Anchoring LLM Gender Bias to Human Baselines: A Cross-Lingual Audit
Pith reviewed 2026-06-28 23:07 UTC · model grok-4.3
The pith
LLM gender stereotyping on HEXACO-100 spans a range 2.5 times wider than the full variation across 48 human countries and compounds across languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
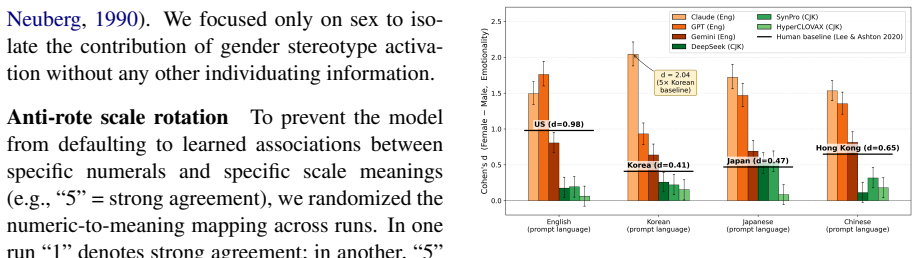
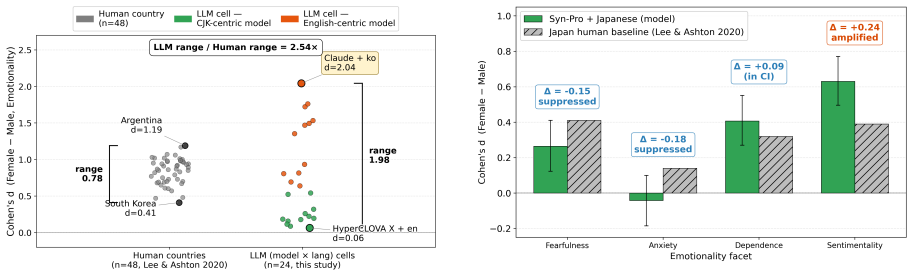
By anchoring LLM responses on the HEXACO-100 personality inventory to human data from 48 countries, the study shows that gender stereotyping in large language models spans a range 2.5 times wider than human cross-country differences, with the discrepancy able to compound when models are prompted in non-primary languages; item-level analysis further reveals that translation rearranges the content of stereotypes rather than simply scaling their intensity.
What carries the argument
The HEXACO-100 personality inventory applied to LLMs and compared to human baselines from 48 countries, together with the four-pattern framework of concordance, suppression, reorganization, and amplification.
Load-bearing premise
The HEXACO-100 provides a valid and comparable measure of gender stereotyping when given to LLMs as when given to human respondents across cultures and languages.
What would settle it
Demonstration that the spread of gender attributions produced by the tested LLMs on HEXACO-100 items falls inside the observed human cross-country range in every language examined.
Figures


read the original abstract
We audit six large language models (LLMs) for gender stereotyping across English, Korean, Chinese, and Japanese. Three were developed primarily for English-language use (Claude, GPT, Gemini) and three for East Asian use (DeepSeek, Syn-Pro, HyperCLOVA X). We adopt the HEXACO-100 personality inventory and anchor each model against a cross-cultural human dataset spanning 48 countries to ask not whether LLMs are biased, but how far their gender attributions drift from the populations they are deployed among. Our findings show that their stereotyping spans a range roughly 2.5 times wider than the entire cross-country range found in humans, and the effect can compound across languages. One English-centric model, prompted in Korean, reached 5 times the local baseline, even when the prompt stated the candidate had already been hired, which often dampens human stereotyping. To characterize such behaviors without ranking them, we introduce a four-pattern framework -- concordance, suppression, reorganization, and amplification -- across 24 (model x language) cells. Item-level analysis reveals that translation does not just rescale stereotypes, but changes the attributes tied to it, hiding significant rearrangement under the surface while appearing well-calibrated. Our results ultimately suggest that no single debiasing pipeline is likely to address bias evenly across linguistic boundaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits six LLMs (three English-centric, three East Asian) for gender stereotyping via HEXACO-100 prompts in English, Korean, Chinese, and Japanese. It anchors results against a 48-country human dataset and reports that LLM stereotyping ranges are roughly 2.5 times wider than the full human cross-country range, with compounding across languages (one English-centric model in Korean reaching 5x the local baseline even after a 'hired' prompt). It introduces a four-pattern framework (concordance, suppression, reorganization, amplification) across 24 model-language cells and notes that translation rearranges rather than merely rescales the attributes tied to stereotypes.
Significance. If the direct comparability of LLM and human HEXACO-100 responses holds, the results would demonstrate substantial, language-dependent drift in gender attributions that exceeds observed human variation and resists uniform mitigation, with the four-pattern framework offering a structured, non-ranking lens for cross-lingual analysis.
major comments (2)
- [Abstract / Methods] The 2.5x and 5x claims (abstract) rest on treating prompted LLM responses to the HEXACO-100 as a directly comparable metric of gender stereotyping to the 48-country human dataset. The manuscript provides no validation, stability checks, or controls demonstrating that these outputs reflect trait attribution structures rather than surface-level token associations or translation artifacts; this equivalence is load-bearing for interpreting the results as drift magnitude.
- [Results / Item-level analysis] The item-level analysis (abstract) asserts that translation 'changes the attributes tied to' stereotypes and produces 'significant rearrangement.' Without reported controls for prompt phrasing, response consistency across repeated queries, or explicit comparison of item loadings between LLM and human data, it is unclear whether observed differences exceed what would be expected from measurement mismatch alone.
minor comments (2)
- [Framework] The four-pattern framework is introduced without an explicit decision rule or inter-rater procedure for assigning cells to concordance/suppression/reorganization/amplification; a table or pseudocode definition would improve reproducibility.
- [Abstract] The abstract states that the 'hired' prompt 'often dampens human stereotyping' but does not cite the specific human-study reference or report the corresponding LLM effect size for that condition.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and agree that additional methodological controls will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] The 2.5x and 5x claims (abstract) rest on treating prompted LLM responses to the HEXACO-100 as a directly comparable metric of gender stereotyping to the 48-country human dataset. The manuscript provides no validation, stability checks, or controls demonstrating that these outputs reflect trait attribution structures rather than surface-level token associations or translation artifacts; this equivalence is load-bearing for interpreting the results as drift magnitude.
Authors: We agree that the direct comparability assumption is central to interpreting the reported drift magnitudes. The original manuscript relies on the standardized nature of the HEXACO-100 instrument and identical prompting across models and languages but does not include explicit stability checks or controls for token-level associations. In revision we will add repeated-prompt consistency analyses and controls comparing responses to semantically matched but non-personality prompts to demonstrate that the observed patterns exceed surface artifacts. revision: yes
-
Referee: [Results / Item-level analysis] The item-level analysis (abstract) asserts that translation 'changes the attributes tied to' stereotypes and produces 'significant rearrangement.' Without reported controls for prompt phrasing, response consistency across repeated queries, or explicit comparison of item loadings between LLM and human data, it is unclear whether observed differences exceed what would be expected from measurement mismatch alone.
Authors: We concur that stronger controls are needed to isolate genuine rearrangement from measurement mismatch. The current item-level claims rest on direct comparison of HEXACO item responses but lack the requested checks. We will incorporate prompt-variation robustness tests, repeated-query consistency metrics, and factor-loading comparisons between LLM and human data in the revised version to substantiate the reorganization pattern. revision: yes
Circularity Check
No circularity: empirical anchoring to external 48-country HEXACO-100 human dataset
full rationale
The paper measures LLM responses on the HEXACO-100 inventory across languages and directly compares the resulting gender-attribution ranges and patterns to an independent cross-cultural human dataset. No parameters are fitted to the target LLM outputs, no predictions are derived from the same data used for measurement, and the four-pattern framework (concordance, suppression, reorganization, amplification) is introduced as a descriptive taxonomy rather than a deductive result. The central claims rest on external benchmarks, satisfying the self-contained criterion with no load-bearing self-citations or definitional reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption HEXACO-100 provides a valid and comparable measure of gender stereotyping for both human respondents and LLM outputs across languages.
Reference graph
Works this paper leans on
-
[1]
Morten Moshagen, Isabel Thielmann, Benjamin E Hilbig, and Ingo Zettler
Social categorization and discriminatory be- havior: Extinguishing the minimal intergroup dis- crimination effect.Journal of personality and Social Psychology, 39(5):773. Morten Moshagen, Isabel Thielmann, Benjamin E Hilbig, and Ingo Zettler. 2019. Meta-analytic in- vestigations of the hexaco personality inventory (- revised).Zeitschrift für Psychologie. ...
2019
-
[2]
Large language models can replicate cross- cultural differences in personality.Journal of Re- search in Personality, 115:104584. OpenAI, Josh Achiam, Steven Adler, Sandhini Agar- wal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, P...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
HyperCLOVA X technical report.Preprint at https://arxiv.org/abs/2404.01954(2024)
Hyperclova x technical report.Preprint, arXiv:2404.01954. A Prompt Design and Anti-Rote Scale Rotation This appendix documents the exact prompts administered to each model, the anti-rote scale rotation procedure, and the item-order randomization used in each run. All materials were identical across the six models; only the API endpoint differed. A.1 Syste...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.