FLAG: Flow Policy MaxEnt-RL by Latent Augmented Guidance
Pith reviewed 2026-06-28 23:19 UTC · model grok-4.3
The pith
FLAG augments the state with a flow latent variable to optimize a provably consistent proxy MaxEnt-RL objective that avoids importance weight collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
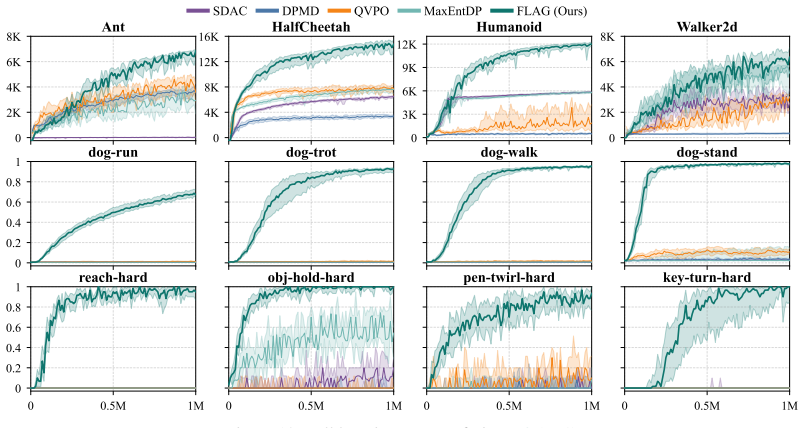
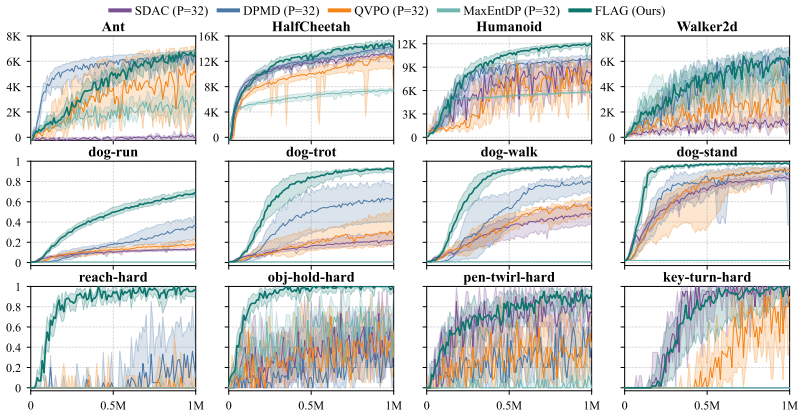
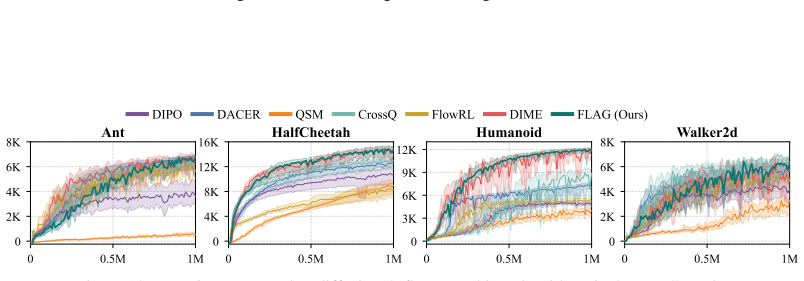
FLAG augments the state space with a flow latent variable and optimizes a provably consistent proxy MaxEnt-RL objective. By localizing the sampling region, the approach avoids the weight degeneracy that arises when importance sampling is performed over the entire action space, thereby enabling expressive policy optimization with limited samples that scales to high-dimensional tasks.
What carries the argument
State augmentation with a flow latent variable that localizes the region for importance sampling inside the MaxEnt-RL objective.
If this is right
- Expressive generative policies become usable inside MaxEnt-RL without restricting to Gaussians.
- Optimization succeeds with a small number of importance samples.
- The method scales to high-dimensional continuous control tasks.
- State-of-the-art performance is reached across standard benchmarks.
- The learned policy satisfies a proxy objective that is provably consistent with the true MaxEnt-RL objective.
Where Pith is reading between the lines
- The same latent-augmentation pattern could be tested in other off-policy algorithms that rely on importance sampling.
- If the localization effect holds, the approach may extend naturally to partially observable or multi-agent settings where action spaces are also high-dimensional.
- A direct comparison of sample efficiency against non-augmented flow policies on the same tasks would isolate the contribution of the state augmentation.
Load-bearing premise
Augmenting the state with a flow latent variable successfully localizes the sampling region and thereby avoids the weight degeneracy induced by importance sampling over the entire action space.
What would settle it
Persistent importance-weight collapse or inability to scale on high-dimensional control tasks when the latent augmentation is used would falsify the localization claim.
Figures
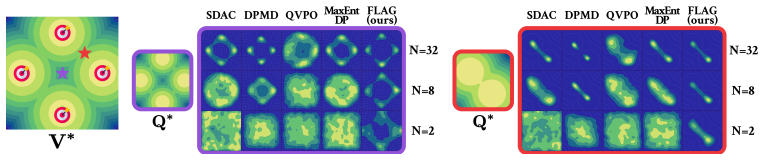

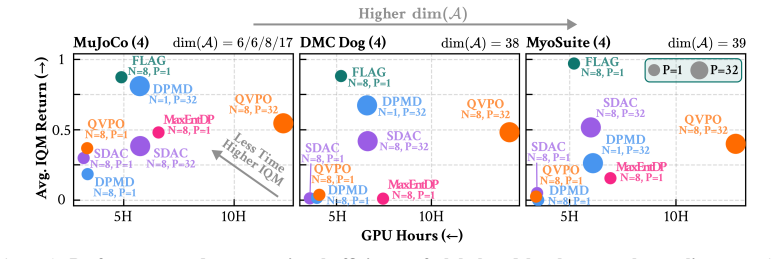
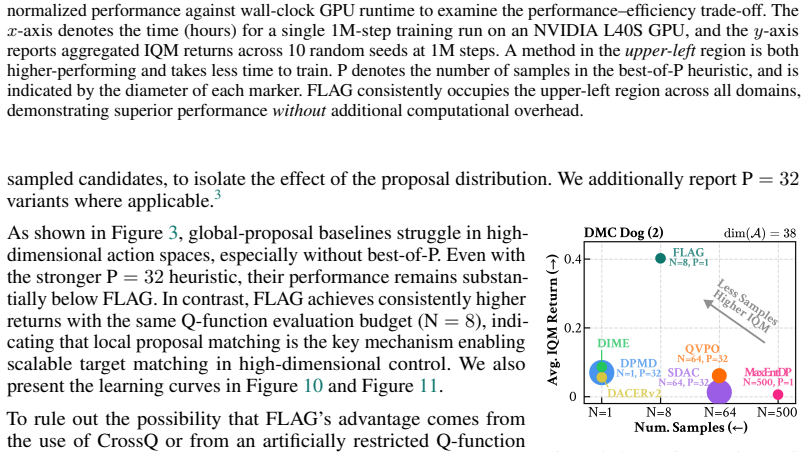
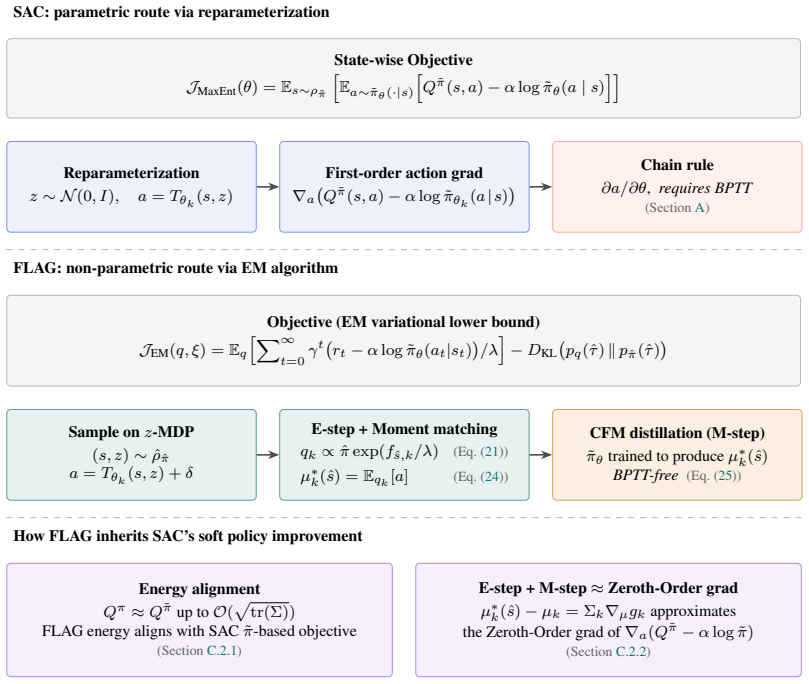
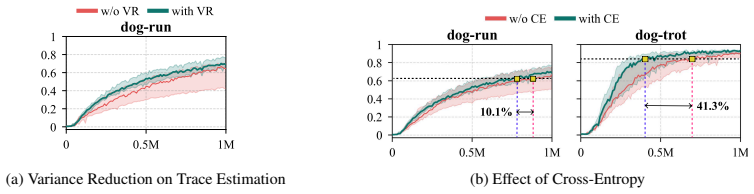
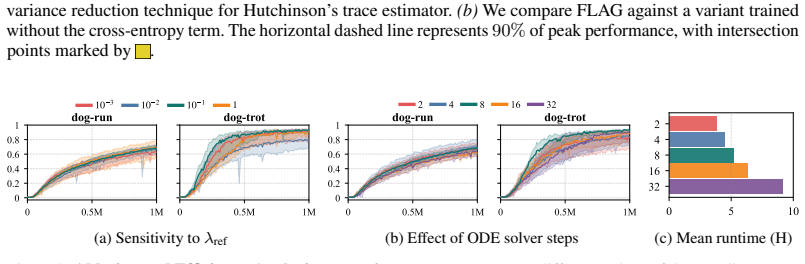
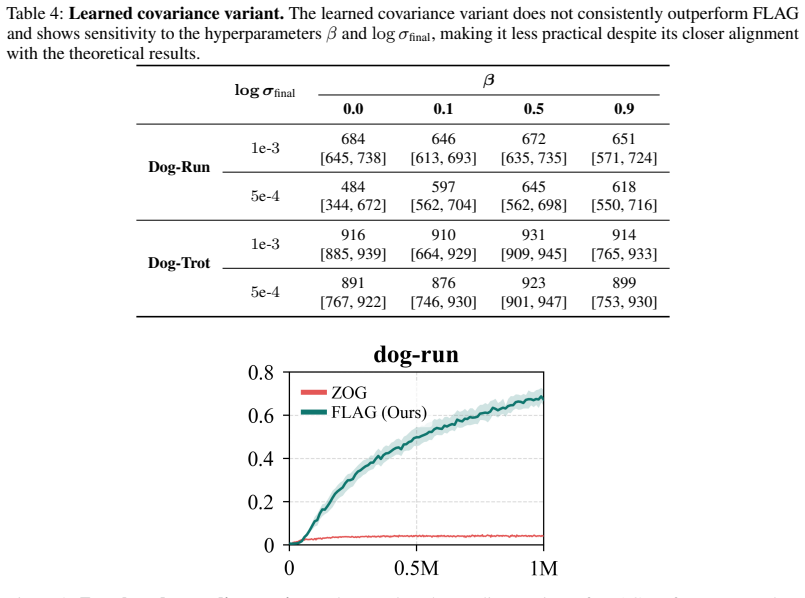
read the original abstract
Maximum entropy reinforcement learning (MaxEnt-RL) enables robust exploration, yet practical implementations often restrict policies to simple Gaussians. While recent approaches incorporate expressive generative policies via importance-weighted supervised learning, they are prone to importance weight collapse, which limits their scalability in high-dimensional action spaces. Our key insight is to mitigate this limitation by localizing the sampling region, avoiding the weight degeneracy induced by importance sampling over the entire action space. To instantiate this insight, we introduce \textbf{FLAG} (\textbf{F}low policy with \textbf{L}atent-\textbf{A}ugmented \textbf{G}uidance). FLAG augments the state space with a flow latent variable and optimizes a provably consistent proxy MaxEnt-RL objective. We empirically demonstrate that FLAG enables expressive policy optimization with limited importance samples and scales to high-dimensional control tasks. Furthermore, FLAG achieves state-of-the-art performance across challenging benchmarks. Our project webpage: https://flag-rl.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLAG (Flow policy with Latent-Augmented Guidance), a method for MaxEnt-RL that augments the state space with a flow latent variable. This enables optimization of a claimed provably consistent proxy objective, localizing sampling to avoid importance weight collapse when using expressive generative policies in high-dimensional action spaces. The work claims this allows effective policy optimization with limited importance samples and achieves state-of-the-art performance on challenging control benchmarks.
Significance. If the proxy objective is rigorously shown to be consistent and the latent augmentation demonstrably localizes sampling without introducing new biases, the method could meaningfully advance scalable MaxEnt-RL beyond Gaussian policies. The empirical SOTA claim on high-dimensional tasks would be a notable strength if supported by detailed, reproducible experiments with proper controls for importance sampling variance.
major comments (2)
- [Abstract] Abstract: The central claim that FLAG 'optimizes a provably consistent proxy MaxEnt-RL objective' is load-bearing for the contribution, yet the provided text contains no derivation, proof sketch, or formal statement of the augmented objective and its consistency guarantee. This prevents verification of whether the proxy is independent of fitted parameters or reduces to a tautology.
- [Abstract] Abstract: The empirical claims of enabling 'expressive policy optimization with limited importance samples' and achieving 'state-of-the-art performance across challenging benchmarks' lack any description of experimental setup, baselines, number of runs, or statistical tests. Without these, the SOTA assertion cannot be assessed and is not proportionate to the evidence shown.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that FLAG 'optimizes a provably consistent proxy MaxEnt-RL objective' is load-bearing for the contribution, yet the provided text contains no derivation, proof sketch, or formal statement of the augmented objective and its consistency guarantee. This prevents verification of whether the proxy is independent of fitted parameters or reduces to a tautology.
Authors: The abstract provides a high-level summary of the contribution. The full manuscript contains the formal derivation of the augmented objective (state space augmented by the flow latent variable) together with the consistency proof in Section 3; the proof establishes that the proxy recovers the optimal MaxEnt policy in the limit and is independent of the specific parameters of the fitted flow. We will revise the abstract to include a one-sentence reference to this section and a brief statement of the consistency guarantee. revision: partial
-
Referee: [Abstract] Abstract: The empirical claims of enabling 'expressive policy optimization with limited importance samples' and achieving 'state-of-the-art performance across challenging benchmarks' lack any description of experimental setup, baselines, number of runs, or statistical tests. Without these, the SOTA assertion cannot be assessed and is not proportionate to the evidence shown.
Authors: Abstracts conventionally omit detailed experimental protocols. The manuscript reports the full experimental setup, baselines, five independent random seeds, and statistical reporting in Section 5. We agree the abstract would be strengthened by a short clause noting that results are averaged over multiple seeds with standard deviations; we will add this. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract presents FLAG as augmenting the state space with a flow latent variable to optimize a provably consistent proxy MaxEnt-RL objective, with empirical scaling claims. No equations, derivations, or self-citations are supplied in the visible text that reduce the central claim to fitted inputs, self-definitions, or load-bearing prior author results by construction. The proxy objective is described as independent, and the reader's assessment of score 2.0 is consistent with the absence of any quoted reduction. The derivation chain appears self-contained against external benchmarks based on provided content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Relative Entropy Regularized Policy Iteration
Abbas Abdolmaleki, Jost Tobias Springenberg, Jonas Degrave, Steven Bohez, Yuval Tassa, Dan Belov, Nicolas Heess, and Martin Riedmiller. Relative entropy regularized policy iteration. arXiv preprint arXiv:1812.02256, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Maximum a posteriori policy optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation. InInternational Conference on Learning Representations, 2018
2018
-
[3]
Randomized algorithms for estimating the trace of an implicit symmetric positive semi-definite matrix.Journal of the ACM (JACM), 58(2):1–34, 2011
Haim Avron and Sivan Toledo. Randomized algorithms for estimating the trace of an implicit symmetric positive semi-definite matrix.Journal of the ACM (JACM), 58(2):1–34, 2011
2011
-
[4]
Layer normalization
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. InNeurIPS Deep Learning Symposium, 2016
2016
-
[5]
A distributional perspective on reinforce- ment learning
Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforce- ment learning. InInternational Conference on Machine Learning, pages 449–458, 2017
2017
-
[6]
Learning long-term dependencies with gradient descent is difficult.IEEE Transactions on Neural Networks, 5(2):157–166, 1994
Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult.IEEE Transactions on Neural Networks, 5(2):157–166, 1994
1994
-
[7]
CrossQ: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity
Aditya Bhatt, Daniel Palenicek, Boris Belousov, Max Argus, Artemij Amiranashvili, Thomas Brox, and Jan Peters. CrossQ: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity. InInternational Conference on Learning Representations, 2024
2024
-
[8]
Springer, 2006
Christopher M Bishop.Pattern Recognition and Machine Learning. Springer, 2006
2006
-
[9]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. 10
2018
-
[10]
MyoSuite: A contact-rich simulation suite for musculoskeletal motor control
Vittorio Caggiano, Huawei Wang, Guillaume Durandau, Massimo Sartori, and Vikash Kumar. MyoSuite: A contact-rich simulation suite for musculoskeletal motor control. InLearning for Dynamics and Control, pages 492–507, 2022
2022
-
[11]
DIME: Diffusion-based maximum entropy reinforcement learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. DIME: Diffusion-based maximum entropy reinforcement learning. In International Conference on Machine Learning, pages 6958–6977, 2025
2025
-
[12]
One-step flow policy mirror descent
Tianyi Chen, Haitong Ma, Na Li, Kai Wang, and Bo Dai. One-step flow policy mirror descent. arXiv preprint arXiv:2507.23675, 2025
-
[13]
Diffusion-based reinforcement learning via Q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via Q-weighted variational policy optimization. InAdvances in Neural Information Processing Systems, volume 37, pages 53945–53968, 2024. doi: 10.52202/079017-1708
-
[14]
GenPO: Generative diffusion models meet on-policy reinforcement learning
Shutong Ding, Ke Hu, Shan Zhong, Haoyang Luo, Weinan Zhang, Jingya Wang, Jun Wang, and Ye Shi. GenPO: Generative diffusion models meet on-policy reinforcement learning. In Advances in Neural Information Processing Systems, 2025
2025
-
[15]
Carles Domingo i Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InInternational Conference on Learning Representations, 2025
2025
-
[16]
Maximum entropy reinforcement learning with diffusion policy
Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion policy. InInternational Conference on Machine Learning, pages 13963–13983, 2025
2025
-
[17]
A minimalist approach to offline reinforcement learning
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 34, pages 20132–20145, 2021
2021
-
[18]
Springer, 2004
Paul Glasserman.Monte Carlo Methods in Financial Engineering. Springer, 2004
2004
-
[19]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational Conference on Machine Learning, pages 1352–1361, 2017
2017
-
[20]
Soft Actor-Critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft Actor-Critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational Conference on Machine Learning, pages 1861–1870, 2018
2018
-
[21]
A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Communications in Statistics - Simulation and Computation, 18(3):1059– 1076, 1989
Michael F Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Communications in Statistics - Simulation and Computation, 18(3):1059– 1076, 1989
1989
-
[22]
Stabilizing off-policy Q-learning via bootstrapping error reduction
Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy Q-learning via bootstrapping error reduction. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[23]
Hyper- spherical normalization for scalable deep reinforcement learning
Hojoon Lee, Youngdo Lee, Takuma Seno, Donghu Kim, Peter Stone, and Jaegul Choo. Hyper- spherical normalization for scalable deep reinforcement learning. InInternational Conference on Machine Learning, pages 33352–33403, 2025
2025
-
[24]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[26]
Flow-based policy for online reinforcement learning
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, Tao Kong, Jiafeng Xu, and Xiao Ma. Flow-based policy for online reinforcement learning. InAdvances in Neural Information Processing Systems, 2025. 11
2025
-
[27]
Efficient online reinforcement learning for diffusion policy
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy. InInternational Conference on Machine Learning, pages 41837–41853, 2025
2025
-
[28]
Flow matching policy gradients
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients. InInternational Conference on Learning Representations, 2026
2026
-
[29]
The expectation-maximization algorithm.IEEE Signal Processing Magazine, 13(6):47–60, 1996
Todd K Moon. The expectation-maximization algorithm.IEEE Signal Processing Magazine, 13(6):47–60, 1996
1996
-
[30]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. AW AC: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[31]
On the theory of risk-aware agents: Bridging actor-critic and economics
Michal Nauman and Marek Cygan. On the theory of risk-aware agents: Bridging actor-critic and economics. InICML Workshop on Aligning Reinforcement Learning Experimentalists and Theorists, 2024
2024
-
[32]
Bigger, regularized, optimistic: Scaling for compute and sample efficient continuous control
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło´s, and Marek Cygan. Bigger, regularized, optimistic: Scaling for compute and sample efficient continuous control. In Advances in Neural Information Processing Systems, volume 37, pages 113038–113071, 2024
2024
-
[33]
Springer Science & Business Media, 2013
Yurii Nesterov.Introductory Lectures on Convex Optimization: A Basic Course, volume 87. Springer Science & Business Media, 2013
2013
-
[34]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational Conference on Machine Learning, pages 1310–1318, 2013
2013
-
[35]
Pytorch: An imperative style, high-performance deep learning library.Advances in Neural Information Processing Systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[36]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[37]
Reinforcement learning by reward-weighted regression for operational space control
Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression for operational space control. InInternational Conference on Machine Learning, pages 745–750, 2007
2007
-
[38]
Learning a diffusion model policy from rewards via Q-score matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via Q-score matching. InInternational Conference on Machine Learning, pages 41163–41182, 2024
2024
-
[39]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational Conference on Machine Learning, pages 1889–1897, 2015
2015
-
[40]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Monte carlo sampling methods.Handbooks in Operations Research and Management Science, 10:353–425, 2003
Alexander Shapiro. Monte carlo sampling methods.Handbooks in Operations Research and Management Science, 10:353–425, 2003
2003
-
[42]
Importance sampling with unequal support
Philip Thomas and Emma Brunskill. Importance sampling with unequal support. InAAAI Conference on Artificial Intelligence, volume 31, 2017
2017
-
[43]
MuJoCo: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A physics engine for model-based control. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033, 2012
2012
-
[44]
Mirror descent policy optimization
Manan Tomar, Lior Shani, Yonathan Efroni, and Mohammad Ghavamzadeh. Mirror descent policy optimization. InInternational Conference on Learning Representations, 2022. 12
2022
-
[45]
Robot trajectory optimization using approximate inference
Marc Toussaint. Robot trajectory optimization using approximate inference. InInternational Conference on Machine Learning, pages 1049–1056, 2009
2009
-
[46]
dm_control: Software and tasks for continuous control.Software Impacts, 6:100022, 2020
Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess, and Yuval Tassa. dm_control: Software and tasks for continuous control.Software Impacts, 6:100022, 2020
2020
-
[47]
Diffusion actor-critic with entropy regulator
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, et al. Diffusion actor-critic with entropy regulator. In Advances in Neural Information Processing Systems, volume 37, pages 54183–54204, 2024. doi: 10.52202/079017-1717
-
[48]
Enhanced DACER algorithm with high diffusion efficiency.arXiv preprint arXiv:2505.23426, 2025
Yinuo Wang, Likun Wang, Mining Tan, Wenjun Zou, Xujie Song, Wenxuan Wang, Tong Liu, Guojian Zhan, Tianze Zhu, Shiqi Liu, et al. Enhanced DACER algorithm with high diffusion efficiency.arXiv preprint arXiv:2505.23426, 2025
-
[49]
Policy representation via diffusion probability model for reinforcement learning
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning.arXiv preprint arXiv:2305.13122, 2023
-
[50]
X t ˆrq(ˆst, at)/λ # −D KL (pq(ˆτ)∥p ˆπ(ˆτ)) ∴J(q, ξ) =E q
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. InAAAI Conference on Artificial Intelligence, volume 22, pages 1433–1438, 2008. 13 A Computational Challenges in Flow-based MaxEnt-RL In this section, we describe in detail the technical challenges of applying flow-based policies within th...
2008
-
[51]
The KL objectiveh(ˆπk, qk, θk)isL-smooth in a neighborhood ofθ k
-
[52]
There existsL ˜π>0such that∥∇ θ log ˜πθ(a|s)∥ ≤L ˜πfor allθin a neighborhood ofθ k
-
[53]
∞X t=0 γt∇θ log ˜πθk(at |s t) ˆs0 #⊤ ∆θk +O(∥∆θ k∥2) =αβE qk+1
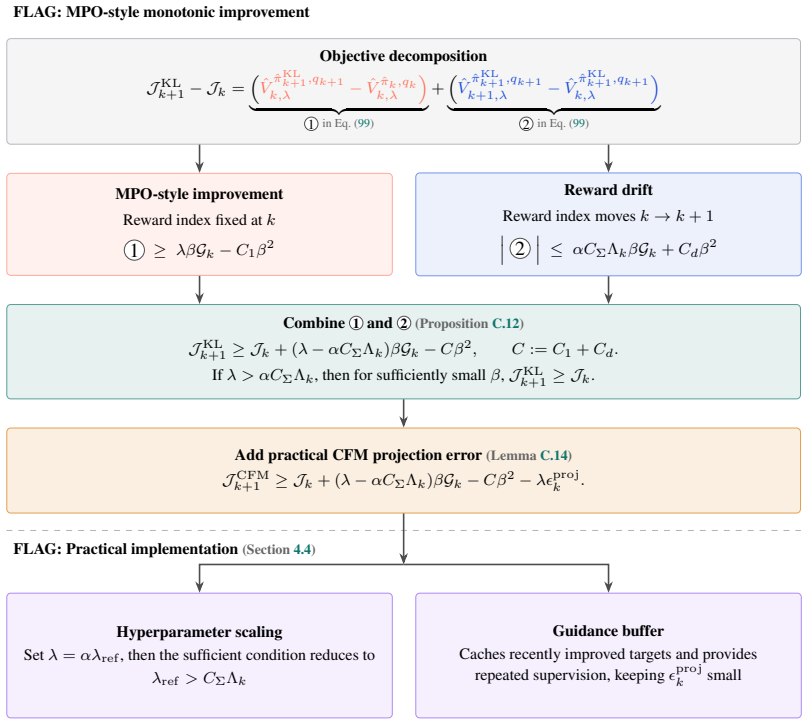
The E-step target and the KL-projected policy change only to first order in the M-step size: sup ˆs ∥qk+1(· |ˆs)−q k(· |ˆs)∥1 =O(β),sup ˆs ∥ˆπKL k+1(· |ˆs)−ˆπk(· |ˆs)∥1 =O(β). Assumption C.11(Variance-scaled drift alignment).Assume that, within iteration k, the local covariance is fixed with respect toθ, state-independent, and isotropic: Σk =σ 2 kI, σ 2 k...
2048
-
[54]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.