AbstainGNN: Teaching Graph Neural Networks to Abstain for Graph Classification
Pith reviewed 2026-06-28 23:55 UTC · model grok-4.3
The pith
AbstainGNN trains graph neural networks to reject uncertain predictions by jointly optimizing a predictive function and an abstention function under a PAC-Bayesian objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AbstainGNN explicitly models both the predictive function and the abstention function on graph data. From a PAC-Bayesian generalization perspective it characterizes the trade-off between classification errors and rejection costs, yielding a unified learning objective. An efficient two-stage training strategy of predictive warm-start followed by abstention calibration then optimizes this objective, producing superior classification performance at fixed rejection rates on five benchmark datasets.
What carries the argument
The unified learning objective derived from PAC-Bayesian bounds on the joint predictive-plus-abstention model, optimized via the two-stage warm-start plus calibration procedure.
If this is right
- GNNs can output an explicit abstain decision on graphs instead of always assigning a class label.
- The same PAC-Bayesian objective applies to any graph-structured input where both prediction and rejection costs matter.
- Two-stage training separates predictor initialization from abstention calibration without changing the underlying GNN architecture.
- Performance gains appear at fixed rejection budgets, directly improving reliability in downstream tasks.
- Graph structural information is used inside both the predictor and the abstainer.
Where Pith is reading between the lines
- The approach could extend to node-level or link-prediction tasks on the same graphs if the abstention head is attached to the appropriate readout.
- In safety-critical pipelines the reject option reduces the fraction of cases sent to expensive human review.
- If the bound tightness assumption fails on larger or noisier graphs, the empirical gains may shrink even though the training procedure still runs.
- The method supplies a concrete way to measure how much abstention budget is needed to reach a target accuracy on new graph datasets.
Load-bearing premise
The PAC-Bayesian bounds stay tight enough when applied to the combined prediction and abstention model on graphs that minimizing the derived objective actually improves real performance rather than just satisfying the bound.
What would settle it
Run the five benchmark experiments; if AbstainGNN does not achieve higher classification accuracy than existing abstention baselines at every tested rejection rate, the central claim does not hold.
Figures


read the original abstract
Graph classification is a core task in graph data mining with widespread real-world applications. Recent advances in graph neural networks (GNNs) have led to substantial performance improvements for graph classification. However, existing GNNs are typically forced to make predictions even under high uncertainty or unknown conditions, resulting in unreliable decisions that can severely impact downstream tasks, particularly in safety-critical scenarios. To address this critical limitation, we propose AbstainGNN, a novel and theory-driven framework for graph classification with abstention, which enables GNNs to reject uncertain predictions instead of producing incorrect decisions. Specifically, AbstainGNN explicitly models both the predictive function and the abstention function, allowing for effective utilization of graph structural information. Moreover, unlike existing heuristic abstention methods, we theoretically characterize the trade-off between classification errors and rejection costs from a PAC-Bayesian generalization perspective, and derive a unified learning objective for model optimization. Guided by this theoretical insight, we further develop an efficient two-stage training strategy consisting of predictive function warm-start and abstention function calibration. Extensive experiments on five benchmark datasets show that AbstainGNN outperforms existing abstention methods, achieving superior classification performance under the same rejection rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AbstainGNN, a framework that augments GNNs for graph classification with an explicit abstention function alongside the predictive function. It claims to derive a unified optimization objective from a PAC-Bayesian analysis that characterizes the trade-off between classification error and rejection cost, proposes a two-stage training procedure (warm-start of the predictor followed by abstention calibration), and reports superior empirical performance versus existing abstention baselines on five benchmark graph datasets under fixed rejection rates.
Significance. If the PAC-Bayesian derivation is valid and the resulting objective produces the claimed error-rejection trade-off on graphs, the work supplies a principled, theoretically grounded alternative to heuristic abstention methods in GNNs. This is relevant for safety-critical graph applications. The attempt to link PAC-Bayes directly to a joint predictive-abstention model and the two-stage training strategy are positive elements; empirical gains on standard benchmarks are noted but secondary to the theoretical contribution.
major comments (2)
- [§3] §3 (PAC-Bayesian derivation): the bound is stated for the joint hypothesis class consisting of the predictive and abstention functions, yet the derivation does not incorporate explicit correction terms for the non-i.i.d. dependencies induced by message passing over the adjacency matrix. Standard PAC-Bayes requires i.i.d. samples; without graph-kernel or spectral adjustments, it is unclear whether the bound remains valid or sufficiently tight for GNNs, which directly affects whether optimizing the derived objective controls the actual risk rather than only the surrogate.
- [§4] §4 (unified objective): the trade-off parameter between classification error and rejection cost appears as a free hyperparameter in the final objective. If this parameter is not derived from the PAC-Bayes bound but chosen post-hoc to match empirical rejection rates, the claim that the objective is 'theoretically characterized' from the generalization perspective is weakened.
minor comments (2)
- Notation for the abstention function and the joint loss should be introduced with explicit definitions before the derivation in §3 to improve readability.
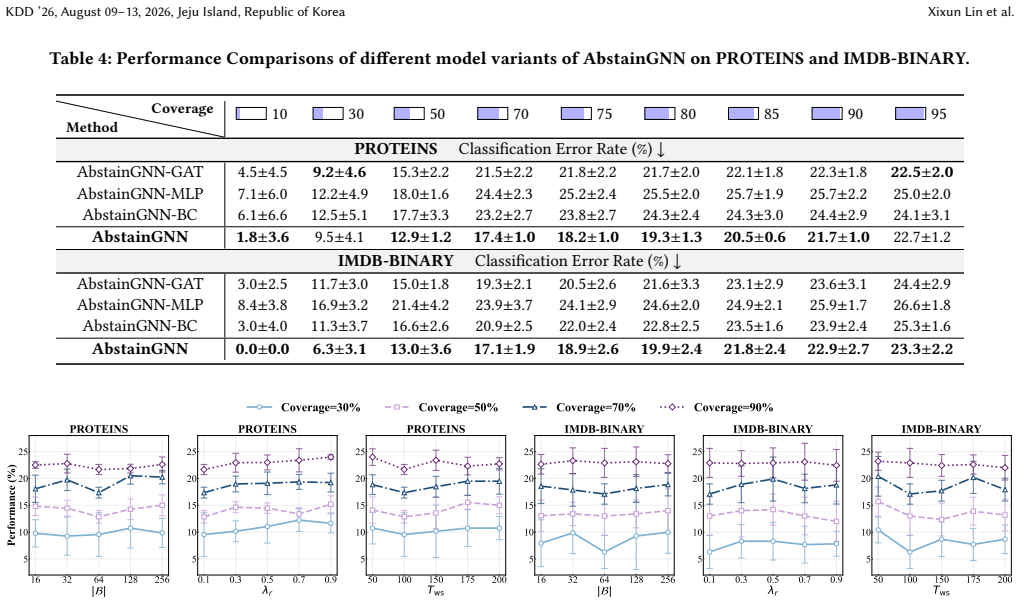
- Figure 2 (training pipeline) would benefit from labeling the warm-start and calibration stages with the corresponding loss terms from the unified objective.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. Below we provide point-by-point responses to the two major comments, indicating the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (PAC-Bayesian derivation): the bound is stated for the joint hypothesis class consisting of the predictive and abstention functions, yet the derivation does not incorporate explicit correction terms for the non-i.i.d. dependencies induced by message passing over the adjacency matrix. Standard PAC-Bayes requires i.i.d. samples; without graph-kernel or spectral adjustments, it is unclear whether the bound remains valid or sufficiently tight for GNNs, which directly affects whether optimizing the derived objective controls the actual risk rather than only the surrogate.
Authors: We agree that standard PAC-Bayes bounds are formulated under an i.i.d. assumption on the samples. In our derivation we treat each graph as an independent draw from the underlying distribution over graphs, which is the conventional modeling choice in graph classification. Intra-graph dependencies induced by message passing are not explicitly corrected for. Developing graph-specific adjustments (e.g., via kernels or spectral methods) would require substantial additional theoretical work that lies outside the scope of the present paper. We will therefore revise §3 to state this modeling assumption explicitly and to discuss it as a limitation of the current analysis, while noting that the derived objective still supplies a principled surrogate that empirically yields improved error-rejection trade-offs. revision: partial
-
Referee: [§4] §4 (unified objective): the trade-off parameter between classification error and rejection cost appears as a free hyperparameter in the final objective. If this parameter is not derived from the PAC-Bayes bound but chosen post-hoc to match empirical rejection rates, the claim that the objective is 'theoretically characterized' from the generalization perspective is weakened.
Authors: The trade-off parameter arises directly from the PAC-Bayesian bound as the weighting factor that balances the classification-error and rejection-cost terms in the generalization bound. Its functional role in the objective is therefore theoretically motivated. The concrete numerical value is selected by cross-validation to achieve a target rejection rate, which is standard practice for such multipliers. We will revise the exposition in §4 to distinguish clearly between the theoretically derived form of the objective and the empirical tuning of its single scalar coefficient, thereby strengthening rather than weakening the claim of theoretical characterization. revision: yes
Circularity Check
PAC-Bayesian derivation for joint abstention model is self-contained with no reduction to inputs
full rationale
The paper states it characterizes the error-rejection trade-off via PAC-Bayesian generalization bounds and derives a unified objective from that perspective, then uses a two-stage training strategy. No quoted equations or steps reduce the objective to a fitted parameter by construction, nor does the central premise rest on self-citation chains or imported uniqueness theorems. The derivation is presented as an application of standard external PAC-Bayes theory to the joint hypothesis class, leaving the claim with independent theoretical content rather than tautological renaming or self-definition. This is the normal non-circular outcome for theory-driven papers whose bounds are not shown to collapse internally.
Axiom & Free-Parameter Ledger
free parameters (1)
- trade-off parameter between classification error and rejection cost
axioms (1)
- domain assumption PAC-Bayesian generalization bounds can be applied to characterize the trade-off for models that jointly predict and abstain on graph data
invented entities (1)
-
abstention function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cristian Bodnar, Fabrizio Frasca, Yuguang Wang, Nina Otter, Guido F Montufar, Pietro Lio, and Michael Bronstein. 2021. Weisfeiler and lehman go topological: Message passing simplicial networks. InInternational conference on machine learning. PMLR, 1026–1037
2021
-
[2]
Karsten Borgwardt and Hans-Peter Kriegel. 2005. Protein function prediction via graph kernels. InISMB
2005
-
[3]
David Buterez, Jon Paul Janet, Dino Oglic, and Pietro Liò. 2025. An end-to-end attention-based approach for learning on graphs.Nature Communications16, 1 (2025), 5244
2025
-
[4]
Nontawat Charoenphakdee, Zhenghang Cui, Yivan Zhang, and Masashi Sugiyama. 2021. Classification with rejection based on cost-sensitive classi- fication. InInternational Conference on Machine Learning. PMLR, 1507–1517
2021
-
[5]
C Chow. 1970. On optimum recognition error and reject tradeoff.IEEE Transac- tions on Information Theory(1970)
1970
-
[6]
C Chow. 2003. On optimum recognition error and reject tradeoff.IEEE Transac- tions on information theory16, 1 (2003), 41–46
2003
-
[7]
C. K. Chow. 1970. On optimum recognition error and reject tradeoff.IEEE Transactions on Information Theory16, 1 (1970), 41–46
1970
-
[8]
Corinna Cortes, Giulia DeSalvo, and Mehryar Mohri. 2016. Boosting with absten- tion.Advances in neural information processing systems29 (2016)
2016
-
[9]
Corinna Cortes, Giulia DeSalvo, and Mehryar Mohri. 2016. Learning with rejec- tion.Journal of Machine Learning Research17, 130 (2016), 1–19
2016
-
[10]
Paul Dobson and Andrew Doig. 2003. Predicting protein function from structure. Molecular BioSystems(2003)
2003
- [11]
-
[12]
Vojtech Franc and Daniel Prusa. 2019. On discriminative learning of prediction uncertainty. InInternational conference on machine learning. PMLR, 1963–1971
2019
-
[13]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. InProceedings of the 33rd International Conference on Machine Learning. PMLR, 1050–1059
2016
- [14]
-
[15]
Yonatan Geifman and Ran El-Yaniv. 2017. Selective classification for deep neural networks.Advances in neural information processing systems30 (2017)
2017
-
[16]
Yonatan Geifman and Ran El-Yaniv. 2019. Selectivenet: A deep neural network with an integrated reject option. InInternational conference on machine learning. PMLR, 2151–2159
2019
-
[17]
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural message passing for quantum chemistry. InInternational conference on machine learning. PMLR, 1263–1272
2017
-
[18]
Yves Grandvalet, Alain Rakotomamonjy, Joseph Keshet, and Stéphane Canu. 2008. Support vector machines with a reject option.Advances in neural information processing systems21 (2008)
2008
-
[19]
Mei Guo, Chen Chen, Chunyan Hou, Yike Wu, and Xiaojie Yuan. 2025. FGDGNN: Fine-Grained Dynamic Graph Neural Network for Rumor Detection on Social Media. InFindings of the Association for Computational Linguistics: ACL 2025. 5676–5687
2025
-
[20]
Lang Huang, Chao Zhang, and Hongyang Zhang. 2020. Self-adaptive training: beyond empirical risk minimization.Advances in neural information processing systems33 (2020), 19365–19376
2020
-
[21]
Hisashi Kashima, Koji Tsuda, and Akihiro Inokuchi. 2003. Marginalized kernels between labeled graphs. InProceedings of the 20th international conference on machine learning (ICML-03). 321–328
2003
-
[22]
Thomas Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks
2016
-
[23]
Nils Kriege, Fredrik Johansson, and Christopher Morris. 2020. A survey on graph kernels.Applied Network Science(2020)
2020
-
[24]
Uday Bhaskar Kuchipudi, Jayadratha Gayen, Charu Sharma, and Naresh Manwani
-
[25]
Node Classification With Reject Option.Transactions on Machine Learning Research(2025)
2025
-
[26]
Zhi-Peng Li, Si-Guo Wang, Qin-Hu Zhang, Yi-Jie Pan, Nai-An Xiao, Jia-Yang Guo, Chang-An Yuan, Wen-Jian Liu, and De-Shuang Huang. 2024. Graph pooling for graph-level representation learning: a survey.Artificial Intelligence Review58, 2 (2024), 45
2024
-
[27]
Xixun Lin, Yanan Cao, Nan Sun, Lixin Zou, Chuan Zhou, Peng Zhang, Shuai Zhang, Ge Zhang, and Jia Wu. 2025. Conformal graph-level out-of-distribution detection with adaptive data augmentation. InProceedings of the ACM on Web Conference 2025. 4755–4765
2025
-
[28]
Xixun Lin, Zhao Li, Peng Zhang, Luchen Liu, Chuan Zhou, Bin Wang, and Zhihong Tian. 2022. Structure-aware prototypical neural process for few-shot graph classification.IEEE Transactions on Neural Networks and Learning Systems 35, 4 (2022), 4607–4621
2022
-
[29]
Xixun Lin, Qing Yu, Yanan Cao, Lixin Zou, Chuan Zhou, Jia Wu, Chenliang Li, Peng Zhang, and Shirui Pan. 2025. Generative Causality-driven Network for Graph Multi-task Learning.IEEE transactions on pattern analysis and machine intelligence(2025)
2025
-
[30]
Ziyin Liu, Zhikang Wang, Paul Pu Liang, Russ R Salakhutdinov, Louis-Philippe Morency, and Masahito Ueda. 2019. Deep gamblers: Learning to abstain with portfolio theory.Advances in Neural Information Processing Systems32 (2019)
2019
-
[31]
Diego Mesquita, Amauri Souza, and Samuel Kaski. 2020. Rethinking pooling in graph neural networks.Advances in Neural Information Processing Systems33 (2020), 2220–2231
2020
-
[32]
Christopher Morris, Nils M Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. 2020. Tudataset: A collection of benchmark datasets for learning with graphs.arXiv preprint arXiv:2007.08663(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[33]
Behnam Neyshabur, Srinadh Bhojanapalli, and Nathan Srebro. 2017. A pac- bayesian approach to spectrally-normalized margin bounds for neural networks. arXiv preprint arXiv:1707.09564(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Chenri Ni, Nontawat Charoenphakdee, Junya Honda, and Masashi Sugiyama
-
[35]
On the calibration of multiclass classification with rejection.Advances in neural information processing systems32 (2019)
2019
-
[36]
Soumyasundar Pal, Liheng Ma, Amine Natik, Yingxue Zhang, and Mark Coates
- [37]
-
[38]
Cheol Woo Park and Chris Wolverton. 2020. Developing an improved crys- tal graph convolutional neural network framework for accelerated materials discovery.Physical Review Materials4, 6 (2020), 063801
2020
-
[39]
Harish G Ramaswamy, Ambuj Tewari, and Shivani Agarwal. 2018. Consistent algorithms for multiclass classification with an abstain option. (2018)
2018
-
[40]
Nino Shervashidze, Pascal Schweitzer, Erik Van Leeuwen, Kurt Mehlhorn, and Karsten Borgwardt. 2011. Weisfeiler-Lehman graph kernels. InNeurIPS
2011
-
[41]
Joel A Tropp. 2012. User-friendly tail bounds for sums of random matrices. Foundations of computational mathematics12, 4 (2012), 389–434
2012
-
[42]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks.arXiv preprint arXiv:1710.10903(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Bingzhe Wu, Yatao Bian, Hengtong Zhang, Jintang Li, Junchi Yu, Liang Chen, Chaochao Chen, and Junzhou Huang. 2022. Trustworthy graph learning: Re- liability, explainability, and privacy protection. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 4838–4839
2022
-
[44]
Yu-Chang Wu, Shen-Huan Lyu, Haopu Shang, Xiangyu Wang, and Chao Qian
-
[45]
Confidence-aware Contrastive Learning for Selective Classification. In ICML
-
[46]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. 2020. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems32, 1 (2020), 4–24
2020
- [47]
-
[48]
Zhenqin Wu, Bharath Ramsundar, Evan Feinberg, Joseph Gomes, et al . 2018. MoleculeNet: A benchmark for molecular machine learning.Chemical Science (2018)
2018
-
[49]
Feng Xia, Ke Sun, Shuo Yu, Abdul Aziz, Liangtian Wan, Shirui Pan, and Huan Liu. 2021. Graph learning: A survey.IEEE Transactions on Artificial Intelligence2, 2 (2021), 109–127
2021
-
[50]
Tian Xie and Jeffrey C Grossman. 2018. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Physical review letters120, 14 (2018), 145301
2018
-
[51]
Xiaotian Xie, Biao Luo, Yingjie Li, Chunhua Yang, and Weihua Gui. 2024. Explor- ing heterophily in calibration of graph neural networks.Neurocomputing604 (2024), 128294
2024
-
[52]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Hao Yang, Min Wang, Qi Wang, Mingrui Lao, and Yun Zhou. 2024. Balanced confidence calibration for graph neural networks. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3747–3757
2024
-
[54]
Chaolong Ying, Xinjian Zhao, and Tianshu Yu. 2024. Boosting graph pooling with persistent homology.Advances in Neural Information Processing Systems37 (2024), 19087–19113
2024
-
[55]
Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. 2018. Hierarchical graph representation learning with differentiable pooling.Advances in neural information processing systems31 (2018)
2018
-
[56]
He Zhang, Bang Wu, Xingliang Yuan, Shirui Pan, Hanghang Tong, and Jian Pei
-
[57]
IEEE112, 2 (2024), 97–139
Trustworthy graph neural networks: Aspects, methods, and trends.Proc. IEEE112, 2 (2024), 97–139
2024
-
[58]
halved-margin
Yinglun Zhu and Robert Nowak. 2022. Efficient active learning with abstention. Advances in Neural Information Processing Systems35 (2022), 35379–35391. AbstainGNN: Teaching Graph Neural Networks to Abstain for Graph Classification KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea A Appendix A.1 Proof of Theorem 4.1 We first establish an intermed...
2022
-
[59]
First, we have 1 |𝐼 𝑦 | ∑︁ 𝐺∈𝐼 𝑦 𝜂(g 𝐺 − ¯g𝑦) 2 2 ≤4𝜂 2 max 𝐺 ||g 𝐺 || 2.(54) By Cauchy–Schwarz inequality, we have ∥𝑠𝑦 ∥2 ≤ 1 |𝐼 𝑦 | ∑︁ 𝐺∈𝐼 𝑦 𝑤 𝐺 ∥d𝐺 ∥2 ≤ 1 |𝐼 𝑦 | ∑︁ 𝐺∈𝐼 𝑦 ∥d𝐺 ∥2 ≤ √︁ 𝑀𝑦,(55) and therefore 2𝜆𝑟 𝜂 |𝐼 𝑦 | 𝑠𝑦 2 2 ≤ 4𝜆2𝑟 𝜂2 |𝐼 𝑦 |2 𝑀𝑦 . Using∥𝑎+𝑏∥ 2 2 ≤2∥𝑎∥ 2 2 +2∥𝑏∥ 2 2, we obtain 1 |𝐼 𝑦 | ∑︁ 𝐺∈𝐼 𝑦 ∥v𝐺 ∥2 2 ≤8𝜂 2 max 𝐺 ||g 𝐺 || 2 + 8𝜆2 𝑟 𝜂2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.