EASE Configuration Facilitates A Reproducible Science of LLM Social Simulations
Pith reviewed 2026-06-28 23:48 UTC · model grok-4.3
The pith
EASE modularization turns ad-hoc LLM social simulators into reproducible research tools by separating environments, agents, engines and metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that imposing the EASE modular structure on LLM-based multi-agent simulators produces more reproducible research outputs; the three case studies conducted inside the SiliSocS sandbox demonstrate this by showing how the same configuration can assess existing questions, dive deeper into complex ones, and elaborate on prior studies while isolating the impacts of specific design choices.
What carries the argument
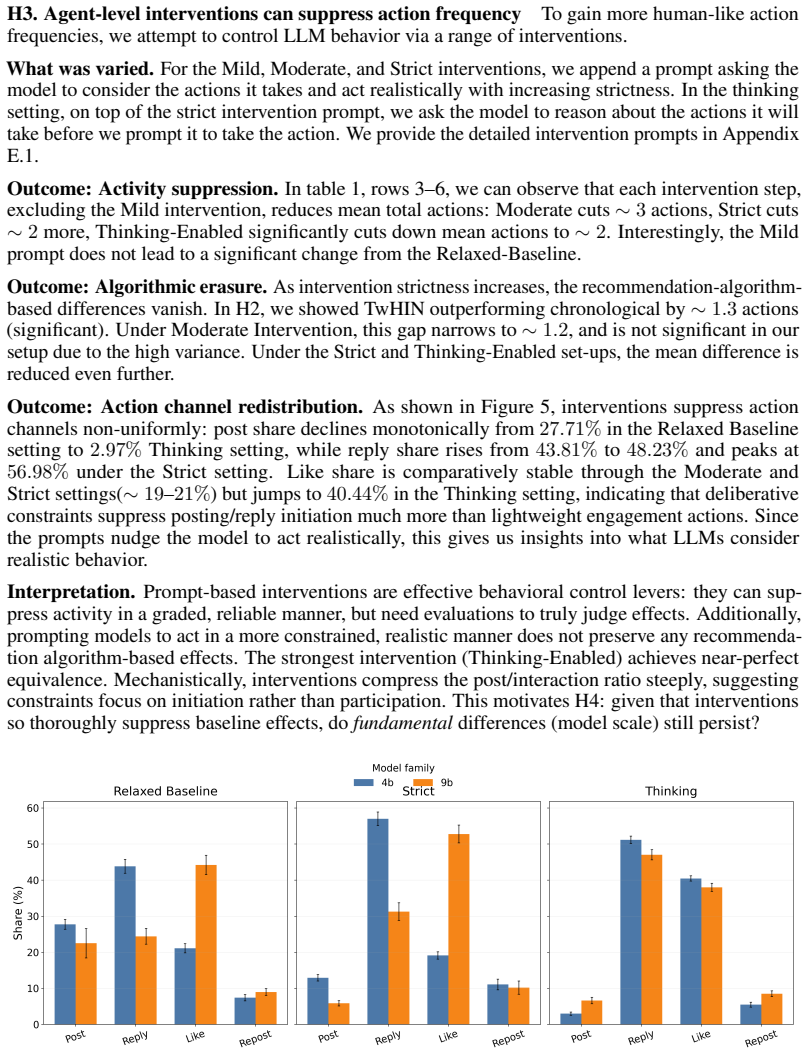
EASE, the explicit separation of a simulator into Environments, Agents, Simulation engines, and Evaluation metrics, which supplies the standardized parts needed to run study-structured workflows around explicit research questions.
If this is right
- Researchers gain a consistent way to orchestrate workflows that center on answering explicit questions inside generated scenarios.
- Limitations of existing modeling approaches become visible through repeated, comparable assessments.
- The effects of individual design choices on key simulation results can be isolated and measured.
- Existing studies can be elaborated or extended using the same modular parts without rebuilding the entire simulator.
Where Pith is reading between the lines
- Groups working on different social domains could share and recombine EASE components instead of rewriting entire simulators from scratch.
- Standardized evaluation metrics inside EASE might eventually support direct numerical comparison of simulation quality across papers.
- The framework could be extended to record exact configuration files alongside published results, making later re-runs trivial.
Load-bearing premise
That forcing simulators into the EASE modular split will produce measurably more reproducible outputs than the current ad-hoc style.
What would settle it
A side-by-side replication exercise in which independent teams rebuild the same social scenario once with ordinary ad-hoc code and once with an EASE-configured system, then compare the variance in generated interaction logs and the success rate of exact replication.
Figures
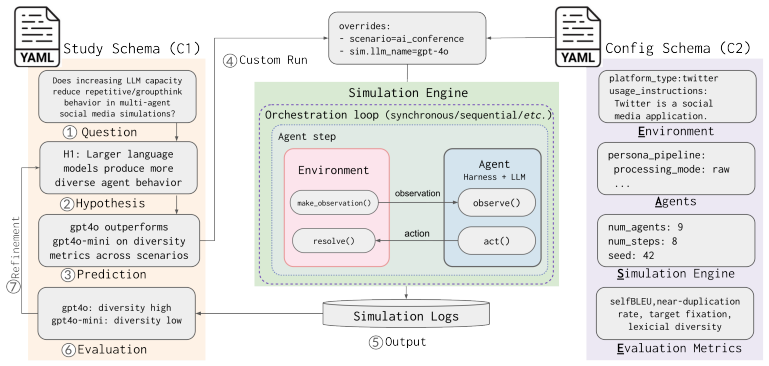
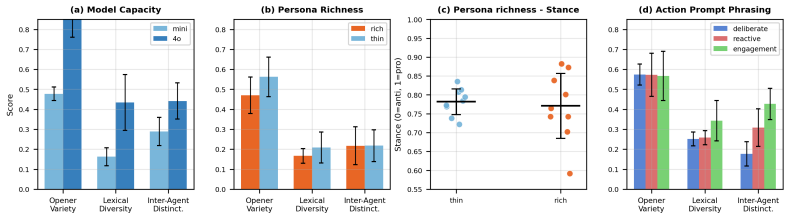
read the original abstract
LLMs are increasingly deployed to simulate social interactions, yet many of the existing simulators remain ad hoc and monolithic. This lack of architectural standardization prevents reproducible research and complicates downstream evaluation. We advance a rigorous science of LLM-based multi-agent simulation by modularizing core components into Environments, Agents, Simulation engines, and Evaluation metrics (EASE). We demonstrate the utility of EASE configuration by wrapping it in an experimental study schema for orchestrating workflows centered around answering explicit research questions in generated scenarios. We contribute SiliSocS, an open-source, research-ready Silicon Society Sandbox implementing a study-structured EASE configuration to enable highly configurable and reproducible LLM-based social simulations. Using SiliSocS and EASE, we present three case studies, showcasing the system's comprehensive assessment of existing questions, ability to dive deeper into complex questions, and elaboration of existing studies, respectively. Together, these case studies highlight the limitations of current modeling approaches and isolate the impacts of design choices on key results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the EASE framework (Environments, Agents, Simulation engines, Evaluation metrics) to modularize LLM-based multi-agent social simulations, aiming to improve reproducibility over ad-hoc approaches. It contributes the open-source SiliSocS sandbox implementing a study-structured EASE configuration and presents three case studies demonstrating comprehensive assessment, deeper dives into questions, and elaboration of prior work.
Significance. The open-source release of SiliSocS is a concrete strength that could enable community-wide experimentation and comparison. If the modular EASE structure can be shown to deliver measurable reproducibility gains, the work would provide a useful organizational scaffold for the growing area of LLM social simulations.
major comments (1)
- [Abstract] Abstract (final sentence) and the case-study descriptions: the central claim that EASE 'isolate[s] the impacts of design choices on key results' and thereby facilitates reproducible science is load-bearing, yet the three case studies are presented only as qualitative demonstrations without any quantitative metrics (variance reduction, inter-run consistency, replication-rate improvement, or explicit before/after comparison to ad-hoc baselines).
minor comments (1)
- The experimental study schema that wraps EASE is mentioned but not given a dedicated section or pseudocode; a concise diagram or table enumerating the workflow steps would improve clarity for readers implementing similar setups.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the potential of the open-source SiliSocS contribution. We address the single major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence) and the case-study descriptions: the central claim that EASE 'isolate[s] the impacts of design choices on key results' and thereby facilitates reproducible science is load-bearing, yet the three case studies are presented only as qualitative demonstrations without any quantitative metrics (variance reduction, inter-run consistency, replication-rate improvement, or explicit before/after comparison to ad-hoc baselines).
Authors: We agree that the case studies function as qualitative demonstrations of EASE's modularity rather than as quantitative benchmarks of reproducibility gains. The manuscript's central claim rests on the observation that the explicit EASE decomposition (with study-structured configuration) makes individual design choices transparent and independently variable, which the three case studies illustrate by showing how targeted changes in one module produce observable differences in generated social outcomes. This structure inherently supports reproducibility by enabling others to replicate or extend the exact configuration. At the same time, we acknowledge that the absence of explicit quantitative metrics (e.g., variance across seeds or direct ad-hoc baselines) leaves the reproducibility benefit as an inferred rather than measured property. In revision we will (1) add a short quantitative subsection reporting run-to-run variance for key metrics under fixed EASE configurations, (2) include a brief discussion contrasting the study-structured workflow with a monolithic baseline, and (3) revise the abstract's final sentence to state that EASE "enables isolation of design-choice impacts" rather than claiming it has already been shown to deliver measurable reproducibility gains. revision: partial
Circularity Check
No circularity: EASE is a conceptual modularization proposal without derivation or self-referential reduction
full rationale
The paper introduces EASE as an organizational framework (Environments, Agents, Simulation engines, Evaluation metrics) for LLM multi-agent simulators and implements it in SiliSocS, with three qualitative case studies as demonstrations. No equations, fitted parameters, predictions, or load-bearing self-citations appear. The central claim that EASE improves reproducibility is presented as a consequence of the modular structure itself, supported by case-study illustrations rather than any closed loop that reduces the output to the input by construction. This is a standard non-circular framework proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based agents can simulate social interactions in a manner that yields scientifically useful outputs
invented entities (1)
-
EASE configuration
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhiheng Xi et al.The Rise and Potential of Large Language Model Based Agents: A Survey
-
[2]
arXiv:2309.07864 [cs.AI].URL:https://arxiv.org/abs/2309.07864
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
- [4]
-
[5]
Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of LLM Agents
Giorgio Piatti et al. “Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of LLM Agents”. In:Advances in Neural Information Processing Systems. Ed. by A. Globerson et al. V ol. 37. Curran Associates, Inc., 2024, pp. 111715–111759. URL: https : / / proceedings . neurips . cc / paper _ files / paper / 2024 / file / ca9567d8ef6b2ea2da0d...
2024
-
[6]
The Concordia Contest: Advancing the Cooperative Intelligence of Language Agents
Chandler Smith et al. “The Concordia Contest: Advancing the Cooperative Intelligence of Language Agents”. In:NeurIPS 2024 Competition Track. 2024.URL: https://openreview. net/forum?id=dfeFy1PSSw
2024
- [7]
- [8]
-
[9]
Natalie Shapira et al.Agents of Chaos. 2026. arXiv: 2602.20021 [cs.AI] .URL: https: //arxiv.org/abs/2602.20021
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Aron Vallinder and Edward Hughes.Cultural Evolution of Cooperation among LLM Agents
- [11]
-
[12]
Position: Time to Close The Validation Gap in LLM Social Simulations
Maximilian Puelma Touzel et al. “Position: Time to Close The Validation Gap in LLM Social Simulations”. In:Forty-third International Conference on Machine Learning Position Paper Track. 2026.URL:https://openreview.net/forum?id=LpbxLBcOBf
2026
-
[13]
Oasis: Open agent social interaction simulations with one million agents,
Ziyi Yang et al. “Oasis: Open agent social interaction simulations with one million agents”. In: arXiv preprint arXiv:2411.11581(2024)
- [14]
-
[15]
Jiaxu Zhou et al.The PIMMUR Principles: Ensuring Validity in Collective Behavior of LLM Societies. 2026. arXiv: 2509 . 18052 [cs.CL].URL: https : / / arxiv . org / abs / 2509 . 18052
2026
-
[16]
Laura Ferrarotti et al.Generative AI collective behavior needs an interactionist paradigm
- [17]
-
[18]
Are LLM-Powered Social Media Bots Realistic?
Lynnette Hui Xian Ng and Kathleen M Carley. “Are LLM-Powered Social Media Bots Realistic?” In:International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation. Springer. 2025, pp. 14–23
2025
-
[19]
Jiaxu Zhou et al.The PIMMUR Principles: Ensuring Validity in Collective Behavior of LLM Societies. 2025. arXiv: 2509 . 18052 [cs.CL].URL: https : / / arxiv . org / abs / 2509 . 18052. 10
2025
- [20]
- [21]
-
[22]
Jinghua Piao et al.AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Ad- vances Understanding of Human Behaviors and Society. 2025. arXiv: 2502.08691 [cs.SI]. URL:https://arxiv.org/abs/2502.08691
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [23]
- [24]
-
[25]
Leibo et al.A Theory of Appropriateness That Accounts for Norms of Rationality
Joel Z. Leibo et al.A Theory of Appropriateness That Accounts for Norms of Rationality. 2026. arXiv:2603.14050 [cs.NE].URL:https://arxiv.org/abs/2603.14050
-
[26]
Benefits and challenges for platform-based design
Alberto Sangiovanni-Vincentelli et al. “Benefits and challenges for platform-based design”. In:Proceedings of the 41st Annual Design Automation Conference. DAC ’04. San Diego, CA, USA: Association for Computing Machinery, 2004, pp. 409–414.ISBN: 1581138288.DOI: 10.1145/996566.996684.URL:https://doi.org/10.1145/996566.996684
work page doi:10.1145/996566.996684.url:https://doi.org/10.1145/996566.996684 2004
- [27]
- [28]
-
[29]
Joon Sung Park et al.Social Simulacra: Creating Populated Prototypes for Social Computing Systems. 2022. arXiv: 2208 . 04024 [cs.HC].URL: https : / / arxiv . org / abs / 2208 . 04024
2022
- [30]
-
[31]
BluePrint: A Social Media User Dataset for LLM Persona Evaluation and Training
Aurélien Bück-Kaeffer et al. “BluePrint: A Social Media User Dataset for LLM Persona Evaluation and Training”. In:Workshop on Tailoring AI: Exploring Active and Passive LLM Personalization (PALS). EMNLP. 2025.URL: https://pals-nlp-workshop.github.io/
2025
-
[32]
Position: LLM Social Simulations Are a Promising Research Method
Jacy Reese Anthis et al. “Position: LLM Social Simulations Are a Promising Research Method”. In:Forty-second International Conference on Machine Learning Position Paper Track. 2025. URL:https://openreview.net/forum?id=cRBg1dtj7o
2025
-
[33]
Aurélien Bück-Kaeffer et al.The Silicon Society Cookbook: Design Space of LLM-based Social Simulations. 2026. arXiv: 2605.00197 [cs.MA].URL: https://arxiv.org/abs/ 2605.00197
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Erica Coppolillo et al.Engagement-Driven Content Generation with Large Language Models
- [35]
-
[36]
TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation
Ahmed El-Kishky et al. “TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation”. In:Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. KDD ’22. ACM, Aug. 2022, pp. 2842–2850.DOI: 10.1145/3534678.3539080.URL:http://dx.doi.org/10.1145/3534678.3539080
work page doi:10.1145/3534678.3539080.url:http://dx.doi.org/10.1145/3534678.3539080 2022
-
[37]
Qwen Team.Qwen3.5: Towards Native Multimodal Agents. Feb. 2026.URL: https://qwen. ai/blog?id=qwen3.5
2026
-
[38]
Decoding Echo Chambers: LLM-Powered Simulations Revealing Po- larization in Social Networks
Chenxi Wang et al. “Decoding Echo Chambers: LLM-Powered Simulations Revealing Po- larization in Social Networks”. In:Proceedings of the 31st International Conference on Computational Linguistics. Ed. by Owen Rambow et al. Abu Dhabi, UAE: Association for Computational Linguistics, Jan. 2025, pp. 3913–3923.URL: https://aclanthology.org/ 2025.coling-main.264/
2025
-
[39]
June 2025.URL: https://huggingface.co/datasets/nvidia/ Nemotron-Personas-USA
Yev Meyer and Dane Corneil.Nemotron-Personas-USA: Synthetic Personas Aligned to Real- World Distributions. June 2025.URL: https://huggingface.co/datasets/nvidia/ Nemotron-Personas-USA. 11
2025
-
[40]
SandboxSocial: A Sandbox for Social Media Using Mul- timodal AI Agents
Maximilian Puelma Touzel et al. “SandboxSocial: A Sandbox for Social Media Using Mul- timodal AI Agents”. In:Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25. Ed. by James Kwok. Demo Track. International Joint Conferences on Artificial Intelligence Organization, Aug. 2025, pp. 11100–11103.DOI: 10.24963/i...
work page doi:10.24963/ijcai.2025/1271.url:https://doi.org/10.24963/ijcai.2025/1271 2025
-
[41]
Qirui Mi et al.MF-LLM: Simulating Population Decision Dynamics via a Mean-Field Large Language Model Framework. 2025. arXiv: 2504.21582 [cs.MA] .URL: https://arxiv. org/abs/2504.21582. LLM Disclosure StatementIn this paper, we used the GPT-5.3-Codex model via GitHub Copilot to interpret data and help in the generation of some case study plots. A Reference...
-
[42]
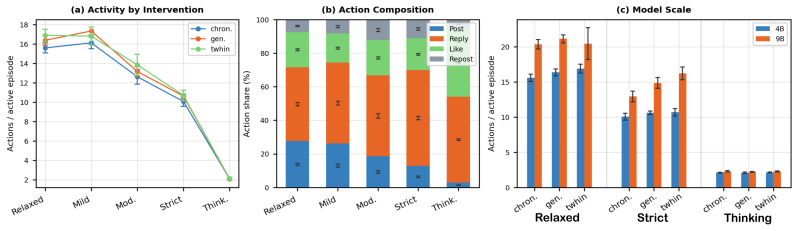
Follower-Chronological: retrieves the 10 most recent posts, replies, or reposts from followed users
-
[43]
General embedding: Uses a general sentence-transformers model to retrieve the top 10 similar posts to the user’s profile, which is generated by combining their persona description, 10 most recent posts, and 10 most recent liked posts
-
[44]
We borrow implementation details of the two recsys algorithms from OASIS [11]
TwHIN Encoder: Same as above, but uses the TwHIN [32] model that is trained on Twitter data to compute similarity. We borrow implementation details of the two recsys algorithms from OASIS [11]. Outcome.We observe that total actions show no significant differences across the different timeline curation settings. Interpretation.Even though we see no meaning...
-
[45]
Similarity exposure: agents observe neighbors with similar beliefs
-
[46]
Opposing exposure: agents observe neighbors with distant or opposing beliefs
-
[47]
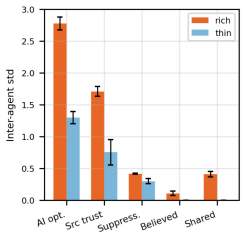
Outcome.Opposing exposure strongly reduces final polarization and global disagreement relative to similarity exposure
Random exposure: agents observe eligible neighbors without belief-similarity filtering. Outcome.Opposing exposure strongly reduces final polarization and global disagreement relative to similarity exposure. Final polarization drops from 2.722 to 1.796, and final global disagreement drops from 2.228 to 1.557. Random exposure produces a weaker version of th...
-
[48]
Exact reproduction: direct neighbor opinion exposure and daily belief update
-
[49]
Outcome.The loose social environment still produces the qualitative echo-chamber signature
Loose social environment: timeline observations, social-media actions, and terminal belief probe. Outcome.The loose social environment still produces the qualitative echo-chamber signature. With Echo-style memory and self-state feedback, final polarization reaches 2.990±0.150 , NCI reaches 0.411±0.108 , and global disagreement falls to 2.296±0.085 . From ...
-
[50]
With self-state feedback: the agent is reminded of its previous opinion and belief
-
[51]
Outcome.Removing self-state feedback weakens polarization and local alignment
Without self-state feedback: the same observations and memory are provided, but explicit previous opinion/belief fields are removed. Outcome.Removing self-state feedback weakens polarization and local alignment. Under GPT- 4o-mini with Echo-style memory, final polarization falls from 2.990 to 2.695, and final NCI falls from 0.411 to 0.295. Belief volatili...
-
[52]
Echo-memory agent: preserves short-term summary, long-term consolidation, and structured belief update
-
[53]
Outcome.The simple social agent still shows echo-chamber directionality, but the effect is weaker
Simple social agent: uses a simpler observe-memory-act memory path. Outcome.The simple social agent still shows echo-chamber directionality, but the effect is weaker. With self-state feedback, final polarization falls from 2.990 for the Echo-memory agent to 2.641 for the simple agent, and NCI falls from 0.411 to 0.193. Without self-state feedback, the sim...
-
[54]
Outcome.Qwen3.5-4B does not reproduce the GPT-like local-alignment signature
Qwen3.5-4B. Outcome.Qwen3.5-4B does not reproduce the GPT-like local-alignment signature. With Echo memory and self-state feedback, Qwen reaches final polarization 2.605, but NCI remains negative at −0.110, and global disagreement increases to 2.841. Without self-state feedback, Qwen Echo- memory agents become highly volatile, with mean belief volatility ...
2026
-
[55]
H5: Algorithmic recommendation system feeds lead to more realistic information dynamic structures such as cascade measurements, virality etc
-
[56]
H6: Agents can be aligned to real-world distributions for engagement-actions via agent selection or assigning agents pre-set social personas
-
[57]
H7: By explicitly making the follower-chronological field non-interesting to the user (not aligned with voting goal, or interests), we can elicit a much bigger gap between the recsys-TWHiN and the chronological timeline 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.