Chess-World-Model: A 10M-Game Benchmark for Exact State Tracking from Chess Move Sequences
Pith reviewed 2026-06-29 08:57 UTC · model grok-4.3
The pith
Recurrent models outperform Transformers at tracking exact chess board states from move sequences, with a random-play split revealing scale limitations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
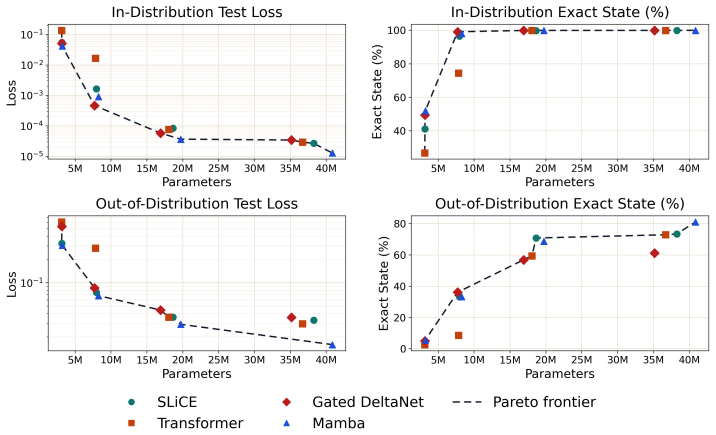
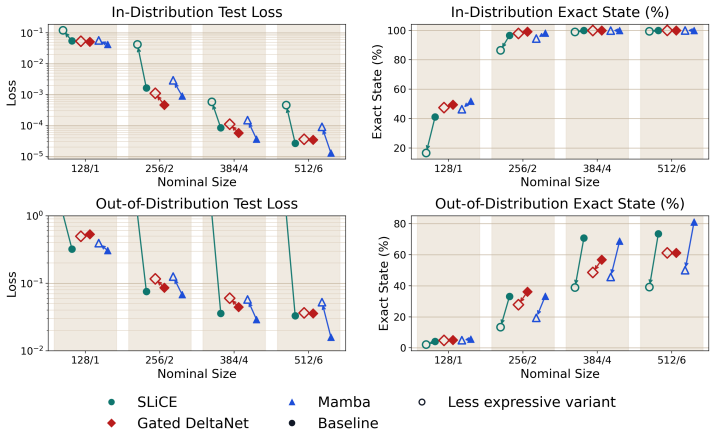
The recurrent models strongly outperform the Transformer at 3 and 8 million parameters. Real-game performance saturates above 18 million parameters, but the random-uniform split remains discriminative up to 40 million, exposing failures otherwise hidden by scale. Additionally, ablations show that less expressive state-transition mechanisms reduce performance on the out-of-distribution split for all three recurrent models.
What carries the argument
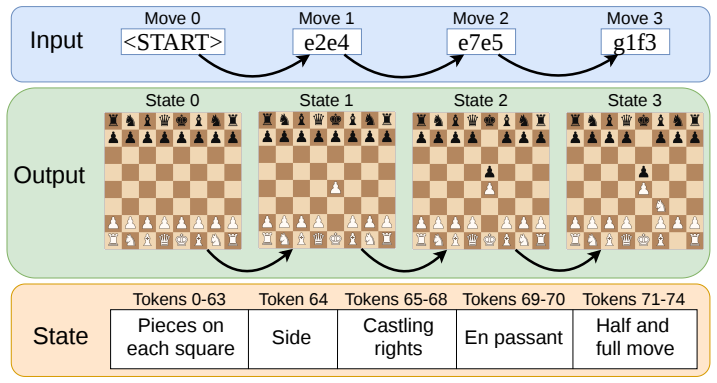
Chess-World-Model benchmark that supplies move sequences and requires exact next-board-state prediction, using a real-game split plus a uniformly random legal-play split to compare causal Transformer, block-diagonal SLiCE, Mamba-3, and Gated DeltaNet under identical training conditions.
If this is right
- Recurrent models learn chess transition rules more effectively than Transformers when parameter count is limited to 3 or 8 million.
- Accuracy on real human games plateaus once models exceed 18 million parameters across the tested architectures.
- The uniformly random legal play split continues to differentiate model performance up to 40 million parameters.
- Reducing the expressiveness of state-transition matrices lowers accuracy on the random split for all recurrent models tested.
Where Pith is reading between the lines
- The benchmark could be applied to other state-tracking domains to check whether scale hides similar rule-learning gaps.
- Architectural choices for handling state updates may matter more than raw size when the task requires following explicit transition rules.
- Models that pass the random split may generalize better to novel planning or simulation tasks outside chess.
Load-bearing premise
The uniformly random legal play split isolates whether models learn the transition rules rather than shortcuts from common human positions, and all models were trained under a truly matched interface and protocol.
What would settle it
A result in which a Transformer reaches the same accuracy as the recurrent models on the random-uniform split once both reach 40 million parameters would show that the split does not expose architecture-specific failures hidden by scale.
Figures
read the original abstract
World models require state tracking, which is the ability to maintain a correct latent state across action sequences. Existing benchmarks are often synthetic or language-based, limiting their value as tests of structured state updates in realistic domains. We introduce Chess-World-Model, a large-scale state-tracking benchmark built from 10 million real chess games, where models predict the exact board state reached after a sequence of legal moves. Alongside a held-out real-game split, we include an out-of-distribution split from uniformly random legal play, which tests whether models learn the transition rules rather than shortcuts from common human positions. Prior theoretical and empirical work has shown that Transformers struggle to state-track, while input-dependent linear RNNs require expressive state-transition matrices to do so. We therefore benchmark a causal Transformer, block-diagonal SLiCE, Mamba-3, and Gated DeltaNet with negative eigenvalues under a matched interface and training protocol. The recurrent models strongly outperform the Transformer at 3 and 8 million parameters. Real-game performance saturates above 18 million parameters, but the random-uniform split remains discriminative up to 40 million, exposing failures otherwise hidden by scale. Additionally, ablations show that less expressive state-transition mechanisms reduce performance on the out-of-distribution split for all three recurrent models. Together, these results establish Chess-World-Model as a practical large-scale benchmark for state tracking that exposes failures model scale would otherwise conceal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Chess-World-Model, a benchmark built from 10 million real chess games for evaluating exact board-state prediction after legal move sequences. It includes a held-out real-game split and an OOD split drawn from uniformly random legal play, intended to test transition-rule learning rather than positional shortcuts. Under a matched training protocol, the authors compare a causal Transformer to three recurrent architectures (block-diagonal SLiCE, Mamba-3, Gated DeltaNet) and report that recurrent models strongly outperform the Transformer at 3 M and 8 M parameters; real-game performance saturates above 18 M parameters while the random split remains discriminative up to 40 M parameters. Ablations on state-transition expressiveness are also presented.
Significance. If the central empirical claims hold after verification of the OOD split, the benchmark would supply a realistic, large-scale testbed for state tracking that reveals architectural differences hidden by scale on in-distribution data. The scale (10 M games), the controlled OOD construction, and the explicit comparison of state-transition mechanisms constitute concrete strengths for an empirical contribution in this area.
major comments (1)
- [Abstract] Abstract (and the description of the OOD split): the claim that the uniformly random legal-play split isolates transition-rule learning from human-position shortcuts is load-bearing for the reported performance gaps and saturation behavior, yet the manuscript provides no quantitative verification (e.g., move-distribution statistics, piece-density comparisons, or legality-pattern analysis) that residual regularities have been eliminated. Without such evidence the outperformance and scale-discriminative results on the random split cannot be unambiguously attributed to state-tracking capacity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the importance of rigorously verifying the properties of the OOD split. We address the comment below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the description of the OOD split): the claim that the uniformly random legal-play split isolates transition-rule learning from human-position shortcuts is load-bearing for the reported performance gaps and saturation behavior, yet the manuscript provides no quantitative verification (e.g., move-distribution statistics, piece-density comparisons, or legality-pattern analysis) that residual regularities have been eliminated. Without such evidence the outperformance and scale-discriminative results on the random split cannot be unambiguously attributed to state-tracking capacity.
Authors: We agree that explicit quantitative verification would make the isolation claim more robust and unambiguous. By construction, the OOD split is generated via uniform sampling over legal moves at each step (starting from the initial position), which produces move distributions, piece densities, and position regularities that differ systematically from human games; however, we did not include supporting statistics in the original submission. In the revision we will add: (i) histograms comparing move-type frequencies (e.g., pawn vs. piece moves, captures) between splits, (ii) average piece-density maps across the board, and (iii) analysis of common legality patterns (e.g., frequency of checks or castling). These will be placed in a new subsection of the data section and referenced from the abstract. We believe this addition will directly address the concern while preserving the central empirical findings. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential predictions
full rationale
The paper introduces an empirical benchmark for state tracking using chess move sequences and compares model families (Transformer vs. recurrent variants) under matched training protocols. No equations, parameter-fitting steps presented as predictions, or derivation chains appear in the provided text. Claims rest on experimental results from real-game and uniform-random splits rather than any self-definition, fitted-input renaming, or load-bearing self-citation. The central performance gaps are externally falsifiable via the described splits and ablations, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Legal chess moves define deterministic state transitions that can be exactly computed from move sequences
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Ballas (2023). “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Assran, M., A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. Muckl...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Gaussian Error Linear Units (GELUs)
Fiekas, N. (2024).python-chess: A Chess Library for Python.URL: https : / / github . com / niklasf/python-chess. Grazzi, R., J. Siems, J. K. H. Franke, A. Zela, F. Hutter, and M. Pontil (2025). “Unlocking State- Tracking in Linear RNNs Through Negative Eigenvalues”. In:Proceedings of the 13th International Conference on Learning Representations (ICLR). Gu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
GLU Variants Improve Transformer
Meyer-Kahlen, S. and R. Huber (2000).Universal Chess Interface. https://www.shredderchess. com/chess- features/uci- universal- chess- interface.html. UCI protocol specifica- tion. Nanda, N., A. Lee, and M. Wattenberg (2023). “Emergent Linear Representations in World Models of Self-Supervised Sequence Models”. In:Proceedings of the 6th BlackboxNLP Workshop...
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[4]
with β1 = 0.9, global gradient clipping at 1.0 (Pascanu et al., 2013), dropout 0.1 (Srivastava et al., 2014), feed-forward multiplier 4, and batch size
2013
-
[5]
On GPUs supporting tensor cores, TF32 matrix multiplication is enabled
The value of β2 is selected by the sweep. On GPUs supporting tensor cores, TF32 matrix multiplication is enabled. Mamba-3 is trained with bfloat16 mixed precision, while the other model families are trained without mixed-precision autocasting. The first-stage sweep consists of 4×4×4×3×3×3 = 1728 one-epoch runs over model family, model size, learning rate,...
2017
-
[6]
The diagonal SLiCE ablation replaces the block-diagonal transition with a diagonal transition while keeping the rest of the configuration fixed
Each layer uses a GELU feed-forward MLP (Hendrycks et al., 2016), RMSNorm (Zhang et al., 2019), and dropout on the residual path (Srivastava et al., 2014). The diagonal SLiCE ablation replaces the block-diagonal transition with a diagonal transition while keeping the rest of the configuration fixed. Gated DeltaNet.The main Gated DeltaNet model uses the sa...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.