Convergence Theory for Iterative LLM-Based Neural Architecture Search: A Parametric Cross-Entropy Framework with Closed-Form Proxy Reliability
Pith reviewed 2026-06-29 08:54 UTC · model grok-4.3
The pith
LLM-based neural architecture search is equivalent to a parametric cross-entropy method that yields monotonic quality gains and a closed-form proxy reliability expression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
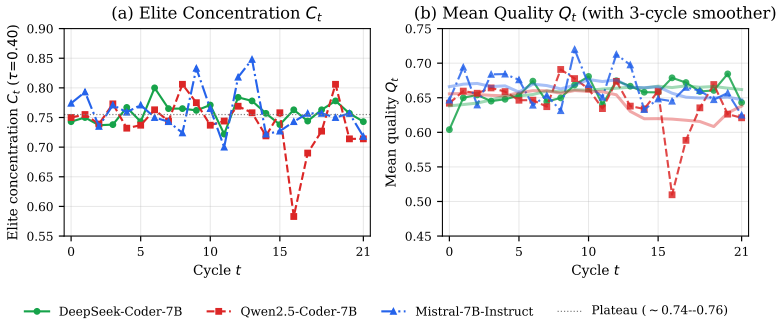
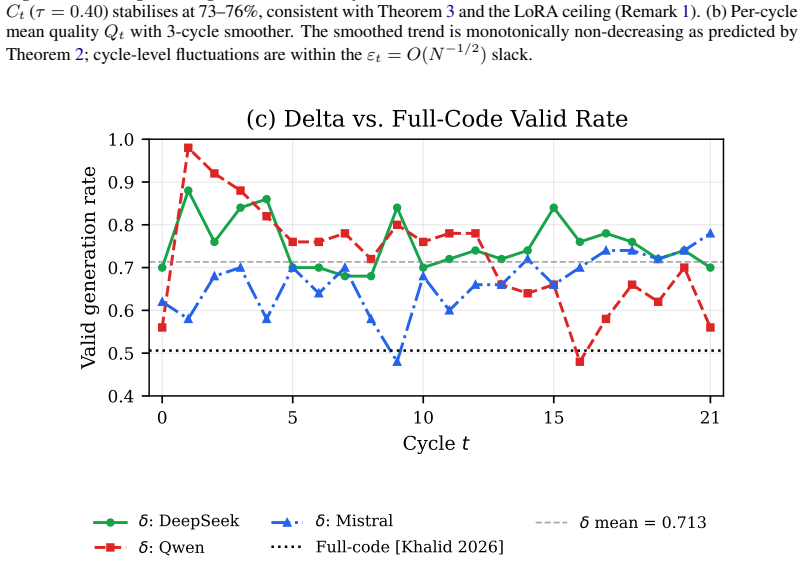
Iterative LLM-NAS is modeled as a parametric Cross-Entropy (CE) method over executable programs. Iterative LLM fine-tuning on elite architectures is equivalent to the CE update restricted to the LLM parametric family. Expected architecture quality is monotonically non-decreasing across cycles. Elite-set probability converges to a fixed point at a geometric rate C_t >= 1-(1-rho_0)^t. Delta-based generation achieves a strictly higher valid-generation rate than full-code generation under a first-order Markov token-error model. The MinHash-Jaccard novelty filter prevents mode collapse. Proxy reliability admits the closed-form rho_S = (6/pi) arcsin(rho_P(SNR)/2), so trustworthy proxy-based rankin
What carries the argument
Parametric cross-entropy method over executable programs, which supplies the equivalence between LLM fine-tuning and the CE update together with the monotonicity and convergence guarantees.
If this is right
- Elite-set probability converges geometrically to a fixed point.
- Delta-based generation yields a strictly higher valid-program rate than full-code generation.
- The MinHash-Jaccard filter blocks mode collapse.
- Trustworthy proxy rankings require architecture variance to greatly exceed noise variance.
Where Pith is reading between the lines
- The same parametric-CE equivalence could be tested on iterative LLM loops for tasks other than architecture search.
- The closed-form proxy formula supplies a pre-search diagnostic for choosing SNR thresholds.
- Removing the Markov token-error assumption might still allow comparison of generation strategies via direct counting of valid outputs.
Load-bearing premise
The token errors follow a first-order Markov process is required to establish that delta-based generation produces more valid programs than full-code generation.
What would settle it
An experiment in which measured expected architecture quality decreases from one cycle to the next would falsify the monotonicity result.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as generators in iterative neural architecture search (NAS), yet no formal convergence theory exists for this class of algorithms. We model iterative LLM-NAS as a parametric Cross-Entropy (CE) method over executable programs and prove six results: (1) iterative LLM fine-tuning on elite architectures is equivalent to the CE update restricted to the LLM parametric family; (2) expected architecture quality is monotonically non-decreasing across cycles; (3) elite-set probability converges to a fixed point at a geometric rate C_t >= 1-(1-rho_0)^t; (4) delta-based generation achieves a strictly higher valid-generation rate than full-code generation under a first-order Markov token-error model; (5) the MinHash-Jaccard novelty filter prevents mode collapse; (6) proxy reliability admits the closed-form rho_S = (6/pi) arcsin(rho_P(SNR)/2), yielding the practical diagnostic sigma^2_arch >> sigma^2_noise as a necessary condition for trustworthy proxy-based rankings. Testing against a 22-cycle, three-LLM, six-dataset experiment with 3,300 generated architectures confirms two predictions quantitatively, two at direction-of-effect level, and explains the proxy-reliability ceiling effect previously reported empirically but left unexplained.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models iterative LLM-based neural architecture search as a parametric cross-entropy (CE) method over executable programs. It proves six results: (1) LLM fine-tuning on elites equals the CE update in the LLM family; (2) expected architecture quality is monotonically non-decreasing; (3) elite-set probability converges geometrically at rate C_t >= 1-(1-rho_0)^t; (4) delta-based generation yields strictly higher valid rate than full-code under a first-order Markov token-error model; (5) MinHash-Jaccard filter prevents mode collapse; (6) proxy reliability has closed form rho_S = (6/pi) arcsin(rho_P(SNR)/2), with diagnostic sigma^2_arch >> sigma^2_noise. A 22-cycle experiment with three LLMs, six datasets, and 3300 architectures confirms two predictions quantitatively and two directionally.
Significance. If the derivations hold, the work supplies the first formal convergence theory for LLM-NAS, linking CE optimization to LLM fine-tuning and providing a closed-form diagnostic for proxy trustworthiness that explains prior empirical ceilings. The 3300-architecture experiment offers concrete quantitative support for several predictions, which strengthens the contribution. The framework could inform practical choices in generation strategy and proxy use within iterative NAS pipelines.
major comments (3)
- [Abstract, result (4)] Abstract, result (4): The strict superiority of delta-based generation is derived under a first-order Markov token-error model (P(error at t | history) = P(error at t | token t-1)). LLM code generation exhibits long-range syntactic and semantic dependencies that violate this assumption, so the strict inequality does not necessarily hold and the result is not load-bearing for the overall framework without a more general error model.
- [Abstract, result (6)] Abstract, result (6): The closed-form rho_S = (6/pi) arcsin(rho_P(SNR)/2) is obtained directly from the CE modeling choice and the Markov error model. This creates a circularity risk: the experimental confirmation of the proxy-reliability prediction may reduce to a quantity defined by the modeling assumptions rather than providing an independent test of the theory.
- [Abstract, experimental confirmation] Abstract, experimental section: The manuscript states that two predictions are confirmed quantitatively on 3300 architectures, but without the full derivations, explicit definitions of the parametric family, or details on how the predictions were isolated from the modeling assumptions, the empirical support cannot be fully assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond point-by-point to the three major comments below, clarifying the modeling assumptions and scope of our results while indicating revisions where they strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, result (4)] Abstract, result (4): The strict superiority of delta-based generation is derived under a first-order Markov token-error model (P(error at t | history) = P(error at t | token t-1)). LLM code generation exhibits long-range syntactic and semantic dependencies that violate this assumption, so the strict inequality does not necessarily hold and the result is not load-bearing for the overall framework without a more general error model.
Authors: We agree that real LLM code generation involves long-range dependencies that go beyond a first-order Markov token-error model, so the strict inequality in result (4) is not guaranteed to hold in practice. Result (4) is explicitly derived and stated under the first-order Markov assumption in the paper. We will revise the abstract and the presentation of result (4) to emphasize this scope and to note that the result supplies theoretical motivation for preferring delta-based generation rather than a claim of universal strict superiority. The core convergence theory (results 1-3 and 5) and the proxy analysis (result 6) do not depend on result (4). revision: partial
-
Referee: [Abstract, result (6)] Abstract, result (6): The closed-form rho_S = (6/pi) arcsin(rho_P(SNR)/2) is obtained directly from the CE modeling choice and the Markov error model. This creates a circularity risk: the experimental confirmation of the proxy-reliability prediction may reduce to a quantity defined by the modeling assumptions rather than providing an independent test of the theory.
Authors: The closed-form expression is derived inside the parametric CE framework together with the Markov error model. The experiment, however, measures rho_S directly from the 3300 architectures by comparing proxy-based rankings against ground-truth performance and separately estimates SNR from the same data; the comparison then checks whether the observed rho_S matches the value predicted by the formula. This supplies an empirical test of the model's predictive accuracy on real data rather than a tautology. We will add a clarifying paragraph in Section 5 to separate the derivation from the empirical validation and thereby address the circularity concern. revision: partial
-
Referee: [Abstract, experimental confirmation] Abstract, experimental section: The manuscript states that two predictions are confirmed quantitatively on 3300 architectures, but without the full derivations, explicit definitions of the parametric family, or details on how the predictions were isolated from the modeling assumptions, the empirical support cannot be fully assessed.
Authors: Sections 3 and 4 of the manuscript contain the full derivations, the definition of the parametric LLM family, and the isolation of each prediction from the modeling assumptions. Section 5 details the experimental protocol and the quantitative confirmation procedure applied to the 3300 architectures. We will revise the abstract to include explicit cross-references to these sections so that readers can locate the supporting material without ambiguity. Should the referee request further expansion of any derivation in the main text, we will incorporate it during revision. revision: yes
Circularity Check
No significant circularity; derivations follow from explicit modeling assumptions and external experiment
full rationale
The paper explicitly frames its six results as consequences of modeling iterative LLM-NAS as a parametric CE method plus auxiliary assumptions (first-order Markov token errors, MinHash filter). Result (1) is an equivalence shown within the chosen parametric family rather than a self-referential definition. Result (6) supplies a closed-form expression derived from the SNR-to-reliability mapping under the model; it is not obtained by fitting to the target data or by renaming an input. The 22-cycle experiment supplies an independent quantitative check on two predictions. No quoted equation reduces a claimed prediction to a fitted parameter or to a self-citation chain; the central claims retain independent mathematical content once the modeling premises are granted.
Axiom & Free-Parameter Ledger
free parameters (1)
- rho_0
axioms (2)
- domain assumption First-order Markov token-error model for code generation validity
- domain assumption LLM fine-tuning on elites is exactly the CE update inside the LLM parametric family
Forward citations
Cited by 1 Pith paper
-
Systematic Exploration of 4-Expert Heterogeneous Mixture-of-Experts via Automated Pipeline Search
Automated search of 4463 heterogeneous 4-expert MoE models found enumeration bias anchoring the space to AirNet and ranked ShuffleNet/MobileNetV3 as top performers.
Reference graph
Works this paper leans on
-
[1]
Delta-Based Neural Architecture Search: LLM Fine-Tuning via Code Diffs
Santosh Premi Adhikari, Radu Timofte, and Dmitry Ignatov. Delta-based neural architecture search: LLM fine-tuning via code diffs.arXiv preprint, arXiv:2605.04903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LEMUR Neural Network Dataset: Towards Seamless AutoML
URLhttps://arxiv.org/abs/2504.10552. Xiaojie Gu, Dmitry Ignatov, and Radu Timofte. Resource-efficient iterative LLM-based NAS with feedback memory.arXiv preprint, arXiv:2603.12091,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun
URLhttps://arxiv.org/abs/ 2603.12091. Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun. Single path one-shot neural architecture search with uniform sampling. InEuropean Conference on Computer Vision (ECCV), pages 544–560,
-
[6]
arXiv preprint arXiv:2301.08727 , year=
URLhttps://arxiv.org/abs/2301.08727. Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers.arXiv preprint, arXiv:2309.03409,
-
[7]
Observe that KL(ˆpSt ∥pθ) = X a ˆpSt(a) log ˆpSt(a)− X a ˆpSt(a) logp θ(a) =H(ˆpSt) +L(θ)
10 A Full Proofs Proof of Theorem 1.The cross-entropy fine-tuning loss isL(θ) =− 1 |St∪L| P a∈St∪L logp θ(a). Observe that KL(ˆpSt ∥pθ) = X a ˆpSt(a) log ˆpSt(a)− X a ˆpSt(a) logp θ(a) =H(ˆpSt) +L(θ). SinceH(ˆp St)does not depend onθ, minimisingL(θ)overΘis equivalent to minimising KL(ˆpSt ∥pθ)overΘ, which is the parametric CE update.□ Proof of Theorem 2.L...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.