ReGuLaR: Relation-Grounded Latent Reasoning for Large Vision-Language Models
Pith reviewed 2026-06-29 07:37 UTC · model grok-4.3
The pith
ReGuLaR trains large vision-language models so their latent reasoning focuses on question-relevant objects and relations, then discards the training module at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
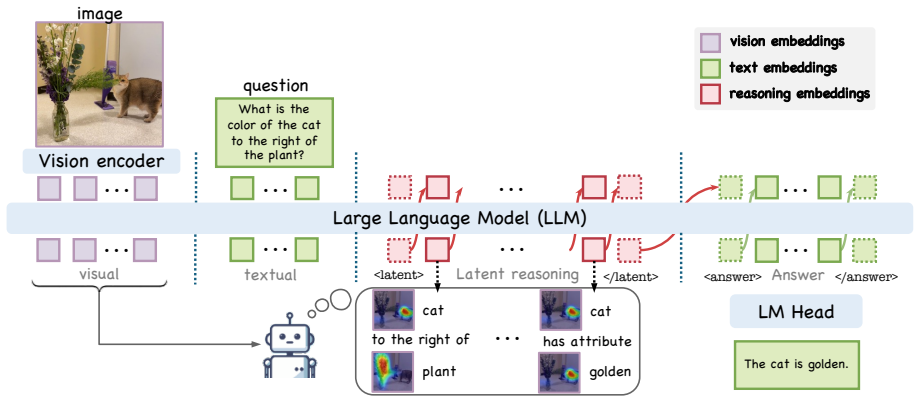
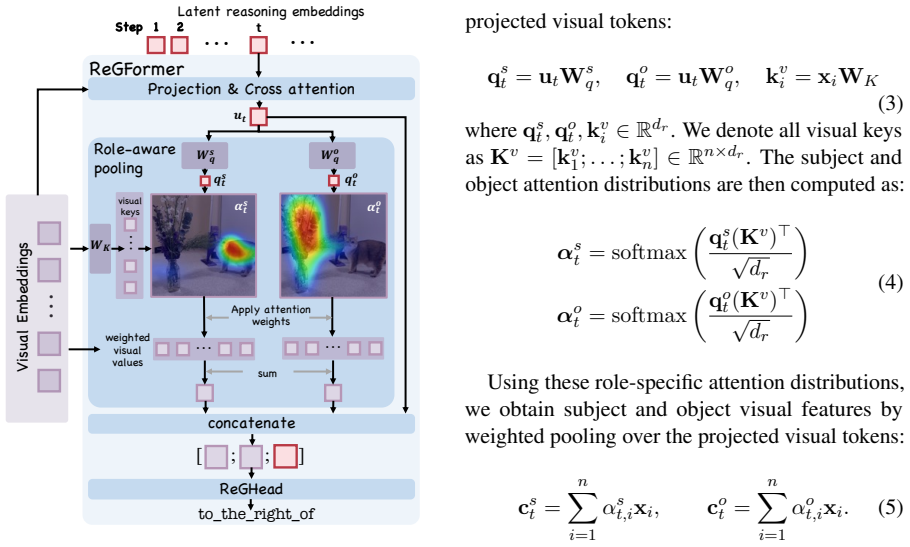
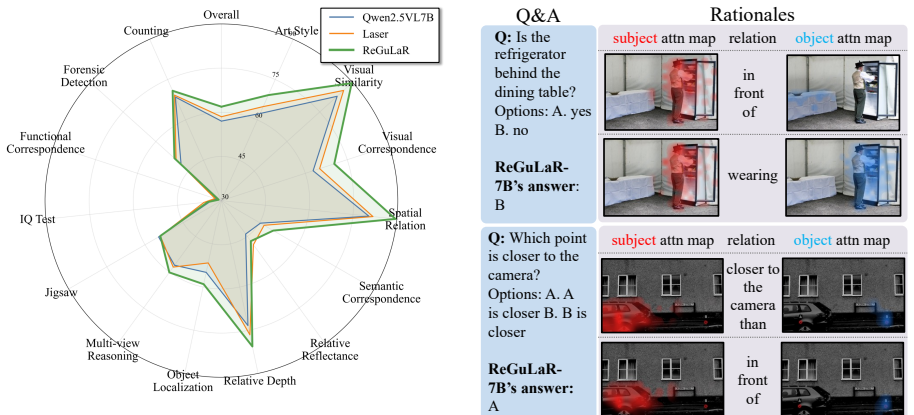
ReGuLaR is a training framework that introduces a ReGFormer to ground the latent states of a large vision-language model in question-relevant objects and inter-object relations drawn from the RGROUNDING-351K dataset. During training the ReGFormer shapes the model's continuous reasoning states; at inference the ReGFormer is removed and the model answers directly from its latent states. Experiments across multiple benchmarks show consistent gains over prior latent-reasoning methods.
What carries the argument
The ReGFormer, an auxiliary module used only during training that redirects latent states toward relevant objects and their relations.
If this is right
- Latent reasoning states become more tightly coupled to visual composition without extra inference steps.
- Performance improves on tasks that require understanding object interactions.
- The same training procedure can be applied to other vision-language models without changing their architecture at test time.
- A publicly released dataset of 351K relation-annotated images supports further work on grounded reasoning.
Where Pith is reading between the lines
- The method could be tested on whether similar auxiliary modules help ground reasoning in spatial layout or temporal sequences rather than only object relations.
- If the gains persist across model scales, the approach might reduce reliance on explicit chain-of-thought text for visual tasks.
- The dataset construction process itself might be reusable for other forms of visual evidence annotation.
Load-bearing premise
That improvements produced by the auxiliary ReGFormer during training remain encoded in the model's latent states after the module is removed for inference.
What would settle it
A controlled comparison in which two identical base models are trained—one with the ReGFormer and one without—then both are evaluated without the ReGFormer; if the ReGFormer-trained model shows no gain, the central claim is false.
Figures



read the original abstract
Chain-of-thought (CoT) reasoning has significantly improved the reasoning ability of large vision-language models (LVLMs) by verbalizing intermediate reasoning steps in natural language. However, such discrete textual rationales are often insufficient for encoding continuous visual evidence. Recent work addresses this limitation by moving reasoning into continuous latent space. Despite promising progress, existing methods leave latent reasoning insufficiently connected to the compositional and relational structure of visual evidence. To address this gap, we introduce ReGuLaR, a relation grounded latent reasoning framework that explicitly grounds latent states in these critical yet overlooked visual evidence. ReGuLaR uses a training-time ReGFormer to focus latent reasoning on question-relevant objects and inter-object relations, while at inference time the model reasons and generates answers without invoking the ReGFormer. To support training ReGuLaR, we construct RGROUNDING-351K, a real-world vision-language dataset annotated with key object bounding boxes and inter-object relations. Extensive experiments across diverse benchmarks show that ReGuLaR consistently outperforms existing approaches and achieves state-of-the-art performance. We include our code in the submission and will release the code and training data publicly upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReGuLaR, a relation-grounded latent reasoning framework for LVLMs. It trains with an auxiliary ReGFormer that focuses latent states on question-relevant objects and inter-object relations drawn from the new RGROUNDING-351K dataset; the ReGFormer is removed at inference so that the base LVLM performs latent reasoning and answer generation unaided. The central claim is that this training procedure yields consistent outperformance and state-of-the-art results across diverse benchmarks.
Significance. If the training-time auxiliary module successfully embeds improved relation sensitivity into the LVLM's latent states that remain usable without the module, the method would offer a low-overhead way to strengthen compositional visual reasoning. The commitment to release code and the RGROUNDING-351K dataset supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that ReGuLaR 'consistently outperforms existing approaches and achieves state-of-the-art performance' is asserted without any quantitative numbers, ablation tables, error bars, or dataset statistics, preventing verification of the central empirical claim.
- [Method / Training and Inference] Training procedure (described in the abstract and method overview): the load-bearing assumption that the ReGFormer modifies the base LVLM's internal representations such that relation-grounded improvements persist at inference without the ReGFormer is asserted but not directly evidenced; gains could arise from dataset scale or standard fine-tuning rather than the intended mechanism. Direct tests (e.g., probing of relation sensitivity or attention maps before/after training) are required to secure the transfer claim.
minor comments (2)
- [Dataset] Clarify the exact construction pipeline and annotation protocol for RGROUNDING-351K, including inter-annotator agreement and how bounding boxes and relations were obtained.
- [Abstract] The abstract states that code is included in the submission; confirm whether the released code will contain the full training pipeline and evaluation scripts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and commit to revisions that strengthen the empirical presentation and mechanistic evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ReGuLaR 'consistently outperforms existing approaches and achieves state-of-the-art performance' is asserted without any quantitative numbers, ablation tables, error bars, or dataset statistics, preventing verification of the central empirical claim.
Authors: We agree that the abstract would benefit from quantitative support. In the revised version we will incorporate key performance numbers (e.g., average gains over strong baselines and representative SOTA scores), the size of RGROUNDING-351K, and a concise reference to the main ablation results. revision: yes
-
Referee: [Method / Training and Inference] Training procedure (described in the abstract and method overview): the load-bearing assumption that the ReGFormer modifies the base LVLM's internal representations such that relation-grounded improvements persist at inference without the ReGFormer is asserted but not directly evidenced; gains could arise from dataset scale or standard fine-tuning rather than the intended mechanism. Direct tests (e.g., probing of relation sensitivity or attention maps before/after training) are required to secure the transfer claim.
Authors: We acknowledge that isolating the contribution of the ReGFormer beyond dataset scale is important. While the diverse relational-reasoning benchmarks already provide supporting evidence, we will add a controlled ablation in the revision that compares ReGuLaR against standard fine-tuning on the identical RGROUNDING-351K data (without the ReGFormer). This directly tests whether the observed gains require the relation-grounding training procedure. We will also include qualitative attention visualizations on held-out examples to illustrate changes in focus on relevant objects and relations. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experiments, not self-referential derivation
full rationale
The paper describes an empirical training procedure that employs an auxiliary ReGFormer only during training (removed at inference) and evaluates performance on external benchmarks after constructing RGROUNDING-351K. No mathematical derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The SOTA claim is asserted via experimental results rather than any closed logical loop that reduces to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie
Sketch-in-latents: Eliciting unified reasoning in mllms.arXiv preprint arXiv:2512.16584. Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multi- modal llms. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9568–9578. Oriol V...
-
[2]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Softcot: Soft chain-of-thought for efficient reasoning with llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23336– 23351. Jingkang Yang, Yi Zhe Ang, Zujin Guo, Kaiyang Zhou, Wayne Zhang, and Ziwei Liu. 2022. Panoptic scene graph generation. InEuropean conference on com- puter v...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
The training process takes approximately 70 hours to complete
For the training objective, we set λans = 1.0 , λrel = 1.0, and λattn = 0.1. The training process takes approximately 70 hours to complete. During inference, ReGFormer is removed, and the model performs a fixed number of latent reasoning steps before generating the final answer. Unless otherwise specified, all results are ob- tained from a single training...
2014
-
[4]
image: the image to be annotated
-
[5]
Each object contains: - object_id: a unique identifier; - name: the object category or noun phrase; - attributes: optional visual attributes; - bbox: [x_min, y_min, x_max, y_max]
objects: a list of objects in the image. Each object contains: - object_id: a unique identifier; - name: the object category or noun phrase; - attributes: optional visual attributes; - bbox: [x_min, y_min, x_max, y_max]
-
[6]
Each relation contains: - subject_id; - subject_name; - relation; - object_id; - object_name
relations: a list of scene-graph relations. Each relation contains: - subject_id; - subject_name; - relation; - object_id; - object_name
-
[7]
Task: Generate one question-answer pair grounded in one or more scene-graph relations
target_relation_candidates: an optional subset of relations selected as candidate targets. Task: Generate one question-answer pair grounded in one or more scene-graph relations. If target_relation_candidates is provided and non-empty, select the target relation(s) only from this subset. Otherwise, select the target relation(s) from the full relations list...
-
[8]
The question must be answerable from the image and the provided annotations
-
[9]
The question must be grounded in explicit relation(s) from the scene graph, such as subject-relation-object, or in a directly annotated visual attribute of an object
-
[10]
The answer must be short, accurate, and uniquely determined by the selected target relation(s) or attribute(s)
-
[11]
The target subject and object must be grounded by valid bounding boxes
-
[12]
If multiple objects have the same name or category, the question must distinguish the intended object using visible attributes, spatial context, or relations to other objects
-
[13]
The question should be natural and concise, but clarity and unambiguity are more important than linguistic variety
-
[14]
Do not infer information that is not supported by the image and annotations
Do not use external knowledge. Do not infer information that is not supported by the image and annotations
-
[15]
Do not ask questions that require subjective judgment, uncertain visibility, fine-grained identity recognition, or private/sensitive attributes such as race, ethnicity, nationality, religion, gender identity, age, disability, health status, or socioeconomic status
-
[16]
Do not generate unsafe, offensive, discriminatory, or inappropriate content
-
[17]
Validation Before Output: Before returning the result, verify that:
Prefer rejecting the example over generating a question that is ambiguous, underspecified, weakly supported, or likely to have more than one valid answer. Validation Before Output: Before returning the result, verify that:
-
[18]
every target relation appears exactly in the provided relation list
-
[19]
every supporting object appears in the provided object list and has a valid bounding box
-
[20]
the question can be answered without using any information outside the image and annotations
-
[21]
the answer is consistent with the selected target relation(s)
-
[22]
no other object or relation in the annotations would make a different answer equally valid
-
[23]
status":
the question wording does not introduce assumptions beyond the image and annotations. Output Format: Return only a JSON object. Do not include any additional text. If a valid question-answer pair can be generated, return: { "status": "ok", "question": "...", "answer": "...", "target_relations": [ { "subject_id": "...", "subject_name": "...", "relation": "...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.