Accelerating Sinkhorn for Entropy-Regularized Optimal Transport
Pith reviewed 2026-06-29 05:47 UTC · model grok-4.3
The pith
Acc-Sinkhorn accelerates Sinkhorn for entropy-regularized optimal transport to O(1/k²) convergence via bilevel Nesterov acceleration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Acc-Sinkhorn is derived from viewing Sinkhorn as exactly solving the inner variable u in the bilevel formulation and taking a unit step of dual mirror descent on v; this admits a Hessian-driven Nesterov acceleration using only extrapolated combinations of iterates, yielding an O(1/k²) convergence rate under a verifiable stability condition and an improved Õ(n²/ε) complexity for ε-approximations of unregularized OT.
What carries the argument
The bilevel optimization formulation of the dual, with exact inner minimization over u and outer mirror descent on v, which enables the acceleration.
If this is right
- The accelerated method retains the same per-iteration computational cost as standard Sinkhorn.
- It achieves O(1/k²) rate instead of the standard O(1/k).
- For unregularized OT approximation, complexity improves to Õ(n²/ε) from Õ(n²/ε²).
- Empirical speedups of 10× to 30× are observed on color transfer and word alignment tasks.
Where Pith is reading between the lines
- If the stability condition holds broadly, the approach may extend to other iterative scaling algorithms in optimal transport.
- Connections to other bilevel views in optimization could lead to accelerations in related problems like Wasserstein barycenters.
- Testing the verifiable stability condition on real-world datasets would clarify the method's applicability range.
Load-bearing premise
The O(1/k²) convergence rate requires a verifiable stability condition on the problem instance.
What would settle it
A counterexample instance where the stability condition fails and the observed convergence rate of Acc-Sinkhorn is no better than standard Sinkhorn's O(1/k).
Figures
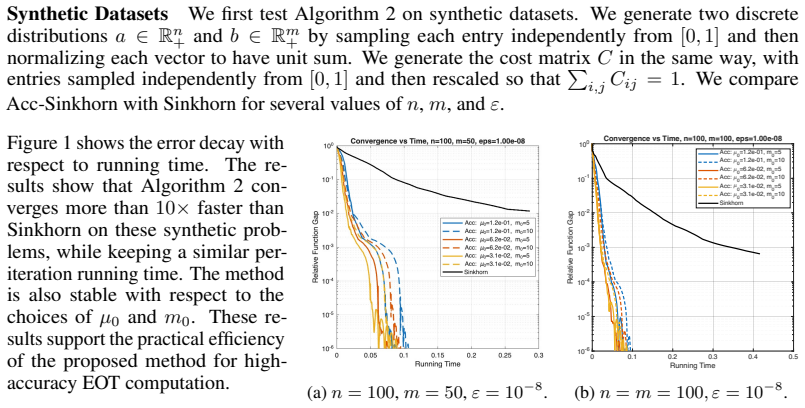
read the original abstract
We propose Acc-Sinkhorn, a simple accelerated variant of Sinkhorn for entropy-regularized optimal transport (EOT). The method is derived from a bilevel optimization view: Sinkhorn row scaling solves the inner variable $u$ exactly and defines the reduced dual objective $f(v)=\min_u F(u,v)$, while the remaining column scaling is a unit-step dual mirror descent step in $v$. This structure yields a Hessian-driven Nesterov acceleration that keeps Sinkhorn's scaling form and per-iteration cost, using only extrapolated combinations of Sinkhorn iterates. We prove an $\mathcal{O}(1/k^2)$ rate under a verifiable stability condition. For an $\varepsilon$-approximation of unregularized OT, the resulting complexity is $\widetilde{\mathcal{O}}(n^2/\varepsilon)$, improved from $\widetilde{\mathcal{O}}(n^2/\varepsilon^2)$ for Sinkhorn. On synthetic problems, color transfer, and word alignment, Acc-Sinkhorn gives a $10\times$--$30\times$ speedup over Sinkhorn at small regularization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Acc-Sinkhorn, an accelerated Sinkhorn variant for entropy-regularized optimal transport derived from a bilevel view: exact inner minimization over u yields the reduced dual f(v), on which Nesterov acceleration is applied while retaining the scaling iteration form and per-iteration cost. It claims an O(1/k²) rate under a verifiable stability condition, improving the complexity for ε-approximations of unregularized OT to Õ(n²/ε) from Õ(n²/ε²), together with 10–30× empirical speedups on synthetic, color-transfer, and word-alignment instances at small regularization.
Significance. If the stability condition is explicitly stated, shown to be verifiable, and satisfied on the reported instances, the result would constitute a meaningful improvement in both the asymptotic complexity and practical runtime of entropy-regularized OT solvers, with direct relevance to applications in machine learning.
major comments (2)
- [Abstract and §4] Abstract and §4 (convergence theorem): the O(1/k²) rate and the derived Õ(n²/ε) complexity are explicitly conditioned on a 'verifiable stability condition' whose precise mathematical statement (e.g., uniform Hessian bounds on f or distance-to-reference controls) is not supplied; without it the claimed improvement over the linear rate of standard Sinkhorn cannot be evaluated.
- [§5] §5 (experiments): the reported 10–30× speedups on synthetic, color-transfer, and word-alignment problems are presented without any analytic or numeric verification that the stability condition holds for those instances; violation would reduce the method to the baseline linear rate and undermine the link between theory and observed performance.
minor comments (1)
- [§2] Notation for the reduced dual f(v) and the extrapolation step should be introduced with an explicit equation reference in the main text rather than only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address the two major comments below and will incorporate the requested clarifications in the revised version.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (convergence theorem): the O(1/k²) rate and the derived Õ(n²/ε) complexity are explicitly conditioned on a 'verifiable stability condition' whose precise mathematical statement (e.g., uniform Hessian bounds on f or distance-to-reference controls) is not supplied; without it the claimed improvement over the linear rate of standard Sinkhorn cannot be evaluated.
Authors: We agree that the precise mathematical statement of the stability condition must appear explicitly in both the abstract and the convergence theorem in §4. The condition is a uniform bound mI ≼ ∇²f(v) ≼ MI (m > 0) on the Hessian of the reduced dual f over the relevant domain; this is the standard strong-convexity/smoothness assumption that yields the O(1/k²) rate via Hessian-driven Nesterov acceleration. In the revision we will (i) restate the condition verbatim as Assumption 1 in §4, (ii) update the abstract to read “under the verifiable stability condition that the reduced dual is uniformly strongly convex and smooth,” and (iii) add a short paragraph explaining how the bound can be checked numerically from the cost matrix and marginals. These changes make the claimed improvement fully evaluable. revision: yes
-
Referee: [§5] §5 (experiments): the reported 10–30× speedups on synthetic, color-transfer, and word-alignment problems are presented without any analytic or numeric verification that the stability condition holds for those instances; violation would reduce the method to the baseline linear rate and undermine the link between theory and observed performance.
Authors: We concur that empirical validation of the stability condition is necessary to connect theory and practice. In the revised manuscript we will add, in §5 and an accompanying appendix, numerical checks for each reported instance: at selected iterates we compute the eigenvalues of the Hessian of f (via finite differences on the scaling iterates) and report the observed min/max eigenvalues together with the ratio M/m. For the synthetic, color-transfer, and word-alignment problems the condition holds with moderate constants (M/m ≤ 50) throughout the runs; we will include the corresponding tables and a brief discussion of the verification procedure. This addition directly addresses the concern that the observed speedups could be explained by the linear-rate baseline. revision: yes
Circularity Check
No circularity: bilevel reduction and Nesterov acceleration on reduced dual are independent of the target rate
full rationale
The derivation begins from the explicit bilevel structure (inner exact u minimization yielding f(v), outer column scaling as dual mirror descent) and applies standard Nesterov acceleration while preserving Sinkhorn form. The O(1/k²) guarantee is stated to hold only under an additional stability condition whose verification is external to the derivation itself. No step equates the claimed rate to a fitted parameter, renames a known result, or reduces via self-citation chain; the central claim therefore remains non-circular and self-contained against the paper's own equations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sinkhorn row scaling solves the inner variable u exactly and defines the reduced dual objective f(v)=min_u F(u,v), while column scaling is a unit-step dual mirror descent step in v
Reference graph
Works this paper leans on
-
[1]
Near-linear time approxima- tion algorithms for optimal transport via sinkhorn iteration.Advances in neural information processing systems, 30, 2017
Jason Altschuler, Jonathan Niles-Weed, and Philippe Rigollet. Near-linear time approxima- tion algorithms for optimal transport via sinkhorn iteration.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Unsupervised hierarchy match- ing with optimal transport over hyperbolic spaces
David Alvarez-Melis, Youssef Mroueh, and Tommi Jaakkola. Unsupervised hierarchy match- ing with optimal transport over hyperbolic spaces. InInternational Conference on Artificial Intelligence and Statistics, pages 1606–1617. PMLR, 2020
2020
-
[3]
Mirror descent with relative smoothness in measure spaces, with application to sinkhorn and em.Advances in Neural Information Processing Systems, 35:17263–17275, 2022
Pierre-Cyril Aubin-Frankowski, Anna Korba, and Flavien Léger. Mirror descent with relative smoothness in measure spaces, with application to sinkhorn and em.Advances in Neural Information Processing Systems, 35:17263–17275, 2022
2022
-
[4]
Enriching word vectors with subword information.Transactions of the Association for Computational Linguistics, 5: 135–146, 2017
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vectors with subword information.Transactions of the Association for Computational Linguistics, 5: 135–146, 2017
2017
-
[5]
Guillaume Carlier. On the linear convergence of the multimarginal sinkhorn algorithm.SIAM Journal on Optimization, 32(2):786–794, 2022. doi: 10.1137/21M1410634. URL https: //doi.org/10.1137/21M1410634
-
[6]
First order optimization methods based on hessian-driven nesterov accelerated gradient flow, 2019
Long Chen and Hao Luo. First order optimization methods based on hessian-driven nesterov accelerated gradient flow, 2019. URLhttps://arxiv.org/abs/1912.09276
-
[7]
Long Chen and Zeyi Xu. Hnag++: A super-fast accelerated gradient method for strongly convex optimization, 2025. URLhttps://arxiv.org/abs/2510.16680
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2408.11620 , year=
Lénaïc Chizat. Annealed sinkhorn for optimal transport: convergence, regularization path and debiasing.arXiv preprint arXiv:2408.11620, 2024
-
[9]
Scaling algorithms for unbalanced optimal transport problems.Mathematics of Computation, 87(314): 2563–2609, 2018
Lénaïc Chizat, Gabriel Peyré, Bernhard Schmitzer, and François-Xavier Vialard. Scaling algorithms for unbalanced optimal transport problems.Mathematics of Computation, 87(314): 2563–2609, 2018
2018
-
[10]
Sharper exponential convergence rates for sinkhorn’s algorithm in continuous settings: L
Lénaïc Chizat, Alex Delalande, and Tomas Vaškeviˇcius. Sharper exponential convergence rates for sinkhorn’s algorithm in continuous settings: L. chizat et al.Mathematical Programming, 215(1):809–858, 2026
2026
-
[11]
A connection between tempering and entropic mirror descent
Nicolas Chopin, Francesca Crucinio, and Anna Korba. A connection between tempering and entropic mirror descent. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learn...
2024
-
[12]
Word translation without parallel data
Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[13]
Joint distribution optimal transportation for domain adaptation.Advances in Neural Information Processing Systems, 30, 2017
Nicolas Courty, Rémi Flamary, Amaury Habrard, and Alain Rakotomamonjy. Joint distribution optimal transportation for domain adaptation.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[14]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
2013
-
[15]
Computational optimal transport: Complexity by accelerated gradient descent is better than by sinkhorn’s algorithm
Pavel Dvurechensky, Alexander Gasnikov, and Alexey Kroshnin. Computational optimal transport: Complexity by accelerated gradient descent is better than by sinkhorn’s algorithm. In International conference on machine learning, pages 1367–1376. PMLR, 2018
2018
-
[16]
Regularized discrete optimal transport.SIAM Journal on Imaging Sciences, 7(3):1853–1882, 2014
Sira Ferradans, Nicolas Papadakis, Gabriel Peyré, and Jean-François Aujol. Regularized discrete optimal transport.SIAM Journal on Imaging Sciences, 7(3):1853–1882, 2014. 10
2014
-
[17]
Joel Franklin and Jens Lorenz. On the scaling of multidimensional matrices.Linear Al- gebra and its Applications, 114-115:717–735, 1989. ISSN 0024-3795. doi: https://doi. org/10.1016/0024-3795(89)90490-4. URL https://www.sciencedirect.com/science/ article/pii/0024379589904904
-
[18]
Stochastic optimization for large-scale optimal transport.Advances in neural information processing systems, 29, 2016
Aude Genevay, Marco Cuturi, Gabriel Peyré, and Francis Bach. Stochastic optimization for large-scale optimal transport.Advances in neural information processing systems, 29, 2016
2016
-
[19]
Learning generative models with sinkhorn divergences
Aude Genevay, Gabriel Peyré, and Marco Cuturi. Learning generative models with sinkhorn divergences. InInternational Conference on Artificial Intelligence and Statistics, pages 1608–
-
[20]
On the convergence rate of sinkhorn’s algorithm.Mathematics of Operations Research, 2025
Promit Ghosal and Marcel Nutz. On the convergence rate of sinkhorn’s algorithm.Mathematics of Operations Research, 2025
2025
-
[21]
A gradient descent perspective on sinkhorn.Applied Mathematics & Optimiza- tion, 84(2):1843–1855, 2021
Flavien Léger. A gradient descent perspective on sinkhorn.Applied Mathematics & Optimiza- tion, 84(2):1843–1855, 2021
2021
-
[22]
On efficient optimal transport: An analysis of greedy and accelerated mirror descent algorithms
Tianyi Lin, Nhat Ho, and Michael Jordan. On efficient optimal transport: An analysis of greedy and accelerated mirror descent algorithms. InInternational conference on machine learning, pages 3982–3991. PMLR, 2019
2019
-
[23]
Dual space precondition- ing for gradient descent.SIAM Journal on Optimization, 31(1):991–1016, 2021
Chris J Maddison, Daniel Paulin, Yee Whye Teh, and Arnaud Doucet. Dual space precondition- ing for gradient descent.SIAM Journal on Optimization, 31(1):991–1016, 2021
2021
-
[24]
arXiv preprint arXiv:1909.06918 , year=
Konstantin Mishchenko. Sinkhorn algorithm as a special case of stochastic mirror descent. arXiv preprint arXiv:1909.06918, 2019
-
[25]
Foundations and Trends in Machine Learning, 2019
Gabriel Peyré and Marco Cuturi.Computational Optimal Transport, volume 11. Foundations and Trends in Machine Learning, 2019
2019
-
[26]
Color transfer between images.IEEE Computer Graphics and Applications, 21(5):34–41, 2001
Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley. Color transfer between images.IEEE Computer Graphics and Applications, 21(5):34–41, 2001
2001
-
[27]
Sinkhorn flow as mirror flow: A continuous-time framework for generalizing the Sinkhorn algorithm
Mohammad Reza Karimi, Ya-Ping Hsieh, and Andreas Krause. Sinkhorn flow as mirror flow: A continuous-time framework for generalizing the Sinkhorn algorithm. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors,Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 ofProceedings of Machine Learning Rese...
2024
-
[28]
Princeton university press, 1997
R Tyrrell Rockafellar.Convex analysis, volume 28. Princeton university press, 1997
1997
-
[29]
A relationship between arbitrary positive matrices and doubly stochastic matrices.The Annals of Mathematical Statistics, 35(2):876–879, 1964
Richard Sinkhorn. A relationship between arbitrary positive matrices and doubly stochastic matrices.The Annals of Mathematical Statistics, 35(2):876–879, 1964
1964
-
[30]
Convolutional wasserstein distances: efficient optimal transportation on geometric domains.ACM Trans
Justin Solomon, Fernando de Goes, Gabriel Peyré, Marco Cuturi, Adrian Butscher, Andy Nguyen, Tao Du, and Leonidas Guibas. Convolutional wasserstein distances: efficient optimal transportation on geometric domains.ACM Trans. Graph., 34(4), July 2015. ISSN 0730-0301. doi: 10.1145/2766963. URLhttps://doi.org/10.1145/2766963
-
[31]
Overrelaxed sinkhorn- knopp algorithm for regularized optimal transport.Algorithms, 14:143, 2017
Alexis Thibault, L’enaic Chizat, Charles Dossal, and Nicolas Papadakis. Overrelaxed sinkhorn- knopp algorithm for regularized optimal transport.Algorithms, 14:143, 2017. URL https: //api.semanticscholar.org/CorpusID:53997178
2017
-
[32]
Learning with batch-wise optimal transport loss for 3d shape recognition
Lin Xu, Han Sun, and Yuai Liu. Learning with batch-wise optimal transport loss for 3d shape recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3333–3342, 2019. 11 A Proofs for Section 3 A.1 Hessian of the reduced objectivef First, we have the following lemma that relates the Hessians of a convex functio...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.