Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents
Pith reviewed 2026-06-29 06:41 UTC · model grok-4.3
The pith
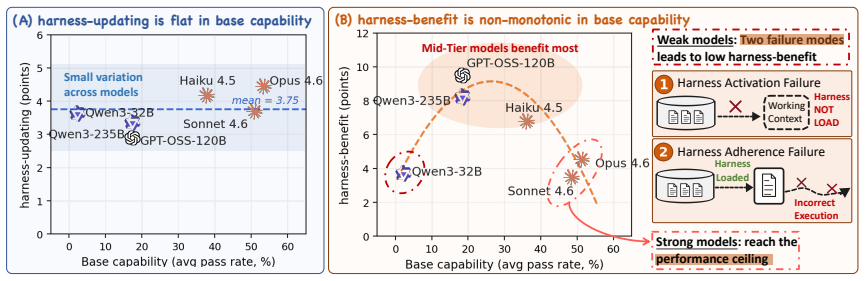
Harness updating stays flat across model strengths while benefit from updates peaks at mid-tier models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
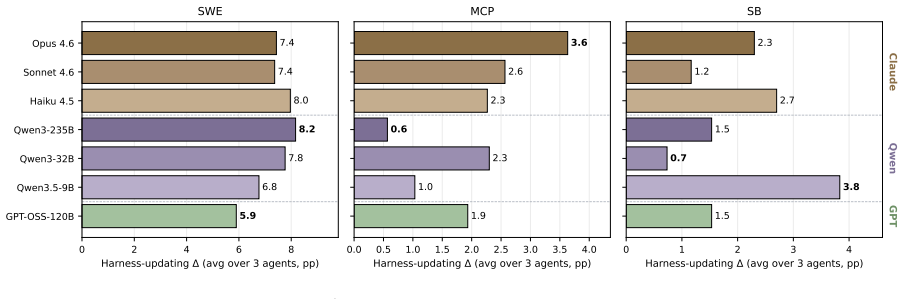
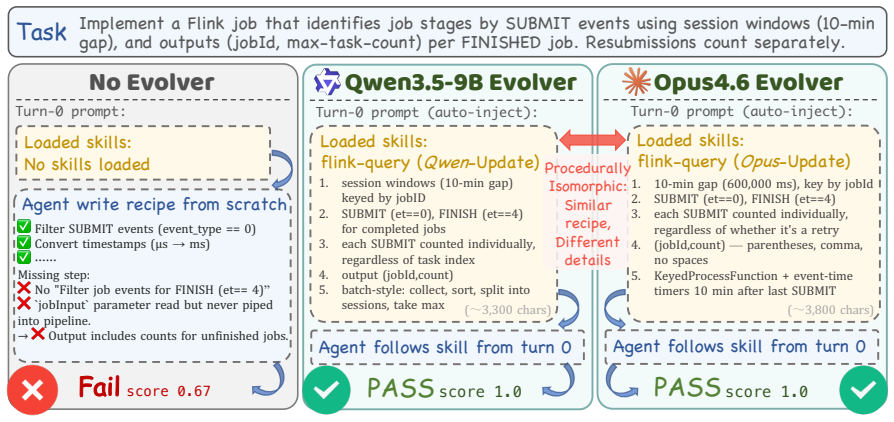
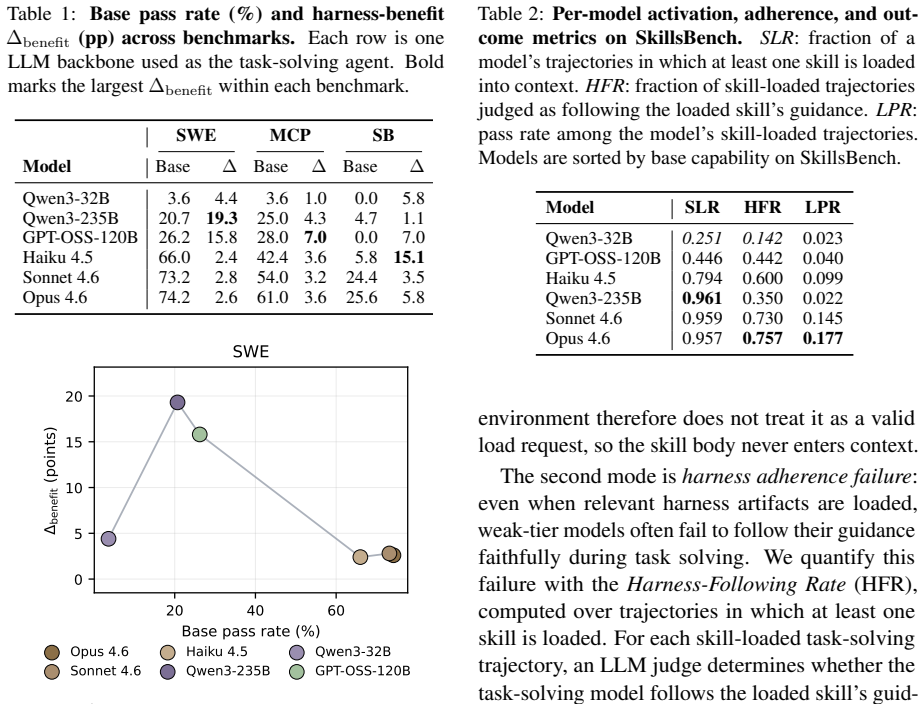
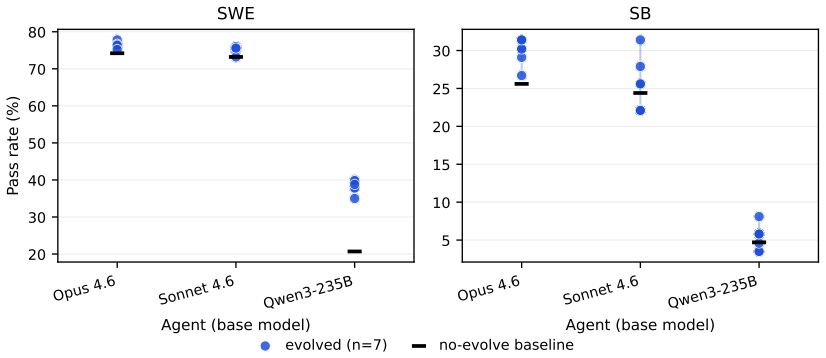
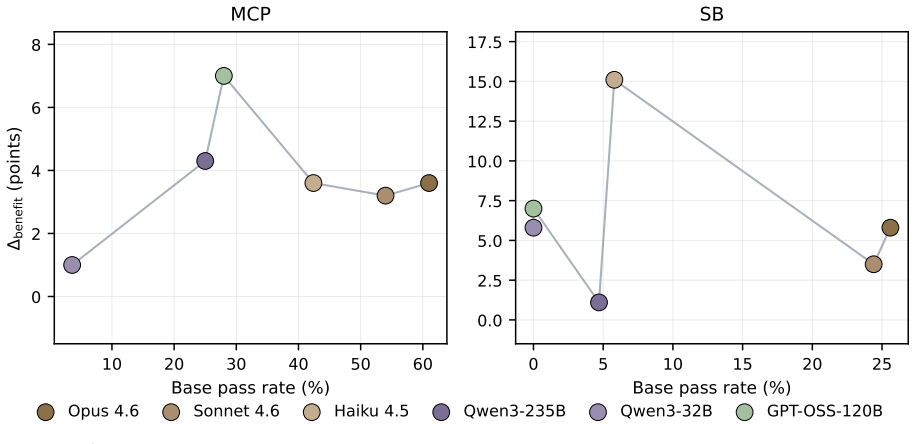
Harness-updating is flat in base capability: models from different capability tiers produce harness updates that lead to surprisingly similar gains; even Qwen3.5-9B's updates yield gains comparable to those of Claude Opus 4.6. Harness-benefit is non-monotonic in base capability: weak-tier models benefit little from updated harnesses, mid-tier models benefit most, and strong-tier models benefit less than mid-tier. Weak-tier models exhibit two failure modes: they may fail to activate relevant harness artifacts or activate them but fail to follow them faithfully.
What carries the argument
The distinction between harness-updating capability (producing useful persistent updates from evidence) and harness-benefit capability (gaining performance from those updates during task solving).
If this is right
- Models from weak to strong tiers generate harness updates that deliver comparable performance gains.
- Weak models fail either to activate harness artifacts or to follow them once activated.
- Capability investment should target the task-solving agent more than the evolver component.
- Agent training should emphasize harness invocation and faithful long-horizon instruction following.
Where Pith is reading between the lines
- Evolution steps could be assigned to a mid-tier model while execution uses a different tier to capture the peak benefit region.
- The non-monotonic benefit pattern may extend to other external memory or tool-update mechanisms beyond the harness types tested.
- Training objectives that reward instruction adherence to external artifacts could raise the benefit curve for weaker models.
Load-bearing premise
The tested harness updates and task setups allow clean separation of updating capability from benefit capability without confounding effects from specific model architectures, task distributions, or harness types.
What would settle it
A controlled experiment in which stronger models produce harness updates that yield substantially larger average gains than those from weaker models across the same task set would falsify the flatness of harness-updating.
Figures



read the original abstract
LLM agents are increasingly deployed as systems built around editable external harnesses, including prompts, skills, memories and tools, that shape task execution without changing model parameters. Harness self-evolution adapts such agents by updating these harnesses from execution evidence. Yet it remains unclear whether a model's base capability in task-solving predicts its capabilities in harness self-evolution: which models produce useful harness updates, and which actually benefit from them? We analyze two harness self-evolution capabilities: (i) harness-updating, the capability to produce useful persistent harness updates from execution evidence; (ii) harness-benefit, the capability to benefit from updated harnesses during task solving. Our analysis reveals two findings. First, harness-updating is flat in base capability: models from different capability tiers produce harness updates that lead to surprisingly similar gains; even Qwen3.5-9B's updates yield gains comparable to those of Claude Opus~4.6. Second, harness-benefit is non-monotonic in base capability: weak-tier models benefit little from updated harnesses, mid-tier models benefit most, and strong-tier models benefit less than mid-tier. We trace low gains at the weak tier to two failure modes: weak-tier models may fail to activate relevant harness artifacts, or activate them but fail to follow them faithfully. These findings suggest investing capability budget in the task-solving agent rather than the evolver, and targeting harness invocation and long-horizon instruction following in agent training. Our source code is publicly available at https://github.com/A-EVO-Lab/a-evolve/tree/release/harness-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes self-evolving LLM agents that use editable external harnesses (prompts, skills, memories, tools). It distinguishes two capabilities: harness-updating (producing useful persistent updates from execution evidence) and harness-benefit (improving task performance when using updated harnesses). The central empirical claims are that harness-updating is flat across base model capability tiers (updates from weak models like Qwen3.5-9B yield gains comparable to those from strong models like Claude Opus 4.6) while harness-benefit is non-monotonic (mid-tier models benefit most; weak models show little benefit due to activation or faithful-following failures). Public code is provided.
Significance. If the separation of updating and benefit capabilities holds under controlled conditions, the results would usefully inform agent design by indicating that capability investment should prioritize the task-solving agent over the evolver and that training should target harness invocation and long-horizon following. The public code release is a clear strength for reproducibility.
major comments (1)
- [Experimental design] The experimental design section does not report the number of models, tasks, harness types, or statistical tests used to establish flatness of updating gains and non-monotonicity of benefit gains. Without these controls, confounding from task distribution or harness specificity could undermine the clean separation of the two capabilities.
minor comments (1)
- [Abstract] Model names in the abstract ('Qwen3.5-9B', 'Claude Opus~4.6') should be standardized to conventional nomenclature for clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer reporting of experimental controls. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental design] The experimental design section does not report the number of models, tasks, harness types, or statistical tests used to establish flatness of updating gains and non-monotonicity of benefit gains. Without these controls, confounding from task distribution or harness specificity could undermine the clean separation of the two capabilities.
Authors: We agree that the experimental design section should explicitly enumerate these quantities to strengthen the claims. In the revised manuscript we will add a dedicated paragraph (and accompanying table) stating: the total number of base models evaluated and their tier distribution; the number and identity of tasks; the four harness types (prompts, skills, memories, tools); and the statistical procedures (e.g., paired t-tests or non-parametric equivalents) used to assess flatness of updating gains and non-monotonicity of benefit gains. The public code repository already contains the full experimental configuration, but we will make the counts and tests transparent in the text itself. revision: yes
Circularity Check
No significant circularity; empirical findings from new experiments
full rationale
The paper reports two empirical findings on harness-updating and harness-benefit capabilities, derived from experiments across model tiers with public code for reproduction. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text. The separation of capabilities is an experimental outcome, not a reduction to prior inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
TBS is an interval-based multi-agent framework that separates private internal-state updates (dissonance appraisal, opinion climate, isolation risk, response strategy, willingness to speak) from public utterance selec...
-
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
TBS is an interval-based multi-agent LLM simulation framework that separates structured internal evaluative states from public utterance generation and shows these states vary systematically with turn-allocation, sile...
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925. Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Ar- nav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alex Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2026. GEPA: Reflective prompt ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model context protocol (mcp): Land- scape, security threats, and future research direc- tions.ACM Transactions on Software Engineering and Methodology. Sihang Jiang, Lipeng Ma, Zhonghua Hong, Keyi Wang, Zhiyu Lu,...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
stores verbal self-reflections from prior at- tempts, Self-Refine (Madaan et al., 2023) itera- tively improves outputs through self-feedback, and ExpeL (Zhao et al., 2024) extracts reusable natural- language insights from training trajectories for later retrieval. These methods show that language feed- back can improve future behavior, but the persis- ten...
2023
-
[4]
Collectively, these methods show that writing execution experience back into persistent harness components can improve downstream task perfor- mance
induces workflows from successful trajecto- ries, SkillRL (Xia et al., 2026) recursively expands a skill library through reinforcement learning, and EvoSkill (Alzubi et al., 2026) studies automated skill discovery from agent experience.Tool-level self-evolution further allows agents to synthesize, revise, or accumulate tools and tool-use knowledge over ti...
2026
-
[5]
Identify the root cause
Understand the issue: Read the issue de- scription carefully. Identify the root cause
-
[6]
Locate relevant code: Use search tools to find the files and functions involved
-
[7]
Plan the fix: Think step-by-step about what needs to change and why
-
[8]
Avoid unnecessary changes
Implement the fix: Make minimal, pre- cise edits. Avoid unnecessary changes
-
[9]
Guidelines • Prefer small, focused patches over large rewrites
Verify: Run existing tests to confirm the fix works and doesn’t break anything. Guidelines • Prefer small, focused patches over large rewrites. • Always check for edge cases the issue de- scription mentions. • If the issue includes a reproduction script, use it to verify your fix. • When in doubt, look at how similar patterns are handled elsewhere in the ...
-
[10]
Understand the task: Read the task de- scription and identify what needs to be accomplished
-
[11]
Review available tools: Check the tool schemas to understand available opera- tions and their parameters
-
[12]
Plan the call sequence: Determine which tools to call and in what order
-
[13]
Execute: Make tool calls with correctly formatted JSON parameters
-
[14]
Guidelines • NEVER ask the user for clarification
Validate: Check the return values and han- dle errors gracefully. Guidelines • NEVER ask the user for clarification. You must use the available tools to find all in- formation needed to complete the task. If the task mentions calendar events, sched- ules, or appointments, use the calendar/- workspace tools to look them up. • Always validate parameters aga...
-
[15]
Do NOT extract advice, rationale, examples, or motivational text as instructions
Identify procedural instructions directly entailed by imperative or normative language in SKILL_BODY. Do NOT extract advice, rationale, examples, or motivational text as instructions
-
[16]
required
For each instruction, provide: •id: stable identifier (e.g.,"step_1"). •source_span : EXACT quoted text from SKILL_BODY that grounds this instruction (must be a substring ofSKILL_BODY, max 250 characters). •text: paraphrased instruction in one imperative sentence. •type : "required" (must execute) |"conditional" (must execute if trigger occurs) | "optiona...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.