366
-
[4]
Doubao phone assistant, 2025
ByteDance. Doubao phone assistant, 2025. URLhttps://o.doubao.com/. Product page. Accessed: 2026-05-04. 8
2025
-
[5]
Zhang, and Eunsol Choi
Hung-Ting Chen, Michael J.Q. Zhang, and Eunsol Choi. Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2292–2307, 2022.https://doi.org/10. 18653/v1/2022.emnlp-main.146. URLhttps://aclanthology.org/20...
2022
-
[6]
ECON: On the detection and resolution of evidence conflicts
Jiayang Cheng, Chunkit Chan, Qianqian Zhuang, Lin Qiu, Tianhang Zhang, Tengxiao Liu, Yangqiu Song, Yue Zhang, Pengfei Liu, and Zheng Zhang. ECON: On the detection and resolution of evidence conflicts. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7816– 7844, 2024. https://doi.org/10.18653/v1/2024.emnlp-mai...
-
[7]
LifeBench: A benchmark for long-horizon multi-source memory.arXiv preprint arXiv:2603.03781, 2026
Zihao Cheng, Weixin Wang, Yu Zhao, Ziyang Ren, Jiaxuan Chen, Ruiyang Xu, Shuai Huang, Yang Chen, Guowei Li, Mengshi Wang, Yi Xie, Ren Zhu, Zeren Jiang, Keda Lu, Yihong Li, Xiaoliang Wang, Liwei Liu, and Cam-Tu Nguyen. LifeBench: A benchmark for long-horizon multi-source memory.arXiv preprint arXiv:2603.03781, 2026. URLhttps://arxiv.org/abs/2603.03781
-
[8]
Leena Choi, Zhouwen Liu, Charles E. Matthews, and Maciej S. Buchowski. Validation of accelerometer wear and nonwear time classification algorithm.Medicine and Science in Sports and Exercise, 43(2): 357–364, 2011.https://doi.org/10.1249/MSS.0b013e3181ed61a3
-
[9]
Cole, Michael J.Q
Jeremy R. Cole, Michael J.Q. Zhang, Daniel Gillick, Julian Martin Eisenschlos, Bhuwan Dhingra, and Jacob Eisenstein. Selectively answering ambiguous questions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 530–543, 2023.https://doi.org/10.18653/ v1/2023.emnlp-main.35. URLhttps://aclanthology.org/2023.emnlp...
2023
-
[10]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2024. URLhttps://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. InAdvances in Neural Information Processing Systems, volume 30, pages 4878–4887. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/hash/ 4a8423d5e91fda00bb7e46540e2b0cf1-Abstract.html
2017
-
[13]
Evaluating memory in LLM agents via incremental multi-turn interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=DT7JyQC3MR
2026
-
[14]
Retrieval-augmentedgenerationwithestimationofsourcereliability
Jeongyeon Hwang, Junyoung Park, Hyejin Park, Dongwoo Kim, Sangdon Park, and Jungseul Ok. Retrieval-augmentedgenerationwithestimationofsourcereliability. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages34279–34303, Suzhou, China, November2025. Association for Computational Linguistics.https://doi.org/10.18653/...
-
[15]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2901–2910,
-
[16]
https://doi.org/10.1109/CVPR.2017.215. URL https://openaccess.thecvf.com/content_ cvpr_2017/html/Johnson_CLEVR_A_Diagnostic_CVPR_2017_paper.html
-
[17]
Selective question answering under domain shift
Amita Kamath, Robin Jia, and Percy Liang. Selective question answering under domain shift. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5684– 5696, 2020. https://doi.org/10.18653/v1/2020.acl-main.503. URL https://aclanthology.org/ 2020.acl-main.503/
-
[18]
Collaborative filtering with temporal dynamics
Yehuda Koren. Collaborative filtering with temporal dynamics. InProceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 447–456, 2009. https://doi.org/10.1145/1557019.1557072
-
[19]
InfiBench: Evaluating the question-answering ca- pabilities of code large language models
Linyi Li, Shijie Geng, Zhenwen Li, Yibo He, Hao Yu, Ziyue Hua, Guanghan Ning, Si- wei Wang, Tao Xie, and Hongxia Yang. InfiBench: Evaluating the question-answering ca- pabilities of code large language models. InAdvances in Neural Information Processing Sys- tems, volume 37, pages 128668–128698. Curran Associates, Inc., 2024. https://doi.org/ 10.52202/079...
-
[20]
Open domain question answering with conflicting contexts
Siyi Liu, Qiang Ning, Kishaloy Halder, Zheng Qi, Wei Xiao, Phu Mon Htut, Yi Zhang, Neha Anna John, Bonan Min, Yassine Benajiba, and Dan Roth. Open domain question answering with conflicting contexts. InFindings of the Association for Computational Linguistics: NAACL, pages 1838–1854, 2025. https://doi.org/10.18653/v1/2025.findings-naacl.99. URL https://ac...
-
[21]
AgentBoard: An analytical evaluation board of multi-turn LLM agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhen- zhong Lan, Lingpeng Kong, and Junxian He. AgentBoard: An analytical evaluation board of multi-turn LLM agents. InAdvances in Neural Information Processing Sys- tems, volume 37, pages 74325–74362. Curran Associates, Inc., 2024. https://doi.org/10. 52202/079017-2365. URL https://p...
2024
-
[22]
Tchrakian, Javier Carnerero-Cano, Yufang Hou, Elizabeth M
Radu Marinescu, Debarun Bhattacharjya, Junkyu Lee, Tigran T. Tchrakian, Javier Carnerero-Cano, Yufang Hou, Elizabeth M. Daly, and Alessandra Pascale. FactReasoner: A probabilistic approach to long-form factuality assessment for large language models. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 14547–14577, Suzhou, Chin...
-
[23]
Consensus or conflict? Fine-grained evaluation of conflicting answers in question-answering
Eviatar Nachshoni, Arie Cattan, Shmuel Amar, Ori Shapira, and Ido Dagan. Consensus or conflict? Fine-grained evaluation of conflicting answers in question-answering. InProceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025), pages 138–159, Suzhou, China, 2025. Association for Computational Linguistics. https://doi.org/10.18653/v1/2025....
-
[24]
Hermes: An open-source personal assistant agent, 2026
Nous Research. Hermes: An open-source personal assistant agent, 2026. URLhttps://github.com/ NousResearch/hermes-agent
2026
-
[25]
Introducing GPT-5.4, 2026
OpenAI. Introducing GPT-5.4, 2026. URL https://openai.com/index/introducing-gpt-5-4/. March 5, 2026
2026
-
[26]
OpenClaw: Open-source personal AI agent, 2025
OpenClaw Project. OpenClaw: Open-source personal AI agent, 2025. URLhttps://openclaw.ai/
2025
-
[27]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023. https://doi.org/10.48550/arXiv.2310.08560. URLhttps://arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[28]
Generative agents: Interactive simulacra of human behavior,
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 2:1–2:22, 2023.https: //doi.org/10.1145/3586183.3606763. URLhttps://doi.org/10.1145/3586...
-
[29]
Paulhus and Simine Vazire
Delroy L. Paulhus and Simine Vazire. The self-report method. In Richard W. Robins, R. Chris Fraley, and Robert F. Krueger, editors,Handbook of Research Methods in Personality Psychology, pages 224–239. Guilford Press, 2007
2007
- [30]
-
[31]
Yunjia Qi, Hao Peng, Xiaozhi Wang, Amy Xin, Youfeng Liu, Bin Xu, Lei Hou, and Juanzi Li. AGENTIF: Benchmarking instruction following of large language models in agentic scenarios.arXiv preprint arXiv:2505.16944, 2025. URLhttps://arxiv.org/abs/2505.16944
-
[32]
Qwen3-235B-A22B-Instruct-2507
Qwen. Qwen3-235B-A22B-Instruct-2507. Hugging Face model card, 2025. URLhttps://huggingface. co/Qwen/Qwen3-235B-A22B-Instruct-2507. Model ID: Qwen/Qwen3-235B-A22B-Instruct-2507. Ac- cessed: 2026-05-06
2025
-
[33]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. LaMP: When large language models meet personalization. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 7370–7392, 2024.https://doi.org/10.18653/v1/ 2024.acl-long.399. URLhttps://aclanthology.org/2024.acl-long.399/
-
[34]
Desiderata for the context use of question answering systems
Sagi Shaier, Lawrence Hunter, and Katharina von der Wense. Desiderata for the context use of question answering systems. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 777–792, 2024.https://doi.org/10. 18653/v1/2024.eacl-long.47. URLhttps://aclanthology.org/2024....
2024
-
[35]
Sagi Shaier, Ari Kobren, and Philip V. Ogren. Adaptive question answering: Enhancing language model proficiency for addressing knowledge conflicts with source citations. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17226–17239, Miami, Florida, USA, 2024. 11 Association for Computational Linguistics. https...
-
[36]
TaskBench: Benchmarking large lan- guage models for task automation
Yongliang Shen, Kaitao Song, Xu Tan, Wenqi Zhang, Kan Ren, Siyu Yuan, Weim- ing Lu, Dongsheng Li, and Yueting Zhuang. TaskBench: Benchmarking large lan- guage models for task automation. InAdvances in Neural Information Processing Sys- tems, volume 37, pages 4540–4574. Curran Associates, Inc., 2024. https://doi.org/10. 52202/079017-0148. URL https://proce...
2024
-
[37]
Reflex- ion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflex- ion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Pro- cessing Systems, volume 36, pages 8634–8652. Curran Associates, Inc., 2023. https://doi.org/ 10.52202/075280-0377. URL https://proceedings.neurips.cc/paper_files/paper/202...
-
[38]
Hamilton
Koustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and William L. Hamilton. CLUTRR: A diagnostic benchmark for inductive reasoning from text. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4506–4515, 2019.https://d...
2019
-
[39]
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. Challenging BIG-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023.https://doi.org/10.18653/...
-
[40]
URLhttps://aclanthology.org/2023.findings-acl.824/
2023
-
[41]
GBrain: Garry’s opinionated OpenClaw/Hermes agent brain, 2026
Garry Tan. GBrain: Garry’s opinionated OpenClaw/Hermes agent brain, 2026. URLhttps://github. com/garrytan/gbrain. GitHub repository. Accessed: 2026-05-04
2026
-
[42]
Gemini 3.1 Pro: A smarter model for your most complex tasks,
The Gemini Team. Gemini 3.1 Pro: A smarter model for your most complex tasks,
-
[43]
February 19, 2026
URL https://blog.google/innovation-and-ai/models-and-research/gemini-models/ gemini-3-1-pro/. February 19, 2026
2026
-
[44]
Baoliang Tian, Yuxuan Si, Jilong Wang, Lingyao Li, Zhongyuan Bao, Zineng Zhou, Tao Wang, Sixu Li, Ziyao Xu, Mingze Wang, Zhouzhuo Zhang, Zhihao Wang, Yi Ke Yun, Ke Tian, Ning Yang, and Minghui Qiu. CrossCheck-Bench: Diagnosing compositional failures in multimodal conflict resolution.Proceedings of the AAAI Conference on Artificial Intelligence, 40(31):258...
2026
-
[45]
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025.https://doi.org/10.1162/tacl_a_00754. URL https://aclanthology.org/2025.tacl-1.26/
-
[46]
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks
Jason Weston, Antoine Bordes, Sumit Chopra, Alexander M. Rush, Bart van Merriënboer, Armand Joulin, and Tomas Mikolov. Towards AI-complete question answering: A set of prerequisite toy tasks. arXiv preprint arXiv:1502.05698, 2015. URLhttps://arxiv.org/abs/1502.05698
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[47]
LongMemEval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking chat assistants on long-term interactive memory. InProceedings of the International Conference on Learning Representations, 2025. URLhttps://proceedings.iclr.cc/paper_files/ paper/2025/hash/d813d324dbf0598bbdc9c8e79740ed01-Abstract-Conference.html
2025
-
[48]
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InProceedings of the International Conference on Learning Representations, 2024. URLhttps://proceedings.iclr.cc/paper_files/ paper/2024/hash/99261adc8a6356b38bcf999bba9a26dc-Abstract-Confer...
2024
-
[49]
Knowledge conflicts for LLMs: A survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for LLMs: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541–8565, Miami, Florida, USA, November 2024. Association for Computational Linguistics.https://doi.org/10.18653/v1/2024.emnlp-main.48...
-
[50]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
A Survey on the Memory Mechanism of Large Language Model based Agents
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model based agents.arXiv preprint arXiv:2404.13501, 2024. URLhttps://arxiv.org/abs/2404.13501
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Exploring Knowledge Conflicts for Faithful LLM Reasoning: Benchmark and Method
Tianzhe Zhao, Jiaoyan Chen, Shuxiu Zhang, Haiping Zhu, Qika Lin, and Jun Liu. Exploring knowl- edge conflicts for faithful LLM reasoning: Benchmark and method.arXiv preprint arXiv:2604.11209,
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Exploring Knowledge Conflicts for Faithful LLM Reasoning: Benchmark and Method
https://doi.org/10.48550/arXiv.2604.11209. URL https://arxiv.org/abs/2604.11209. Accepted at SIGIR 2026
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.11209 2026
-
[54]
ArgRAG: Explainable retrieval augmented generation using quantitative bipolar argumentation
Yuqicheng Zhu, Nico Potyka, Daniel Hernández, Yuan He, Zifeng Ding, Bo Xiong, Dongzhuoran Zhou, Evgeny Kharlamov, and Steffen Staab. ArgRAG: Explainable retrieval augmented generation using quantitative bipolar argumentation. InProceedings of the 19th International Conference on Neurosymbolic Learning and Reasoning, volume 284 ofProceedings of Machine Lea...
-
[55]
avoid providing conflicting information that would invalidate the question
URLhttps://proceedings.mlr.press/v284/zhu25a.html. 13 Appendix Contents A Related Work 15 A.1 Comparison Table with Existing Conflict-Related Benchmarks . . . . . . . . . . . . . . . . . 15 A.2 Long-Term Memory Benchmarks and Agent Memory . . . . . . . . . . . . . . . . . . . . . . . 15 A.3 Knowledge Conflicts . . . . . . . . . . . . . . . . . . . . . . ....
-
[56]
These systems study how agents store, retrieve, and reuse memory
uses memory for verbal self-improvement. These systems study how agents store, retrieve, and reuse memory. Our evaluation target is the separate problem of resolving conflicts across systematically biased personal-memory streams. A.3 Knowledge Conflicts Xu et al. [46] survey knowledge conflicts in LLMs, categorizing them as context-memory, inter-context, ...
-
[57]
Cole et al.[9] study selective answering under question ambiguity using sampling-based confidence
apply it to QA. Cole et al.[9] study selective answering under question ambiguity using sampling-based confidence. Wen et al.[42] survey ˜100 abstention methods across the LLM lifecycle. Our testbed extends selective prediction to multi-source settings where evidence insufficiency is an explicit driver of abstention, alongside model uncertainty. A.7 Synth...
-
[58]
the prerequisite condition does not exist for this persona
evaluates code-LLM question answering, and AgentIF [30] benchmarks instruction following in agentic scenarios (tool use, system prompts, multi-step plans). These benchmarks evaluate planning, tool use, and instruction following; our benchmark focuses on multi-source conflict resolution and selective abstention over personal memory. B Benchmark Details and...
2026
-
[59]
The LLM reads raw NL memory (LLM-Direct)
NL. The LLM reads raw NL memory (LLM-Direct)
-
[60]
the answer 29 is v
Schema-Aware. The LLM receives NL memory augmented with source-bias descriptions and reliability guidance. 3.ˆµinput. A method reads structured atomsˆµextracted from NL memory. 4.µ∗input. A method reads structured atomsµ∗directly from the structuredL3 source streams. The 2×2 crossing of resolver (DSNBF vs. GPT-5.4) and input quality (ˆµvs. µ∗) enables the...
-
[61]
Read the question text carefully
-
[62]
Consider evidence from ALL relevant source sections
-
[63]
When sources disagree, use your judgment to determine the most likely true answer
-
[64]
Select exactly one answer label from the answer space (forced answer — you MUST pick one)
-
[65]
20_or_more
Also decide: if you had the option to abstain (because evidence is too conflicting or insufficient for a confident judgment), would you? Record this as would_skip (true/false). # Answering Principles - Synthesize across sources. Different sources may tell different stories. - No single source is presumed correct. Every source has potential biases. - Force...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.