The Tutoring Effectiveness Index: Predicting LLM Math Tutor Quality from Four Conversation Signals
Pith reviewed 2026-06-29 00:06 UTC · model grok-4.3
The pith
Four internal signals let a frozen LLM select its own best math-tutoring responses and raise student improvement from 59 percent to 81.9 percent at N=8.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
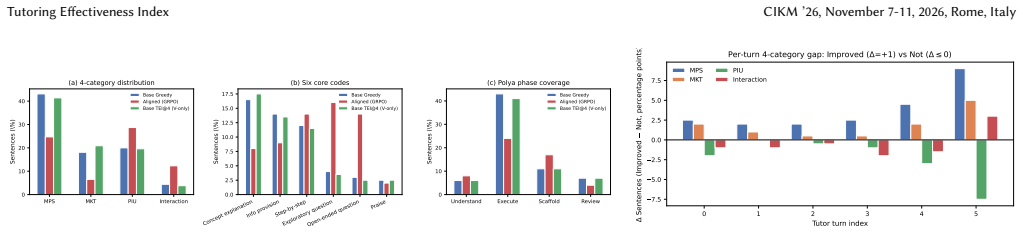
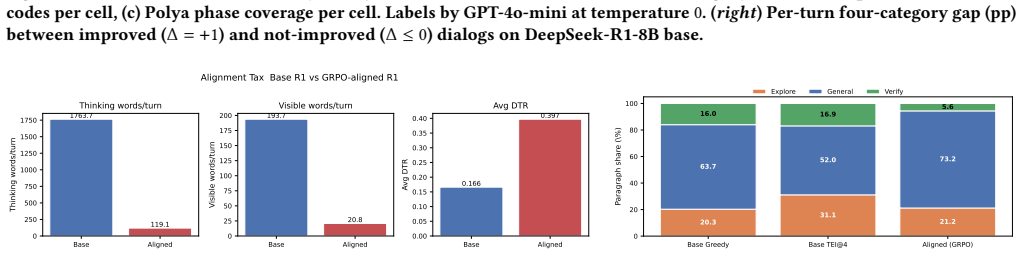
The Tutoring Effectiveness Index is a training-free, judge-free score formed from four conversation signals that ranks candidate tutor responses. On a frozen base model, the TEI@8 rule raises the improvement rate on pre-incorrect scenarios from 59.0 percent to 81.9 percent. Pedagogical alignment training reduces thinking length by 93 percent, cuts content-knowledge and pedagogical-knowledge accuracy by 71 percent and 80 percent, and changes student solve-rate improvement from positive to negative. A one-shot structural classifier reproduces an 82-code educational codebook across 119009 tutor sentences.
What carries the argument
The Tutoring Effectiveness Index, a composite score from Schoenfeld-Verify keyword ratio, math-step density, ends-question rate, and deep-reasoning gate.
If this is right
- Selection among multiple generations improves tutoring outcomes on a frozen model without reinforcement learning or external judges.
- The four signals can be extracted directly from the model's internal conversation traces.
- Pedagogical alignment training shortens responses dramatically and reverses student improvement.
- A structural classifier can scale validation of tutoring content against an 82-code codebook.
Where Pith is reading between the lines
- The same signals might serve as cheap quality filters when deploying tutoring models in other subject areas.
- If the signals remain predictive across model scales, they could replace costly human or LLM-based evaluations during inference.
- The large alignment tax observed suggests that general-purpose alignment objectives can conflict with tutoring-specific goals.
- Reproducing codebooks via classifiers opens a route to automated auditing of large volumes of tutoring dialogue.
Load-bearing premise
The four signals actually forecast real gains in students' later solve rates rather than merely reflecting surface patterns in the responses.
What would settle it
Run the same candidate-generation and selection procedure, then measure actual post-tutoring solve rates on a fresh set of math problems to test whether the top-ranked responses still deliver the reported 22.9-point gain over random selection.
Figures
read the original abstract
Aligning large language models (LLMs) as math tutors typically demands costly reinforcement-learning (RL) training and external LLM judges. We ask whether a frozen model's internal reasoning signals can replace both. We propose the Tutoring Effectiveness Index (TEI), a training-free, judge-free four-signal index that combines a Schoenfeld-Verify keyword ratio, a math-step density, an ends-question rate, and a deep-reasoning gate from the Deep-Thinking Ratio (DTR) probe. Selecting from $N$ candidates with TEI (the TEI@$N$ rule) raises the improvement rate on pre-incorrect scenarios from $59.0\%$ to $81.9\%$ at $N{=}8$ on a frozen DeepSeek-R1-8B base, with no training and no external judge. We also measure the alignment tax of pedagogical GRPO. Thinking length drops from $1{,}764$ to $119$ words per turn ($-93\%$), Content-Knowledge and Pedagogical-Knowledge accuracy fall by $-71\%$ and $-80\%$ relative, and the student's $\Delta$ Solve Rate crosses from $+0.180$ to $-0.012$. To anchor the behavioural reading, we reproduce an 82-code educational codebook on $119{,}009$ tutor sentences with a one-shot structural classifier. Together, these results offer a cost-effective recipe for building math-tutoring LLMs without RL training or external judges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Tutoring Effectiveness Index (TEI), a training-free four-signal index (Schoenfeld-Verify keyword ratio, math-step density, ends-question rate, deep-reasoning gate from DTR) to predict LLM math tutor quality. It claims that TEI@N selection from N=8 candidates on a frozen DeepSeek-R1-8B model raises the improvement rate on pre-incorrect scenarios from 59.0% to 81.9% without training or external judges. It further quantifies the alignment tax of pedagogical GRPO (e.g., thinking length drop of 93%, accuracy drops of 71-80%) and reproduces an 82-code educational codebook on 119009 tutor sentences via one-shot classification.
Significance. If the predictive validity holds, the work supplies a low-cost, reproducible alternative to RL alignment and external judges for math-tutoring LLMs. The reported TEI@N lift is quantitatively large, and the codebook reproduction on a large sentence corpus provides useful empirical grounding for behavioral claims. These elements could meaningfully lower barriers to developing effective educational AI systems.
major comments (2)
- [TEI@N selection experiment] TEI@N selection experiment: The reported lift from 59.0% to 81.9% at N=8 shows only that the four signals induce a ranking different from uniform sampling. No direct correlation (Pearson, Spearman, or AUC) between per-response TEI scores and downstream ΔSolve Rate is reported on held-out data never used for selection. This is load-bearing for the central claim that the signals track pedagogical quality rather than length, keyword density, or model artifacts.
- [Methods / Signal definitions] Signal definitions and dataset: The abstract and evaluation supply no explicit formulas, weighting scheme, or thresholds for the four signals, nor details on how the test scenarios, pre-incorrect labels, or improvement-rate metric were constructed. Without these, the data-to-claim link cannot be verified and the result is difficult to reproduce.
minor comments (2)
- [Abstract] Abstract notation: Expressions such as N{=}8 and $Δ$ Solve Rate should be standardized to conventional LaTeX (N=8, ΔSolve Rate) for readability.
- [Codebook reproduction] Codebook section: The one-shot classifier reproduction is a strength, but reporting per-code precision/recall or inter-annotator agreement would allow readers to assess its reliability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. The concerns about direct validation of the signals and reproducibility are well-taken; we address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [TEI@N selection experiment] TEI@N selection experiment: The reported lift from 59.0% to 81.9% at N=8 shows only that the four signals induce a ranking different from uniform sampling. No direct correlation (Pearson, Spearman, or AUC) between per-response TEI scores and downstream ΔSolve Rate is reported on held-out data never used for selection. This is load-bearing for the central claim that the signals track pedagogical quality rather than length, keyword density, or model artifacts.
Authors: The TEI@N results show that responses ranked higher by the four signals produce substantially better student outcomes than uniform sampling from the identical frozen model. While this functional improvement supports the claim that the signals track pedagogical quality, we agree that reporting direct per-response correlations (Pearson, Spearman, and AUC) on held-out data would provide stronger evidence against confounds such as length or keyword artifacts. We will add this analysis in the revision. revision: yes
-
Referee: [Methods / Signal definitions] Signal definitions and dataset: The abstract and evaluation supply no explicit formulas, weighting scheme, or thresholds for the four signals, nor details on how the test scenarios, pre-incorrect labels, or improvement-rate metric were constructed. Without these, the data-to-claim link cannot be verified and the result is difficult to reproduce.
Authors: We agree that the evaluation section should contain explicit, self-contained definitions. The full manuscript defines the signals in Methods (Schoenfeld-Verify keyword ratio, math-step density, ends-question rate, and DTR deep-reasoning gate) with equal weighting and reports the improvement-rate metric on pre-incorrect scenarios, but these details are not repeated in the evaluation. We will add a dedicated reproducibility subsection with all formulas, weights, thresholds, scenario construction, and metric definitions. revision: yes
Circularity Check
No significant circularity; TEI defined from signals and evaluated on external outcome metric
full rationale
The paper defines TEI directly from four observable signals (Schoenfeld-Verify keyword ratio, math-step density, ends-question rate, deep-reasoning gate) without any fitting to the target student solve-rate improvement. The TEI@N selection result is shown by comparing ranked vs. uniform sampling on the downstream metric, which is measured independently. No equation reduces the claimed prediction to its inputs by construction, no self-citation chain bears the central claim, and no ansatz or uniqueness theorem is imported. The derivation remains self-contained against the external student-outcome benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four conversation signals are predictive of tutoring effectiveness
Reference graph
Works this paper leans on
- [1]
-
[2]
Deborah Loewenberg Ball, Mark Hoover Thames, and Geoffrey Phelps. 2008. Content Knowledge for Teaching: What Makes It Special?Journal of Teacher Education59, 5 (2008), 389–407
2008
- [3]
-
[4]
Chi and Ruth Wylie
Michelene T.H. Chi and Ruth Wylie. 2014. The ICAP Framework: Linking Cogni- tive Engagement to Active Learning Outcomes.Educational Psychologist49, 4 (2014), 219–243
2014
-
[5]
David Dinucu-Jianu, Jakub Macina, Nico Daheim, Ido Hakimi, Iryna Gurevych, and Mrinmaya Sachan. 2025. From Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
- [6]
-
[7]
Unggi Lee, Jiyeong Bae, Jaehyeon Park, Haeun Park, Taejun Park, Younghoon Jeon, Sungmin Cho, Junbo Koh, Yeil Jeong, and Gyeonggeon Lee. 2026. Reward- ing How Models Think Pedagogically: Integrating Pedagogical Reasoning and Thinking Rewards for LLMs in Education.arXiv preprint arXiv:2601.14560(2026)
-
[8]
Unggi Lee, Sookbun Lee, Heungsoo Choi, Jinseo Lee, Haeun Park, Younghoon Jeon, Sungmin Cho, Minju Kang, Junbo Koh, Jiyeong Bae, Minwoo Nam, Juyeon Eun, Yeonji Jung, and Yeil Jeong. 2026. OpenLearnLM Benchmark: A Unified Framework for Evaluating Knowledge, Skill, and Attitude in Educational Large Language Models.arXiv preprint arXiv:2601.13882(2026)
-
[9]
Yifei Liu, Yuxin Cao, Peng Li, and Bo Xu. 2024. Aligning LLM Tutors via Socratic Persona. InAdvances in Neural Information Processing Systems, Vol. 37
2024
-
[10]
Jakub Macina, Nico Daheim, Sankalan Pal Chowdhury, Tanmay Sinha, Manu Kapur, Iryna Gurevych, and Mrinmaya Sachan. 2023. MathDial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems. InFindings of the Association for Computational Linguistics: EMNLP 2023
2023
-
[11]
1945.How to Solve It: A New Aspect of Mathematical Method
George Pólya. 1945.How to Solve It: A New Aspect of Mathematical Method. Princeton University Press
1945
-
[12]
Schoenfeld
Alan H. Schoenfeld. 1985.Mathematical Problem Solving. Academic Press
1985
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Lee S. Shulman. 1986. Those Who Understand: Knowledge Growth in Teaching. Educational Researcher15, 2 (1986), 4–14
1986
-
[15]
Anaïs Tack and Chris Piech. 2022. The AI Teacher Test: Measuring the Pedagogical Ability of Blender and GPT-3 in Educational Dialogues. InProceedings of the International Conference on Artificial Intelligence in Education
2022
-
[16]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. 2023. Activation Addition: Steering Lan- guage Models Without Optimization.arXiv preprint arXiv:2308.10248(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models.arXiv preprint arXiv:2203.11171 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.Advances in Neural Information Processing Systems35 (2022)
2022
-
[19]
Bruner, and Gail Ross
David Wood, Jerome S. Bruner, and Gail Ross. 1976. The Role of Tutoring in Problem Solving.Journal of Child Psychology and Psychiatry17, 2 (1976), 89–100
1976
-
[20]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judg- ing LLM-as-a-Judge with MT-Bench and Chatbot Arena.Advances in Neural Information Processing Systems36 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.