GRUFF: LLM Pronoun Fidelity, Reasoning, and Biases in German
Pith reviewed 2026-06-29 07:37 UTC · model grok-4.3
The pith
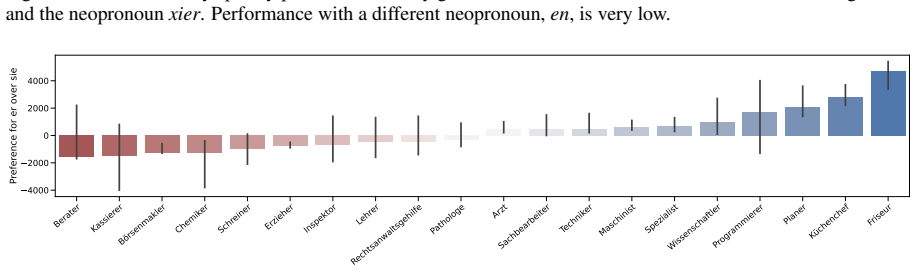
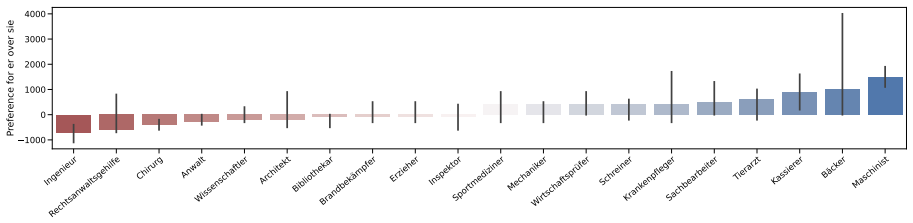
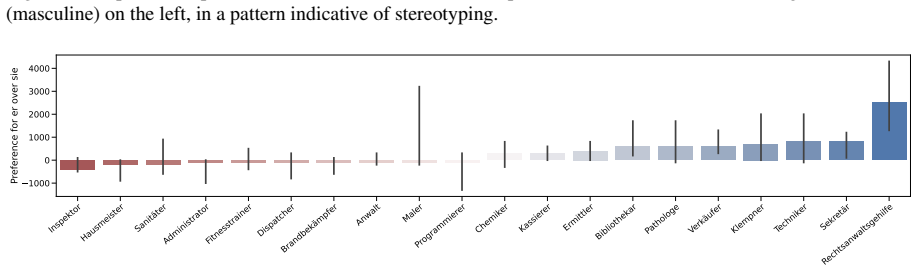
LLMs maintain strong grammatical agreement for masculine and feminine pronouns in German but fail with neopronouns xier and en, and most models lose robustness when distractors appear.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
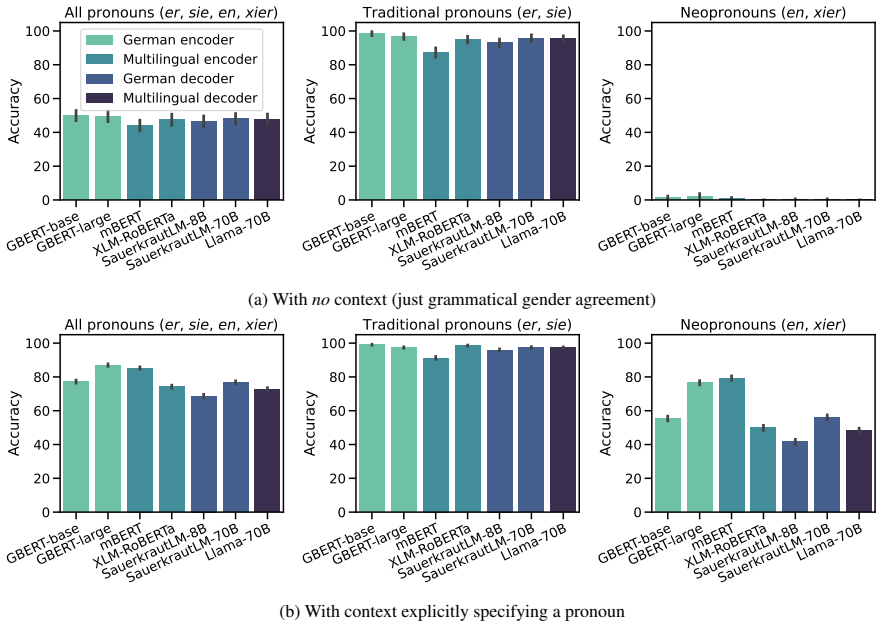
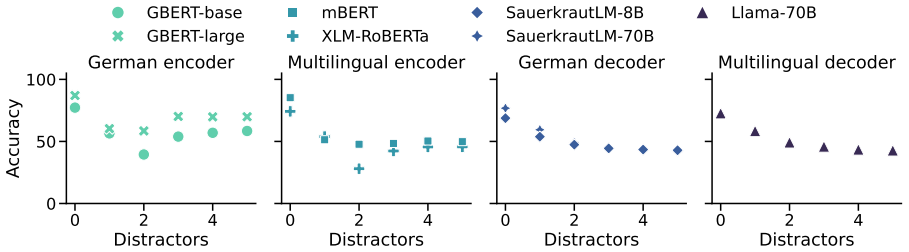
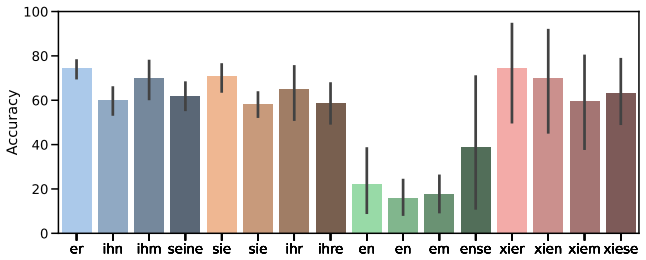
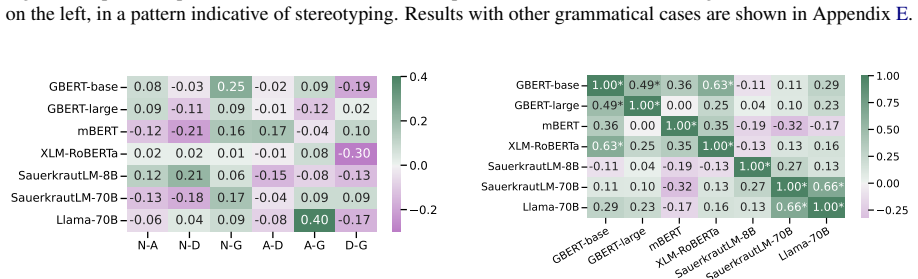
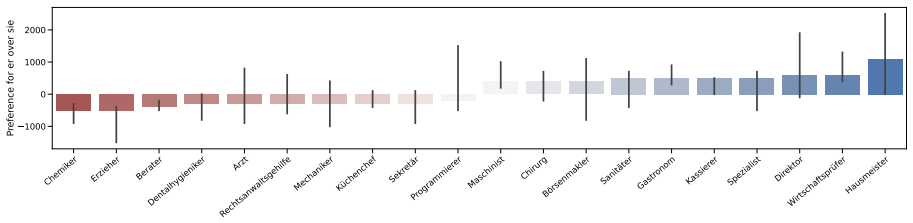
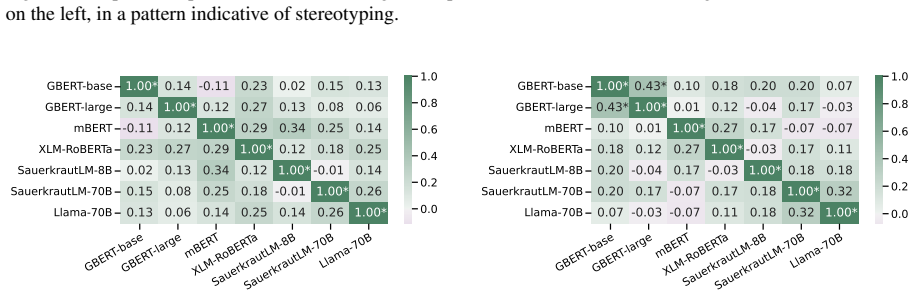
We present GRUFF, a large-scale dataset covering four gender agreement systems in nouns and four pronoun sets to measure pronoun fidelity in German. Using this dataset we show that LLMs exhibit strong grammatical agreement for masculine and feminine entities in the absence of explicit context, but not for neopronouns xier and en. Models are generally not robust to distractors, but encoder-only models are more robust in German than in English, reflecting the importance of grammatical gender. Occupational stereotypes in this context are poorly correlated across grammatical cases and across most models, except ones with closely related architectures.
What carries the argument
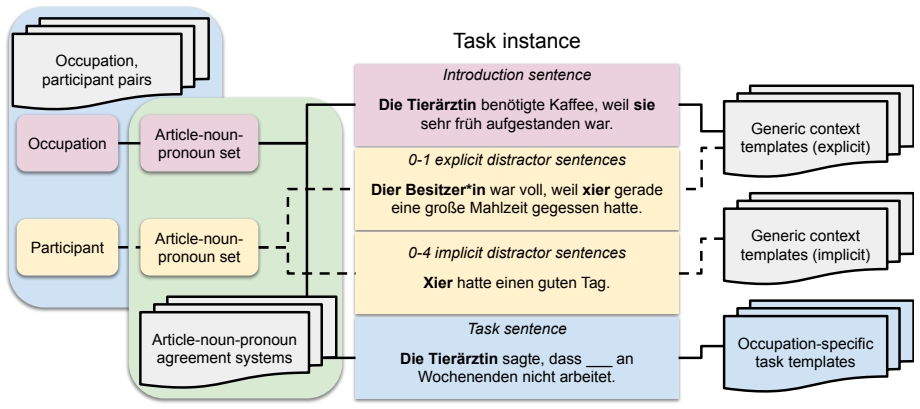
The GRUFF dataset, which isolates the task of correctly reusing a specified pronoun for a discourse entity despite intervening distractors across different noun gender classes and pronoun types including neopronouns.
If this is right
- Models will correctly reuse masculine and feminine pronouns in German text without distractors.
- Neopronouns xier and en will not be maintained reliably by current LLMs in German discourse.
- Encoder-only models will show greater robustness to distractors than decoder-only models when processing German pronouns.
- Occupational stereotypes will show low correlation across different grammatical cases for most models.
- Bias patterns measured in German will differ from those in English because of richer grammatical gender.
Where Pith is reading between the lines
- The greater robustness of encoder-only models in German suggests that explicit grammatical gender marking during training improves handling of referential distractors.
- The dataset could support development of fine-tuning methods that raise neopronoun fidelity while preserving agreement on traditional pronouns.
- Because stereotypes correlate poorly across cases, bias audits in German should test multiple grammatical forms rather than nominative alone.
- Similar fidelity gaps may appear in other languages with grammatical gender such as French or Spanish, warranting parallel datasets.
Load-bearing premise
The GRUFF dataset items isolate pronoun fidelity from other discourse factors and that the chosen occupational stereotypes and distractors are representative of real usage patterns in German.
What would settle it
A controlled test in which current LLMs reuse xier and en at rates matching er and sie in sentences without distractors would falsify the claim of differential agreement for neopronouns.
Figures


read the original abstract
Third-person singular pronouns have long been used to study stereotypical biases in language models and to test their abilities to reason about reference. More recently, the interplay between reasoning and bias has been investigated with the task of pronoun fidelity, which assesses models' abilities to correctly reuse a previously-specified pronoun for a discourse entity, independent of other potentially distracting discourse entities mentioned in between. However, such research focuses on English, which is a language with limited grammatical gender and almost no gender agreement. In this paper we contribute a novel, large-scale dataset, GRUFF, to measure pronoun fidelity in German, covering four different gender agreement systems in nouns, and four sets of pronouns. With this dataset, we show that LLMs show strong grammatical agreement for masculine and feminine entities in the absence of explicit context, but not for neopronouns xier and en. Models are generally not robust to distractors, but encoder-only models are more robust in German than in English, reflecting the importance of grammatical gender. Finally, we show that occupational stereotypes in this context are poorly correlated across grammatical cases, and across most models, except ones with closely related architectures. We release all code and data to encourage further work on gender-inclusive language and referential reasoning in German.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GRUFF dataset to measure pronoun fidelity in German LLMs across four gender agreement systems in nouns and four pronoun sets. It claims LLMs exhibit strong grammatical agreement for masculine and feminine entities without explicit context but not for neopronouns xier and en; models are generally not robust to distractors, though encoder-only models show greater robustness in German than English; and occupational stereotypes are poorly correlated across grammatical cases and across most models except those with closely related architectures. All code and data are released.
Significance. If the empirical results hold, this extends English-centric pronoun fidelity and bias research to a language with rich grammatical gender, providing evidence on how grammatical features affect referential reasoning and neopronoun handling in LLMs. The release of code and data is a clear strength supporting reproducibility and further work on gender-inclusive language. The model-family contrast offers a falsifiable benchmark for multilingual evaluation.
minor comments (3)
- Abstract: the four pronoun sets are referenced but not named; listing them (or adding a short table) would improve immediate clarity for readers.
- Dataset description: include one or two concrete GRUFF example items in the main text (rather than only in supplementary material) to illustrate how distractors and occupational stereotypes are instantiated.
- Results: the claim of 'poorly correlated' stereotypes across cases would be strengthened by reporting the exact correlation coefficients and any statistical tests used.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the GRUFF dataset and its contributions to multilingual pronoun fidelity research, as well as for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical study that introduces the GRUFF dataset and reports LLM evaluation results on pronoun fidelity across German gender systems. No derivations, equations, fitted parameters, or first-principles predictions are present that could reduce to inputs by construction. Claims about model behavior follow directly from the stated experimental contrasts on the released data, with no self-citation chains or ansatzes invoked as load-bearing support. This is a standard falsifiable empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pronoun fidelity is a valid measure of referential reasoning independent of stereotypical bias
Reference graph
Works this paper leans on
-
[1]
MisgenderMender: A community-informed approach to interventions for misgendering. InPro- ceedings of the 2024 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7538–7558, Mexico City, Mexico. Association for Computational Linguistics. Alina Huck. 2021. Ef...
2024
-
[2]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Fairtranslate: an english-french dataset for gender bias evaluation in machine translation by over- coming gender binarity. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and 10 Transparency, FAccT ’25, page 150–166, New York, NY , USA. Association for Computing Machinery. Jaap Jumelet, Leonie Weissweiler, Joakim Nivre, and Arianna ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
InSecond Conference on Language Modeling
Agree to disagree? a meta-evaluation of LLM misgendering. InSecond Conference on Language Modeling. Tony Sun, Andrew Gaut, Shirlyn Tang, Yuxin Huang, Mai ElSherief, Jieyu Zhao, Diba Mirza, Elizabeth Belding, Kai-Wei Chang, and William Yang Wang
-
[4]
InProceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics, pages 1630–1640, Florence, Italy
Mitigating gender bias in natural language processing: Literature review. InProceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics, pages 1630–1640, Florence, Italy. Association for Computational Linguistics. tresiwalde. 2024. Llama-3-sauerkrautlm-70b-instruct- awq. Hugging Face Model Repository. Last ac- cessed: 2025-10...
2024
-
[5]
Queer NLP: A Critical Survey on Literature Gaps, Biases and Trends
Queer nlp: A critical survey on literature gaps, biases and trends.Preprint, arXiv:2602.16151. Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Or- donez, and Kai-Wei Chang. 2018. Gender bias in coreference resolution: Evaluation and debiasing methods. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Li...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.