Unifying Temporal and Structural Credit Assignment in LLM-Based Multi-Agent Prompt Optimization
Pith reviewed 2026-06-28 23:53 UTC · model grok-4.3
The pith
Decomposing credit assignment into temporal bottlenecks and structural roles enables targeted prompt optimization in multi-agent LLM systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
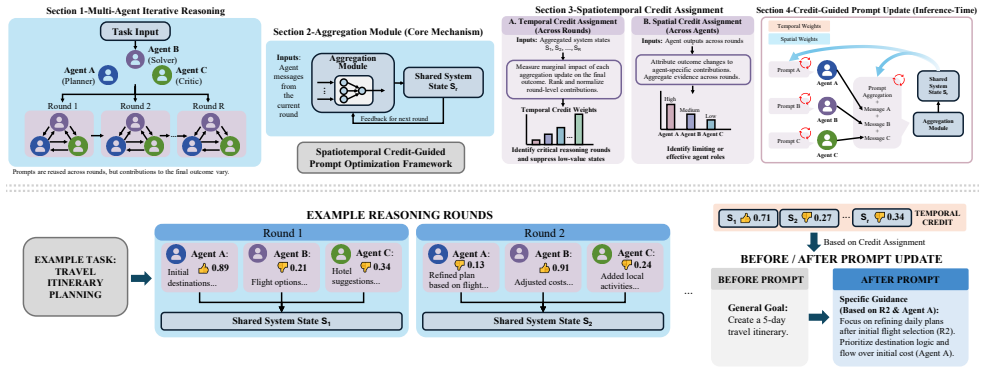
By using state-space bottlenecks for temporal credit and stationary role policies for structural credit, a discrete verbalized block coordinate descent algorithm can iteratively refine role prompts and aggregation protocols with targeted LLM-generated proxy gradients rather than indiscriminate global updates.
What carries the argument
Temporal and structural credit assignment, which decomposes the objective along critical rounds identified by bottlenecks and agent contributions isolated by role policies to support targeted proxy-gradient updates.
Load-bearing premise
State-space bottlenecks reliably identify critical rounds and stationary role policies isolate individual agent contributions well enough for LLM proxy gradients to produce useful targeted updates without adding new errors or instability.
What would settle it
Run the method on a multi-agent system whose bottlenecks do not correspond to actual failure points and observe whether performance gains disappear or query counts rise relative to a global-update baseline.
Figures


read the original abstract
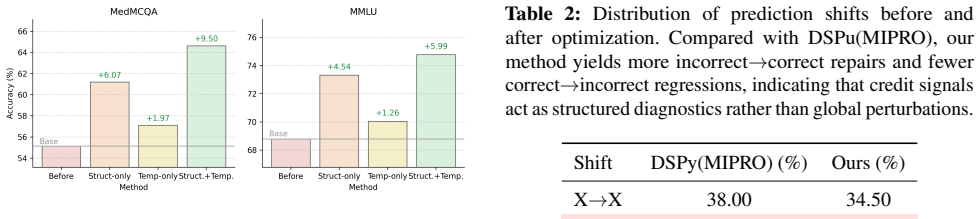
While Multi-Agent Systems (MAS) empower Large Language Models to tackle complex reasoning tasks through collaborative interaction, optimizing their dynamics remains a formidable challenge due to the discrete, non-differentiable nature of the computation graph and the sparsity of global supervisory signals. Existing black-box optimizers struggle to attribute trajectory-level failure to specific local components, resulting in inefficient, high-variance exploration. We argue that tractable MAS optimization needs structural inductive biases to disentangle error signals. We propose temporal and structural credit assignment, which decomposes the objective along two axes: (i) temporal credit, using state-space bottlenecks to identify critical rounds, and (ii) structural credit, using stationary role policies to isolate agent contributions. Leveraging these decomposed signals, we introduce a discrete, verbalized block coordinate descent algorithm for iterative refinement. Rather than indiscriminate global updates, it alternates between optimizing role prompts and aggregation protocols, using LLM-generated "proxy gradients" to target only the identified weak links. Across diverse reasoning benchmarks, our approach substantially reduces query complexity while improving performance, providing a principled and interpretable path toward self-improving MAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tractable optimization of LLM-based multi-agent systems requires structural inductive biases to disentangle error signals. It decomposes the objective via temporal credit assignment (state-space bottlenecks to identify critical rounds) and structural credit assignment (stationary role policies to isolate agent contributions). These signals enable a discrete verbalized block coordinate descent algorithm that alternates between optimizing role prompts and aggregation protocols, using LLM-generated proxy gradients to target only identified weak links. The approach is asserted to substantially reduce query complexity while improving performance across diverse reasoning benchmarks.
Significance. If the decomposition reliably isolates contributions and the proxy gradients produce net-positive targeted edits without instability, the work would offer a more interpretable and query-efficient alternative to black-box MAS optimizers, with potential for self-improving systems grounded in explicit credit assignment.
major comments (2)
- [Abstract] Abstract and method description: the central performance claims (reduced query complexity and improved benchmark performance) are stated without any equations, experimental setup, error analysis, ablation studies, or data; the soundness of the proxy-gradient mechanism cannot be evaluated from the provided material.
- [Method] Method section on proxy gradients: no formal characterization is supplied of the conditions under which an LLM can serve as a reliable local gradient estimator, nor any argument showing that state-space bottlenecks and stationary role policies actually separate the relevant variables rather than conflating them; this is load-bearing for the claim that targeted block-coordinate updates outperform indiscriminate global search.
minor comments (1)
- [Abstract] Notation for 'proxy gradients' and 'verbalized block coordinate descent' is introduced without precise definitions or pseudocode, making the algorithm difficult to reproduce.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract and method sections require strengthening to better substantiate the performance claims and the proxy-gradient mechanism. We respond to each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central performance claims (reduced query complexity and improved benchmark performance) are stated without any equations, experimental setup, error analysis, ablation studies, or data; the soundness of the proxy-gradient mechanism cannot be evaluated from the provided material.
Authors: The abstract is written at a high level per standard conventions and length limits. The full manuscript includes a dedicated Experiments section reporting benchmark results, query complexity reductions, statistical analysis, ablation studies on temporal and structural credit assignment, and comparisons against black-box baselines. We will revise the abstract to include one sentence on the experimental setup and key quantitative outcomes. We will also insert a concise paragraph in the method overview referencing the experimental validation of the proxy gradients, including high-level error analysis and ablation outcomes, to improve evaluability. revision: yes
-
Referee: [Method] Method section on proxy gradients: no formal characterization is supplied of the conditions under which an LLM can serve as a reliable local gradient estimator, nor any argument showing that state-space bottlenecks and stationary role policies actually separate the relevant variables rather than conflating them; this is load-bearing for the claim that targeted block-coordinate updates outperform indiscriminate global search.
Authors: The manuscript supplies empirical support via ablations demonstrating that disabling the credit assignment components increases query complexity and reduces performance, consistent with disentanglement. We acknowledge the absence of a formal characterization of LLM proxy gradients or a rigorous separation proof. In revision we will add a dedicated discussion subsection outlining the operating assumptions (e.g., observed stability across benchmarks) under which the proxy gradients remain net-positive, together with an expanded argument—supported by the algorithm pseudocode and ablation data—explaining how state-space bottlenecks and stationary role policies isolate contributions rather than conflate them. This will directly address the load-bearing claim for block-coordinate descent. revision: yes
Circularity Check
No circularity detected; derivation chain is conceptual only
full rationale
The provided manuscript text (abstract and description) contains no equations, parameter fits, or explicit derivations. The central claims rest on a high-level algorithmic description of temporal/structural credit assignment and verbalized block coordinate descent using LLM proxy gradients. No step reduces a prediction or result to its own inputs by construction, and no self-citations are invoked as load-bearing uniqueness theorems. The method is presented as a proposed inductive bias without mathematical reduction that would trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MAS-PromptBench: When Does Prompt Optimization Improve Multi-Agent LLM Systems?
A new benchmark study finds that prompt optimization can deliver significant gains in multi-agent LLM systems but its effectiveness varies strongly with task, workflow, communication protocol, and team size.
Reference graph
Works this paper leans on
-
[1]
Xufeng Cai, Chaobing Song, Stephen Wright, and Jelena Diakonikolas
Curran Associates, Inc., 2020. Xufeng Cai, Chaobing Song, Stephen Wright, and Jelena Diakonikolas. Cyclic block coordinate descent with vari- ance reduction for composite nonconvex optimization. In Proceedings of the 40th International Conference on Ma- chine Learning, volume 202, pages 3469–3494. PMLR,
2020
-
[2]
FaithScore: Fine-grained evaluations of hallucina- tions in large vision-language models
URL https://proceedings.mlr.press/ v202/cai23e.html. Zhipeng Chen, Zihan Wang, et al. Mas-gpt: Training LLM s to build LLM -based multi-agent systems.arXiv preprint arXiv:2402.08960, 2024. M. Deng, J. Wang, et al. Rlprompt: Optimizing discrete text prompts with reinforcement learning. InEMNLP, 2022. C. Fernando, D. Banarse, et al. Promptbreeder: Self- ref...
-
[3]
URL https://aclanthology.org/2024. findings-emnlp.427/. Yuxuan Li, Zhenfang Chen, et al. Evomac: Evolution- ary multi-agent collaboration for large language models. arXiv preprint arXiv:2403.01245, 2024b. Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems...
-
[4]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
URL https://proceedings.mlr.press/ v174/pal22a.html. Martin L. Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, New York, 1994. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate- level google-proof q&a b...
work page internal anchor Pith review Pith/arXiv arXiv 1994
-
[5]
doi: 10.1023/A:1017501703105. Jason Wei, Xuezhi Wang, et al. Chain-of-thought prompt- ing elicits reasoning in large language models. InPro- ceedings of the 36th International Conference on Neu- ral Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088. Tim Z. Xiao, Robert Bamler, Bernhard Schölkopf,...
-
[6]
A multiple-choice question with options A, B, C, and D
-
[7]
The gold correct answer
-
[8]
NONE". - If the answer is incorrect, failure_pattern MUST NOT be
The final answer produced by ONE debating agent. Your task is NOT to solve the question again. Your task is to evaluate this agents final answer independently and assign a score that reflects the quality of its reasoning and decision-making. You must: - Determine whether the final answer is correct. - If incorrect, identify the primary reason for failure ...
-
[9]
Do NOT restate the full question or options
-
[10]
Do NOT compare with other agents
-
[11]
Do NOT suggest prompt changes explicitly
-
[12]
Focus on issues that could be mitigated by improving the agents prompt or debate behavior
-
[13]
"" B.2 AGENT DIAGNOSIS PROMPT Agent Diagnosis Prompt AGENT_DIAGNOSIS_PROMPT =
Be concise, consistent, and scoring-oriented. """ B.2 AGENT DIAGNOSIS PROMPT Agent Diagnosis Prompt AGENT_DIAGNOSIS_PROMPT = """ You are an attribution analyst for a multi-agent reasoning system. Your role is to analyze summarized error information produced by a single agent and generate a concise attribution summary of the agents systematic failure chara...
-
[14]
Role and objective correction: - If failures indicate domain mismatch or objective misalignment, remove or correct the role perspective, focus, or priorities that cause the agent to reason from an inappropriate viewpoint or answer the wrong question
-
[15]
Reasoning discipline reconstruction: - If failures indicate misinterpretation, incomplete reasoning, overgeneralization, or weak justification, introduce clearer reasoning requirements such as careful question interpretation, constraint checking, step-by-step reasoning, and explicit justification
-
[16]
Constraints: - Do not preserve incorrect assumptions from the original prompt
Knowledge use and grounding control: - If failures indicate knowledge deficits or ungrounded responses, strengthen guidance on using only relevant, task-appropriate knowledge and avoiding speculative or unsupported conclusions. Constraints: - Do not preserve incorrect assumptions from the original prompt. - Do not add task-specific facts or external domai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.