GMOS: Grounding Moving Object Segmentation in 3D Space and Time
Pith reviewed 2026-06-29 08:12 UTC · model grok-4.3
The pith
GMOS produces 3D-aware, temporally fine-grained segmentation of moving objects directly from RGB video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
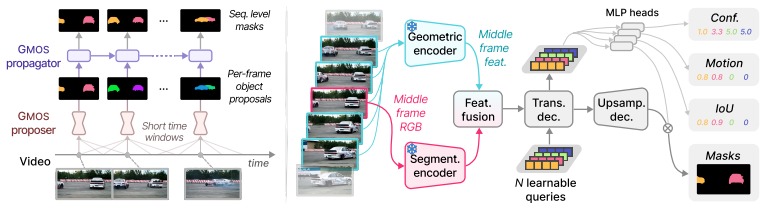
GMOS is a framework that operates directly on RGB video to produce 3D-aware, temporally fine-grained segmentation of multiple moving objects, achieving state-of-the-art results across MOS, MOS-I, and Unsupervised VOS benchmarks while running significantly faster than prior multi-object MOS methods and supporting online inference for streaming deployment.
What carries the argument
The GMOS framework that grounds moving object segmentation in 3D space and time by processing RGB video directly.
If this is right
- Delivers segmentation without pre-computed 2D auxiliary modalities such as optical flow or point trajectories.
- Accounts for the instantaneous motion state of each object rather than sequence-level attributes.
- Achieves state-of-the-art results on MOS, MOS-I, and unsupervised VOS benchmarks.
- Runs significantly faster than prior multi-object MOS methods and supports online inference for streaming deployment.
Where Pith is reading between the lines
- Video analysis pipelines could eliminate separate optical flow computation steps if implicit 3D cues from RGB prove reliable.
- The MOS-I protocol may encourage finer temporal metrics in future motion segmentation evaluations.
- Repurposing VOS datasets with added per-object motion labels offers a scalable path to train 3D-grounded models.
- The faster GMOS-S variant could enable deployment in real-time settings like live video monitoring.
Load-bearing premise
That RGB video by itself supplies enough 3D geometric information and instantaneous motion cues to segment moving objects accurately without pre-computed 2D auxiliary modalities.
What would settle it
A benchmark comparison on video sequences with ambiguous 2D projections of distinct 3D motions, checking whether GMOS accuracy falls below flow-based methods.
Figures



read the original abstract
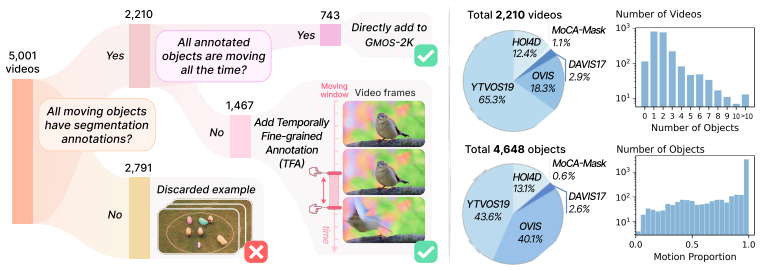
Moving Object Segmentation (MOS) aims to discover, segment, and track objects that move independently of the camera. Current MOS methods, however, exhibit two fundamental limitations: they rely on pre-computed 2D auxiliary modalities such as optical flow or point trajectories that lack 3D geometric information, and they treat motion as a sequence-level attribute, overlooking the instantaneous motion state of each object. We address both by grounding MOS in 3D space and time, and propose GMOS, a framework that operates directly on RGB video to produce 3D-aware, temporally fine-grained segmentation of multiple moving objects, alongside a foreground--background variant GMOS-S for faster deployment. To support training and evaluation in this regime, we curate GMOS-2K, a dataset of 2,210 real-world videos with per-object temporal motion annotations drawn from five established Video Object Segmentation (VOS) benchmarks, and formalise MOS-I ("I" for instantaneous), a temporally fine-grained evaluation protocol with three complementary metrics. GMOS achieves state-of-the-art results across MOS, MOS-I, and Unsupervised VOS benchmarks, while running significantly faster than prior multi-object MOS methods and supporting online inference for streaming deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GMOS, a framework for moving object segmentation (MOS) that grounds the task in 3D space and time by operating directly on RGB video without pre-computed 2D auxiliary modalities such as optical flow. It proposes a foreground-background variant GMOS-S, curates the GMOS-2K dataset (2,210 videos with per-object temporal motion annotations from existing VOS benchmarks), and formalizes the MOS-I protocol with three complementary metrics for temporally fine-grained evaluation. The authors report state-of-the-art results on MOS, MOS-I, and unsupervised VOS benchmarks, along with significantly faster runtime than prior multi-object methods and support for online inference.
Significance. If the results hold, the work is significant for shifting MOS away from reliance on 2D modalities and sequence-level motion attributes toward 3D-aware, instantaneous segmentation from RGB alone. The curation of GMOS-2K and formalization of the MOS-I protocol with three metrics provide concrete resources that could standardize fine-grained evaluation in the field. The reported efficiency gains and online capability are practical strengths for streaming deployment. These elements are load-bearing for the paper's contribution and are explicitly supported by the dataset curation and metric definitions.
minor comments (2)
- [Abstract] Abstract: the claim of 'significantly faster' runtime would benefit from a specific comparison (e.g., FPS or runtime table reference) to make the efficiency advantage immediately quantifiable.
- [§3] The paper should clarify in §3 (method) whether any implicit depth or 3D cues are learned end-to-end or if the 3D grounding is achieved purely through the temporal modeling and new loss terms.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, the recognition of its contributions to 3D-aware MOS, the GMOS-2K dataset, and the MOS-I protocol, and the recommendation to accept.
Circularity Check
No significant circularity
full rationale
The paper introduces a new framework (GMOS) for 3D-aware moving object segmentation directly from RGB video, along with a curated dataset (GMOS-2K) and a new evaluation protocol (MOS-I). No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the provided text. The central claims rest on empirical SOTA results and efficiency measurements rather than any self-referential construction. This is a standard empirical CV contribution with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
It’s moving! a probabilistic model for causal motion segmentation in moving camera videos
Pia Bideau and Erik Learned-Miller. It’s moving! a probabilistic model for causal motion segmentation in moving camera videos. InECCV, 2016
2016
-
[2]
Object segmentation by long term analysis of point trajectories
Thomas Brox and Jitendra Malik. Object segmentation by long term analysis of point trajectories. InECCV, 2010
2010
-
[3]
SAM 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris Coll-Vinent, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Ro- man Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu ...
2026
-
[4]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV, 2021
2021
-
[5]
Moving object segmentation in 3D LiDAR data: A learning-based approach exploiting sequential data
Xieyuanli Chen, Shijie Li, Benedikt Mersch, Louis Wiesmann, Jürgen Gall, Jens Behley, and Cyrill Stachniss. Moving object segmentation in 3D LiDAR data: A learning-based approach exploiting sequential data. InIROS, 2021
2021
-
[6]
Easi3r: Estimating disentangled motion from dust3r without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training. InICCV, 2025
2025
-
[7]
Schwing, and Alexander Kirillov
Bowen Cheng, Alexander G. Schwing, and Alexander Kirillov. Per-pixel classification is not all you need for semantic segmentation. InNeurIPS, 2021
2021
-
[8]
Ho Kei Cheng and Alexander G. Schwing. XMem: Long-term video object segmentation with an atkinson-shiffrin memory model. InECCV, 2022
2022
-
[9]
Tracking anything with decoupled video segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, and Joon-Young Lee. Tracking anything with decoupled video segmentation. InICCV, 2023
2023
-
[10]
Putting the object back into video object segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Joon-Young Lee, and Alexander Schwing. Putting the object back into video object segmentation. InCVPR, 2024
2024
-
[11]
Implicit motion handling for video camouflaged object detection
Xuelian Cheng, Huan Xiong, Deng-Ping Fan, Yiran Zhong, Mehrtash Harandi, Tom Drummond, and Zongyuan Ge. Implicit motion handling for video camouflaged object detection. InCVPR, 2022
2022
-
[12]
S. Cho, M. Lee, S. Lee, C. Park, D. Kim, and S. Lee. Treating motion as option to reduce motion dependency in unsupervised video object segmentation. InWACV, 2023
2023
-
[13]
Dual prototype attention for unsupervised video object segmentation
Suhwan Cho, Minhyeok Lee, Seunghoon Lee, Dogyoon Lee, Heeseung Choi, Ig-Jae Kim, and Sangyoun Lee. Dual prototype attention for unsupervised video object segmentation. InCVPR, 2024
2024
-
[14]
Guess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion
Subhabrata Choudhury, Laurynas Karazija, Iro Laina, Andrea Vedaldi, and Christian Rupprecht. Guess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion. In BMVC, 2022
2022
-
[15]
Towards segmenting anything that moves
Achal Dave, Pavel Tokmakov, and Deva Ramanan. Towards segmenting anything that moves. InICCV, 2019
2019
-
[16]
Tap-vid: A benchmark for tracking any point in a video
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Recasens, Lucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang. Tap-vid: A benchmark for tracking any point in a video. InNeurIPS, 2022. 10
2022
-
[17]
Tapir: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InICCV, 2023
2023
-
[18]
The via annotation software for images, audio and video
Abhishek Dutta and Andrew Zisserman. The via annotation software for images, audio and video. InACM MM, 2019
2019
-
[19]
Shifting more attention to video salient object detection
Deng-Ping Fan, Wenguan Wang, Ming-Ming Cheng, and Jianbing Shen. Shifting more attention to video salient object detection. InCVPR, 2019
2019
-
[20]
Video segmentation by tracing discontinuities in a trajectory embedding
Katerina Fragkiadaki, Geng Zhang, and Jianbo Shi. Video segmentation by tracing discontinuities in a trajectory embedding. InCVPR, 2012
2012
-
[21]
Fleet, Saurabh Saxena, and Andrea Tagliasacchi
Lily Goli, Sara Sabour, Mark Matthews, Brubaker Marcus, Dmitry Lagun, Alec Jacobson, David J. Fleet, Saurabh Saxena, and Andrea Tagliasacchi. RoMo: Robust motion segmentation improves structure from motion. InICCV, 2025
2025
-
[22]
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti (Derek) Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Me...
2022
-
[23]
Geomotion: Rethinking motion segmentation via latent 4d geometry
Xiankang He, Peile Lin, Ying Cui, Dongyan Guo, Chunhua Shen, and Xiaoqin Zhang. Geomotion: Rethinking motion segmentation via latent 4d geometry. InCVPR, 2026
2026
-
[24]
Segment any motion in videos
Nan Huang, Wenzhao Zheng, Chenfeng Xu, Kurt Keutzer, Shanghang Zhang, Angjoo Kanazawa, and Qianqian Wang. Segment any motion in videos. InCVPR, 2025
2025
-
[25]
Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos
Suyog Dutt Jain, Bo Xiong, and Kristen Grauman. Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos. InCVPR, 2017
2017
-
[26]
Full-duplex strategy for video object segmentation
Ge-Peng Ji, Keren Fu, Zhe Wu, Deng-Ping Fan, Jianbing Shen, and Ling Shao. Full-duplex strategy for video object segmentation. InICCV, 2021
2021
-
[27]
Dynamicstereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Chris- tian Rupprecht. Dynamicstereo: Consistent dynamic depth from stereo videos. InCVPR, 2023
2023
-
[28]
Cotracker3: Simpler and better point tracking by pseudo-labeling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labeling real videos. In ICCV, 2025
2025
-
[29]
Learning segmentation from point trajectories
Laurynas Karazija, Iro Laina, Christian Rupprecht, and Andrea Vedaldi. Learning segmentation from point trajectories. InNeurIPS, 2024
2024
-
[30]
Motion trajectory segmentation via minimum cost multicuts
Margret Keuper, Bjoern Andres, and Thomas Brox. Motion trajectory segmentation via minimum cost multicuts. InICCV, 2015
2015
-
[31]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. InICCV, 2023
2023
-
[32]
Betrayed by motion: Camouflaged object discovery via motion segmentation
Hala Lamdouar, Charig Yang, Weidi Xie, and Andrew Zisserman. Betrayed by motion: Camouflaged object discovery via motion segmentation. InACCV, 2020
2020
-
[33]
Dong Lao, Zhengyang Hu, Francesco Locatello, Yanchao Yang, and Stefano Soatto. Divided attention: Unsupervised multi-object discovery with contextually separated slots.arXiv preprint arxiv:2304.01430, 2023
-
[34]
M. Lee, S. Cho, S. Lee, C. Park, and S. Lee. Unsupervised video object segmentation via prototype memory network. InWACV, 2023
2023
-
[35]
Guided slot attention for unsupervised video object segmentation
Minhyeok Lee, Suhwan Cho, Dogyoon Lee, Chaewon Park, Jungho Lee, and Sangyoun Lee. Guided slot attention for unsupervised video object segmentation. InCVPR, 2024. 11
2024
-
[36]
Ni, and Heung-Yeung Shum
Feng Li, Hao Zhang, Huaizhe Xu, Shilong Liu, Lei Zhang, Lionel M. Ni, and Heung-Yeung Shum. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. InCVPR, 2023
2023
-
[37]
Fuxin Li, Taeyoung Kim, Ahmad Humayun, David Tsai, and James M. Rehg. Video segmentation by tracking many figure-ground segments. InICCV, 2013
2013
-
[38]
Multi-sensor fusion for robust localization with moving object segmentation in complex dynamic 3D scenes.International Journal of Applied Earth Observation and Geoinformation, 2023
Qipeng Li, Yuan Zhuang, You Chen, Jianzhu Huai, Miaomiao Li, Tianxiang Ma, Yufei Tang, and Xinlian Liang. Multi-sensor fusion for robust localization with moving object segmentation in complex dynamic 3D scenes.International Journal of Applied Earth Observation and Geoinformation, 2023
2023
-
[39]
Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu, and William T. Freeman. Learning the depths of moving people by watching frozen people. InCVPR, 2019
2019
-
[40]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InCVPR, 2025
2025
-
[41]
Long Lian, Zhirong Wu, and Stella X. Yu. Bootstrapping objectness from videos by relaxed common fate and visual grouping. InCVPR, 2023
2023
-
[42]
Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. InICLR, 2026
2026
-
[43]
F2net: Learning to focus on the foreground for unsupervised video object segmentation
Daizong Liu, Dongdong Yu, Changhu Wang, and Pan Zhou. F2net: Learning to focus on the foreground for unsupervised video object segmentation. InAAAI, 2021
2021
-
[44]
Depth-aware test-time training for zero-shot video object segmentation
Weihuang Liu, Xi Shen, Haolun Li, Xiuli Bi, Bo Liu, Chi-Man Pun, and Xiaodong Cun. Depth-aware test-time training for zero-shot video object segmentation. InCVPR, 2024
2024
-
[45]
Hoi4d: A 4d egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. InCVPR, 2022
2022
-
[46]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[47]
See more, know more: Unsupervised video object segmentation with co-attention siamese networks
Xiankai Lu, Wenguan Wang, Chao Ma, Jianbing Shen, Ling Shao, and Fatih Porikli. See more, know more: Unsupervised video object segmentation with co-attention siamese networks. In CVPR, 2019
2019
-
[48]
arXiv preprint arXiv:2310.01040 , year =
Etienne Meunier and Patrick Bouthemy. Unsupervised motion segmentation in one go: Smooth long-term model over a video.arXiv preprint arXiv:2310.01040, 2023
-
[49]
Em-driven unsupervised learning for efficient motion segmentation.IEEE TPAMI, 2022
Etienne Meunier, Anaïs Badoual, and Patrick Bouthemy. Em-driven unsupervised learning for efficient motion segmentation.IEEE TPAMI, 2022
2022
-
[50]
Deep anomaly detection through visual attention in surveillance videos.Journal of Big Data, 2020
Nasaruddin Nasaruddin, Kahlil Muchtar, Afdhal Afdhal, and Alvin Prayuda Juniarta Dwiyantoro. Deep anomaly detection through visual attention in surveillance videos.Journal of Big Data, 2020
2020
-
[51]
P. Ochs, J. Malik, and T. Brox. Segmentation of moving objects by long term video analysis. IEEE TPAMI, 2014
2014
-
[52]
Object segmentation in video: a hierarchical variational approach for turning point trajectories into dense regions
Peter Ochs and Thomas Brox. Object segmentation in video: a hierarchical variational approach for turning point trajectories into dense regions. InICCV, 2011
2011
-
[53]
Video object segmentation using space-time memory networks
Seoung Wug Oh, Joon-Young Lee, Ning Xu, and Seon Joo Kim. Video object segmentation using space-time memory networks. InICCV, 2019
2019
-
[54]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[55]
Fast object segmentation in unconstrained video
Anestis Papazoglou and Vittorio Ferrari. Fast object segmentation in unconstrained video. In ICCV, 2013
2013
-
[56]
Hier- archical feature alignment network for unsupervised video object segmentation
Gensheng Pei, Fumin Shen, Yazhou Yao, Guo-Sen Xie, Zhenmin Tang, and Jinhui Tang. Hier- archical feature alignment network for unsupervised video object segmentation. InECCV, 2022
2022
-
[57]
A benchmark dataset and evaluation methodology for video object segmentation
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. InCVPR, 2016
2016
-
[58]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Occluded video instance segmentation: A benchmark.IJCV, 2022
Jiyang Qi, Yan Gao, Yao Hu, Xinggang Wang, Xiaoyu Liu, Xiang Bai, Serge Belongie, Alan Yuille, Philip Torr, and Song Bai. Occluded video instance segmentation: A benchmark.IJCV, 2022
2022
-
[60]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Reciprocal transformations for unsupervised video object segmentation
Sucheng Ren, Wenxi Liu, Yongtuo Liu, Haoxin Chen, Guoqiang Han, and Shengfeng He. Reciprocal transformations for unsupervised video object segmentation. InCVPR, 2021
2021
-
[62]
Hiera: A hierarchical vision transformer without the bells-and-whistles
Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, and Christoph Feichtenhofer. Hiera: A hierarchical vision transformer without the bells-and-whistles. InICML, 2023
2023
-
[63]
Multi-object discovery by low-dimensional object motion
Sadra Safadoust and Fatma Güney. Multi-object discovery by low-dimensional object motion. InICCV, 2023
2023
-
[64]
Generalizable fourier augmentation for unsupervised video object segmentation
Huihui Song, Tiankang Su, Yuhui Zheng, Kaihua Zhang, Bo Liu, and Dong Liu. Generalizable fourier augmentation for unsupervised video object segmentation. InAAAI, 2024
2024
-
[65]
Learning video object segmentation with visual memory
Pavel Tokmakov, Karteek Alahari, and Cordelia Schmid. Learning video object segmentation with visual memory. InICCV, 2017
2017
-
[66]
Learning to segment moving objects
Pavel Tokmakov, Cordelia Schmid, and Karteek Alahari. Learning to segment moving objects. IJCV, 2019
2019
-
[67]
Self- supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics
Jiangliu Wang, Jianbo Jiao, Linchao Bao, Shengfeng He, Yunhui Liu, and Wei Liu. Self- supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics. InCVPR, 2019
2019
-
[68]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[69]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024
2024
-
[70]
Xudong Wang, Ishan Misra, Zizun Zeng, Rohit Girdhar, and Trevor Darrell. Videocutler: Surpris- ingly simple unsupervised video instance segmentation.arXiv preprint arXiv:2308.14710, 2023
-
[71]
π3: Permutation-equivariant visual geometry learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning. InICLR, 2026
2026
-
[72]
Attention-based temporal encoding network with background-independent motion mask for action recognition.Computational Intelligence and Neuroscience, 2021
Zhengkui Weng, Zhipeng Jin, Shuangxi Chen, Quanquan Shen, Xiangyang Ren, and Wuzhao Li. Attention-based temporal encoding network with background-independent motion mask for action recognition.Computational Intelligence and Neuroscience, 2021
2021
-
[73]
Segmenting moving objects via an object-centric layered representation
Junyu Xie, Weidi Xie, and Andrew Zisserman. Segmenting moving objects via an object-centric layered representation. InNeurIPS, 2022. 13
2022
-
[74]
Appearance-based refinement for object-centric motion segmentation
Junyu Xie, Weidi Xie, and Andrew Zisserman. Appearance-based refinement for object-centric motion segmentation. InECCV, 2024
2024
-
[75]
Moving object segmentation: All you need is sam (and flow)
Junyu Xie, Charig Yang, Weidi Xie, and Andrew Zisserman. Moving object segmentation: All you need is sam (and flow). InACCV, 2024
2024
-
[76]
Kai Xu, Tze Ho Elden Tse, Jizong Peng, and Angela Yao. Das3r: Dynamics-aware gaussian splatting for static scene reconstruction.arXiv preprint arxiv:2412.19584, 2024
-
[77]
Youtube-vos: A large-scale video object segmentation benchmark
Ning Xu, Linjie Yang, Yuchen Fan, Dingcheng Yue, Yuchen Liang, Jianchao Yang, and Thomas Huang. Youtube-vos: A large-scale video object segmentation benchmark. InECCV, 2018
2018
-
[78]
Self-supervised video object segmentation by motion grouping
Charig Yang, Hala Lamdouar, Erika Lu, Andrew Zisserman, and Weidi Xie. Self-supervised video object segmentation by motion grouping. InICCV, 2021
2021
-
[79]
S. Yang, L. Zhang, J. Qi, H. Lu, S. Wang, and X. Zhang. Learning motion-appearance co-attention for zero-shot video object segmentation. InICCV, 2021
2021
-
[80]
Unsupervised moving object detection via contextual information separation
Yanchao Yang, Antonio Loquercio, Davide Scaramuzza, and Stefano Soatto. Unsupervised moving object detection via contextual information separation. InCVPR, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.