When Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
Pith reviewed 2026-06-29 00:04 UTC · model grok-4.3
The pith
In hybrid multi-agent systems, the best mix of on-device small models and cloud large models varies sharply by task, and using more powerful cloud models does not always improve outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
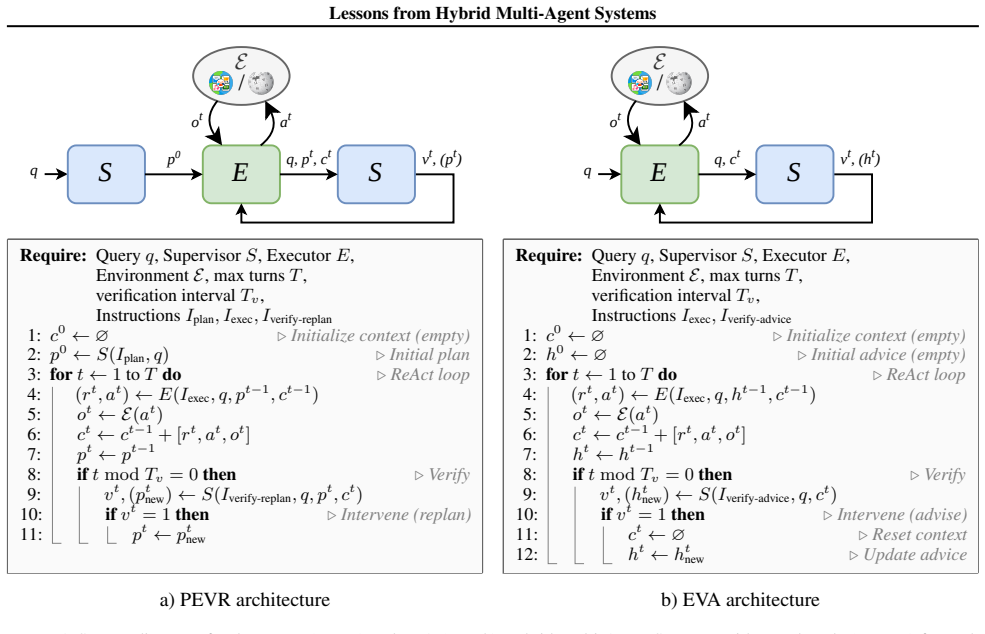
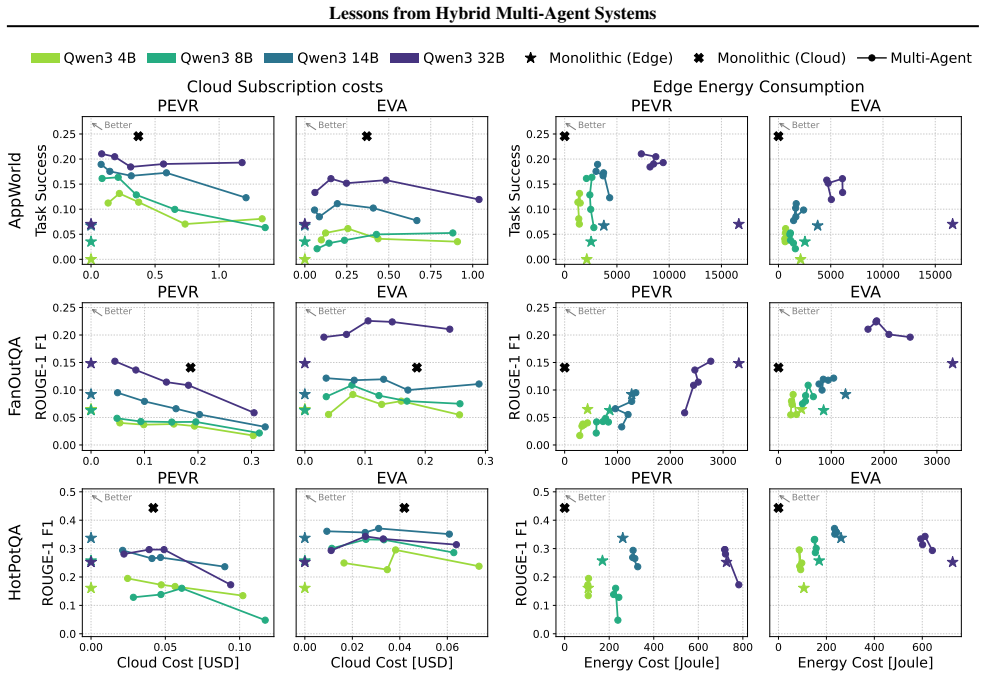
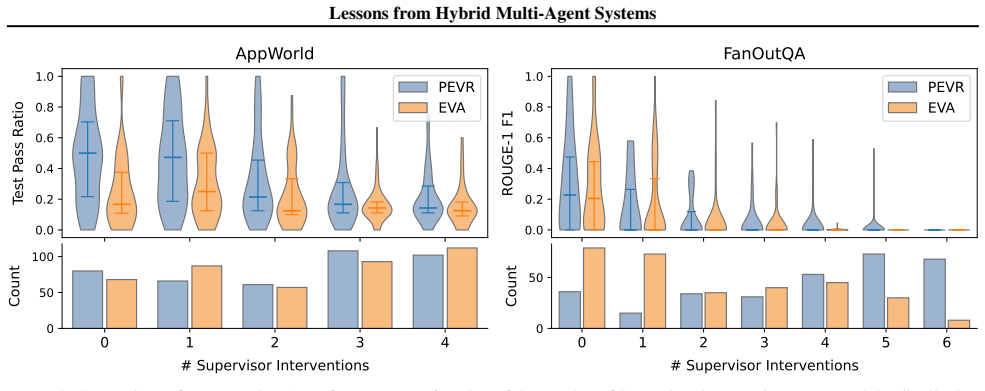
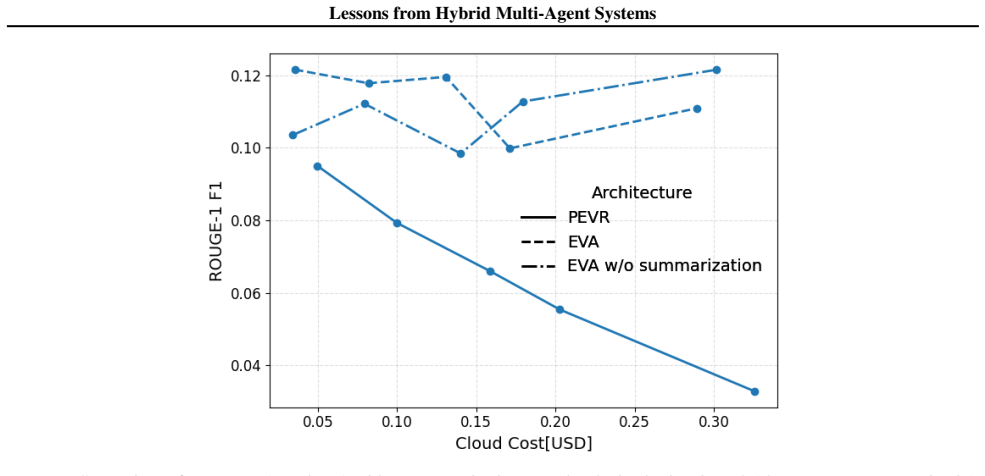
Adapting two representative MAS architectures to support hybrid inference reveals that SLMs can effectively benefit from LLM assistance, yet the optimal architecture is highly task-dependent, and greater frontier-level compute does not consistently translate to better performance across the Pareto frontier of power, cost, and performance.
What carries the argument
Two adapted representative multi-agent system architectures that enable hybrid on-device and cloud model inference, used to map shifts along the Pareto frontier of accuracy, cost, and energy consumption.
If this is right
- Design choices in hybrid systems must be tailored to individual tasks rather than applied uniformly.
- Selective use of LLM assistance can enhance SLM performance without requiring the highest-end cloud models.
- Energy use on edge devices can be optimized by routing decisions within the multi-agent framework.
- Monetary costs of inference can be lowered by avoiding default reliance on frontier LLMs.
- Performance gains from additional compute are not guaranteed and require task-specific validation.
Where Pith is reading between the lines
- Agent systems could benefit from dynamic architecture selection based on detected task features.
- Further experiments with more architectures might uncover general rules for when hybrid designs outperform pure on-device or pure cloud approaches.
- These findings could influence mobile AI applications by favoring lighter models with occasional cloud boosts over always-on large models.
- Similar task-dependence may appear in other hybrid computing scenarios beyond language agents.
Load-bearing premise
That studying two representative MAS architectures sufficiently covers the hybrid design space and that the task-dependence observed holds for other tasks and models.
What would settle it
Running the same tasks with a third distinct MAS architecture or additional model combinations and finding that one architecture consistently outperforms or that frontier models always improve results.
Figures









read the original abstract
The design space of agentic AI inference spans two extremes: frontier large language models (LLMs), typically hosted in the cloud and offering strong performance across a wide range of tasks at substantially high cost, and more cost-efficient small language models (SLMs), which are amenable to on-device inference. Hybrid multi-agent systems (MASs) combining on-device and cloud models offer a promising middle ground, but they also introduce a complex and poorly understood design space in which task accuracy, monetary cost, and edge energy consumption are tightly coupled; in the absence of general design principles, hybrid components, although not the most prevalent choice, are typically introduced through ad hoc decisions tailored to specific domains. In this work, we examine this design space more systematically. We adapt two representative MAS architectures to support hybrid inference and study how individual design choices shift the operating point along the Pareto frontier of power, cost, and performance. Our findings paint a nuanced picture of hybrid MAS design: while SLMs can effectively benefit from LLM assistance, the optimal architecture is highly task-dependent, and greater frontier-level compute does not consistently translate to better performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the design space of hybrid multi-agent systems (MAS) that integrate cloud-hosted frontier LLMs with on-device SLMs. The authors adapt two representative MAS architectures to enable hybrid inference and examine how individual design choices affect the Pareto frontier across task accuracy, monetary cost, and edge energy consumption. The central claims are that SLMs can benefit from LLM assistance, that the optimal architecture is highly task-dependent, and that greater frontier-level compute does not consistently translate to better performance.
Significance. If the empirical patterns hold under broader validation, the work would provide timely, practically relevant guidance on hybrid agentic systems by showing that task-specific optimization is required and that assumptions of monotonic compute benefits do not hold. This addresses an important gap between ad-hoc hybrid deployments and systematic design principles.
major comments (2)
- [Abstract] Abstract: The claim that the study examines the hybrid design space 'more systematically' and that 'the optimal architecture is highly task-dependent' is load-bearing for the headline conclusions, yet rests on adaptation of only two MAS architectures. No argument, ablation, or coverage analysis is supplied to show that these two span the relevant axes (communication topology, role decomposition, routing logic). If a third architecture yields different Pareto fronts or reverses the task-dependence pattern, the generalization does not follow from the experiments performed.
- [Abstract and experimental design] The non-monotonic compute result and the assertion that greater frontier-level compute 'does not consistently translate to better performance' require evidence that the observed patterns are properties of the hybrid MAS space rather than artifacts of the two chosen architectures. Without a parametric family or additional architectures, the task-dependence conclusion risks being architecture-specific.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the scope and generalizability of our experimental design. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the study examines the hybrid design space 'more systematically' and that 'the optimal architecture is highly task-dependent' is load-bearing for the headline conclusions, yet rests on adaptation of only two MAS architectures. No argument, ablation, or coverage analysis is supplied to show that these two span the relevant axes (communication topology, role decomposition, routing logic). If a third architecture yields different Pareto fronts or reverses the task-dependence pattern, the generalization does not follow from the experiments performed.
Authors: The two architectures were selected because they instantiate distinct coordination paradigms—one centralized with explicit role decomposition and one decentralized with iterative collaboration—thereby varying communication topology and routing logic. We will revise the manuscript to add an explicit subsection justifying this selection against the relevant design axes and acknowledging the coverage limitations. revision: yes
-
Referee: [Abstract and experimental design] The non-monotonic compute result and the assertion that greater frontier-level compute 'does not consistently translate to better performance' require evidence that the observed patterns are properties of the hybrid MAS space rather than artifacts of the two chosen architectures. Without a parametric family or additional architectures, the task-dependence conclusion risks being architecture-specific.
Authors: The non-monotonicity appeared consistently across both architectures and the evaluated tasks. Nevertheless, we agree that stronger evidence would require additional architectures. In revision we will qualify the abstract and conclusion statements to indicate that the patterns hold for the studied representative architectures and note the desirability of broader validation. revision: partial
Circularity Check
No circularity; empirical claims rest on direct experiments
full rationale
The paper conducts an empirical study by adapting two MAS architectures and measuring shifts along the Pareto frontier of power, cost, and performance across tasks. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. Central claims about task-dependence and non-monotonic compute benefits are presented as observations from the experiments rather than derived by construction from prior inputs or citations. The limitation noted in the skeptic headline concerns experimental coverage, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lost in the middle: How language models use long contexts
URL https://www.adamcasson.com/ posts/transformer-flops. Cemri, M., Pan, M. Z., Yang, S., Agrawal, L. A., Chopra, B., Tiwari, R., Keutzer, K., Parameswaran, A., Klein, D., Ramchandran, K., Zaharia, M., Gonzalez, J. E., and Stoica, I. Why do multi-agent LLM systems fail?arXiv [cs.AI], October 2025. Chen, S., Liu, Y ., Han, W., Zhang, W., and Liu, T. A surv...
work page internal anchor Pith review doi:10.1162/tacl 2025
-
[2]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Association for Computational Linguistics. Su, H., Diao, S., Lu, X., Liu, M., Xu, J., Dong, X., Fu, Y ., Belcak, P., Ye, H., Yin, H., Dong, Y ., Bakhturina, E., Yu, T., Choi, Y ., Kautz, J., and Molchanov, P. ToolOrches- tra: Elevating intelligence via efficient model and tool orchestration.arXiv [cs.CL], 26 November 2025. Tongyi DeepResearch Team, Li, B....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
decide whether execution should continue or be stopped, and
-
[4]
AUTHORITY AND SCOPE: - The PLAN is authoritative
ONLY IF you decide to stop execution (INTERVENE), also produce a replacement plan for the Executor. AUTHORITY AND SCOPE: - The PLAN is authoritative. - The Executor is expected to follow the plan exactly. - The MEMORY is the ground-truth record of what has actually happened. INPUTS: - Plan: <PLAN> {{ plan }} </PLAN> - Executor context: <EXECUTOR CONTEXT> ...
-
[5]
<SUMMARY>: a concise, factual summary of completed work
-
[6]
AUTHORITY AND SCOPE: - The USER QUERY defines the intended goal
<ADVICE>: a short plan for remaining steps, plus concise corrections for any recurrent mistakes. AUTHORITY AND SCOPE: - The USER QUERY defines the intended goal. - The MEMORY is the ground-truth record of what the Executor has done. - The Executor is expected to act rationally and make progress. 21 Lessons from Hybrid Multi-Agent Systems INPUTS: - User qu...
2018
-
[7]
**Persistent Runtime**: Variables persist across interactions within the same episode
-
[8]
**Python Syntax**: Use standard Python code (loops, conditionals, variable assignments)
-
[9]
**Code Delimiters**: Wrap your code in`<code>...</code>`tags
-
[10]
Albert Einstein
**Print Outputs**: You MUST`print()`results to see them, otherwise only execution status is returned ### Example Interaction: <code> # Get Spotify recommendations recommendations = apis.spotify.show_recommendations(access_token=spotify_access_token, page_index=0) print(recommendations) </code> --- ## API Discovery Tools Since there are 400+ APIs, you cann...
-
[11]
**Start with Discovery**: Use`apis.api_docs.show_api_descriptions()`to find relevant APIs for the task
-
[12]
**Get Details**: Use`apis.api_docs.show_api_doc()`for specific API documentation
-
[13]
about the user
**Get Credentials**: Use`apis.supervisor`tools ()'show_active_task', 'complete_task', 'show_profile', 'show_addresses', 'show_payment_cards', 'show_account_passwords') to obtain necessary information, passwords, addresses, etc. about the user
-
[14]
Use obtained credentials to authenticate with the 'login' API for the target app
**Authenticate**: All Apps (except for 'supervisor' and 'api_docs') require authentication to use their APIs. Use obtained credentials to authenticate with the 'login' API for the target app. This will return an access_token for subsequent API calls in that app
-
[15]
**Execute Operations**: Write Python code to accomplish the task using API calls
-
[16]
**Print Results**: Always`print()`outputs to see results
-
[17]
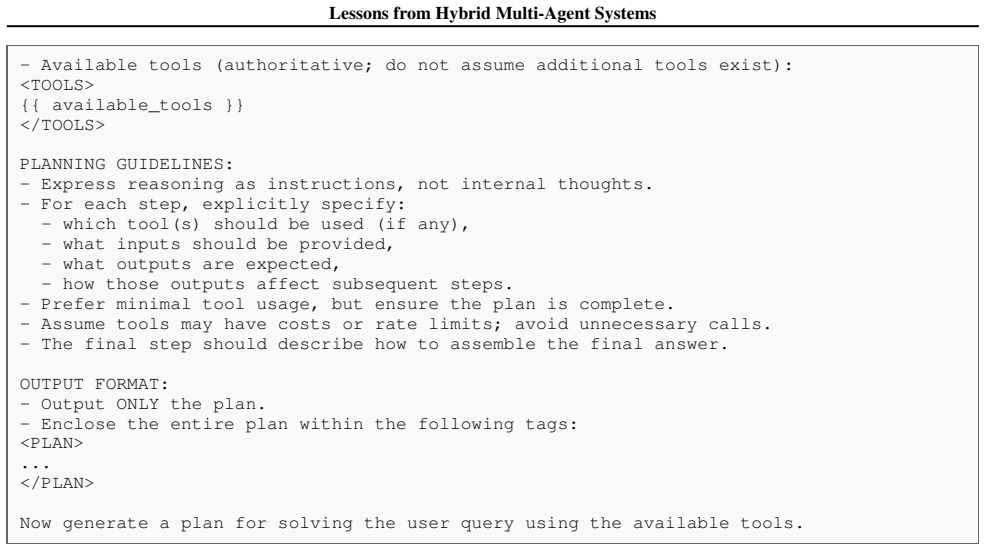
Name the artist most recommended to me on Spotify
**Complete Task**: Call`apis.supervisor.complete_task()`when done ### Example trajectory Question: "Name the artist most recommended to me on Spotify." Code generated across ReAct steps: # Step 1: Discover available Spotify APIs <code> spotify_apis = apis.api_docs.show_api_descriptions(app_name='spotify') print(spotify_apis) </code> # Step 2: Get detailed...
-
[18]
**Always use`<code>...</code>`delimiters ** around your Python code
-
[19]
**Always`print()`results ** to see outputs (otherwise you only see execution status)
-
[20]
**Use API discovery tools** to find the right APIs for your task
-
[21]
**Get user credentials** before making API calls that require authentication
-
[22]
**Complete the task** with`apis.supervisor.complete_task()`when done
-
[23]
Did Richard Feynman win a Nobel Prize?
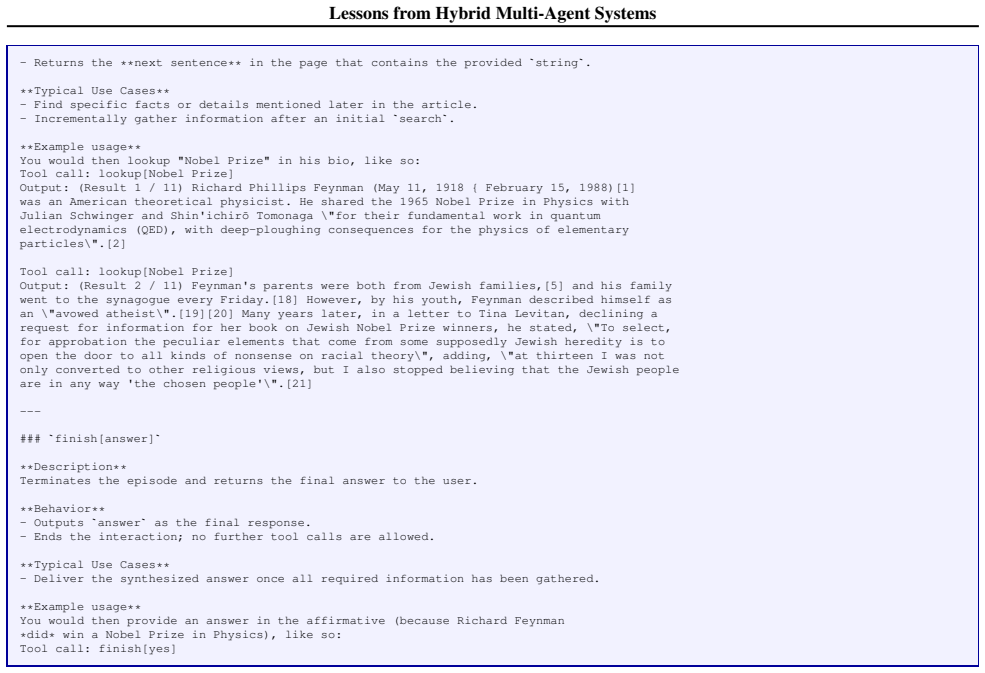
**Evaluation is comprehensive**: Both your answer and environment state are checked ``` Figure 13.Executor tool prompt for the AppWorld environment. 26 Lessons from Hybrid Multi-Agent Systems D.3. Wikipedia Environment We implement a lightweight interactive environment that enables an agent to consult Wikipedia during multi-step reasoning. The design is b...
2022
-
[24]
- Expected output: A list of API names and their brief descriptions
**Discover Amazon APIs** - Use`apis.api_docs.show_api_descriptions(app_name='amazon')`to retrieve a list of available APIs for interacting with the Amazon app. - Expected output: A list of API names and their brief descriptions. This will help identify the API to fetch the cart details
-
[25]
- Expected output: Detailed documentation for the cart API, including parameter requirements and example responses
**Get Detailed Documentation for Cart API** - Use`apis.api_docs.show_api_doc(app_name='amazon', api_name='[CART_API_NAME]')`(replace `[CART_API_NAME]`with the identified API from step 1) to understand the inputs and outputs required for retrieving cart details. - Expected output: Detailed documentation for the cart API, including parameter requirements an...
-
[26]
- Expected output: A dictionary containing account credentials, including the Amazon account username and password
**Discover User Credentials for Amazon** - Use`apis.supervisor.show_account_passwords()`to retrieve the user's stored Amazon credentials. - Expected output: A dictionary containing account credentials, including the Amazon account username and password
-
[27]
- Expected input: Username and password for the Amazon account
**Log in to Amazon** - Use the retrieved credentials to log in to the Amazon app using the`login`API. - Expected input: Username and password for the Amazon account. - Expected output: An`access_token`to authenticate subsequent API calls to Amazon. 28 Lessons from Hybrid Multi-Agent Systems
-
[28]
- Expected input: The user's`access_token`
**Retrieve Cart Details** - Use the identified cart API from step 2 with the`access_token`obtained in step 4 to fetch the cart details. - Expected input: The user's`access_token`. - Expected output: A list of items in the cart, including their names and prices
-
[29]
- Expected output: The total cost as a numeric value
**Calculate Total Cart Cost** - Parse the retrieved cart details to calculate the total cost of all items in the cart, excluding tax and delivery fees. - Expected output: The total cost as a numeric value
-
[30]
- Expected output: A list of API names and their brief descriptions
**Discover Venmo APIs** - Use`apis.api_docs.show_api_descriptions(app_name='venmo')`to retrieve a list of available APIs for interacting with the Venmo app. - Expected output: A list of API names and their brief descriptions. This will help identify the API for requesting money
-
[31]
- Expected output: Detailed documentation for the money request API, including parameter requirements and example responses
**Get Detailed Documentation for Money Request API** - Use`apis.api_docs.show_api_doc(app_name='venmo', api_name='[REQUEST_API_NAME]')`(replace `[REQUEST_API_NAME]`with the identified API from step 7) to understand the inputs and outputs required for requesting money. - Expected output: Detailed documentation for the money request API, including parameter...
-
[32]
- Expected output: A dictionary containing account credentials, including the Venmo account username and password
**Discover User Credentials for Venmo** - Use`apis.supervisor.show_account_passwords()`to retrieve the user's stored Venmo credentials. - Expected output: A dictionary containing account credentials, including the Venmo account username and password
-
[33]
- Expected input: Username and password for the Venmo account
**Log in to Venmo** - Use the retrieved credentials to log in to the Venmo app using the`login`API. - Expected input: Username and password for the Venmo account. - Expected output: An`access_token`to authenticate subsequent API calls to Venmo
-
[34]
Reimbursement for Amazon cart items
**Request Money from Adam** - Use the identified money request API from step 8 with the`access_token`obtained in step 10 to request the calculated total cart cost from Adam. - Expected input: Adam's Venmo username or email, the calculated total cost (from step 6), and a note indicating the reason for the request (e.g., "Reimbursement for Amazon cart items...
-
[35]
No specific answer needs to be provided, as the task is evaluated based on the successful execution of the steps
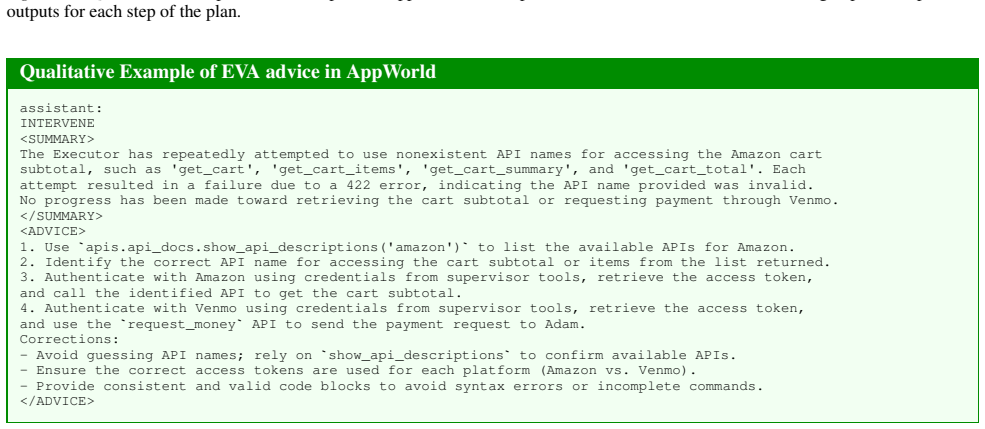
**Complete the Task** - Use`apis.supervisor.complete_task()`to signal task completion. No specific answer needs to be provided, as the task is evaluated based on the successful execution of the steps. - Expected output: Task completion confirmation. </REPLAN> Figure 15.Qualitative Example of PEVR replan in AppWorld. The replan is detailed and actionable, ...
-
[36]
Use`apis.api_docs.show_api_descriptions('amazon')`to list the available APIs for Amazon
-
[37]
Identify the correct API name for accessing the cart subtotal or items from the list returned
-
[38]
Authenticate with Amazon using credentials from supervisor tools, retrieve the access token, and call the identified API to get the cart subtotal
-
[39]
Corrections: - Avoid guessing API names; rely on`show_api_descriptions`to confirm available APIs
Authenticate with Venmo using credentials from supervisor tools, retrieve the access token, and use the`request_money`API to send the payment request to Adam. Corrections: - Avoid guessing API names; rely on`show_api_descriptions`to confirm available APIs. - Ensure the correct access tokens are used for each platform (Amazon vs. Venmo). - Provide consiste...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.