Sophrosyne: Agentic Exploration of Relational Data Systems Needs Moderation
Pith reviewed 2026-06-28 20:44 UTC · model grok-4.3
The pith
Fine-grained APIs in data systems cause Text2SQL agents to over-explore schemas and generate inaccurate queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
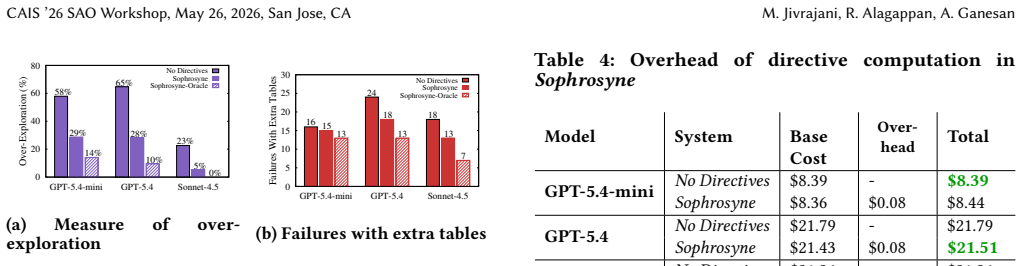
Text2SQL agents explore relational data systems through fine-grained APIs before formulating queries, yet this causes them to incorporate irrelevant schema elements and yield inaccurate SQL. Sophrosyne augments API responses with directives that guide the agent's exploration process, reducing over-exploration by 4.6x and improving accuracy by up to 12.4 percent.
What carries the argument
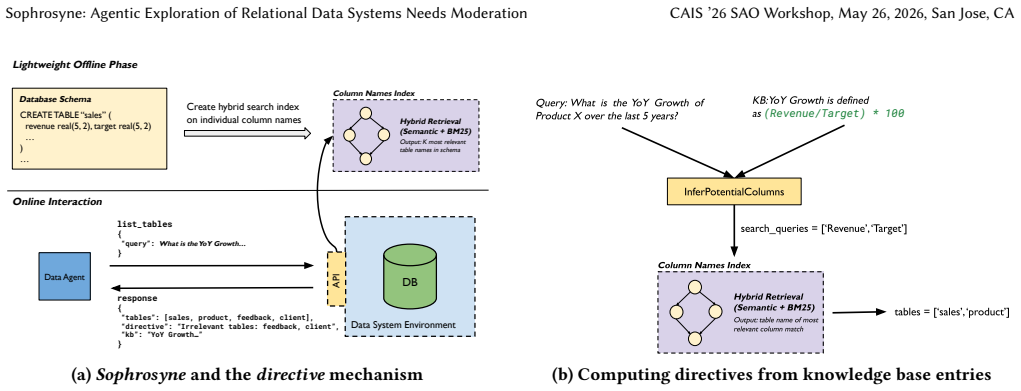
Sophrosyne, a data system environment that augments API responses with directives to guide the agent's exploration process.
If this is right
- Agents can safely use fine-grained APIs without the accuracy penalty from over-exploration.
- Data systems maintain their preferred fine-grained access model while supporting agentic workloads.
- Fewer tool calls occur during exploration, lowering the cost of query formulation.
- Accuracy on standard Text2SQL tasks rises without changes to the base API surface.
Where Pith is reading between the lines
- The same directive approach could moderate agent behavior when interacting with APIs in non-relational or non-database systems.
- API designers may need to consider agent exploration patterns as a first-class requirement alongside human users.
- Standardized directive formats across data systems could reduce the need for per-system solutions like Sophrosyne.
Load-bearing premise
Agents will incorporate the added directives into their exploration behavior instead of continuing to over-explore.
What would settle it
Run the same Text2SQL agent on a fixed benchmark set of natural language questions both with and without Sophrosyne directives, then count the number of irrelevant schema elements referenced in the generated queries.
Figures



read the original abstract
Text2SQL agents powered by LLMs translate natural language intent into SQL by exploring the data system through tool calls before formulating the query. However, to ensure secure and scoped access, data systems construct environments with explicit API surfaces. We study and categorize these APIs exposed today as either coarse-grained or fine-grained and posit that choosing between them presents a fundamental tradeoff between cost-efficient exploration and accurate SQL generation. Most data systems expose fine-grained APIs, but this inadvertently disadvantages agents: they over-explore, incorporating irrelevant schema elements into their query formulation and produce inaccurate results. We argue that curbing over-exploration is key to the effective use of these API surfaces, and propose Sophrosyne, a data system environment that augments API responses with directives that guide the agent's exploration process. Initial results show that directives reduce over-exploration by 4.6x and boost accuracy by up to 12.4% (approx. 4 percentage points).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that most data systems expose fine-grained APIs, which cause LLM-based Text2SQL agents to over-explore by incorporating irrelevant schema elements and generating inaccurate queries. It proposes Sophrosyne, a data system environment that augments API responses with directives to moderate the agent's exploration process, and reports initial results showing a 4.6x reduction in over-exploration and up to 12.4% (approximately 4 percentage points) accuracy improvement.
Significance. If the empirical results hold under rigorous evaluation, the work could be significant for the design of API surfaces in relational data systems intended for agentic use, by formalizing a cost-accuracy tradeoff between coarse- and fine-grained APIs and demonstrating a lightweight moderation mechanism via directives. The approach of embedding guidance directly in API responses is a practical contribution that could be adopted in production systems.
major comments (2)
- [Abstract] Abstract: The central empirical claims (4.6x reduction in over-exploration and up to 12.4% accuracy boost) are presented as direct outcomes of the proposed directives, yet the abstract supplies no experimental setup, benchmark datasets, agent implementation details, baseline systems, definition or measurement protocol for 'over-exploration,' or statistical analysis. This is load-bearing because the soundness of the hypothesis and the value of Sophrosyne rest entirely on these unverified quantitative results.
- [Abstract] Abstract: The posited fundamental tradeoff between coarse-grained and fine-grained APIs is asserted without any formal definitions, concrete examples drawn from existing data systems, or analysis showing how fine-grained APIs specifically induce over-exploration in Text2SQL agents. This weakens the motivation for the proposed moderation technique.
minor comments (1)
- [Abstract] The abstract contains a subject-verb agreement error ('they over-explore ... and produce inaccurate results').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the recommendation for major revision. We agree that the abstract can be strengthened to better contextualize the empirical claims and motivation. We respond to each major comment below and will incorporate revisions in the next manuscript version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (4.6x reduction in over-exploration and up to 12.4% accuracy boost) are presented as direct outcomes of the proposed directives, yet the abstract supplies no experimental setup, benchmark datasets, agent implementation details, baseline systems, definition or measurement protocol for 'over-exploration,' or statistical analysis. This is load-bearing because the soundness of the hypothesis and the value of Sophrosyne rest entirely on these unverified quantitative results.
Authors: We acknowledge that the abstract's brevity omits key experimental context, which could make the quantitative claims harder to evaluate at a glance. The full manuscript details the evaluation in Sections 4 and 5: benchmarks include Spider and BIRD; over-exploration is defined and measured as the rate of irrelevant schema elements incorporated (via schema element precision/recall); the agent uses a ReAct-style loop with tool calling; baselines include vanilla LLM prompting and unmoderated fine-grained API access; results include statistical analysis via multiple runs and significance testing. To address the concern directly, we will revise the abstract to concisely incorporate a high-level description of the setup, the over-exploration metric, and the evaluation protocol while remaining within length limits. revision: yes
-
Referee: [Abstract] Abstract: The posited fundamental tradeoff between coarse-grained and fine-grained APIs is asserted without any formal definitions, concrete examples drawn from existing data systems, or analysis showing how fine-grained APIs specifically induce over-exploration in Text2SQL agents. This weakens the motivation for the proposed moderation technique.
Authors: Section 2 of the manuscript categorizes real-world APIs from systems including PostgreSQL (fine-grained introspection endpoints), MySQL, BigQuery (coarser query interfaces), and Snowflake, with concrete examples of how fine-grained surfaces enable step-by-step schema exploration that leads agents to include extraneous tables/columns. Section 3 provides formal definitions of coarse- vs. fine-grained APIs and formalizes over-exploration as unnecessary expansion of the explored schema subgraph. We will revise the abstract to include a brief clause referencing this tradeoff analysis and its grounding in existing systems to better motivate the directives approach. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper advances an empirical hypothesis that fine-grained APIs cause agent over-exploration in Text2SQL tasks and evaluates a proposed moderation mechanism (Sophrosyne directives) via reported experimental gains. No equations, parameter fits, self-citations, or derivations appear in the abstract or described content; the accuracy and over-exploration metrics are presented as direct empirical outcomes rather than reductions to prior inputs or self-referential definitions. The central claim therefore remains independent of the circularity patterns enumerated.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-grained APIs cause agents to over-explore and incorporate irrelevant schema elements
Reference graph
Works this paper leans on
-
[1]
Shubham Agarwal, Asim Biswal, Sepanta Zeighami, Alvin Cheung, Joseph Gonzalez, and Aditya G. Parameswaran. Arming data agents with tribal knowledge. https://arxiv.org/abs/2602.13521, 2026
-
[2]
Inside meta’s home grown ai analytics agent
Analytics at Meta. Inside meta’s home grown ai analytics agent. https://medium.com/@AnalyticsAtMeta/inside-metas- home-grown-ai-analytics-agent-4ea6779acfb3 , March 2026
2026
-
[3]
OpenCode: The open source AI coding agent
Anomaly (SST). OpenCode: The open source AI coding agent. https: //opencode.ai, 2025. Apache-2.0 license. Accessed: 2026-03-15
2025
-
[4]
Introducing the Model Context Protocol
Anthropic. Introducing the Model Context Protocol. https://www. anthropic.com/news/model-context-protocol, November
-
[5]
Accessed: 2025-12-11
2025
-
[6]
Claude code
Anthropic. Claude code. https://code.claude.com/docs/en/ overview, 2025. Accessed: 2026-03-15
2025
-
[7]
Pricing - Claude documentation
Anthropic. Pricing - Claude documentation. https://docs. claude.com/en/docs/about-claude/pricing, 2025. Ac- cessed: 2025-12-11
2025
-
[8]
Cursor: The AI code editor
Anysphere. Cursor: The AI code editor. https://cursor.com,
-
[9]
Accessed: 2026-03-15
2026
-
[10]
Aurora DSQL MCP server
AWS Labs. Aurora DSQL MCP server. https://awslabs.github. io/mcp/servers/aurora-dsql-mcp-server , 2025. Apache- 2.0 license. Accessed: 2026-04-19
2025
-
[11]
MySQL MCP server
AWS Labs. MySQL MCP server. https://awslabs.github.io/ mcp/servers/mysql-mcp-server , 2025. Apache-2.0 license. Ac- cessed: 2026-04-19
2025
-
[12]
Postgres MCP server
AWS Labs. Postgres MCP server. https://awslabs.github.io/ mcp/servers/postgres-mcp-server, 2025. Apache-2.0 license. Accessed: 2026-04-19
2025
-
[13]
Redshift MCP server
AWS Labs. Redshift MCP server. https://awslabs.github.io/ mcp/servers/redshift-mcp-server, 2025. Apache-2.0 license. Accessed: 2026-04-19
2025
-
[14]
Pneuma: Leveraging LLMs for tabular data representation and retrieval in an end-to-end system.Proc
Muhammad Imam Luthfi Balaka, David Alexander, Qiming Wang, Yue Gong, Adila Krisnadhi, and Raul Castro Fernandez. Pneuma: Leveraging LLMs for tabular data representation and retrieval in an end-to-end system.Proc. ACM Manag. Data, 3(3), June 2025
2025
-
[15]
AgentSM: Semantic memory for agentic text-to-SQL
Asim Biswal, Chuan Lei, Xiao Qin, Aodong Li, Balakrishnan Narayanaswamy, and Tim Kraska. AgentSM: Semantic memory for agentic text-to-SQL. https://arxiv.org/abs/2601.15709, 2026
-
[16]
Building agents that reach production systems with mcp
Claude Platform. Building agents that reach production systems with mcp. https://claude.com/blog/building-agents-that- reach-production-systems-with-mcp, April 2026
2026
-
[17]
Cormack, Charles L A Clarke, and Stefan Buettcher
Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. Recip- rocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Confer- ence on Research and Development in Information Retrieval, SIGIR ’09, page 758–759, New York, NY, USA, 2009. Association for Computing Machinery
2009
-
[18]
Introducing genie agent mode
Databricks. Introducing genie agent mode. https://www. databricks.com/blog/introducing-genie-agent-mode , April 2026
2026
-
[19]
Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, and Hao Zhang. ReFoRCE: A text-to- SQL agent with self-refinement, consensus enforcement, and column exploration.https://arxiv.org/abs/2502.00675, 2025
-
[20]
Text-to-sql empowered by large language models: A benchmark evaluation.Proc
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. Text-to-sql empowered by large language models: A benchmark evaluation.Proc. VLDB Endow., 17(5):1132–1145, January 2024
2024
-
[21]
Google cloud MCP servers: Big query
Google Cloud. Google cloud MCP servers: Big query. https://docs.cloud.google.com/bigquery/docs/ reference/mcp/tools_overview, 2025. Preview. Accessed: 2026-03-15
2025
-
[22]
Use the Spanner remote MCP server
Google Cloud. Use the Spanner remote MCP server. https://docs. cloud.google.com/spanner/docs/use-spanner-mcp, 2026. Accessed: 2026-03-15
2026
-
[23]
Richard D. Hipp. SQLite. https://www.sqlite.org/index. html, 2020. Version 3.31.1
2020
-
[24]
Context rot: How increasing input tokens impacts LLM performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts LLM performance. Technical report, Chroma, July 2025
2025
-
[25]
Codes: Towards building open-source language models for text-to-sql.Proc
Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. Codes: Towards building open-source language models for text-to-sql.Proc. ACM Manag. Data, 2(3), May 2024
2024
-
[26]
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. Supporting our AI overlords: Redesigning data systems to be agent-first. https://arxiv.org/ abs/2509.00997, 2025
-
[27]
Parameswaran
Ruiying Ma, Shreya Shankar, Ruiqi Chen, Yiming Lin, Sepanta Zeighami, Rajoshi Ghosh, Abhinav Gupta, Anushrut Gupta, Tanmai Gopal, and Aditya G. Parameswaran. Can ai agents answer your data questions? a benchmark for data agents, 2026
2026
-
[28]
Query rewriting for retrieval-augmented large language models
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large language models. https://arxiv.org/abs/2305.14283, 2023
-
[29]
Azure SQL MCP Tools
Microsoft. Azure SQL MCP Tools. https://learn.microsoft. com/en-us/azure/data-api-builder/mcp/data- manipulation-language-tools, 2025. Accessed: 2026-04- 19
2025
-
[30]
Building agents that reach production sys- tems with mcp
Model Context Protocol. Building agents that reach production sys- tems with mcp. https://modelcontextprotocol.io/docs/ tutorials/security/authorization
-
[31]
MotherDuck’s DuckDB MCP server
MotherDuck. MotherDuck’s DuckDB MCP server. https:// github.com/motherduckdb/mcp-server-motherduck, 2025. MIT license. Accessed: 2026-04-19
2025
-
[32]
Mcp server for interacting with neon management api and databases
Neon Database. Mcp server for interacting with neon management api and databases. https://github.com/neondatabase/mcp- server-neon, 2026. MIT license. Accessed: 2026-03-15
2026
-
[33]
Fine- tuning text-to-sql models with reinforcement-learning training objec- tives.Natural Language Processing Journal, 10:100135, 2025
Xuan-Bang Nguyen, Xuan-Hieu Phan, and Massimo Piccardi. Fine- tuning text-to-sql models with reinforcement-learning training objec- tives.Natural Language Processing Journal, 10:100135, 2025
2025
-
[34]
Codex CLI
OpenAI. Codex CLI. https://developers.openai.com/ codex/cli/, 2025. Accessed: 2026-03-15
2025
-
[35]
Inside our in-house data agent
OpenAI. Inside our in-house data agent. https://openai.com/ index/inside-our-in-house-data-agent/, January 2026
2026
-
[36]
OpenAI API pricing
OpenAI. OpenAI API pricing. https://developers.openai. com/api/docs/pricing, 2026. Accessed: 2026-04-02
2026
-
[37]
PlanetScale MCP server
PlanetScale. PlanetScale MCP server. https://github.com/ planetscale/mcp-server, 2026. Apache-2.0 license. Accessed: 2026-03-15
2026
-
[38]
DTS-SQL: Decomposed text-to-SQL with small large language models
Mohammadreza Pourreza and Davood Rafiei. DTS-SQL: Decomposed text-to-SQL with small large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Associ- ation for Computational Linguistics: EMNLP 2024, pages 8212–8220, Miami, Florida, USA, November 2024. Association for Computational Linguistics
2024
-
[39]
ROUTE: Robust multitask tuning and collaboration for text-to-SQL
Yang Qin, Chao Chen, Zhihang Fu, Ze Chen, Dezhong Peng, Peng Hu, and Jieping Ye. ROUTE: Robust multitask tuning and collaboration for text-to-SQL. InThe Thirteenth International Conference on Learning 5 CAIS ’26 SAO Workshop, May 26, 2026, San Jose, CA M. Jivrajani, R. Alagappan, A. Ganesan Representations, 2025
2026
-
[40]
Robertson and Steve Walker
Stephen E. Robertson and Steve Walker. Some simple effective approx- imations to the 2-poisson model for probabilistic weighted retrieval. InProceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 232–241, Dublin, Ireland, 1994. Springer-Verlag
1994
-
[41]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. https://arxiv.org/abs/2302.04761, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Automatic metadata extraction for text-to-SQL
Vladislav Shkapenyuk, Divesh Srivastava, Theodore Johnson, and Parisa Ghane. Automatic metadata extraction for text-to-SQL. https: //arxiv.org/abs/2505.19988, 2025
-
[43]
Amp: AI coding agent
Sourcegraph. Amp: AI coding agent. https://ampcode.com, 2025. Accessed: 2026-03-15
2025
-
[44]
Supabase MCP server
Supabase Community. Supabase MCP server. https://github. com/supabase-community/supabase-mcp, 2025. Apache-2.0 license. Accessed: 2026-03-15
2025
-
[45]
CHESS: Contextual Harnessing for Efficient SQL Synthesis
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. CHESS: Contextual harnessing for efficient SQL synthesis. https://arxiv.org/abs/2405.16755, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
LiveSQLBench: A dynamic and contamination-free benchmark for evaluating LLMs on real-world text-to-SQL tasks
BIRD Team. LiveSQLBench: A dynamic and contamination-free benchmark for evaluating LLMs on real-world text-to-SQL tasks. https://github.com/bird-bench/livesqlbench, 2025. Ac- cessed: 2025-05-22
2025
-
[47]
Introducing the Turso database MCP
Turso. Introducing the Turso database MCP. https: //turso.tech/blog/introducing-the-turso-database- mcp-server, 2025. Accessed: 2026-05-03
2025
-
[48]
approximate air quality
Matei Zaharia. Bridging the operational and analytical worlds with Lakebase. InProceedings of the 51st International Conference on Very Large Data Bases, VLDB ’25, 2025. Keynote 3. 6 Sophrosyne: Agentic Exploration of Relational Data Systems Needs Moderation CAIS ’26 SAO Workshop, May 26, 2026, San Jose, CA A System Prompts A.1 Column Inference System Pro...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.